2022软工第06组第三次博客作业
本博客为OUC2022秋季软件工程06组第三次作业
目录
-
- 一、视频学习
- 二、代码练习
-
- 1、MNIST 数据集分类
- 2、CIFAR10 数据集分类
- 3、使用 VGG16 对 CIFAR10 分类
- 三、问题思考
一、视频学习
这周学习的这个视频,主要讲解了CNN的的基本组成结构——卷积、池化和全连接。还介绍了AlexNet到ResNet等典型结构。
卷积神经网络用处很大,人脸识别、人脸认证、物品分类等都可以见到,最近比较火的AI绘画也是使用此技术。相对于传统神经网络,参数更少,准确率更高。
经过卷积处理,可以使输入的参数减少。卷积在我理解,就是将图像的特征提取出来。
而池化,则是保留主要特征的同时减少参数和计算量,防止过拟合,提高模型泛化能力,它一般处于卷积层和卷积层之间,全连接层和全连接层之间。一般分为最大值池化和平均池化。
全连接层通常处于卷积神经网络的尾部,参数量是所有层最大的,两次全连接层之间所有神经元都有权重链接。
在AlexNet卷积神经网络结构中,使用了百万级数据训练,和非线性激活函数,这个函数能解决梯度会变为0的情况,为了防止过拟合,还开创性地使用了Dropout和Data augmentation函数。
而现在应用的ResNet已经可以用来训练非常深的网络了。
二、代码练习
1、MNIST 数据集分类
——构建简单的CNN对 mnist 数据集进行分类
添加各种头文件
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
import numpy
# 一个函数,用来计算模型中有多少参数
def get_n_params(model):
np=0
for p in list(model.parameters()):
np += p.nelement()
return np
# 使用GPU训练
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
(1) 加载数据(MNIST)
MNIST的使用方法如下,可以将这些数据下载到本地
torchvision.datasets.MNIST(root, train=True, transform=None, target_transform=None, download=False)
其中
- root 为数据集下载到本地后的根目录,包括 training.pt 和 test.pt 文件
- train,如果设置为True,从training.pt创建数据集,否则从test.pt创建。
- download,如果设置为True, 从互联网下载数据并放到root文件夹下
- transform, 一种函数或变换,输入PIL图片,返回变换之后的数据。
- target_transform 一种函数或变换,输入目标,进行变换。
input_size = 28*28 # MNIST上的图像尺寸是 28x28
output_size = 10 # 类别为 0 到 9 的数字,因此为十类
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('./data', train=True, download=True,
transform=transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))])),
batch_size=64, shuffle=True)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('./data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))])),
batch_size=1000, shuffle=True)
然后我们运行下面的代码可以显示数据集中的部分图像
plt.figure(figsize=(8, 5))
for i in range(20):
plt.subplot(4, 5, i + 1)
image, _ = train_loader.dataset.__getitem__(i)
plt.imshow(image.squeeze().numpy(),'gray')
plt.axis('off');

