RACV2022观点集锦 | 视觉基础模型
来源:https://mp.weixin.qq.com/s/pAbMI-qwdCY7-9SeMxDlFw
“本文得到CCF-CV专委会(公众号: CCF计算机视觉专委会)授权发布”
视觉基础模型(Vision Foundation Model)是当前计算机视觉领域最为火热的研究方向之一。在视觉领域,获取大量标注数据是非常昂贵的。我们可以通过借助无标注数据、图文数据或者多模态数据等,采用对比学习、掩码重建等学习方式预训练得到视觉基础模型,用于许多视觉下游任务,如物体检测、语义分割等。虽然现有方法已经表现不俗,但视觉基础模型仍有许多共同关注的问题值得进一步探索,包括如何更好地利用图文数据、未来视觉基础模型会如何发展等。我们在RACV 2022组织了“视觉基础模型”专题论坛,邀请到王井东、王兴刚、谢凌曦以及黄高四位专家做了专题进展报告,同与会的40余位国内专家一道就多个相关话题进行了深入研讨。
**专题组织者:**王井东(百度)、程明明(南开大学)、侯淇彬(南开大学)
**讨论时间:**2022年8月10日
**发言嘉宾:**王井东、王兴刚、谢凌曦、黄高
参与讨论嘉宾【按发言顺序】:王井东、谢凌曦、程明明、武智融、金连文、沈春华、虞晶怡、郑伟诗、吴小俊、张磊、毋立芳、王兴刚、夏勇、高阳、贾旭、王鹤、王涛、马占宇、卢湖川、鲁继文、于剑、査红彬、丁凯、弋力
**文字整理:**侯淇彬

各位老师好,非常高兴来参加今年的RACV。本次的专题是视觉基础模型,英文叫Vision Foundation Model,咱们有时候也叫大模型。


很多视觉任务,从应用的角度来讲,是需要视觉基础模型的。为什么这么讲?大家一直苦恼的问题是说能不能给我更多的标注数据,尤其是识别。传统上我们通常认为(标注)数据越多识别效果越好,但事实上我们很难去获得非常大量的标注数据,主要原因不在于技术上,而是很高代价去获得这些标注数据。
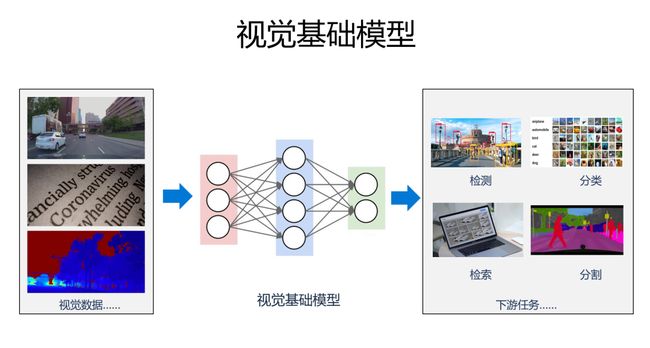
最近一两年,大家觉得从预训练模型角度来讲,是不是可以帮助这些下游任务。预训练最近几年在NLP里面提的非常的多。很多人觉得视觉里面这个基础模型不如NLP发展的显著。其实这个事情要换个角度看看,视觉里从13年的RCNN开始,实际上已经在应用预训练模型。要在这个基础上进一步提高,实际上是具有挑战的事情。现在,我们希望通过大量数据,不管是有标注的或者图文数据,训练一个网络,能够非常容易地应用在一些下游任务里面,通过非常简单的方法,这是我们希望看到的事情。

我自己也有一些简单的认识,也希望大家能给我一些建议。关于视觉基础模型,包含了很多维度,这里面列了5个具有代表性的。第一个需要有大量的数据,没有数据,我们的模型再漂亮再强,其实很难体现它的效果。第二个,大模型的参数量大,可以用能力来挖掘数据里面的知识。第三点,就是我们希望有一个所谓的大一统的方案出来去解决各种各样的任务。另外就是大算法,其实不是说简单的大数据,大模型就可以了,其实算法还是非常重要,如果仅仅靠大量数据,那这个事情就纯变成一个依赖算力的事情了。最后一点就是大算力。

我们谈到视觉基础模型,其实需要学的东西非常多,那最近大家关注更多的是表征训练。其实谈到这个视觉表征训练,目前主要有两大类。一个是图文相关的,比如说OpenAI的CLIP,张磊老师原来在微软的团队做的Florence等等,这些数据都是互联网上非常容易获得的。另外一大类是自监督学习。其实这里面我一直在思考,视觉语言训练出来的表征其实是比较强的,那些语言可能是有一点noise甚至可能是错误的或者不全的,但他确实能够训练出来强的模型。在大量的数据下,跟有监督的很类似,表征学的很好。自监督,除了图像其实啥都没给,怎么能够学到很好表征。因为没有给这个所谓的这个语言监督,也没有给标签,这个时候所谓的语义表征实际上是说在表征空间里面的不同语义的物体表征能够聚集在一起。
视觉语言看上去非常好,确实它的表征会比之前的会好一些,但是我们还需不需要自监督学习?其实我们真正去应用这样一个视觉基础模型和预训练模型的时候,在很多领域里面可能没有图文里的文本信息。这里面举一个例子,比如OCR,大家可以想象OCR图像所给的文字语言信息可能会是什么?可能说这个图关于文档的,它不会具体到说里面的文字究竟是什么,对吧?
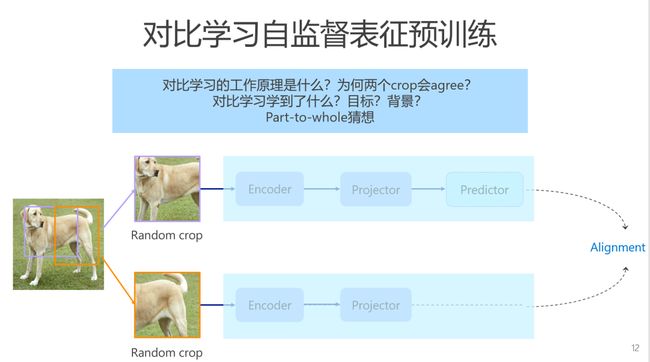
之前的自监督方法主要是基于对比学习的。从去年开始掩码图像建模在视觉里受到大家的关注越来越多,今年上半年已经有非常多的相关工作。就是说它给同样一个View,然后把一些patch的给mask掉,希望用剩余的patch预测masked的patch。关于对比学习,我目前一直没看到它为什么会work。我大概一两个月之前跟一位同行讨论这个问题,他有个文章里面做了这么一件事情,就把encoder的表征跟projector的表征去做相似patch的搜索。他发现encoder拿出来特征的part信息非常好,比如说我们查询一个狗的脑袋,用encoder特征去搜索,出来的基本都是狗的脑袋,但是projector出来的结果就比较乱,但基本上还是狗。对比学习里预训练的任务是什么?其实不是很明确,或许是通过projector实现part-to-whole任务。

关于掩码建模,我也在思考它究竟怎么work的。对比预训练主要学了中间物体的信息,相比较,掩码图像建模学到了图像里目标和背景信息。我猜想,掩码图像建模是part-to-part的任务。
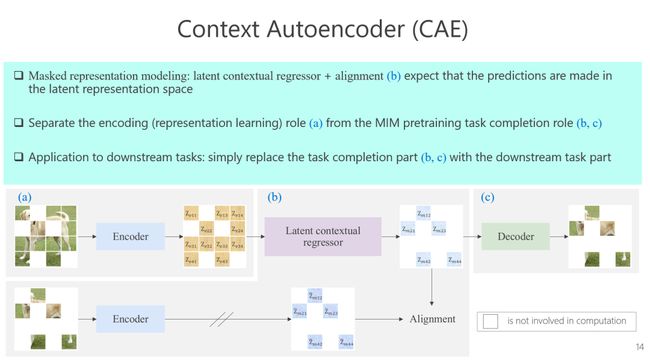
这里我也简单介绍一下我们的工作以及它跟几个相关的MIM的方法的对比。我们方法首先去抽取可见patch的特征,抽取的时候只把可见patch数据输入到encoder里面去,这意味着我们看到的是没有mask部分的信息,然后我们的目的是用可见的patch猜测mask的部分,但这还是不够的,我们下面加了一个alignment分支,使得MIM任务在表征空间里完成。最近我们发现在深度学习里面,其实很多方法都是在表征空间里面做,比如DALL·E 2我认为在表征空间里面,如果说我们把任务解决得很好的话,那有可能学到的表征都非常好,所以希望regressor出来的表征也是在encoder的表征空间里的。
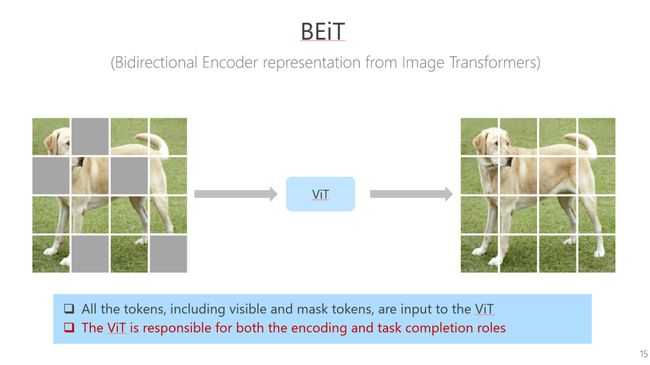
BEiT在干什么?masked图像经过一个ViT网络结构,然后经过linear层直接得到最后的重建图像。这个ViT既要学习表征,同时也能解决预训练任务。解决预训练任务本身学到的知识,对我们下游任务不见得有多大帮助,但是BEiT里面是混合在一起的,所以我认为这个方案学到的表征不见得那么好。
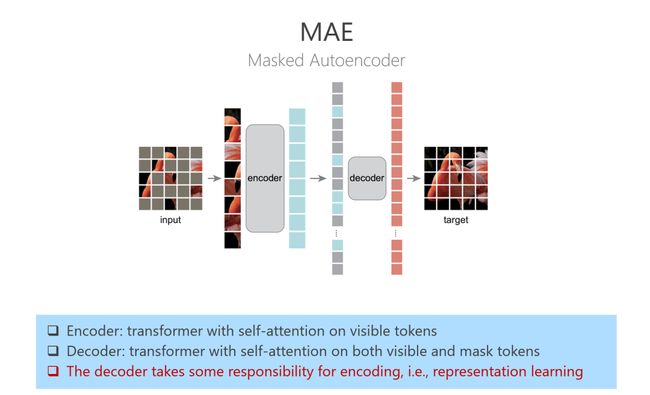
下面这个MAE的工作,只看decoder那部分跟BEiT很像,只不过前面加了一个encoder。实验证明了它结果非常好。从我的角度来看,MAE也是要把预训练任务跟encoder分离开,这个情况下其实不能保证decoder是只做重建任务。这个所谓的decoder可能也会学可见patch的表征,前面encoder的能力就会被削弱。我认为,预训练任务一定要和encoder分开,不能混在一起,希望就刚才讲的要在表征空间里去做预测。下图是比较的总结。


与MIM对比,对比学习一般把中间的物体学得很好,它highlight的基本是中间的物体。然后MIM的方法会把整个区域都highlight出来,换句话讲整个图像的信息都会学得非常的不错。

