深度学习之路=====10=====>>Resnext(tensorflow2)
简介
类型:2017CVPR 作者: Kaiming He组
和其他轻量级网络特点一样,Resnext也是通过降低参数量来改进模型,提高模型精度的。该模型基于Inception的split-transform-merge范式和VGG堆叠网络,将Resnet的单路卷积变成多路卷积(分组卷积),与Inception的区别是该模块的所有支路采用相同的拓扑结果。
作者认为split-transform-merge是通用的神经网络标准范式,
用如下公式表示:

作者引入Resnext后的表达式为:
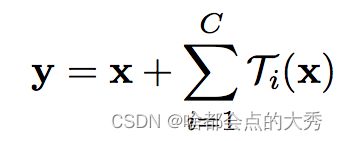
x表示short-cut, C表示cardinality,即分组个数-独立且相同的拓扑结构, τ ( x ) \tau \left( x \right) τ(x)表示任意变换,最后进行merge。
特点
- 增加 cardinality 比增加深度和宽度更有效;
- 采用 VGG 堆叠的思想和 Inception 的 split-transform-merge 思想,可扩展性比较强;
- 101 层的 ResNeXt 比 200 层的 ResNet 更好;
- 用一种平行堆叠相同拓扑结构的blocks代替原来 ResNet 的三层卷积的block,在不明显增加参数量级的情况下提升了模型的准确率,同时由于拓扑结构相同,超参数也减少了,便于模型移植。
创新点
- 采用相同拓扑结构的分组卷积,引入cardinality用来表示对通道的分组数
- 降低参数量和计算量
下图左右分别为Resnet和Resnext的基本block,其中Resnext-block符合作者提到的split-transform-merge范式
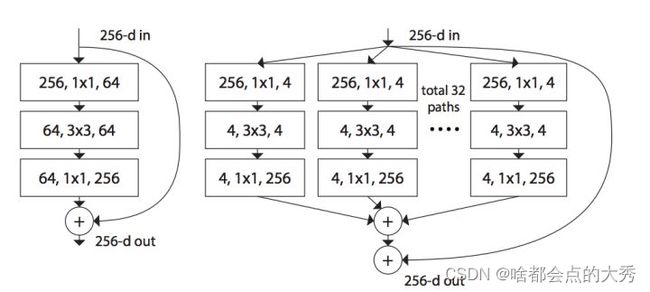
ResNext的BottleNeck结构:
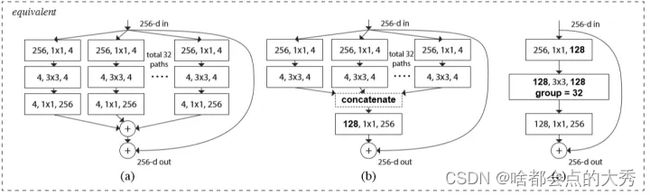
下图中的三种结构为等价结构,其中©结构较前两种实现简单,文中使用©结构。
网络结构
方括号内容表示Block中的网络设置

容易忽略的点:
- Resnext中相邻间Repeat stage中的第二块stage中的第一个block中的GC(分组卷积)的步长为2,也就是上表中conv3,conv4,conv5的第一个block中的分组卷积步长为2,这样,相邻间Repeat stage的输出尺寸差2倍(28->14->7)。
- 上面的步长变化导致对应块中的short-cut层的卷积步长也要对应为2,这样经过各自的卷积计算后,他们的尺寸仍然一致,可以进行“+”计算。
代码
import tensorflow as tf
import numpy as np
from tensorflow.keras.layers import *
from tensorflow.keras import Model
class Conv(Model):
def __init__(self,filters,kernel_size=1,strides=1):
super().__init__()
self.layers_list=[]
self.layers_list.append(Conv2D(filters,kernel_size=kernel_size,strides=strides,padding='same'))
self.layers_list.append(BatchNormalization())
self.layers_list.append(Activation('relu'))
def call(self,x):
for layer in self.layers_list:
x=layer(x)
return x
class Group_Conv(Model):
def __init__(self,strides,cardinality,in_channels):
super().__init__()
self.cardinality=cardinality
self.channels_per_group=in_channels//cardinality
assert self.channels_per_group>0 ,"erro!!,the channels of per group is less 0"
self.gc_list=[]
for i in range(cardinality):
self.gc_list.append(Conv2D(self.channels_per_group,kernel_size=3,strides=strides,padding='same'))
self.b=BatchNormalization()
self.a=Activation('relu')
def call(self,input):
x_list=tf.split(input,self.cardinality,axis=-1)
for i,group_conv in enumerate(self.gc_list):
x_list[i]=group_conv(x_list[i])
x=tf.concat(x_list,axis=-1)
x=self.b(x)
output=self.a(x)
return output
class Resnext_block(Model):
def __init__(self,in_channels,strides,cardinality):
super().__init__()
self.residual=[]
self.residual.append(Conv2D(filters=in_channels*2,kernel_size=1,strides=strides,padding='same'))
self.residual.append(Activation('relu'))
self.out_channels=in_channels*2
self.layers_list=[]
self.layers_list.append(Conv(in_channels))
self.layers_list.append(Group_Conv(strides,cardinality,in_channels))
self.layers_list.append(Conv(self.out_channels))
def call(self,x):
#print(x.shape)
input=x
for residual_layer in self.residual:
input=residual_layer(input)
residual=input
#print(residual.shape)
for layer in self.layers_list:
x=layer(x)
y=x+residual
#print(y.shape)
return y
class Resnext(Model):
def __init__(self,repeat_list,filters=64,cardinality=32):
super().__init__()
self.in_channels=filters
self.layers_list=[]
self.layers_list.append(Conv(self.in_channels,kernel_size=7,strides=2))
self.layers_list.append(MaxPooling2D(pool_size=(3,3),strides=2,padding='same'))