(2) 创建网络
定义网络时,需要继承nn.Module,并实现它的forward方法
class FC2Layer(nn.Module):
def __init__(self, input_size, n_hidden, output_size):
# nn.Module子类的函数必须在构造函数中执行父类的构造函数
# 下式等价于nn.Module.__init__(self)
super(FC2Layer, self).__init__()
self.input_size = input_size
# 这里直接用 Sequential 就定义了网络,注意要和下面 CNN 的代码区分开
self.network = nn.Sequential(
nn.Linear(input_size, n_hidden),
nn.ReLU(),
nn.Linear(n_hidden, n_hidden),
nn.ReLU(),
nn.Linear(n_hidden, output_size),
nn.LogSoftmax(dim=1)
)
def forward(self, x):
# view一般出现在model类的forward函数中,用于改变输入或输出的形状
# x.view(-1, self.input_size) 的意思是多维的数据展成二维
# 代码指定二维数据的列数为 input_size=784,行数 -1 表示我们不想算,电脑会自己计算对应的数字
# 在 DataLoader 部分,我们可以看到 batch_size 是64,所以得到 x 的行数是64
# 大家可以加一行代码:print(x.cpu().numpy().shape)
# 训练过程中,就会看到 (64, 784) 的输出,和我们的预期是一致的
# forward 函数的作用是,指定网络的运行过程,这个全连接网络可能看不啥意义,
# 下面的CNN网络可以看出 forward 的作用。
x = x.view(-1, self.input_size)
return self.network(x)
class CNN(nn.Module):
def __init__(self, input_size, n_feature, output_size):
# 执行父类的构造函数,所有的网络都要这么写
super(CNN, self).__init__()
# 下面是网络里典型结构的一些定义,一般就是卷积和全连接
# 池化、ReLU一类的不用在这里定义
self.n_feature = n_feature
self.conv1 = nn.Conv2d(in_channels=1, out_channels=n_feature, kernel_size=5)
self.conv2 = nn.Conv2d(n_feature, n_feature, kernel_size=5)
self.fc1 = nn.Linear(n_feature*4*4, 50)
self.fc2 = nn.Linear(50, 10)
# 下面的 forward 函数,定义了网络的结构,按照一定顺序,把上面构建的一些结构组织起来
# 意思就是,conv1, conv2 等等的,可以多次重用
def forward(self, x, verbose=False):
x = self.conv1(x)
x = F.relu(x)
x = F.max_pool2d(x, kernel_size=2)
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x, kernel_size=2)
x = x.view(-1, self.n_feature*4*4)
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x)
x = F.log_softmax(x, dim=1)
return x
接下来我们开始定义训练和测试函数,如下:
# 训练函数
def train(model):
model.train()
# 主里从train_loader里,64个样本一个batch为单位提取样本进行训练
for batch_idx, (data, target) in enumerate(train_loader):
# 把数据送到GPU中
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % 100 == 0:
print('Train: [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
def test(model):
model.eval()
test_loss = 0
correct = 0
for data, target in test_loader:
# 把数据送到GPU中
data, target = data.to(device), target.to(device)
# 把数据送入模型,得到预测结果
output = model(data)
# 计算本次batch的损失,并加到 test_loss 中
test_loss += F.nll_loss(output, target, reduction='sum').item()
# get the index of the max log-probability,最后一层输出10个数,
# 值最大的那个即对应着分类结果,然后把分类结果保存在 pred 里
pred = output.data.max(1, keepdim=True)[1]
# 将 pred 与 target 相比,得到正确预测结果的数量,并加到 correct 中
# 这里需要注意一下 view_as ,意思是把 target 变成维度和 pred 一样的意思
correct += pred.eq(target.data.view_as(pred)).cpu().sum().item()
test_loss /= len(test_loader.dataset)
accuracy = 100. * correct / len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
accuracy))
(3) 在小型全连接网络上训练(Fully-connected network)
n_hidden = 8 # number of hidden units
model_fnn = FC2Layer(input_size, n_hidden, output_size)
model_fnn.to(device)
optimizer = optim.SGD(model_fnn.parameters(), lr=0.01, momentum=0.5)
print('Number of parameters: {}'.format(get_n_params(model_fnn)))
train(model_fnn)
test(model_fnn)
结果如下:
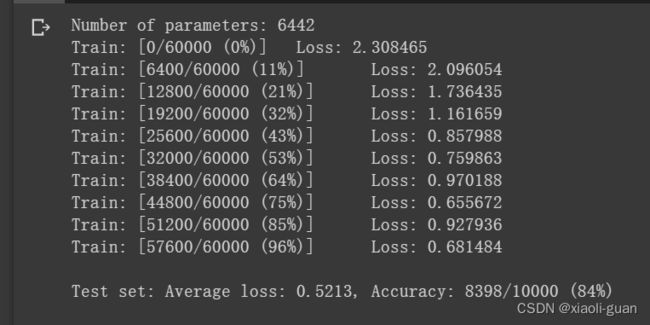
测试集:平均损失:0.5212,准确率:8398/10000 (84%)
(4) 在卷积神经网络上训练
# Training settings
n_features = 6 # number of feature maps
model_cnn = CNN(input_size, n_features, output_size)
model_cnn.to(device)
optimizer = optim.SGD(model_cnn.parameters(), lr=0.01, momentum=0.5)
print('Number of parameters: {}'.format(get_n_params(model_cnn)))
train(model_cnn)
test(model_cnn)
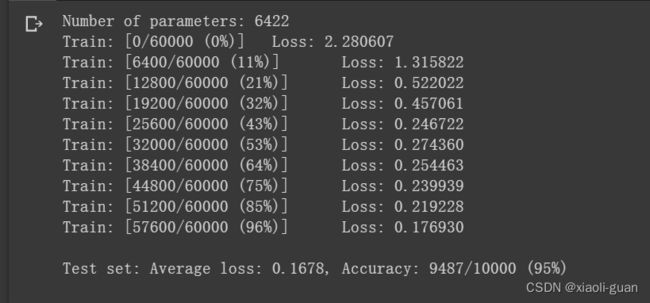
测试集:平均损失:0.1678,准确率:9487/10000 (95%)
对比两个结果可以发现,含有相同参数的 CNN 效果要明显优于 简单的全连接网络。这是因为卷积神经网络的两个手段——卷积和池化。
(5)打乱像素顺序再次在两个网络上训练与测试
如果我们把图像中的像素打乱顺序,这样 卷积 和 池化 就难以发挥作用了。
首先下面代码展示随机打乱像素顺序后,图像的形态:
# 这里解释一下 torch.randperm 函数,给定参数n,返回一个从0到n-1的随机整数排列
perm = torch.randperm(784)
plt.figure(figsize=(8, 4))
for i in range(10):
image, _ = train_loader.dataset.__getitem__(i)
# permute pixels
image_perm = image.view(-1, 28*28).clone()
image_perm = image_perm[:, perm]
image_perm = image_perm.view(-1, 1, 28, 28)
plt.subplot(4, 5, i + 1)
plt.imshow(image.squeeze().numpy(), 'gray')
plt.axis('off')
plt.subplot(4, 5, i + 11)
plt.imshow(image_perm.squeeze().numpy(), 'gray')
plt.axis('off')