各位老师早上好,非常荣幸有这个机会来汇报一下关于视觉基础模型的一些理解。

在NLP里面,像Bert这种被认为是基础模型,但视觉里面什么是基础模型,其实至今我觉得是没有一个很明确的定义。所以我这里引用了一个斯坦福学者在去年的时候写了一个综述,On the opportunities and risks of foundation models里面的一个定义。在这个定义中,我们希望能够把所有多模态数据汇聚起来一起来学习,然后能够适应到很多的下游任务。
它有两个很重要的特性,一个叫Emergence,另外一个叫homogenization。这两个词我觉得我们可能需要去理解一下,它有两个中文的翻译,我也是参考其他的翻译但不一定准确。第一个就是涌现。涌现就是说我们希望学习形式是隐式的,而不是非常直接去显示学习。比如我们需要去做目标检测,我们希望学了一部分类别,然后对其他所有的物体都能够去检测。再比如,现在的一些视觉模型,训练阶段是一个分类的模型,最后能够做分割,能够对定位很有作用,这就是一种隐式学习,这样的话才能够去为更多的任务提供支撑。另外一个就是同质化,同质化主要意思是一种牵一发而动全身的特性,基础模型改变了,其实对所有的下游任务都会有影响。现在来讲,大部分的基础模型学习的技术手段基本上都是非常大规模的自监督学习。
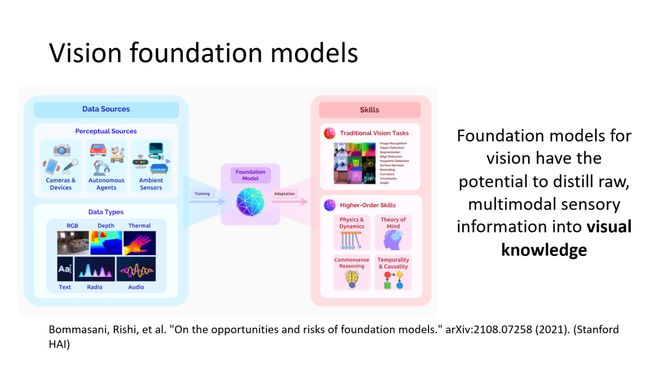
同样在斯坦福HAI的技术报告里面,我们可以看到它对视觉的基础模型也做了一个描述,左边是多模态数据,经过训练,得到一个基础模型能够用于检测分割、三维重建、常识推理等各种下游任务中,因此我们对视觉基础模型的期待是非常大的。其中核心要做的事是希望能够把多模态的数据通过学习之后能够变成视觉knowledge,当然这是个非常困难的远景。
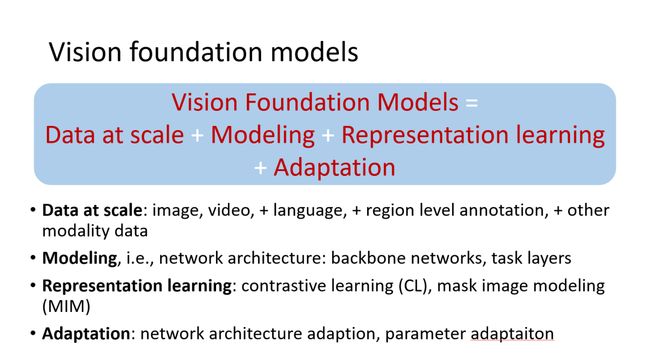
这我个人有一点点理解,我做了一个不是特别准确的公式,我认为视觉基础模型它包括第一个就是做大规模的数据,这个数据可以包括图像视频、语言,也可以加上其他模态的数据。如果说我们数据变得更多,结果应该会变得更好。第二个就是建模,其实主要指的是网络框架。第三个就是表征学习。最后第四点是adaptation,就是说能够去适应到下游。
就建模而言,其实我们有很多很多的探索以及成功的经验,比如说去年得马尔奖的Swin Transformer,RepLKNet和HorNet。
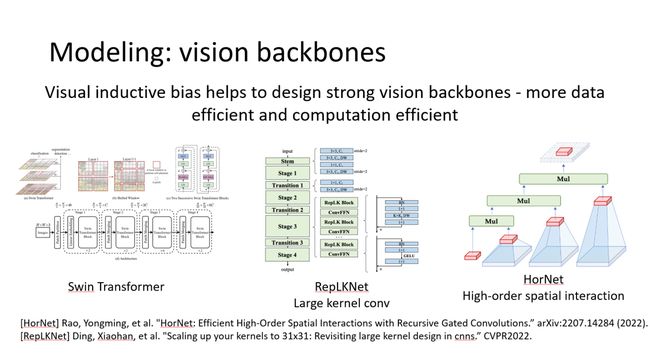
在数据限定、计算限定情况下,他们表现非常好,相对于朴素ViT,他们具有更好的数据效率和计算效率。然而,最朴素的ViT这个架构其实也是非常好的。

我看可以参照推特上的一个图。ViT这种最朴素的模型其实也有非常好的可扩展性,这里我引用了一个Google最近写的Survey,它做了很多的实验。第一个结论就是不能在朴素的ViT上面加太多inductive bias。加上inductive bias可能在特定数据上表现非常好,但是它的可扩展性是有伤害的。第二个就是说不同模型架构可扩展性不一样。第三点base模型可能表现很好,如果我们把它变到large或者huge上面,它这个提升并没有(base、large、huge对应的是模型的参数量)。总的来说,朴素ViT其实是一个很好的选择。

在这个task layer层面上,最近也有很好的工作,比如说mask2former以及Unicorn。他们核心点在于query加self-attention,目的是把一些任务做到统一。所以我们可以总结朴素的注意力机制在backbone和task layer上的表现都是非常好的。
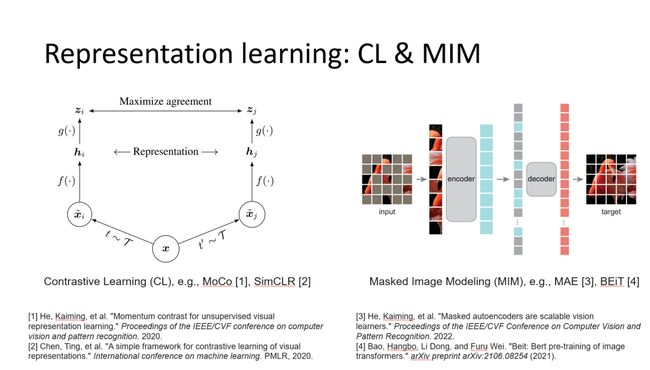
对于表征,现在主要有两大核心的思路,第一个对比学习,另外一个是MIM(视觉掩码建模)。最近有一些工作表明这两大表征其实可以同时用,发现两个表征其实是有很好的互补性。二者结合的好处可能是对比学习具有可区分性,MIM可以得到很好的泛化性能,二者的好处能够得到结合。
那Vision理解其实我们不应该局限于图像的分类,更多的其实我们希望能够走向检测分割甚至三维理解,甚至是更高级的任务。
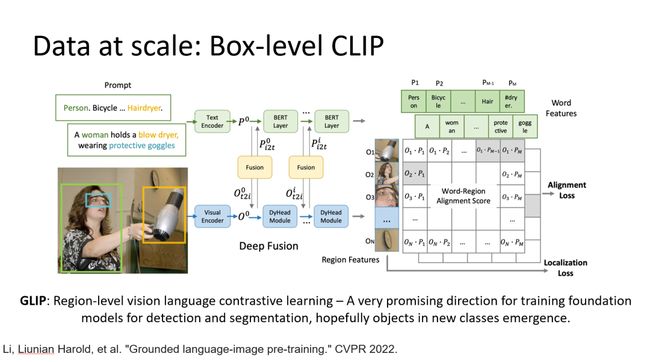
最近微软有一个工作叫GLIP,它其实做box-level的对比学习。说对于每个box它都有一个文本表示,然后用CLIP的形式去对每一个box学习。通过收集很多有具有box-text的标注数据能够训练得到一个很好的模型,它能够去做开放环境中的检测。我个人认为这其实是对视觉基础模型的一个很好的探索。希望它能够去识别出一些新的类别——这些新的物体没有被学过,但能够被检测出来。

还有一个工作叫Detic,它其实是用传统检测器把box supervision和class supervision做一个结合,对于很多没有box训练过的类别,也能够得到非常准确的检测。这是一种通过这种混合的监督来扩大数据规模,同时能够检测出一些新的类别的有效的技术手段。
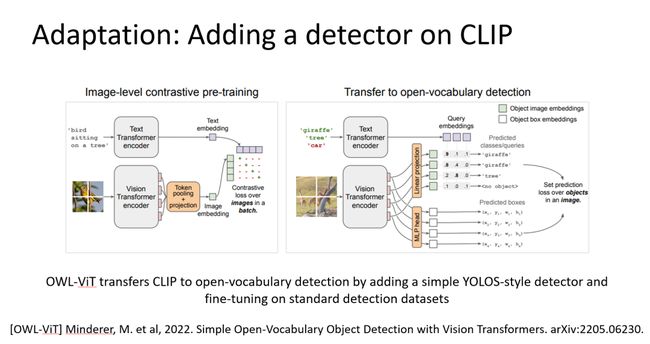
最后讲一下关于adaptation的进展,比如最近一个工作做开放场景目标检测,它是把左边这个标准clip加了一个检测的头(类似我们的NeurIPS 2021工作YOLOS方法的检测头),用检测头输出的box与对应的文本做对比学习,它能够将clip做很小的改动,从而实现开放场景的目标检测,所以这也体现了adaptation的优势。

那关于MIM的adaptation,何凯明他们自己也做了一些工作,ViTDet,它的一个核心思路其实说在一个朴素ViT上面加一些window和global的attention,然后在这个backbone基础上拉出4层feature,这样的检测结果也是非常好的。

我这里讲一点点我们在adaptation上面的一个工作,MiMDet。不同于ViTDet,我们不采用window attention,而是下游检测分割任务中只取一部分patch输入到ViT重,得到的是一个可以高效计算的架构,并且能够缩小上游预训练和下游adaption之间的距离。这样一个架构在底层加一点点conv可以得到多尺度的表征,最终可以得到很好的检测分割结果。

最后简单总结一下,视觉基础模型最重要其实还是它是可扩展的。如果说它只在一个有限的数据集上表现很好而没有去验证它在大规模数据上的可扩展性,其实还是不够的。另外就是下游任务应该也是可以扩展的,应该不局限于分类这样一个下游任务。第二点是说朴素的ViT其实都是非常好的,它能够非常灵活去unify很多任务。然后表征学习层面上,对比学习和MIM某种程度上可能是互补的。最后就是adaptation层面上,其实是可以做得很高效,去解决一些当前的任务。

个人认为未来可能有一些挑战,第一个就是对MIM的理解,现在有一些文章表现说MIM可能没有数据扩展性,但是这个可能还是存疑的。另外一个就是说当图像复杂时,怎么去做区域和文本描述的对齐,所以弱监督的表征学习非常重要。另外一个就是跨模态的表征学习,当前的对比学习和MIM如何适应跨模态数据,或者说在跨模态框架下有何种更好的表征学习形式。我认为视觉基础模型的发展其实是一个大工程,也是希望国内计算机领域共同努力去突破包括计算瓶颈在内的一系列问题,谢谢。

各位老师大家上午好,非常高兴今天能够有这个机会向大家分享我们最新的一些研究以及心得体会,我今天报告的题目是《走向无线细粒度的按需视觉识别》。

我的报告主要分为两个部分。第一部分我会介绍什么是视觉识别中的无限细粒度问题,以及为什么现有的视觉识别算法无法做到无限细粒度。第二部分,我会讲讲我们自己最近的一个研究提议,也就是按需视觉识别,以及为什么我们这个提议能够走向无限细粒度。我讲的内容跟前面两位老师可能是互补的,因为比起预训练和模型设计,我更关注当前的视觉识别算法在下游任务上能不能达到完整识别的目标。

先从背景说起。视觉识别是计算机视觉中最本质的问题之一,我今天要讨论的问题,是当前的视觉识别算法能不能做到“完整”的视觉识别。“完整”的意思就是我们能够从一段视频或一张图像中识别出所有能够识别的东西。我们这里引出一个“无限细粒度”的概念:人类只要愿意,他就可以从图像或者视频当中识别出任意精细程度的语义。显然,当前计算机视觉的标注系统和算法都做不到这一点。

