双音多频技术介绍及应用——识别电话号码
双音多频技术
作者:郑不挫。
原理
电话拨号有两种,脉冲和音频,所谓音频也称双音多频(DTMF)信号的拨号方式,双音多频既是电话拨号时每按一个键,有两个音频频率叠加成一个双音频信号,十二个按键由八个音频频率区分。如下图

应用
知道了双音多频技术的原理,下面讲讲如何通过双音多频技术来识别号码。采用的音频的采样频率为1000Hz,随意录制一段拨号音频,其时域波形如下:
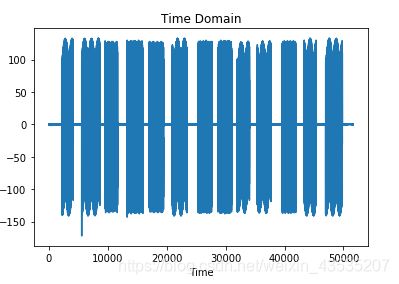
为了进行号码识别,需要将音频信号进行切割,这里可以通过幅值来进行切割,比较简单就不说了。切割完成后,就得到了每个拨号的音频,然后对每个拨号进行FFT变换并进行一定的信号处理,就可以得到每个拨号音频的信号。

由于音频的频率为1000Hz,故双音多频表格中对应的频率也要做相应变化
如下表:

下面就是识别每个拨号音频的频谱图上的两个波峰对应的频率即可完成拨号识别。

源码
# -*- coding: utf-8 -*-
"""
Created on Mon Oct 12 22:57:08 2020
@author: ZhengBuCuo
"""
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 加载数据并进行预处理
def Load_data(filepath):
# 使用read_csv方法读取数据
input_data = pd.read_csv(filepath, sep = ' ', header=None,engine = 'python' )
input_data = np.array(input_data)
# 对数据进行预处理,便于频域变换
Pretreated_data = input_data[:,1]-3232
plt.plot(input_data[:,0],Pretreated_data)
plt.title('Time Domain')
plt.xlabel('Time')
plt.show()
return Pretreated_data
# 将时域信号转至频域
def TransformTofrequencydomain(data):
sample_rate = 1000 # 采样率
nframes = len(data) # 信号点数
df=sample_rate/(nframes-1)
freq=[df*n for n in range(0,nframes)] # 信号频率
transformed=np.fft.fft(data) # 对信号进行傅里叶变换
d = int(len(transformed)/2) # 根据对称性,取一般
while freq[d]>500: # 去除频率大于500的无效信息
d-=10
freq=freq[:d]
transformed=transformed[:d]
for i,data in enumerate(transformed): # 取绝对值
transformed[i]=abs(data)
plt.plot(freq,transformed)
plt.title('Frequency Domain')
plt.xlabel('Frequency')
plt.show()
return freq , transformed
# 找频域图中低频和高频的两个波峰
def find_peaks(freq,fft_result):
local_peaks=[]
for i in np.arange(1,len(fft_result)-20):
if fft_result[i]>fft_result[i-1] and fft_result[i]>fft_result[i+1]: #波峰必须在大于左右两个点
max_flag = 1
for j in range(1,20): # 在大于左右两个点的前提下,判断是否大于周围20个点,排除干扰,保证结果的正确性
if fft_result[i]<fft_result[i-j] or fft_result[i]<fft_result[i+j]:
max_flag = 0
break
if max_flag == 1:
#print(fft_result[i])
local_peaks.append(fft_result[i])
local_peaks=sorted(local_peaks)
# 取最后两个值作为低频和高频的波峰
loc1=np.where(fft_result==local_peaks[-1])
peak1_freq=freq[loc1[0][0]]
loc1=np.where(fft_result==local_peaks[-2])
peak2_freq=freq[loc1[0][0]]
#print('Freqs of two peaks:',peak2_freq,peak1_freq)
if peak1_freq > peak2_freq:
temp = peak1_freq
peak1_freq = peak2_freq
peak2_freq = temp
return peak1_freq,peak2_freq
# 利用双音多频技术识别号码
def recognition_numbers(AllPeak_freqs):
result = []
low_index = 0
high_index = 0
num = 0
# 根据双音多频得到1000Hz采样率的参考频率
reference_low_freqs = [303,230,148,59]
reference_high_freqs = [209,336,477]
# 双音多频模板
Keyborad_demo = np.mat([[1,2,3],
[4,5,6],
[7,8,9],
[99,0,99]])
# 根据频率判断数字在模板中的位置,从而得到识别结果
for i in range(0,len(AllPeak_freqs),2):
num_lowfreq = AllPeak_freqs[i]
num_highfreq = AllPeak_freqs[i+1]
for i in range(4):
if abs(num_lowfreq-reference_low_freqs[i])<20:
low_index = i
for i in range(3):
if abs(num_highfreq-reference_high_freqs[i])<20:
high_index = i
# print(low_index,high_index)
num = Keyborad_demo[low_index,high_index]
if num == 99:
print("Recognition failed!")
result.append(num)
low_index = 0
high_index = 0
return result
def TransformTofrequencydomain(data):
sample_rate = 1000
nframes = len(data)
fr=sample_rate/(nframes-1)
freq=[fr*n for n in range(0,nframes)] #得到对应频率
transformed=np.fft.fft(data) #傅里叶变换
d = int(len(transformed)/2)
freq=freq[:d]
transformed=transformed[:d]
for i,data in enumerate(transformed): # 取绝对值
transformed[i]=abs(data)
plt.plot(freq,transformed) ##绘制频谱图
plt.title('Frequency Domain')
plt.xlabel('Frequency')
plt.show()
return freq , transformed
def find_wavepeaks(freq,fft_result):
freq_peaks=[] #保存峰值频率
for i in np.arange(1,len(fft_result)-20):
if fft_result[i]>fft_result[i-1] and fft_result[i]>fft_result[i+1]: #波峰必须在大于左右两个点
max_flag = 1
for j in range(1,20): # 在大于左右两个点的前提下,判断是否大于周围20个点,排除干扰,保证结果的正确性
if fft_result[i]<fft_result[i-j] or fft_result[i]<fft_result[i+j]:
max_flag = 0
break
if max_flag == 1:
#print(fft_result[i])
freq_peaks.append(fft_result[i])
freq_peaks=sorted(freq_peaks) #排序
loc1=np.where(fft_result==freq_peaks[-1])
peak1_freq=freq[loc1[0][0]] #根据峰值 位置取出对应频率
loc1=np.where(fft_result==freq_peaks[-2])
peak2_freq=freq[loc1[0][0]]
if peak1_freq > peak2_freq:
temp = peak1_freq
peak1_freq = peak2_freq
peak2_freq = temp
print('Freqs of two peaks:',peak1_freq,peak2_freq)
return peak1_freq,peak2_freq
def Decoder_numbers(AllPeak_freqs):
# 双音多频的频率
reference_low_freqs = [303,230,148,59]
reference_high_freqs = [209,336,477]
# 双音多频频率对应的数字
freqsofnumbers = np.mat([[1,2,3],
[4,5,6],
[7,8,9],
[886,0,886]])
result = [] # 用于保存结果
lowfreq_index = 0 #
highfreq_index = 0
num = 0
# 根据双音多频的参考频率进行数字的识别
for i in range(0,len(AllPeak_freqs),2):
num_lowfreq = AllPeak_freqs[i]
num_highfreq = AllPeak_freqs[i+1]
for i in range(4):
if abs(num_lowfreq-reference_low_freqs[i])<40:
lowfreq_index = i
break
for i in range(3):
if abs(num_highfreq-reference_high_freqs[i])<40:
highfreq_index = i
break
# print(low_index,high_index)
num = freqsofnumbers[lowfreq_index,highfreq_index]
if num == 886:
print("")
result.append(num)
lowfreq_index = 0
highfreq_index = 0
return result
# 加载数据
Pretreated_data = Load_data("msc_matric_9.dat")
# 对数据进行处理,提取有效数据,即拨号的声音信息
index = 0
flag = False
efficient_all_signal = [] # 用于保留所有的有效信号
efficient_data = [] # 暂存有效信息
count = 0
for i in range(0, len(Pretreated_data)):
if abs(Pretreated_data[i])>1: # 大于1,保存为有效信息
efficient_data.append(Pretreated_data[i])
if i+1 > len(Pretreated_data):
break
if abs(Pretreated_data[i+1])<=1: # 小于等于1,视为无效信息,判断是否有连续60个无效信息,是的话说明有效信息保留完成
for j in range(1,60):
if i+1+j > len(Pretreated_data):
break
if abs(Pretreated_data[i+1+j])<=1:
index += 1
if index>=59:
flag = True
if flag == True:
if len(efficient_data)>1000:
efficient_all_signal.append(efficient_data) # 整合有效信息
count += 1
index = 0
flag = False
efficient_data = []
print(count,"numbers")
# 对有效的信号进行傅里叶变换,并找到频谱图中的低频波峰和高频波峰
AllPeak_freqs = []
for i in range(len(efficient_all_signal)):
freq,fft_signal = TransformTofrequencydomain(efficient_all_signal[i])
peak1_freq,peak2_freq = find_peaks(freq,fft_signal)
# 按照低频,高频的顺序保存
if peak1_freq > peak2_freq:
AllPeak_freqs.append(peak2_freq)
AllPeak_freqs.append(peak1_freq)
else:
AllPeak_freqs.append(peak1_freq)
AllPeak_freqs.append(peak2_freq)
# 利用模板频率信息,和双音多频技术机型识别并得到结果
result = recognition_numbers(AllPeak_freqs)
print("recognition results:",result)
音频文件
音频文件和源码已上传在我的资源,可以下载验证。
参考文献
度娘百科