然后重新定义和训练与测试函数
# 对每个 batch 里的数据,打乱像素顺序的函数
def perm_pixel(data, perm):
# 转化为二维矩阵
data_new = data.view(-1, 28*28)
# 打乱像素顺序
data_new = data_new[:, perm]
# 恢复为原来4维的 tensor
data_new = data_new.view(-1, 1, 28, 28)
return data_new
# 训练函数
def train_perm(model, perm):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
# 像素打乱顺序
data = perm_pixel(data, perm)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % 100 == 0:
print('Train: [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
# 测试函数
def test_perm(model, perm):
model.eval()
test_loss = 0
correct = 0
for data, target in test_loader:
data, target = data.to(device), target.to(device)
# 像素打乱顺序
data = perm_pixel(data, perm)
output = model(data)
test_loss += F.nll_loss(output, target, reduction='sum').item()
pred = output.data.max(1, keepdim=True)[1]
correct += pred.eq(target.data.view_as(pred)).cpu().sum().item()
test_loss /= len(test_loader.dataset)
accuracy = 100. * correct / len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
accuracy))
在全连接网络上训练与测试:
perm = torch.randperm(784)
n_hidden = 8 # number of hidden units
model_fnn = FC2Layer(input_size, n_hidden, output_size)
model_fnn.to(device)
optimizer = optim.SGD(model_fnn.parameters(), lr=0.01, momentum=0.5)
print('Number of parameters: {}'.format(get_n_params(model_fnn)))
train_perm(model_fnn, perm)
test_perm(model_fnn, perm)
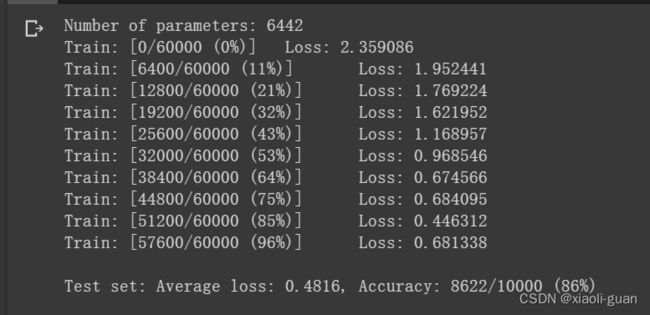
测试集:平均损失:0.4816,准确率:8622/10000 (86%)
在卷积神经网络上训练与测试:
perm = torch.randperm(784)
n_features = 6 # number of feature maps
model_cnn = CNN(input_size, n_features, output_size)
model_cnn.to(device)
optimizer = optim.SGD(model_cnn.parameters(), lr=0.01, momentum=0.5)
print('Number of parameters: {}'.format(get_n_params(model_cnn)))
train_perm(model_cnn, perm)
test_perm(model_cnn, perm)