for j,repeat in enumerate(repeat_list):
self.in_channels=self.in_channels*2
#print(self.in_channels)
for i in range(repeat):
if j!=0 and i==0:
strides=2
else:
strides=1
self.layers_list.append(Resnext_block(self.in_channels,strides,cardinality))
self.layers_list.append(GlobalAveragePooling2D())
self.layers_list.append(Dense(1000,activation='softmax'))
def call(self,x):
for layer in self.layers_list:
x=layer(x)
#print(x.shape)
return x
##用一个数据验证模型正确性
model = Resnext(repeat_list=[3,4,6,3])
inputs = np.zeros((1, 224, 224, 3), np.float32)
model(inputs).shape
model.summary()
##模型结构和图中提到的一致,但是最终的参数量和比论文中多几乎一半,不解。
#这是每个block输出的shape,与表中一致
(1, 112, 112, 64)
(1, 56, 56, 64)
(1, 56, 56, 256)
(1, 56, 56, 256)
(1, 56, 56, 256)
(1, 28, 28, 512)
(1, 28, 28, 512)
(1, 28, 28, 512)
(1, 28, 28, 512)
(1, 14, 14, 1024)
(1, 14, 14, 1024)
(1, 14, 14, 1024)
(1, 14, 14, 1024)
(1, 14, 14, 1024)
(1, 14, 14, 1024)
(1, 7, 7, 2048)
(1, 7, 7, 2048)
(1, 7, 7, 2048)
(1, 2048)
(1, 1000)
Model: "resnext_16"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv_498 (Conv) multiple 9728
_________________________________________________________________
max_pooling2d_11 (MaxPooling multiple 0
_________________________________________________________________
resnext_block_243 (Resnext_b multiple 64768
_________________________________________________________________
resnext_block_244 (Resnext_b multiple 138496
_________________________________________________________________
resnext_block_245 (Resnext_b multiple 138496
_________________________________________________________________
resnext_block_246 (Resnext_b multiple 351744
_________________________________________________________________
resnext_block_247 (Resnext_b multiple 548352
_________________________________________________________________
resnext_block_248 (Resnext_b multiple 548352
_________________________________________________________________
resnext_block_249 (Resnext_b multiple 548352
_________________________________________________________________
resnext_block_250 (Resnext_b multiple 1395712
_________________________________________________________________
resnext_block_251 (Resnext_b multiple 2182144
_________________________________________________________________
resnext_block_252 (Resnext_b multiple 2182144
_________________________________________________________________
resnext_block_253 (Resnext_b multiple 2182144
_________________________________________________________________
resnext_block_254 (Resnext_b multiple 2182144
_________________________________________________________________
resnext_block_255 (Resnext_b multiple 2182144
_________________________________________________________________
resnext_block_256 (Resnext_b multiple 5560320
_________________________________________________________________
resnext_block_257 (Resnext_b multiple 8706048
_________________________________________________________________
resnext_block_258 (Resnext_b multiple 8706048
_________________________________________________________________
global_average_pooling2d_13 multiple 0
_________________________________________________________________
dense_13 (Dense) multiple 2049000
=================================================================
Total params: 39,676,136
Trainable params: 39,615,592
Non-trainable params: 60,544
参考
深度学习——分类之ResNeXt
ResNeXt算法详解