比如我们看一张普通的街景图片,它来源于ADE20K数据集。虽然数据集的作者在街景图片中标注了很多东西,如人、车、道路、建筑物、天空等,对于人、车、建筑物,它还力所能及地标注了一些part,但是很显然还有很多没标出来的视觉信息。我分类列举未标注信息的例子。第一类是一些细粒度的分类,比如这个人的性别是什么、这个车的型号是什么,等等。第二类是将某些part划分为更精细的part,比如说他们虽然把人分成了头、躯干、四肢,但是我们显然可以对头进行更进一步的分割,成为眼睛、鼻子、嘴巴,甚至在分出眼睛以后还能继续分出眼球、睫毛和瞳孔。第三,可以往这个数据库里面加入一些它没有学过的概念,比如说这个人身上有个手提包,它没有标出来。第四,我们还可以标注一些属性类的信息,比如说这个人的衣服是什么颜色、这辆车是什么颜色、马路上有没有积水,等等。能够标注的语义信息几乎是无穷无尽的。
既然如此,为什么已有数据集没有标注这些信息呢?主要原因是,随着标注粒度的不断上升,会产生很多新的问题。我们把这些问题归纳为两点。第一点叫做缺乏一致性。比如在这个街景图上有很多行人。如果这个人分辨率很大,我们可以看得很清楚,进而去标注他的头、躯干、四肢;但是对于大部分分辨率很小的人,我们甚至无法把他的整体轮廓准确地标注出来。也就是说,不同个体的可标注粒度可能有很大不同,但是当前的系统都不能支持这一点。第二个是可扩展性。系统必须能够支持我们方便地引入新的语义概念,不管是新的part还是新的类别,但是现有的方法都多少有些困难:要么在加入新概念以后,必须把整个数据集再扫一遍,看看以前有没有漏标这个东西;要么必须引入诸如增量学习这样的方法——总的来讲引入新概念的代价还是比较大的。

为了强化上述概念,我们调研已有方法如何增加视觉识别的粒度。我们主要把已有的方法分成两大类。第一类,我把它称之为基于分类的识别方法,它包含传统意义上的分类、检测、分割等一系列的问题,它们的共同特点就是要给图像中的每个视觉单元分配一个类别标签。这类方法比较容易定义,学习方法也很好设计,但它有一个非常明确的缺点,就是随着标注粒度的上升,它的确定性会不可避免地下降。这个冲突很好理解:举例说,我们很容易识别车这个概念,但是如果我要把它进一步细化成跑车这个概念,就会遇到很多情况,我们很难说清楚一辆车到底是不是跑车。这就意味着,当我们走向无限细粒度的时候,标注的确定性会成为很大的问题。那么人是怎么解决这个问题的?其实人并不需要非常显式或者说非常确定的分类能力,比如我去商店里面买辆车,我不会纠结于这辆车到底是不是跑车,只要这辆车的性能满足我的要求就可以了。这说明,人类不会永远追求最细的粒度,而是可以根据需求灵活地调整识别的粒度。这是我们得到的一个启发,后面会用到。

关于分割,情况也是很类似的。当我们通过分割instance和part等信息,把空间上的标注粒度不断加细,那么标注的确定性也一定会下降。典型的例子是,如果我们一定要把分辨率很小的个体划分出来,那么有可能一两个像素就会对分割精度造成很大的影响。这就是在空间上的不确定性,而刚才讲的分类问题对应于在语义上的不确定性。


第二类,我把它称为语言驱动的识别方法。这是一种用自然语言引导视觉识别的模式,在去年CLIP模型出现以后,这类方法有了长足的进步。它的基本思路很简单:通过语言的指代,将图像中的相应语义识别出来。这类方法确实增加了视觉识别的灵活性,也引入了重要的开放域能力,但是语言的指代粒度很有限,想要描述细粒度的识别任务很困难。以当前流行的视觉prompt为例,虽然我们可以通过a photo of something对于简单图像做分类,但是要通过类似的方法在复杂图像中指代一个特定的个体并对其进行分析,就非常困难。这说明,简单引入语言并不能解决问题,还需要将语言与视觉结合起来。

总结报告的前半部分,我们可以得出结论:当前的视觉识别算法还没有办法去实现无限细粒度的识别。但是这个问题非常重要,因为人类是有这种能力的,我们也希望算法能有这样的能力。根据上面的分析,我将走向无限细粒度的三个要点列举出来。第一是算法必须有开放域识别能力,而这种能力很可能由自然语言提供。第二点是识别任务需要指代明确,不能因为引入了自然语言,就把语言的不确定性和模糊性引入进来。第三点,也是今天最希望强调的一点,是识别算法必须具有可变的粒度,能够根据需求调整识别粒度。只有这三点都实现了,我们才能走向一个无限细粒度或者说任意细粒度的视觉识别。
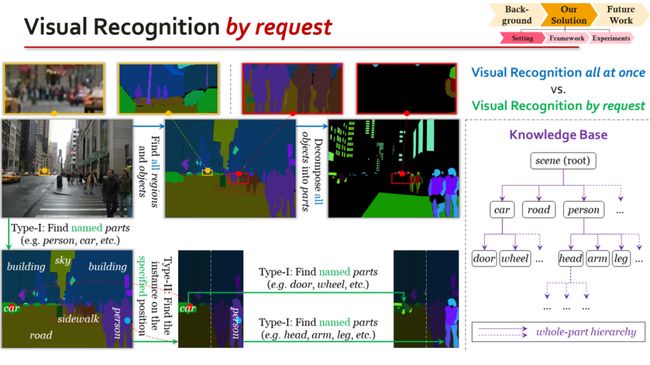
结合这三点,尤其是最后一点,我就提出了按需视觉识别的概念。按需视觉识别是跟传统意义上的一次性视觉识别或者统一视觉识别相对应的一个概念。什么叫统一视觉识别?就是标注者或者算法会事先拿到一个字典,字典中规定了所有要识别的视觉概念;每当他看到一张图片的时候,他就必须按照字典把其中规定的所有概念一个一个地识别出来。比如说这个字典当中规定了人和人的头部这两个概念,那么当他看到一张街景图片的时候,他就必须把这张街景当中所有人的头部都给识别出来。即使街景中有100个人,少识别1个人或者1个人的头部,都会被认为是不准确的识别。这样做,就会导致前面所说的问题。
而按需视觉识别不再要求这个识别要一次性完成,而是把识别任务分解成若干个request的形式。当前,我们定义的request有两类。第一类request,输入是一个instance,而输出是这个instance的所有part的semantic分割。一个instance具有的part,通过一个层次化的字典来定义,我把这个字典称为知识库。比如,字典里有车的概念,当我们需要将一辆车分成part的时候,就会去查这个字典,然后得知这个车要分成车门、车轮、车架子等part,并根据这些信息完成分割任务。第二类request,输入是一个semantic区域(可能包含很多instance)和这个区域里的一个像素位置,输出是这个pixel所对应的那一个instance,将它从semantic区域中分离出来。也就是说,第一类request是从instance到semantic的分割问题,而第二类request是从semantic到instance的分割问题。它们是互补的,我们只要将它们反复组合、反复迭代,就可以以任意的粒度去分割这张图。这里要强调的是,第一类request的输出必须是semantic而不是instance,因为instance可能有很多,如果直接要求把每个instance都识别出来,就违背了按需识别的思想。为了得到instance,必须再次调用第二类request,把那些感兴趣的instance识别出来。

这是一个典型的标注过程。和传统的setting相比,按需识别的最大优势在于,我们可以在任何一个步骤上停下来,而不影响标注的准确性。也就是说,对于每张图来说,标注可能不完整,但是标注永远保证精确。例如一张街景图片上有100个人,我只用标注其中一两个人,也完全不影响后续的识别和评估算法,因为标注、识别和评估都是以request为基本单位进行的。虽然每张图标注的信息都不完整,但是算法总可以从不同的图像中学习各种信息并且把它们整合起来。换句话说,我们追求从整体数据集中学习到无限细粒度的语义,但是并不要求在所有的instance上都去实现无限细粒度。这是一个非常重要的性质,只有这样才能解决粒度和不确定性之间的冲突。
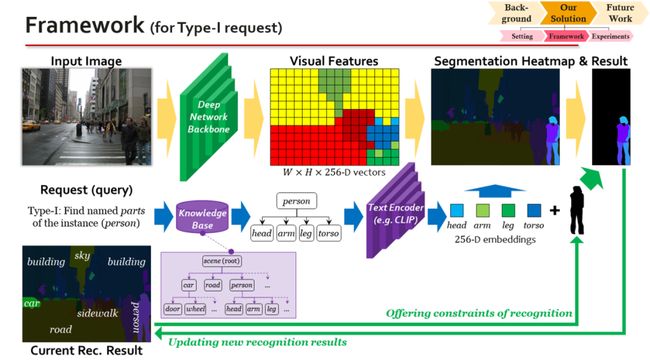
如果大家能接受上述想法,包括我们的setting,那么我今天最重要的内容就已经讲完了。至于后面怎么去实现这个 setting,反倒是一些细节性的事情,其实并不是非常重要。简单地说,任何一个能够结合语言和视觉的算法,都可以做到这件事情。我们的示意图也很直观:算法抽取视觉特征和文本特征,然后把两组特征结合在一起,就可以了。

我们在两个数据集上进行了实验。第一个数据集叫做CPP,它是一个标注相对完整的数据集。另一个是ADE20K,这个数据集有很多语义概念和很多part,但是它的part标注非常稀疏、非常不完整,所以之前从来没有任何方法能够在这个数据集上量化地对part分割结果进行评估。而我们提出的setting,因为天生适应不完整的标注,所以也第一次在ADE20K数据集上报告了带有part的量化分割精度。

为了计算按需识别的精度,我们扩展了全景分割的PQ指标,使得它能够评估层次化、不断细分的分割结果。这个新的指标称为Hierarchical PQ。
在CPP数据集上,我们用合理的baseline,得到的HPQ大约是50-60%。然而在ADE20K数据集上,相同的方法只能做到30%左右的HPQ。可以想象,如果把ADE20K标注得更完整,特别是把比较困难的语义都标注出来,这个HPQ值还会继续下降。也就是说,相比于传统的语义分割和实例分割,按需识别的提升空间更大。这也说明,在追求无限细粒度识别的过程中,我们会遇到很多之前没有遇到的困难。

最后展示一些可视化的分割结果。可以看出,我们的方法能够学会一些标注得很少的part的概念,而并不需要用到任何复杂的学习技巧。
作为最后的总结,我今天的报告提出了计算机视觉中的无限细粒度问题,以及为了达到这个目标,必须满足的三个条件:开放性、特异性和可变粒度。而基于可变粒度的思想,我们提出了按需视觉识别的方法。在未来,我们提出的按需视觉识别还有很多工作要做,由于时间关系我没法仔细讲。我觉得这个方向是非常重要的,期待与各位共同探讨这个问题。

非常高兴也很荣幸能够再一次来到RACV作引导发言。今天我将从视觉基础模型的结构和学习方法两方面分享自己的一点思考。抛出的观点不一定很成熟,希望能跟各位老师探讨和交流。
关于模型结构,我认为可以分为微观结构和宏观结构分别来讨论。
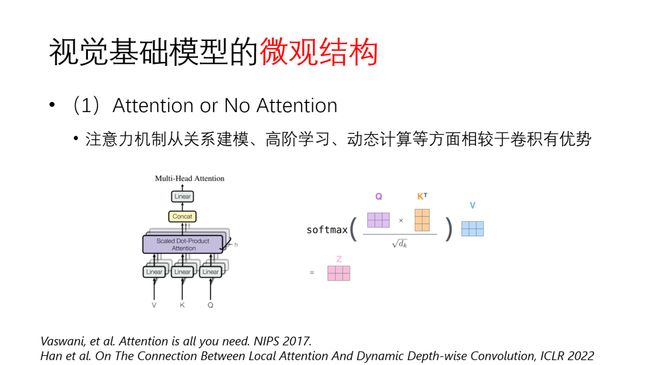
首先在微观结构方面,这两年探讨得比较多的就是attention。到底要不要用attention,目前在NLP领域基本上是形成共识了,在视觉领域,我认为attention也是一个非常可取的微观设计。
它的优势主要体现在三个方面:第一是关系建模能力,即能够有效建模图像不同区域之间、视频不同时间节点之间的关系,尤其是对全局关系的学习和长程建模能力优于常用的卷积算子;第二是高阶学习能力。神经网络本质上是一个关于输入x的函数,它关于x始终是一个一阶函数。但是引入attention之后,由于Q和K之间的乘法运算,关于输入x就至少是一个二阶函数。高阶计算在表征能力上更强,因此我们可以看到基于attention的结构在大数据集上有更强的scalability。第三是动态计算的能力。由于attention值是基于每个输入样本计算的,即data dependent,因此attention可以理解成一种动态计算。从这个角度,基于attention的网络在表征能力和计算效率方面也有突出的优势。
因此,从以上多个角度来看,attention所具备的优势都是视觉领域所需要的。

