最全NLP中文文本分类实践(下)——Voting和Stacking的模型融合实现
前面的两篇文章中,我们完成了文件内容提取、中文分词、机器学习模型构建等任务。现在,我们希望对得到的模型效果做出优化。当然,有很多方法可以提升模型的表现,包括特征工程、调参、模型融合等。在这篇文章中,主要介绍针对模型融合的实践内容,即对多个baseline按一定的方法进行“融合”以期达到指标的提升。以下是前面两篇文章的链接。
最全NLP中文文本分类实践(上)——中文分词获取和Word2Vec模型构建
最全NLP中文文本分类实践(中)——SVM和基于keras的TextCNN实现
1 概念简介
所谓模型融合,其实就是字面意思,通过融合多个不同的模型来提升性能。最容易理解的模型融合有针对分类问题的Voting和回归问题的Average。在其基础上有改进或稍微复杂的有Bagging,Boosting,Stacking等。
- Voting
用多个模型对样本进行分类,以“投票”的形式,投票最多者为最终的分类。
- Average
对不同模型得出的结果取平均或加权平均。
- Bagging
先利用多次有放回抽样生成不同的训练集训练出不同的模型,将这些模型的输出结果通过上述两种方法综合得到最终的结果。随机森林就是基于Bagging算法的一个典型例子。
- Boosting
一种迭代的方法,每一次训练的时候都更加关心分类错误的样例,给这些分类错误的样例增加更大的权重,下一次迭代的目标就是能够更容易辨别出上一轮分类错误的样例。最终将这些弱分类器进行加权相加。
- Stacking
本质上是分层的结构。第一层是k折交叉的训练集,针对于每一折,由除自己以外的其他的训练数据训练出模型,并以此模型对这一折进行预测。按照此流程进行k次之后,我们得到了用不同模型预测训练集标签的结果,按顺序罗列之后作为第二层的训练集。再用k次训练的模型预测测试集标签,将得到的结果除以k取平均,作为第二层的测试集。随后,我们再用另一个模型去训练第二层的训练集并预测第二层的测试集,获取对原始的测试集的预测结果进行评估。
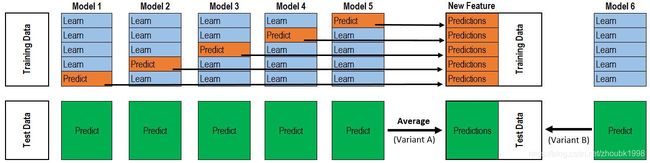
这一部分的内容概念可能用语言描述起来不太好理解,我是通过以下链接进行更直观的认知的。有需要的同学可以去加深一下理解认识。
【机器学习】模型融合方法概述
在本次实践中,我主要应用的是Voting和Stacking两种模型融合的方法,也将在下文中分别展开。
2 Voting实现
在此之前,我们先需要有几个预先存好的模型。最好是奇数个,这样不会出现特别多的平票的情况。我使用了5个模型进行voting,分别是TextCNN,以及5个和10个epochs分别训练出来的Word2Vec模型下,各自的SVM和神经网络分类器。
#模型融合
import joblib
import h5py
from tensorflow.keras.models import load_model
#导入五个提前保存好的模型
cnnmodel = load_model('textcnn.h5')
svm1model = joblib.load("download_w2v_svm.m")
svm2model = joblib.load("download_w2v_10epochs_svm.m")
nn1model = joblib.load("download_w2v_nn.m")
nn2model = joblib.load("download_w2v_10epochs_nn.m")
#由于CNN模型和其他分类器模型所产生的标签格式是不一致的
#因此需要应用不同的测试集特征格式,并将预测结果进行统一
y_cnnpred = cnnmodel.predict(X_testcnn, batch_size=64,
verbose=0, steps=None,
callbacks=None, max_queue_size=10,
workers=1, use_multiprocessing=False)
y_svm1pred = svm1model.predict_proba(X_testclf)
y_svm2pred = svm2model.predict_proba(X_testclf)
y_nn1pred = nn1model.predict_proba(X_testclf)
y_nn2pred = nn2model.predict_proba(X_testclf)
#获取one-hot标签形式
y_cnnpred = np.rint(y_cnnpred)
y_nn1pred = np.rint(y_nn1pred)
y_nn2pred = np.rint(y_nn2pred)
y_svm1pred = np.rint(y_svm1pred)
y_svm2pred = np.rint(y_svm2pred)
#加和投票
y_ensemble = y_cnnpred + y_svm1pred + y_svm2pred + y_nn1pred + y_nn2pred
y_pred_ensemble = y_ensemble.argmax(axis=1)
#Confusion Matrix and report
print(confusion_matrix(y_test, y_pred_ensemble))
print(classification_report(y_test, y_pred_ensemble, digits=4))
最终,该融合模型可以达到了90.77%的准确率和88.57%的macro f1,这在我目前的所有模型中达到最好的效果,也比上一节只是用SVM分类器多个指标提高了1%以上。
3 Stacking实现
拿下了目前为止的最优模型表现,我们一鼓作气向Stacking方法前进。Stacking在原理上其实没有很难理解,实现上也不是特别复杂。当然,我个人对这个方法所能达到的效果还是有些怀疑,虽然是应用交叉验证进行了模型融合,但是双层的训练结构其实也会一定程度上会造成错误的累加。虽然初衷是降低泛化的误差,但是略显复杂的模型结构也容易造成过拟合。简单进行了一些思考和预估之后,开始实践。
def get_stacking(clf,X_train,y_train,X_test,n_folds):
"""
x_train, y_train, x_test 的值应该为numpy里面的数组类型 numpy.ndarray .