测试集:平均损失:0.5281,准确率:8348/10000 (83%)
从打乱像素顺序的实验结果来看,全连接网络的性能基本上没有发生变化,但是 卷积神经网络的性能明显下降。
2、CIFAR10 数据集分类
——使用 CNN 对 CIFAR10 数据集进行分类
首先,加载并归一化 CIFAR10 使用 torchvision 。torchvision 数据集的输出是范围在[0,1]之间的 PILImage,我们将他们转换成归一化范围为[-1,1]之间的张量 Tensors。
import torch
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
# 使用GPU训练,可以在菜单 "代码执行工具" -> "更改运行时类型" 里进行设置
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# 注意下面代码中:训练的 shuffle 是 True,测试的 shuffle 是 false
# 训练时可以打乱顺序增加多样性,测试是没有必要
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64,
shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=8,
shuffle=False, num_workers=2)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
下面展示 CIFAR10 里面的一些图片
def imshow(img):
plt.figure(figsize=(8,8))
img = img / 2 + 0.5 # 转换到 [0,1] 之间
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
# 得到一组图像
images, labels = iter(trainloader).next()
# 展示图像
imshow(torchvision.utils.make_grid(images))
# 展示第一行图像的标签
for j in range(8):
print(classes[labels[j]])

接下来定义网络,损失函数和优化器:
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
# 网络放到GPU上
net = Net().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.001)
训练网络:
for epoch in range(10): # 重复多轮训练
for i, (inputs, labels) in enumerate(trainloader):
inputs = inputs.to(device)
labels = labels.to(device)
# 优化器梯度归零
optimizer.zero_grad()
# 正向传播 + 反向传播 + 优化
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 输出统计信息
if i % 100 == 0:
print('Epoch: %d Minibatch: %5d loss: %.3f' %(epoch + 1, i + 1, loss.item()))
print('Finished Training')

现在我们从测试集中取出8张图片:
# 得到一组图像
images, labels = iter(testloader).next()
# 展示图像
imshow(torchvision.utils.make_grid(images))
# 展示图像的标签
for j in range(8):
print(classes[labels[j]])
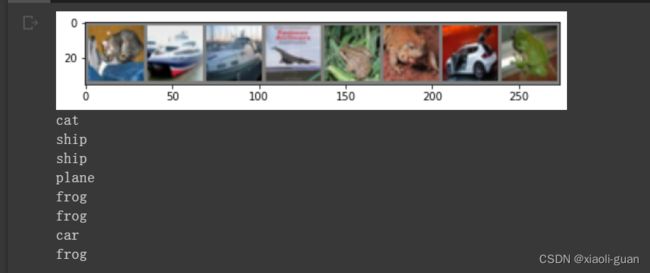
我们把图片输入模型,看看CNN把这些图片识别成什么:
outputs = net(images.to(device))
_, predicted = torch.max(outputs, 1)
# 展示预测的结果
for j in range(8):
print(classes[predicted[j]])

可以看到,第1、3、5、7识别错误了。
接下来查看整个数据集的识别率
correct = 0
total = 0
for data in testloader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' % (
100 * correct / total))

准确率在63%左右。
3、使用 VGG16 对 CIFAR10 分类
(1)定义 dataloader
import torch
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
# 使用GPU训练,可以在菜单 "代码执行工具" -> "更改运行时类型" 里进行设置
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform_train)
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform_test)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=128, shuffle=True, num_workers=2)
testloader = torch.utils.data.DataLoader(testset, batch_size=128, shuffle=False, num_workers=2)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
(2) VGG 网络定义
下面是模型的实现代码:
(这里老师埋了两个坑,一、直接运行老师的代码会显示第5行cfg未命名,只需要将第5行的参数cfg改为self.cfg即可
二、如果第6行的第一个参数是2048.那么训练时也会报错,因为两个矩阵的行列不匹配,将其修改为512即可)
class VGG(nn.Module):
def __init__(self):
super(VGG, self).__init__()
self.cfg = [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M']
self.features = self._make_layers(self.cfg)
self.classifier = nn.Linear(512, 10)
def forward(self, x):
out = self.features(x)
out = out.view(out.size(0), -1)
out = self.classifier(out)
return out
def _make_layers(self, cfg):
layers = []
in_channels = 3
for x in cfg:
if x == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
layers += [nn.Conv2d(in_channels, x, kernel_size=3, padding=1),
nn.BatchNorm2d(x),
nn.ReLU(inplace=True)]
in_channels = x
layers += [nn.AvgPool2d(kernel_size=1, stride=1)]
return nn.Sequential(*layers)
初始化网络,根据实际需要,修改分类层。因为 tiny-imagenet 是对200类图像分类,这里把输出修改为200。
# 网络放到GPU上
net = VGG().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.001)
(3)网络训练
for epoch in range(10): # 重复多轮训练
for i, (inputs, labels) in enumerate(trainloader):
inputs = inputs.to(device)
labels = labels.to(device)
# 优化器梯度归零
optimizer.zero_grad()
# 正向传播 + 反向传播 + 优化
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 输出统计信息
if i % 100 == 0:
print('Epoch: %d Minibatch: %5d loss: %.3f' %(epoch + 1, i + 1, loss.item()))
print('Finished Training')
结果如下:

(4) 测试验证准确率
correct = 0
total = 0
for data in testloader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %.2f %%' % (
100 * correct / total))

准确率83%左右。可以看出,与CIFAR10相比有了显著提升。
三、问题思考
1、dataloader 里面 shuffle 取不同值有什么区别?
shuffle在机器学习与深度学习中代表的意思是将训练模型的数据集进行打乱的操作。当shuffle=true时,会对数据进行重新排序,打乱其顺序;当shuffle=false时,则不打乱数据。通过修改shuffle的取值可以实现数据的重排序。
2、transform 里,取了不同值,这个有什么区别?
transform顾名思义就是转化,比较常见的就是
transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))这里的参数就是均值,方差,主要就是将image改为tensor形式
再比如,
transforms.Compose()作用主要是读取CIFAR10数据集时进行归一化操作并转换图像值;
transforms.Normalize()则是通过平均值和标准差来标准化一个tensor图像;
transforms.Compose的作用是将若干个变换组合在一起。
3、epoch 和 batch 的区别?
batch用于定义在更新内部模型参数之前要处理的样本数,其大小为模型更新前的样本数,并且小于或等于训练数据集中的样本总数。
epoch定义了学习算法在整个训练数据集中的工作次数。此外epoch由若干个batch组成。
4、1x1的卷积和 FC 有什么区别?主要起什么作用?
1x1的卷积本质是进行一种特殊的卷积运算,主要是将数据不改变宽高,而改变通道数量,可以起到降维的作用。与FC相比,1x1卷积能实现权值共享,参数量较同等功能的fc层相比少,使用了位置信息,并且fc层对于训练样本要求统一尺寸,但是1x1的卷积不受这种规定的限制。即1x1的卷积核是输入map大小不固定的;而FC是固定的。
FC多用于卷积神经网络的输出,在整个卷积神经网络中起到“分类器”的作用。而1x1卷积可以增加或减少特征图的层数,也可以用在多处进行增维降维。
5、residual leanring 为什么能够提升准确率?
使用residual leanring可以加深网络层数,其支路设计时,会加上其自己本身,形成了Y=F(x)+x的结构,这样使得梯度的值不会为0,解决了梯度消失的问题,从而提高了准确率。
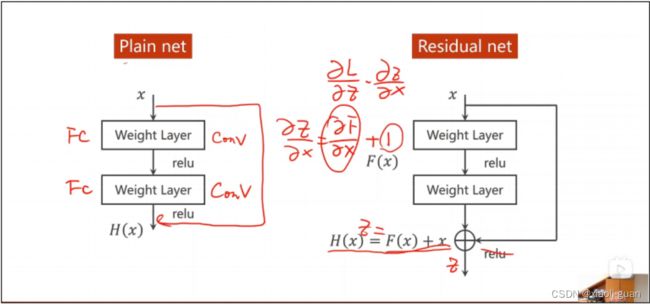
如图正常来说,有些梯度算过去后,会非常的小,比如0.001,这时候再乘上学习率,再相减,你的参
数基本不会得到什么改变。
而多加了一个x后我们看到后面加了一个常数1,这时候就相当于让我们对参数的更新幅度变大一些。
或者你可以更狠一点,全都连接一遍!
6、代码练习二里,网络和1989年 Lecun 提出的 LeNet 有什么区别?
Lenet是一个 7 层的神经网络,包含 3 个卷积层,2 个池化层,1 个全连接层。其中所有卷积层的所有
卷积核都为 5x5,步长 strid=1,池化方法都为全局 pooling,激活函数为 Sigmoid。
代码练习二中使用的是最大池化和ReLU激活函数,而LeNet使用的是平均池化,激活函数是sigmoid。
7、代码练习二里,卷积以后feature map 尺寸会变小,如何应用 Residual Learning?
使用1x1的卷积来改变改变feature map的尺寸,最终使其一致。
8、有什么方法可以进一步提升准确率?
增大数据集,使用更多的数据进行模拟训练
改变训练模型,使用更高效的模型
添加Dropout操作,多尝试不同的网络结构,适当调节层数尝试不同的激活函数
这里贴一个组员的问题思考,比较详细
https://blog.csdn.net/ekkoalex/article/details/127340880