接下来,Transformer和CNN两种网络结构的对比是这两年讨论得非常激烈的一个话题。需要注意的是,Transformer与CNN的对比,并不等同于有attention和无attention的对比。因为Transformer和CNN通常是指一个完整的网络结构,它们之间的差异不仅体现在有无attention,还包括很多其他的宏观和微观上设计的不同,这些因素都会影响模型的性能。目前视觉Transformer系列包括ViT、Swin Transformer、PVT等,最新的CNN结构包括ConvNeXt、Large Kernel CNN等。
从当前已公开论文的结果来看,在ImageNet及以下规模的数据集上,这两个模型孰强孰弱的争论还在继续。但是在更大的数据集上,我们看到的是具有attention机制的Transformer结构似乎有更好的scalability。
当然,我们在对比Transformer、CNN这两大类模型的时候需要特别的谨慎,因为虽然从名字上看迥然不同,但两者实际上有许多相通和可以相互借鉴之处。许多结构设计并不一定专属于Transformer或者CNN。简单的根据几个实验结果就断言这个结构好、那个结构不好并不是很严谨。今年公开的ConvNeXt论文就揭示了通过合理选取卷积网络的kernel size、normalization layer、activation layer等,就可以将一个标准的CNN改造成与Swin Transformer性能相当的网络。与其去争论Transformer和CNN到底谁好,不如多去考虑如何各取所长,实现互补。CNN固有的inductive bias对图像低层特性学习是合理而且自然的,而Transformer在关系建模上有突出的优势。实际上,基于融合CNN与Transformer优点的思想,产生了很多不错的工作,如CoAtNet、Container、TransCNN等。
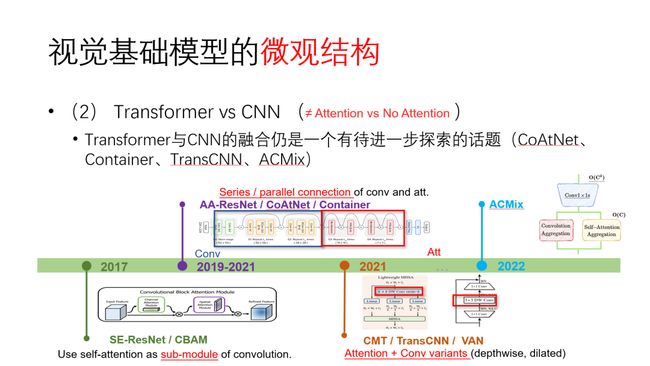
今年我们组在CVPR上发表的工作ACmix,就是在微观结构上去融合CNN和Transformer两种结构。我们发现,从计算的角度,两者实际上共享相同的“主干”,只是实现特征聚合的“头”不一样。基于这个观察,我们可以在已有CNN或者Transformer基础上,通过引入少量额外的计算量,就可以比较优雅地实现两者的融合,使网络具备彼此的优点。
这两年微观结构设计方面的进展还包括对大kernel卷积的重新审视。大kernel在下游任务上优势非常明显,而通过与depth-wise conv相结合,计算量并不会增加太多。
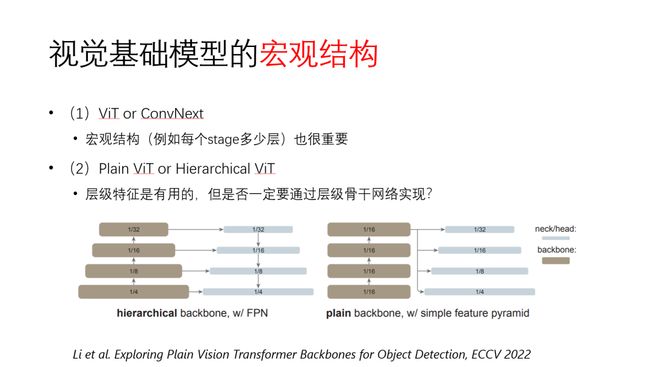
在宏观结构方面,我们还需要继续讨论 Transformer和CNN,因为宏观结构设计对两者性能的影响也十分重要,比如说每个stage配置多少层,对结果影响非常显著。
此外,关于plain ViT和hierarchical ViT的讨论和比较也在继续。最早的plain ViT和DEiT都是保持主干网络特征图尺寸不变,而Swin Transformer和PVT则采用的是特征金字塔结构,从而使得以前为CNN设计的结构可以直接进行借鉴,尤其是更加容易适配下游任务,因此在最近受到广泛关注和使用。不过最近研究发现其实plain ViT的结构即便在主干网络使用统一尺寸的特征图,也能通过后期对特征图进行下采样构造特征金字塔,并且在检测等下游任务上取得不错的效果。由于Plain ViT在设计上更为简洁,因此也具有较好的发展前景。关于到底哪一种结构更好,目前还未形成定论。
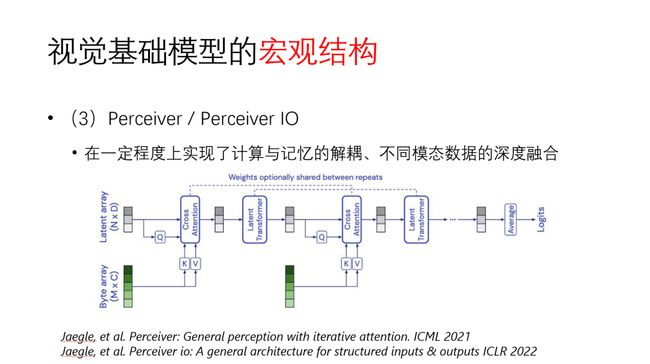
在宏观结构方面,DeepMind提出的Perceiver是这两年让人眼前一亮的网络结构。它和常见的CNN、Transformer结构很不一样,其主干的输入是一组latent array,不同模态的数据(图像、文本、语音)向量化之后与主干网络的latent array去做cross attention。因为Perceiver没有采用self attention,所以它的计算量不会随输入的维度平方增长。我认为这是一种很有创新性的结构,在一定程度上实现了记忆和计算的解耦。实际上,不管是CNN还是Transformer,网络所谓的记忆都是分布式的存在于模型参数中。网络参数同时承担计算的任务,也具有记忆的功能,两者是融合在一起的。而Perceiver的很多记忆是存在于latent array中,由于latent array是独立且显式存在的,这对于提升神经网络可解释性和迁移性是有帮助的。网络学习的过程可以理解为根据外界的输入信号,从网络的记忆中去做匹配或检索,整个过程变得容易被理解。Perceiver结构在一些特定的任务上取得很好的性能,虽然目前并没有跟CNN和Transformer在ImageNet等主流的数据上做直接对比,但我认为Perceiver为网络结构设计提供了一种新的、有价值的思路。
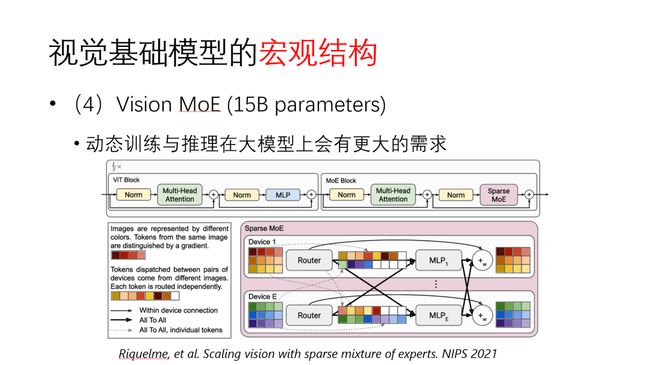
宏观结构方面另一个值得一提的是视觉大模型。目前最大的视觉模型之一是Vision MoE,有150亿参数。其核心思想是采用混合专家模型(mixture of expert),这本质上是一种动态模型,可以让模型参数量很大而不至于计算量太多。Vision MoE在达到已有模型相近的准确率时,计算量能够缩减一半。我认为动态推理在大模型上有非常好的前景。在小模型上,动态计算可能会面临稀疏计算在GPU上实际计算低效的问题。但往大模型上走,碎片化的问题被大大缓解,动态训练和动态推理会有更大的潜力。

在深度模型的学习方法方面,不得不提的是自监督学习。刚才几位老师也都提到了,目前主要是两条路线。一类是对比学习,利用图像的不变性去构造contrastive loss; 另一类是基于掩码重构的方式。我个人认为这两类方法更多的是在学习低层的特征,由此得到的模型的浅层特征迁移性很好。但由于缺乏类别、物体整体性等信息,仅仅给模型喂大量的图像让它去做重构和对比学习,可能很难形成真正高层语义的理解。