"""
#初始化
train_num, test_num = X_train.shape[0], X_test.shape[0]
second_level_train_set = np.zeros((train_num,))
second_level_test_set = np.zeros((test_num,))
test_nfolds_sets = np.zeros((test_num, n_folds))
#创建k折数据
skf = StratifiedKFold(n_splits=n_folds)
for i,(train_index, test_index) in enumerate(skf.split(X_train,y_train)):
X_tra, y_tra = X_train[train_index], y_train[train_index]
X_tst, y_tst = X_train[test_index], y_train[test_index]
clf.fit(X_tra, y_tra)
#获得第二层训练集
second_level_train_set[test_index] = clf.predict(X_tst)
test_nfolds_sets[:,i] = clf.predict(X_test)
#获得第二层测试集,取平均
second_level_test_set[:] = test_nfolds_sets.mean(axis=1)
return second_level_train_set, second_level_test_set
get_stacking()是针对一个模型进行k折交叉验证。和刚才的Voting方法相同,我们同样导入所需要的的模型。
import joblib
rfmodel = joblib.load("download_w2v_rf.m")
svm1model = joblib.load("download_w2v_svm.m")
svm2model = joblib.load("download_w2v_10epochs_svm.m")
nn1model = joblib.load("download_w2v_nn.m")
nn2model = joblib.load("download_w2v_10epochs_nn.m")
train_sets = []
test_sets = []
for clf in [rfmodel, svm1model, svm2model, nn1model, nn2model]:
train_set, test_set = get_stacking(clf, X_train, y_train, X_test,n_folds=5)
train_sets.append(train_set)
test_sets.append(test_set)
meta_train = np.concatenate([result_set.reshape(-1,1) for result_set in train_sets], axis=1)
meta_test = np.concatenate([y_test_set.reshape(-1,1) for y_test_set in test_sets], axis=1)
这时我们已经获取了第二层的训练集和测试集,接下来我们再用一个新的模型去进行训练和预测。
from sklearn import svm
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import f1_score
#Find the svm(rbf) model with highest f1 score
clfsecond = svm.SVC()
grid_values = {'gamma': [0.001, 0.01, 0.05, 0.1, 1, 10],
'C':[0.01, 0.1, 1, 10, 100]}
grid_clf = GridSearchCV(clfsecond, param_grid = grid_values,scoring = 'f1_macro')
grid_clf.fit(meta_train, y_train)
y_grid_pred = grid_clf.predict(meta_test)
print('Test set F1: ', f1_score(y_test,y_grid_pred,average='macro'))
print('Grid best parameter (max. f1): ', grid_clf.best_params_)
print('Grid best score (accuracy): ', grid_clf.best_score_)
最终合适的参数为{‘C’: 10, ‘gamma’: 0.01}。在这组参数下,我们获得的结果为85.83%的准确率和82.65%的macro f1,果然效果不是很好。当然,在这次实践中效果一般,不能否定其价值,也许是我在某些细节上还没有做到位,也欢迎大家给予更多意见和建议。
4 Badcase分析
为了更好地发现模型对于某些有共性案例的错误判断,我们往往会对预测错误的badcase进行分析。
#badcase 预测标签和实际标签不一样的案例
test = pd.read_csv('article_features_test.csv')
test['predict'] = pd.Series(y_pred_ensemble.tolist())
badcase = test[test.label != test.predict]
truecase = test[test.label == test.predict]
之前已经发现,模型对历史类别的分类表现较差,因此我们着重去观察历史类的错误分类文档,发现这些文章一部分是文物的出土,可能是因为这部分词的词频过低,因此在Word2Vec模型中就没有得到很好的训练,不巧这些词又在文章中扮演着重要作用,因此造成了判定错误的结论。当然,更多的历史文章都是讲述历史中的一个课题,比如过去某个时段的事件或名人,某种文化的发展进程等等,我们很难单独把历史这个类别割裂出来,这也造成了其准确率较差的表现。
当然,以上仅是我对一些表现的原因分析,至于如何去完善或修正这些badcases,我在Word2Vec模型上的改进尝试没有取得理想的效果,或许添加一些预知的规则会有用,但是其实还是没有明确的思路。如果各位有什么经验或想法的话欢迎多多交流。
5 小结
通过模型融合,我们确实提升了模型的性能,尽管没有特别高的突破,但也是有所收获。至此,我们已经完整的完成了中文文本分类的全过程,包括文件提取,中文分词,词向量表达,模型构建和模型融合。当然,每一个部分都是以实践为主,而实践的方法肯定也会有不同之处。比如,将文本转化为向量会有其他方法,而模型的构建也是多种多样。只是我在学习过程中,发现每一个部分的知识都比较碎片,少有把整个过程整合起来的文章,所以既然自己也已经完成了一次中文文本分类的实践,就把自己所用到的方法略作总结,算是对知识的回顾也希望能为有需要的人提供帮助。如果有不足和错误也欢迎大家在评论区指出,很希望和大家交流心得!
注:转载请注明出处!