上面提到的自监督学习是在只有图像的封闭集合上做训练,在整体性和高层语义的学习方面比较受限。最近两年关于多模态数据的自监督训练是我个人更感兴趣的一个方向。其中,视觉-语言预训练模型CLIP是一个非常重要的进展。我认为多模态预训练中最重要的要素是“互监督”,即利用不同模态数据的对应关系构造对齐损失。当文本信息与图像形成互监督时,语言就能够为图像识别任务提供丰富的语义信息,从而适应相对开放的场景。例如考虑分类任务,人工标注的类别始终是一个有限的集合,我们标识了1000类的数据,模型就只能识别1000类。当有了语言模型提供的丰富语义,视觉学习就能摆脱类别数量的局限。所以像CLIP这样的模型能够做非常好的零样本学习,碾压之前所有的方法。
但是原始的CLIP模型还有很多局限,仍然缺乏对视觉输入中物体结构的学习,并且依赖大量的图文对。但它证明了互监督学习的强大,极大地推动了多模态学习的研究。
最近一年来,多模态大模型发展十分迅速,例如Florence、女娲和悟道模型都是优秀的代表。其中,Florence是一个非常ambitious的模型,同时探究了多模态学习的三个维度:模态、时间和空间。Florence模型不止能做分类,同时可以做目标检测和分割等任务。不过美中不足的地方在于检测、分割等任务还依赖监督式训练。
我认为互监督多模态学习的未来,一方面会如Florence模型一样,统一更多的视觉任务;另一方面会像自监督学习那样,在预训练阶段摆脱对数据标注的依赖。正如Jitendra Malik所说的,标注数据是计算机视觉的鸦片。如果仍然依赖大量的人工数据标注,是很难训练出视觉通用基础模型的。
因此,我认为视觉基础模型研究中一个非常重要的方向是如何在多模态数据之间构造互监督学习损失,以一种不需要(或者只需要少量)人工标注的方式,实现大规模的预训练。人类的学习过程能够很好地综合图像、视频、文本、知识等诸多模态的信息,而当前基于深度学习的AI基础模型仍处在起步阶段,对多模态数据之间的互监督关系挖掘尚不充分,我们能做的事情还很多,机会也很多。
我们第一个议题是对比学习和掩码图像建模两种方法究竟学到的是什么?后者在下游任务上的性能会比对比学习好很多,对比学习是否会被代替?
这个问题的范围很大,首先我来简单地谈一谈我的理解。我认为对比学习是不会被替代的,因为对比学习有很多独有的优势,其中一点就是它允许我们把一张图像放在一堆图像的context里去学习如何才算是找到自己的另一个view,这是非常重要的。这也是掩码图像学习最大的一个缺点,其只针对单张图像进行学习。此外,往大了说,我认为现在的自监督学习应该是去学习视觉信号的一个高效的表征。所谓高效的表征,即把它压缩了非常多倍之后,它还能重建出自己,或者认出自己到底是谁。从这点来说,对比学习天生的适应能力应该更强一些,它的context能力也更重要,而MIM则具有一定局限性,所以我认为对比学习不会被替代。
我也补充几点,我觉得对比学习是不会被替代的。另外,我也在思考为什么我们会有这样的疑惑?或者说为什么有人会认为对比学习会被替代?我认为主要是因为现在自监督学习的好坏大多是通过一些底层的任务来进行评价的。例如,我们会用ImageNet做一个分类任务来评价自监督学习表征的好坏。然而,像分类任务这样的底层任务需要的信息特别少,可能导致一些方案看起来不错,但做一些其他任务(如高层语义任务)时,就会出现一些问题。我们前段时间也在做一个1000类的无监督语义分割任务。我们发现很多自监督学习模型在分类任务上表现得很好,但其学到的表征无法直接应用于这种语义分割任务中。此外,对于规模特别大的无监督任务,它无法去做Finetuning,这个时候直接使用就会遇到很多的困难。因此,我认为我们在评价自监督学习模型好坏的时候,不光得看在ImageNet训练得到的Performance,还得看其对更高层语义任务的适应性,这些任务才是我们通常要直接使用的,谢谢大家!
谢谢各位老师!我先简单说一下在我的理解中这两种学习有什么不一样的地方。我认为对比学习学习的是不变性,但掩码图像建模刻画的是所有的变化(例如,当你需要预测一张图片的其余部分,就必须要预测该图片的其他部分,即图片的尺寸、物体的大小、物体的不同以及颜色等)。因此这两个方法之间有着很大的不同,学习到的知识也不同。至于说对比学习是否会替代掩码图像建模,我的观点和前面两位老师不太一样,我对掩码图像建模持更加乐观的态度,因为其学习到的知识是非常丰富的,不仅学到了语义的信息,还可能学到了别的东西。如果你把这些信息在预训练阶段丢掉的话,那么对于下游任务是非常不利的,因为你不知道下游任务遇到的问题可能会用到哪种信息,保留的信息越全面可能对下游任务越有帮助。此外,我在单位和我的老板Steve讨论的时候,他的观点更加明确,他甚至认为掩码图像建模可以学习到一些三维的结构信息,因为如果不知道三维信息的话,将很难准确地对物体进行重构。在这个观点下,我认为掩码图像建模学到的信息显然比对比学习更加丰富,我也更看好它,谢谢。
今天主要是来学习的,听了前面几位老师的观点很受启发。从我比较粗浅的理解来看,对比学习是属于判别式自监督学习的范畴,而图像掩码建模例如MAE等这样的框架,是属于生成式自监督学习的范畴。举个例子来说,一个会造车的人,他肯定会比一个只会开车的人对汽车的理解要深刻的多,因此从这个角度上来讲,我很看好图像掩码自监督学习这种生成式框架,因为如果你能够通过生成的办法把你要理解的任务给描述出来,那你一定是对这个任务本身有更深刻、更好的理解;因为你只有对一个任务理解好了,你才能够把它给生成得好;而一旦你能够把它生成的好,再去解决这个任务相关的问题,例如去解决感知识别问题、或者做推理、预测等任务,那可能也相对容易很多。
我非常同意金老师刚才提到的。我个人认为掩码图像建模的训练方式跟生成式模型存在一些潜在的联系。无论是MAE还是MIM,二者都是在做重建。如果抛开网络框架的不同,根据它们的Loss Function可以看出这两个任务和之前机器学习中的Denoising AutoEncoder没有本质的区别。比如,最近两年比较热的Diffusion Model,在训练的时候可以选择两种不同的Object Function,它们的效果都不错,而其中一种的本质为Denoising AutoEncoder,只不过其在训练过程中相较于MAE和MIM更加复杂,需要不断地进行迭代。因此,我觉得MAE和MIM这种学习的方式肯定和生成式模型存在一个对应的关系。虽然现在还没有相应的论文去严格地证明二者间在理论和数据上的关系,但从训练使用的Loss Function可以看出这两者是存在一致性的。
我简要地谈一谈我为什么觉得对比学习不会被替代。刚刚两位老师说对比学习是判别式,而掩码图像建模是生成式,这个我完全同意。但从另一个角度看,我认为它们都是基于退化的学习。什么是退化呢?退化的意思是把原来图像中已经有的信息给丢掉。比如,预处理通过crop把图像中的部分信息给丢掉,那么对比学习就需要去判断我丢掉的信息是什么,或者说丢掉信息以后的图像跟原来的图像是否具有相似的语义。当然,掩码图像建模也是一样的,丢掉一些patch后,把这些patch再重建起来。所以它们虽然一个更像判别,一个更像生成,但从本质上来说,它们都是预测退化的信息是什么的一种学习方式,因此我们不需要把这两者严格地割裂开来看待。
为什么我认为对比学习不可替代呢?掩码图像建模的目标是重建像素,但是否真的需要把所有的像素都重建出来呢?好像并不需要。我认为只需要重建到能够认出这个图像到底是什么,或者说确定图像中的大部分信息被保留下来,就可以了。如果重建每一个像素的话,就容易出现过拟合的问题。那该如何去判断重建是否达标了呢?对比学习就是一个很好的方法。它相当于把目标图像放到一个大池子里,如果它能找到自己,或者找到自己相应的变化,就可以认为其已经成功地重建出其中的大部分信息。因此我觉得对比学习,至少它的核心思想即InfoNCE loss,是不会被替代的。这是我要补充的观点,谢谢。
我有一个问题,因为我们主要在做图像的生成(包括三维的生成),刚刚沈春华老师专门提到它和生成任务的相似性,所以我们如果从另一个角度去看掩码图像建模的话,有没有人考虑过从Inversion的角度去思考呢?因为在生成任务的过程中,一般来说我们需要先做PPI之类的Inversion,但我们的领域还没有相应的工作使用缺失的地方去做Inversion。我不太清楚这两者的co-relation是什么样的?
各位老师,我在这里分享一下自己在自监督学习方面的经验。针对图像而言,MAE在ImageNet上确实挺成功的,毕竟因为ImageNet有1000类,每个类之间并不是非常Fine-Grained的。对于一些比较Fine-Grained的识别任务,无论掩码的尺寸是大还是小,其结果并不是很好。比如,我们把图像中的人的好多部分都遮盖掉,重建的时候很难知道这个人是不是背着包,或者是不是戴着帽子。但如果只是用在ImageNet中比较宏观的物体上时,可能就很容易地被重构出来。虽然把重构的图片放大,可能有很多缺失和错误的信息,但总体而言,车子还是那个车子,Airplane也还是那个Airplane。相反的,对于一些比较Fine-Grained的物体,这些Patch是完全被摧毁掉的,重构出来的也和原来的Image不一样。这一点可能会使一些Fine-Grained的识别任务出现识别率不高的问题。
我补充一下关于下游任务的讨论。首先,我刚才提到MAE和MIM本质都是Denoising AutoEncoder,其中移除Patch的操作就可以理解为在图像中添加噪声的过程。实际上,这种类型的噪声并不是必须的。我们初步的实验结果表示,添加High Level的噪声,训练出来的结果也还是不错的,Fine Tuning后在ImageNet测试出的结果相差在0.5个百分点以内。MAE之所以采用移除Patch来添加噪声只不过是因为和ViT中通过Split生成Patch的操作结合得比较好,但这并不是必须的做法。此外,MIM的那篇论文还涉及一些卷积网络的实验,证明即使不用ViT这种结构,也能训练出比较好的模型。Anyway,如果说扔掉Patch不是唯一的加噪声的方式,那我们还可以探究添加不同种类的噪声,可能最后训出的模型也是差不多的。
关于虞老师刚刚提出的Inverse过程。Diffusion Model是生成式模型,Forward是训练过程,而Inverse就是生成图像的过程,但对于MAE或MIM,并没有Inverse这个过程。目前为止我也没有看到相关的论文去探讨MAE或MIM和生成式模型到底有什么潜在的联系?以及MAE或MIM该如何去Inverse从而得到一些好的结果?Diffusion Model最早的Paper中就有一个实验,是将Diffusion Model训练好后,将其中的UNet结构用来做一些下游任务,也非常有效。我也更看好这种成果,有非常漂亮的数学模型在里面。但现在的MAE等工作,大部分都是在跑实验,并没有解释为什么,我们也不知道其中学习到了什么。
很高兴来到RACV。我首先支持一下沈老师的观点,我感觉MAE和MIM是一回事,只是两个不同的名字,但解决的问题可能是完全一模一样的。这是我个人的一个观点。然后我回应一下王井东老师刚才提到的“对比学习为什么work“这样一个问题。其中的一个核心观点是对比学习可以学到Semantics。
此外,南京理工大学的杨健教授在这个方面做过研究。他在ICML 2021发表的工作从理论上证明了对比学习能够明显地提升分类任务的Discrimination,可以看出其至少对于分类问题是非常有效的。谢谢!
我刚才主要是想听听各位老师的一些观点,我有一些想法和大家不太一样。我觉得掩码图像建模实际上在做重构的任务,刚才凌曦提到这种方法中图像没有跟其他的图像做交互,但我觉得它的交互实际上是体现在模型参数上的。在NLP中,其中一种经典方法是学习 Contextualized Representation,这指的是一句话里有若干个单词,同样语义的单词表示会更接近一些并且被group到一起,比如一些表示指代的词it或者he。我认为掩码图像建模也会起到相同的作用。在学到最后的表示层时,比较相近的语义会融合在一起。因此我认为其在某种程度上是可以学习到语义上的一些特征,比如同样物体上面不同部位的语义特征。这也是我认为掩码建模图像能在分类任务以及很多跟语义相关的一些问题上取得更好结果的一个原因。
此外,在图像领域我觉得还是存在一些比较难解决的问题,比如物体尺度的问题。在Language里,Token是没有这个概念的,所以不需要考虑这个问题;但在视觉领域,处理的物体是有大有小的,而固定尺寸的掩码可能会盖住一些细粒度的物体,从而很难学习。我觉得在这方面还有很多比较细的工作可以继续去做。
总体而言,很难说一个方向是否会替代另一个方向,两个方向肯定都会往前继续探索的。谢谢!
刚刚春华老师提到在ImageNet上做Finetuning的evaluation。这就牵扯到另外一个问题,应该怎么去evaluate?之前有观点认为Linear Probing是一个很重要的指标,后来又有观点认为Finetuning也很重要,但很多人又发现方法差别很大的情况下,Finetuning之后可能没什么difference。此外,我们可能要多花一些时间再探讨一下Encoder究竟学到了什么?大家还有什么需要补充的吗?
刚才听兴刚老师说:并不是模型越大,性能越好,然后我就在思考这样一个问题:在自然语言处理中,大模型一般能起到一个很好的作用,但是在视觉里面会不会也是这个样子呢?或者说对于视觉而言,是不是适度大的模型比较好,模型过大之后反而不好了呢?我觉得自然语言处理的处理对象是人说出来的话,其中的语义性比较强一些,但视觉的很多数据的语义性不是那么强,对于有些任务是信号的区域可能对其他任务就是噪声。如果模型的规模变大以数据扩充为前提的话,是不是对于某些特定任务来讲,意味着引入了更多的噪声,从而影响模型完成该任务的性能?导致最后训练得到的大模型对任何任务都不是最优?
我回答一下毋老师刚才那个问题,因为跟我的工作有点相关。现在有一些观点认为,人脑的容量比现在模型的容量要高很多,现在的很多模型都是不够大的。我们需要得到一个像人脑一样的Foundation Model,这就要求它有越大越好的特性,这样才能够有一个继续往下发展的一个趋势。当然大了之后呢我们还有很多办法可以把它变小让它能够被应用,但这都是一些工程问题,而不是一个科学的问题。从科学上来讲,可能就是希望要不断地扩展模型,吃更多的数据,变得更好;但从应用的角度来讲,我们可能并不需要用到。
然后,关于MIM呢,我觉得还需要更多对它进行理解,甚至可以做得更大胆一点,就像黄高老师说的这个多模态,我们是否能够做多模态的MIM呢?现在只做图像的话,我觉得可能还不够,可以把更多的模态引入,然后一起去做这个掩码图像建模。
我接着兴刚的话说。我认为视觉和语言是不一样的东西,我们应该区分来看待。对于文本来说,模型确实越大越好,但视觉上并不一定是这样。因为视觉处理的信号和文本信号有本质上的区别。文本信号是人类创造出来存储知识和表达知识的,他一定要注重高效性,所以文本的信息密度非常大;而视觉信号是人类从传感器中获得的,注重真实性,所以它信息密度比较低。因此,对于这两种信号,我们所使用的学习方法和模型必然是很不一样的。在语言任务上,模型越大越好是因为语言多多少少有种死记硬背的感觉,记住那么多语料,就能进行泛化;但视觉信号对真实世界的采样密度还是非常低的,无法通过一些死记硬背或者预训练的方式去达到非常高的通用程度。所以说在当下,对于视觉任务来说,比起做大模型,我们更多地还要去做一些其他的事情,比如对视觉信号进行高效地抽取,创造一个良好的环境使得视觉上的scaling law能够显现出来。现在视觉领域暂时的情况是,把迁移学习做好、把各类的任务分开来做好,会更有用一些。或许在未来的某一天,当我们把视觉的基础建设提上来后,达到了和文本同一起跑线,那么scaling law可能就会出现了。这是我对毋老师的问题的回答。谢谢!
虽然有点跑题了,但我还是想回应一下刚才两个老师说的这个问题。我在网上看到Tesla的Andrej Karpathy(现在已离职)说过,10年前视觉、语音和自然语言是分离的,图像也是分为Static和Video,同时在Static图像里做分割、分类和检测也是使用不同的方法,但这几年的趋势是AI Consolidation。我们可以看到BERT、Transformer等Language里的模型在Vision里取得很好的成果,也看到更多的证据表明同一个模型也可以做不同的任务。因此,我觉得我们可能需要一个可以学习到一些更本质东西的大模型,需要学到一些非常Fundamental的东西。这和我们今天讨论的MIM到底该学什么东西是相似的?
谢谢夏老师把我的问题拉回来。我们想探讨MIM学到什么?现在这个方案在这个目的上能学到什么?
首先我想回应一下凌曦,目前并没有明显的证据表明MIM中使用Pixel作为监督信息会出现过拟合的现象。根据MAE的Paper里汇报的实验,即使训练周期非常长(达到1600个Epoch),其在小数量的数据集上也并没有表现出过拟合的现象,其性能还是会持续地增长。此外,我认为掩码图像建模的预训练任务是非常丰富的,丰富到在小数据集上也可以定义很多任务让网络去学习。
还有一个很重要的实验和毋老师的问题相关,MAE尝试过很大的模型,比如ViT Huge,但用在ImageNet的100万张图片上也没有出现过拟合的问题。相比之下,对比学习即使用在ViT Large模型上也会出现非常严重的过拟合现象。此外,对于之前的一些对比学习框架,它们都很难进行ViT Large模型的训练。因此,我认为掩码图像建模定义了更加广阔的问题空间。
我也有一些跟武老师相似的一些想法,我觉得对比学习、Masked Image Modeling和最近正常火的DalleV2这种的Full Image Generation,这三者都是Special的自监督任务。什么意思呢?对比学习相当于一个Classification,输出的number of bits为;对于Masked Image Modeling,输出的number of bits为恢复多少的像素,比如在MAE中大概是75%的像素个数;而对于DalleV2这种的Full Image Generation的话,不仅需要恢复图像的每一个像素,每个像素恢复的精度也需要特别高。我认为我们希望自监督的任务越来越难,信息恢复得越来越多,这样学到的Information才越来越多。此外,从实验效果来看,DalleV2的结果非常惊艳,随便写一句话,它都能生成非常符合这个语意的图像。这让我觉得DalleV2的Encoder学习到的信息量是更大的。
然后从另外一个角度来说呢,为什么大家认为对比学习很好?是因为它的Linear Probing很强,甚至对于DINO,它用在Nearest Neighbor Classifier也很强,现在能达到70到80左右。
此外,我们还需要关注视觉标准到底有多么容易去Readout。对于对比学习,它是非常容易Readout的,因为预训练任务和下游任务是一样的,都是在做Classification;对于MAE,其并没有做InfoNCE,Paper中的Linear probing效果不好;对于DalleV2这类的任务,虽然Paper中没有提到Classification的效果,但我估计效果并不好。总的来说,我认为视觉表征如何“easy to readout to your downstream task”可能是未来可能比较多关注的问题。
下面我们看一下语言能为视觉基础模型带来什么,视觉基础模型是不是一定需要语言?
我先接上一个问题说一下,然后再说一下王老师所说问题。我也觉得对比学习更像是一种判别性的学习,然后MIM更像一种生成式的学习,这个可能跟前面的老师基本上是一样的,我想说就是对于MIM这种偏生成式的学习,我觉得它可以学到的知识和能力其实是更广泛的。对比学习可能更偏向判别性,学到的知识区分能力较强,但可能泛化到其他任务时,他的能力可能相对来说就会弱一些。还有关于MIM,我觉得它比较好一点可能是我们不一定非得去重构像素,去做像素级的重构,其实我们可以去做不同的粒度的重构,而且非像素的特征其实也可以去重构,比如说我们在做传统CV方法的时候,那时候有很多的特征是根据先验人工设计出来的,也可以去试着去重构这些特征,这样的话其实它会学到一些相应的先验知识,所以我个人认为MIM可能也会更灵活一些。
然后关于语言这个问题,其实我也做过一些简单的思考,比较像刚才王兴刚老师也提到的混合多模态的模型,比如利用语言时,把一句话中的一些词抠掉,然后换成一些图像区域的表示,做这种context的学习,反过来,可以把一幅图的一些区域扣掉,换成其对应的物体的语言的表示,这样将image embedding和word embedding混合在一起去学,会更加促进视觉与语言两种表示空间的连接,这就是我比较简单的一些看法。谢谢。
我再补充一点,其实第一个问题,我可能问得不是很好,其实应该说我们解决这个对比学习的任务和解决掩码图像的任务能给我们带来什么,而不是这个任务本身,
我觉得语言对于视觉基础模型是非常重要的,因为视觉的理解还是要跟语义联系起来,我们希望不光是做一些low level的任务,更要理解图像里面有什么东西,然后这个东西它有什么部件,这个物体跟其他物体之间怎么去交互。从这个任务目的来说,视觉数据的开发是远远滞后于自然语言领域的。在自然语言理解领域,大家可以想象现在训练语言大模型的数据,对语言的覆盖是接近完备的,用它训练完大模型之后,可以覆盖语言里面的各种问题。然而视觉方面的数据还远远达不到,把web上所有的图像数据都抓下来,仍然还有很多问题,无法覆盖视觉领域的所有问题。在视觉数据有限的情况下,语言是可以帮助我们去做语义上的扩展,这非常重要。从我们最近的一些视觉基础模型上的工作来看,训练数据实际上还是比较有限的,但是仍然能看到它有一定的泛化能力。我觉得语言带过来的一些知识,与视觉信息是相关联的,视觉的表示跟语言结合后,随着语言的扩展,视觉的表示也会扩展自己的表征能力。
我说一下我的观点,就是视觉基础模型一定是需要语言的,未来一定是视觉跟语言相融合的一个态势,比如说过了几年以后,业界最好的模型中,可能就不存在纯粹的视觉基础模型,最好的模型都是视觉和语言融合的。顺便也回应一下这个问题:图文弱监督和视觉自监督两个是不是都需要?我的观点是非常明确,两个都需要。因为图文弱监督就像刚才黄高老师说的,它是包含有一种互监督的概念,可以帮助我们去克服纯视觉预训练存在的问题,即你很难抽出有效的语义信息。一旦有了文本的辅助,这件事情就变得好做很多。那么自监督为什么也需要呢?是因为自监督它本身更加适应视觉任务,对图像的性质捕捉得更好。进一步说,这两个方法不仅都需要,而且我们在研究和落地的过程中,发现它们是有先后顺序的:先做图文弱监督的预训练,然后以它作为基础模型,再做视觉预训练,相当于把视觉预训练作为一个图文预训练的fine-tuning。更明确地说,我们现在的方法分为三步走:先用图文弱监督去做预训练,再用视觉自监督去做二次预训练,最后才去下游任务上做微调。我们最近在ECCV发表了一个叫做MVP文章,也确定了这样做是有益的,包括对于检测分割这种下游任务,都有明显的性能提升。
关于各种自监督弱监督方法,我个人的看法就是语言涵盖了大量的语义信息,但是语言它不可能是无限精确地描述图片的信息。那么互联网上的图片和文字描述,文字以泛泛描述为主,精确描述很少。所以我觉得我们依赖图文弱监督的话,主要是理解大概上的事情,那么对这个MAE和MIM这种方法,刚刚虞老师也谈到了,我个人觉得它是在隐式地思考图片里的几何信息。但很可惜我觉得现有的MAE的方式,它的loss是一个MSE loss,这种loss其实它并不能够发现看不见的部分, MIM mse这种loss对SSL来说是不利的,所以我也在想这几种方式,他们其实是互补的。如果我们关心的是物体的low level的几何,特别是我们做智能,我们要感兴趣怎么跟它接触,那么几何是很重要的,在这个问题上可能语义并没有什么作用。我们做弱监督,其实真的缺乏能用的视觉数据。所以说我们变换一个视角,我们可以reconstruct它,但是目前的弱监督,很难去真正反映其中的几何,那么目前的这个mae的这种监督也只能说是在这种先天条件缺失的情况下,去给他找一个方式去学看不见的地方是什么,我感觉对于数据模态的类型的补充和 loss方式,还有很多可以探讨的地方。
在图像检索和视频理解中,我们经常提到结构化、语义化。这就是说,计算机视觉领域主要解决两个问题:(一)语义化,图片中含有什么实体,它的语义概念是什么?例如:图中有一架飞机,一个人。(二)结构化,实体间的关系是什么?例如: 人从飞机走下舷梯。当实体和关系都描述清楚了,我们就理解图片包含的语义是乘客下飞机,而不是上飞机,坐飞机,驾驶飞机或站在拖拉机旁。计算机视觉的根本目标是视觉信息的结构化和语义化,对应到自然语言就是命名实体、实体关系(空间关系,交互关系)。对于视频,结构化还要考虑持续时间的上下文关系。
关于视觉基础模型学习方法,今天大家探讨了很多。对比学习(CL)是通过比较两个对象是否相似来解决区分力问题(实体识别);大量标注样本对模型训练肯定是很有帮助的。但实际上,我们在做模型训练时,经常缺少大量的标注样本,所以就产生了解决样本自标注,自监督学习问题的掩码学习方法(MAE),即通过掩码抹掉子图,然后由自编码器填空生成缺失的已知部分(实体关系)来实现学习的一种方式。
我记得悟道大模型的研制者唐杰老师,他在一篇论文的标题中提到:“所有的一切都是生成“。我当时在想,难道不是所有的一切是分类?但他却说一切都是生成,生成是识别的基础,其实就是类似于掩码学习,生成的思想如出一辙。就是你缺少一个东西,你去生成它的时候(原始照片本来就有,挖掉一块区域,通过生成把它填充好),在反复的生成过程中就学习到了这个东西。现实中,我们训练样本实在是太缺乏了,基于MAE的生成学习为我们提供了一种新的学习方式。
我就说这些。另外我提一个问题,去年RACV2021,我们讨论过视觉大模型。正好这次华为盘古视觉大模型的谢曦凌来了,百度视觉的专家王井东也在,能否介绍一下您们视觉大模型的最新进展、经验和问题?
这个问题很好,那么第一个就是其实兴刚提到的那个大模型,不过是个150亿参数,我们前段时间发布了一个更大的、170亿参数多任务大模型。
我简单说一下,非常感谢王涛老师给我这样一个说一下自己落地工作的机会。其实我刚才回答毋老师问题的时候已经讲过了:视觉跟文本是不一样的。就语言来说,现在我们收集到语料库已经是现实世界的一个非常好的采样,它覆盖的范围足够大,于是我们用预训练去死记硬背,甚至过拟合语料库,依然能够取得明显的收益。但是,视觉还远远达不到这个程度。在落地的过程当中,如果我们拿一个在通用数据集上训练好的模型直接用于实际业务,比如说你把ImageNet训练好的模型用到医疗影像上去、用到矿井图像当中去、用到工业质检的电路板图像上面去,效果不一定会好。这是因为视觉的预训练数据集没有覆盖这么多复杂的场景,那么过拟合的副作用就显现出来。这是大模型在视觉上没有全面铺开的第一个原因。
第二个原因其实也是一个非常现实的原因:视觉大模型太慢了。文本大模型,即使有千亿参数,它推理一句话还是很快的。但是视觉大模型,如果做到十几亿的参数量,那么在一张图片上做检测,可能要20秒钟的时间。一张图片20秒,谁能忍受?那不可能的。所以说我们在实际业务当中必须把这个东西给调整过来,比如说有一个预训练大模型作为基础,在微调的过程中,通过蒸馏剪枝或者说别的方法,你把它弄成一个稍微小一点的业务上能用的模型,用到业务上去。而且我们发现在这个过程当中,微调的收益比起模型规模的收益要大得多。这也是我前面说过的,因为视觉信号太复杂了,你没有办法通过预训练去覆盖所有的数据分布。所以在视觉领域做落地的思路,跟语言肯定不一样。我们现在做视觉大模型的思路也不是像在文本那样,一定要往大的去走;在视觉上我们就是做到10亿左右参数,基本上就可以了,不用再做大了,而是把精力放在模型的下游微调上。这是我对于我们业务的一些解释,谢谢。
我就第五个问题谈一谈我自己的观点。语言能给视觉模型带来什么,我觉得大家都比较认可语言是有帮助的,但现在我们关注更多的是怎么带来或者怎么做性能提升。我在想我们是不是应该思考现在语言的使用方式是不是合理,或者有没有更合理更优的方式。
大模型的发展目前有四个维度,第一个是空间的维度,空间的维度主要体现在粒度上,由图片分类这样的粗粒度向中层粒度(object level)及细粒度(pixel level)不断深入,第二个是时间上的维度,由静态图像向动态视频方向扩展,第三个是模态的维度,由RGB模态、向红外、深度、语言等多模态发展。第四个是多任务的维度,大模型需要向下游不同的任务扩展,从而实现一网多能,一网通吃。
当前语言和图像融合的大模型,如Clip对视觉理解的发展有很好的促进,语言的描述相比图像来说,实际上是非常精炼的,通常是人类的对图像的一个总结,可能眼前这个图什么都有,但是你通过语言描述后,人会对图像的注意力更精准,理解更到位。其实语言它还有一些明确的描述,它其实是表征了一些结构信息,很多是知识性的信息,这些知识在图谱中又有上下文的关联关系,这些其实都是对视觉的有指导意义,通过知识图谱的方式来指导视觉模型,那么会使得我们会对视觉理解的更充分,在很多任务上面都提升明显。
所以说我觉得其实语言为视觉带来了很多,但是另外一个问题呢,我其实也不太了解,就是NLP方面是不是需要视觉的一些知识和模型?相比图像的粒度来说,语言描述的粒度较粗,而且图像本身变化是多种多样的,它的空间表征更更大一些,有些其实超出了语言描述的内容,所以说这样翻过来,为了对语言的理解更深刻,NLP究竟会不会用视觉大模型,我想抛出这个问题。
各位老师上午好,刚才听了各位老师的报告和发言,很受启发,我谈一下对视觉基础模型的一些理解。过去这两年我也一直从事视觉基础模型方向的研究,在国内很多地方也汇报了我们课题组在这方面的一些工作。我们可以简单回顾一下近10年来这一波的计算机视觉发展历程,从2012年到2022这10年其实可以分两个阶段:从2012年到2017年,计算机视觉应该说能够成功其实也是受到语言的启发,大家可以看一下深度学习最开始成功的其实并不是在图像识别任务上,那个时候我在新加坡工作,深度学习在语音识别任务上成功了很久,在2012年才在视觉任务开始成功,所以说那个时间节点上其实也多少受到一些语言的启发。这一波从2017年到2022,我们都看清楚,实际上计算机视觉是在跟着NLP在走,如果说早些年我们可以比较骄傲地说计算机视觉推动了人工智能的发展,现在很多时候我们没有办法。刚才卢老师讲的很对,就我们把模型用在图像视频上,根本解释不清楚为什么需要Transformer这样的东西。所以我的观点就是说语言跟视觉一个本质的区别,那就算语言是有非常清晰的语法,而视觉是比较缺失的。今天上午讨论了很多对比学习,我感觉我们更需要关注语法这种东西在视觉数据里面如何挖掘,这是一个很难的问题。因为现在视觉没有语法,而语言是有很强的语法,十几年前美国一个知名教授跟我讲一句话,我至今印象非常深刻。他讲的一个观点就是computer vision is language。他说计算机视觉也是一门语言,语言的本质就是语法,视觉现在没有语法,所以我希望或者说各位同行一起就在这个方向能够研究,一起用语法来指导视觉基础模型的构建,谢谢。
这个问题很有意思。语言有语法,那么图像或者识别有没有语法呢?因为语言是我们自己发明创造的,所以我们认为它有语法;但是图像虽然不是人创造的,可能是自然界某种规律创造的,是不是也有自然界的语法呢?
因为我对计算机视觉不是很熟悉,之前有做过一点,但没有继续做了,后来主要是做机器学习和人工智能理论。所以呢,我就说一下第三、第五这两点吧。机器学习早年的时候也曾经有一个梦想,这个梦想和第三个问题差不多是一样的。当时是想这种学习任务会有一个统一的学习算法。但这是不可能的,因为95年的时候就有人证明了没有免费午餐定理,97年这个观点就进了教科书,从此机器学习就不再梦想去构建一个统一的机器学习模型了。如果说在一些条件下这种模型是可能的,那么就意味着这些任务要么是存在投影(同态)关系,要么是可以互相重构的。如果不是这种关系的话,那我认为这是一个很困难的事情。从机器学习上来说,对于不同的学习任务,利用没有免费午餐定理,每种任务都应存在更适合的算法。当然这是我的理解,也不一定完全正确,万一日后证明了在机器视觉领域各类任务之间居然存在同构或同态关系,那确实会是很大的成就。但是,如果证明不了这件事情,那么这些任务本质上就是不同的应用。这就是我的观点,从机器学习的角度对第三个问题进行了一点补充。
接着说一下第五个问题。语言和视觉的实现是非常不一样的。从符号的角度来说,视觉属于相似符号,语言属于象征符号,它们是完全不同的。虽然像相似符号之间会存在一些相互关系,比如说照相和漫画之间可以存在映射的关系;但是不同的符号之间,比如相似符号到象征符号,这种映射是极其复杂的。对语言来讲,从汉语到汉语是可以同构的,英语到汉语不见得是同构,但可以说是近似同构。因为如果不近似同构的话,翻译就是不可能的,所以可以说是近似同构。但是对视觉而言,我们计算机的图像到语言是同构吗?从我的观点上来说,可能是差得很远,从自然符号到相似符号就差很远了,再从相似符号到我们所谓的象征符号,那就更加天差地别。实际上我们象征符号的单位是有限的,已经有人证明实际上每种语言的常用词也就5万个左右。对于每个人来说就更少了,与图像的数量有很显著的差异。
于老师讲的挺底层和哲学,我也来谈一点观点。实际上,语言和视觉在逐渐的统一,从NLP的角度上来讲,语言可以向量化,从而转变成一个传统的统计学习的问题;而图像可以Token化,也可以转换成NLP处理范式的问题,这两者当中的差距是越来越小的。视觉和语言之间也有很多的互相受益的地方。我特别同意谢老师讲的观点,在自然语言方面我们有比较全面的数据,但直到今天,我们还是很缺乏大规模多任务的视觉数据。现在NLP里面有像SuperBLUE、Big-Bench等多任务benchmarks,但是视觉领域像ImageNet这种任务太简单了,哪怕加上segmentation和detection任务,总体来说还是单一的。如果我们能构建一个大规模数据集,增加更加丰富的任务例如视觉推理、问答、细粒度的CV任务如人脸识别、ReID、OCR等等,将来有一天先把一个超大规模的多任务图像视觉数据集构造和定义出来,再去研究面向视觉的大模型,可能会更加更加有价值和有意义。
从我们实验室的一些经验来讲,语言对于我们视觉的理解是很有大帮助的。比如说对于跨模态的多模态文档图像理解。在文档图像理解中,中文或英文的数据有很多,但是对于小语种而言,不管是无标注的数据还是有标注的数据都很难获取。如果把视觉模型和语言模型解耦出的训练,利用某种方式再把它们耦合在一起时会有很好的效果。比如说利用跨几十种语言的大规模语言模型,把它迁移到视觉里面,就可以帮助我们解决一些few-shot或者zero-shot场景下文档图像的分类、识别、信息抽取等视觉上的问题。我们今年在ACL2022年就有一篇文章在做这个工作,我们发现即使是zero-shot情况下,如果有语言知识帮助我们建模,是可以更好的去解决视觉问题的。
从这个意义上来讲,我很看好将来视觉和语言可以走到一起。刚才继文老师提到,回顾过去10年AI领域的发展,前5年可能是CV领域在引领主流,从17年到现在是以Transformer为代表的这种NLP领域中的方法在引领主流。展望未来5年或10年,这两个领域可能会走得越来越近,我们也希望这两个领域中还能够产生让人眼前一亮的或者具有革命性的一些工作,比如说像MAE,还有Hinton教授去年提出的Pix2Seq,今年也出了Pix2Seq v2,把视觉检测、实例分割、关键点检测、图像描述等任务统一到了一个基于Transformer的框架,方法简洁,效果惊艳。我觉得这些方法还是能够给我们带来一些新的启发。
我刚刚听了金老师和于老师的发言,我觉得很有启发,忍不住想要问张磊老师和井东老师一个问题。其实前面已经提到,现在已经出现了很多根据语言做图像生成的工作,至少从视觉来看,这个任务已经做的非常的好了。那么根据语言生成的大规模的图像,对于视觉基础模型到底有没有帮助呢?对这个问题,我的看法是,有帮助或没有帮助都很重要。假如说没有帮助,即这些图像对于机器视觉不会有任何帮助,这表明我们已经cover了所有的information,不可能再生成additional information了,所以即使这个问题的答案是no,也是很有意义的。如果答案是yes,也就是有帮助的话,那么举例来说,如果我能够生成在原始图像里面不可能存在的,比如刚才讲到的熊猫在沙滩上一类的本不可能在你的数据里产生的图像,但也许有一天真的会出现这样的数据,这种明显是基于语言生成的高质量图像,对视觉基础模型会不会带来帮助呢?我很想听听两位的观点。
虞老师的问题是一个比较新颖的角度。在我看来,现在做的生成模型,并不是在解决representation learning的问题,主要是把大量图像映射到空间里,对它的分布做采样的过程。很少用生成模型这种方式去做表示学习,表示学习还是用弱监督或者自监督的方法比较多。我认为从生成的角度来说,某种程度上仍然是一个类似于重构的任务。当它重构了数据之后,可以做更好的采样。我觉得至少目前这个研究领域里还不是在探讨使用生成模型去解表示学习的问题,所以我对这个问题还没有一个特别好的答案。
我来补充一点点。我没记错的话,DALL·E 2中使用的是CLIP模型,它的表征是从CLIP出来的。DALL·E 2可以认为在语义空间中做diffusion sampling,然后使用diffusion decoder完成图像的生成。其实这个地方就是刚刚提到的,怎么样才能生成的漂亮,怎么能把隐含空间里面的表征变成真实的东西。像Google做的Imagen,也是融合了这些过程的。我觉得在那个隐含空间里面sampling还是需要一个好的表征空间的。
尤其是语言特征空间,需要有一个好的表示。DALL·E 2实际上也是利用了CLIP来帮它解决问题,而不是它去帮CLIP解决问题。我认为在DALL·E 2中没有加入增强CLIP表征能力的地方。因为generation的问题比表征学习更难,所以它实际上是在借助于表征学习的一些工作的进展来进一步解决问题,而不是反过来帮助解决表征学习的问题,当然后者也是一个很好的方向。
其实DALL·E 1生成的东西也不错,只是quality没那么高。主要的差异在diffusion decoder,使得DALL·E 2的quality非常高,也就是生成地更漂亮,单从语义的角度来说,差异并没有那么显著。
我也想提一个问题,这个问题可能有一定的争论。今天上午我们这个专题讲的是大模型,大模型是数据驱动的机器学习方式。现在,除了各大公司以外,很多学校也在做,是个很流行的研究方向。我担心的是,这样下去是不是会对我们计算机视觉的研究产生一些负面的影响呢?
这话是什么意思呢?我们在做大模型研究的时候,基本上都把数据获取这个过程给忽略掉了。我们知道计算机视觉是应该包含数据获取、数据选择等环节的。生物也好人也好,像很久之前生态心理学所主张的那样,视觉系统是要把感知、认知及其决策这些功能融合到一起去的。但现在如果使这些功能处于一种分离状态的话,这是不是会对我们这个领域产生影响?
当然,从另外一个角度来看,我们也看到这种数据驱动的方式在一些视觉任务中能够发挥作用,能够提升系统在一些特定问题上的视觉认知质量。但我还想问一下,从本质上讲,除了刷榜之外,大模型能解决哪些我们以前解决不了的问题,或者说它在哪些方面可能会引起计算机视觉研究方法论上的突破呢?
正好我们也在做大模型,所以我就先回答一下查老师的问题。其实大模型在我自己看来,在预训练算法部分,跟小模型其实没有太大区别,它更多是一个工程问题,所以业界也很少有学者针对大模型去专门发表论文。那么大模型它能带来什么改变呢?从落地上来讲,大模型带来的规范,会让我们落地会更快更便捷。比如说,当我们有一个基础模型以后,就可以比较方便、规范地把它迁移到不同的下游场景里面去;而且由于预训练的原因,在小样本任务上,它的能力确实是有所提升的,因为它share了一些公共的feature。这是我们在大模型上能够得到的一个比较明确的好处。
关于前面虞老师提到的,生成图像辅助识别的问题,刚才张磊老师说没有这方面经验,但正好我有这方面的一个失败的经验。我们曾经用生成图像尝试去提升识别精度,但是最终失败了。背景是这样的。我们知道在图像分类里有一个工作叫mixup,它的想法非常简单:假如有两张图像,图像A是狗,图像B是猫,我们把A的像素乘以0.8,B的像素乘以0.2,两者相加创造出一个重叠的图像,然后强行让分类器得出这张图像0.8概率是狗、0.2概率是猫的结论。这种做法可以提升分类精度。我们就进一步想,这样做是不是太弱了,能不能用图像生成技术来改进这件事情。我们知道GAN inversion出来以后,很多工作都会展示一个被称为image warping的实验。比如说一张图像是猫,一张图像是狗,warping就可以创造一个序列,使得猫渐变成狗,相信大家也有都有见过这样的图片。具体做法,是把两张图像分别逆映射到特征空间,在特征空间中插值,然后再映射回来,就可以做到这样渐变的效果。于是我就想,能不能用它来替代mixup呢?这是一个很自然的想法,但它最终失败了,而且是很彻底的失败,没有任何提升性能的迹象。这是为什么呢?后来,我们发现一个很明确的点。在warping时,我们一般都假设它在语义空间上是连续变化的,但是实际上不是这样。我再举个例子,比如说有一只头朝左的狗和一只头朝右的狗,我们理想中的warping,应该是这个狗逐渐地从左边转到右边,但实际产生的效果是,左边的狗头逐渐消失,而右边逐渐长出一个狗头来。这种warping效果,跟我们想要的就不一样,无法帮助我们在图像分类或者识别这个任务上做得更好。
所以我可以回答刚才的问题。总结我在这方面的失败经验就是,当前的生成模型还没有真正根据语义去生成,而是根据统计学习直接去生成的,这就导致它生成出来东西很不确定,可能还没有办法很稳定地去帮助分类或识别的任务。但是,在某些情况下,生成数据还是有用的。比如说我生成了一些熊猫在池子里游泳的图片,而我下游要做的检测任务,目标恰好就是熊猫在池子里游泳。这个时候你没有真实的数据,那么生成一些数据总比没有要强。但是在一般的情况下,因为生成模型对语义的把握还没有那么强,它就很难辅助识别任务。这是我的失败的经验和教训。
这个我来说一下,我觉得前面讲得很有道理,就是说在语义中是没有考虑到三维的,这种情况下,是会存在geometric constraints的。
我快速回应一下。我们确实没有考虑三维信息。但就算考虑了,这个过程也是不可控的。
我是觉得现在深度学习这种数据驱动基本上没有考虑到三维,把图像恢复出来,我们都想象不到背后在做什么,我认为这还是一个pattern的重现过程。因为我们的算法里面没有为三维重建专门设计任何东西,虽然我们不能排除它没有学,但我觉得确实是没有看到这个东西。现在的图文相关的、尤其是大规模的工作,基本上就是分类。
就像凌曦刚才讲,对于大模型而言,90%都是工程问题,因为要把这么多GPU一起去训练,然后把数据加载保证不出问题,它基本上就可以看做是一个工程问题了。我在微软也是在做这个方向,这个方向确实有大量的工程。不过确实可以看到它的结果在逐渐地变好,数据量不断增多,模型不断变大,效果也在不断变好。所以我是觉得这个趋势是没有问题的,但它的工程会越来越复杂,它就变得不太像是一个典型的研究方式得到的成果了。
我也想补充一下,我是北京大学王鹤。我觉得像CLIP这种大的图文的弱监督模型,也是有很多问题的。我们会发现在互联网上的一些语言中,会经常性的出现信息丢失,或者是大家不在意的一些信息。对于这些我们不在意的东西,通过Visual language pretraining就学不到,比如说有一张大合影,其实很难注意到这个 image里面有多少个人。像这些信息不一定有,即使有,模型也学不到,所以我们现在用clip的pretrain model的时候,如果想把它knowledge distill 出来,我们会发现比较common的一些东西是可以distill出来的,但一些detail的东西则distill不出来。这个时候再联想到DALL·E模型,因为我们能够使用语言来控制它的生成,那么我们给出一些特殊的语句,它也能够给我们一些想要的输出,以此形成这样的image和text的pair。
但由此会出现两个困扰着我的问题。第一个问题是就连我们这些大学的researcher都没有办法access到这些非常好的image生成模型。即使申请获批了,可能一天也就生成10张图片左右,不可能允许进行大规模的生成,之后再用来做训练。今天咱们有很多国内公司的代表,能不能咱们中国搞一个open access的模型让我们researcher也来玩一玩生成,我觉得这个能很快boost相关方面的一些进展。第二个问题就是我们发现在他们的training data里有很多missing area。我个人本身就比较喜欢关注的是图像里面part的结构,比如说拿clip去做表征,它能不能知道椅子的背上有几条横幅这样的信息?我们发现这些模型根本不知道,更精细的来讲,比如说一个遥控器上哪个按钮是关机键,哪个按钮是调声音的,这些事情是完全没有任何信息的,因为这些东西本身在互联网上就是处于一个信息缺失的状态。所以我们也在想是不是对某种特殊task,我们也需要用一些data来distill或者是enrich vision和language model,build一个小范围的specific的vision-language的pair。我觉得这些都是可能推动vision language model在具体task应用上的一些方向。
各位老师好,我是来自于合合信息的丁凯,关于视觉大模型,我这边想提两个问题,请教一下各位老师。第一个问题是关于视觉和语言融合的,目前大家提到的视觉跟语言的融合中的语言一般来说都是自然语言,同时语言还有一种表述的方式,也就是经过人类这么多年抽象之后形成的知识。在业界中也有很多知识的表示方式,比如知识图谱等等,那么这些知识如何和我们的视觉模型融合起来,更好的去指导我们模型的训练,并且去避免一些人类的常识问题呢?举个例子,之前在NLP领域里面比较火热的大模型GPT-3,它生成出来的有些语言也会缺乏甚至违背常识。所以视觉大模型与知识的融合这个方向有没有可能是未来的一个发展方向呢?
第二个问题,就是刚刚查老师提到一点,大模型的发展会不会有什么负面作用?现在的大模型有几个特点:数据量非常大,参数非常多,训练成本非常高,变成了只有一些大的公司或者机构才能做的工作,像一般的科研工作者只能去用这个模型,这样的好处是大幅度降低了下游任务的难度和门槛,同时也会出现同质化的情况。即大家都是用同一个预训练模型,然后再去做下游任务,做到后面会发现这个任务的瓶颈就是这个预训练模型了,导致大家做出来的结果都差不多,缺乏新的东西出来。所以我再想,未来在大模型蓬勃发展的同时,有没有一个可能得方向就是让我们的视觉大模型具备数据选择能力的,在大量数据中可以去选择有价值的数据。这样好处是通过对数据的选择,同时持续的对新数据不断地进行迭代训练,那是否可能会在一些场景里面产生非常多样性的大模型或者预训练模型。例如,在同一个场景里面,因为每个大模型预训练任务的数据选择的方式不同,迭代的数据不同,使得在具体任务上的模型是具有多样性的,从而避免出现一个大模型统一天下的情况。这就是我的两个问题,谢谢各位。
谢谢丁凯老师,下面我们看看除了丁凯老师的问题,我们看看未来1~2年什么样的一个方向是值得我们往下做的。
我想首先回应一下刚才查老师的问题,就是大模型到底对我们有什么帮助,是否有什么负面的影响。这实际上是一个视觉研究中的路线之争的问题。肯定有人拥抱它,有人怀疑它,这都是正常的。我个人的观点是非常支持它的。我这里跟各位老师汇报一下,大概就是去年这个时候,北京智源人工智能研究院黄铁军老师带着我们一起,探索视觉大模型的构建,就是希望将来有一天视觉基础模型能够像今天的电力一样服务于千家万户。我们知道在信息域有一个链条,有基础软件,工业软件,那么将来视觉模型可能会类似于我们手机的操作系统。国家也特别支持,今年的2030新一代人工智能重大研究计划里面就支持了这个方向,并且希望将来能够开放共享,让大家去用,这还是非常有意义的。第二点查老师刚才已经讲了,就是目前还没有看到有大模型和没有大模型的本质变化。我认为确实也是这样的,现在除了在精度上有一些帮助之外在其他方面没有看到,但是不排除未来通过我们的努力,比如说5年或8年后,可能会出现一种解释性比较强、通用性比较好的基础模型。所谓通用性主要有两点,第一点是对视觉数据的通用性,不管是对可见光、红外、射频、雷达等等数据都有通用性;第二个是任务的通用性,包括检测、分割、识别等,所有任务都有通用性。如果真的能做出这个东西,我们传统的计算机视觉方法是做不了的。
大家好,我是清华大学的弋力。听到各位老师讨论之后有很多自己的想法和思考,可能也跟最后的这些问题有一些挂钩。我本身是做三维视觉的,三维点云的数据量是非常有限的,根本考虑不到大模型这个事情。因为很多时候我们都是要三维借助于二维的大模型,或者是借助语言的大模型去做一些事情。有的时候我也在想到底我们能从这个大模型中benefit到什么。我觉得今天讲的 language对我而言其实还挺有启发的,因为我觉得其实language对于这个场景的描述其实是包含了很多维度的东西,可能现阶段大模型更多的还是在研究有什么东西或者是什么东西的层面。也就是 language里面的concept可能影响我们对图片中concept的形成,但其实language里也会有很多关于为什么或者怎么样的一些描述,这是和认知推理相关的东西。那么我们可以思考一下,借助 language的信息去从 visual的feature中提取出一些有助于reasoning相关的一些特征,或者来帮助我们结合一些spatial的信息来更好的去预测物体的变化等等。这些可能可以真正能服务到下游的一些机器人视觉或者是机器人交互的一些层面上,对这个问题我还是非常感兴趣的。
再有一个就是黄高老师提到的多模态,卢老师刚刚也说要做既有3D又有2D的universal的模型。现在的2D大模型中对于视角的信息做得不好,3D在这个方面有天然的优势,但是缺少很匹配的文本数据。那是不是在整个交叉的领域里,我们可以搞一个更加universal的model。可能并不是每个领域都必须得有大的数据的支持,因为如果说需要3D的大的数据的支持,那恐怕现在可能只有车厂有雷达数据一类的信息。现在的深度图的数据也还是比较小体量的,所以最好是大模型能够benefit或者help其他的domain,我觉得这个会非常有价值,谢谢。
我觉得未来1~2年视觉基础模型最有前景发展方向既不是架构设计,也不是模型训练,而是定义一种更加通用的评价指标。现在天下苦ImageNet久矣,包括分类、检测、分割任务的定义,都已经是很久之前提出来的,不能适应现在的需求。那么我们怎么样定义一个新的指标,让这些任务都能统一起来,从而更好地往前推进视觉识别的一些本质问题,这是未来发展方向。我今天做的报告,就是希望往这个方向去走,谢谢大家。
RACV2022 | 计算机视觉前沿进展研讨会成功召开
RACV2022观点集锦 | 三维重建和沉浸式渲染