深入分析序列化和反序列化原理,终于知道serialVersionUID到底有什么用了
一个问题引发的思考
下面是一个简单的socket通信demo。
通信数据类:
package com.zwx.serialize.demo;
public class SocketUser {
public SocketUser(String id, String name) {
this.id = id;
this.name = name;
}
private String id;
private String name;
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
socket服务端:
package com.zwx.serialize.demo;
import com.alibaba.fastjson.JSONObject;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.net.ServerSocket;
import java.net.Socket;
public class SocketServer {
public static void main(String[] args) {
//ServerSocket用于TCP/IP中的客户端连接
ServerSocket serverSocket = null;
try {
//使用ServerSocket监听8888端口
serverSocket = new ServerSocket(8888);
//获取请求连接
Socket socket = serverSocket.accept();
ObjectInputStream input = new ObjectInputStream(socket.getInputStream());
SocketUser user = (SocketUser) input.readObject();
System.out.println(JSONObject.toJSONString(user));
}catch (Exception e){
e.printStackTrace();
}finally {
if (null != serverSocket){
try {
serverSocket.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
socket客户端:
package com.zwx.serialize.demo;
import java.io.IOException;
import java.io.ObjectOutputStream;
import java.net.Socket;
public class SocketClient {
public static void main(String[] args) {
Socket socket = null;
ObjectOutputStream out = null;
try {
socket = new Socket("localhost",8888);
SocketUser user = new SocketUser("1","张三");
out = new ObjectOutputStream(socket.getOutputStream());
out.writeObject(user);
}catch (Exception e){
e.printStackTrace();
}finally {
if (null != out){
try {
out.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (null != socket){
try {
socket.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
接下来我们先启动socket服务端,然后再启动socket客户端,这时候客户端就会连接上服务端进行通讯数据传输。
运行时却发现,报错了,提示我们没有序列化:
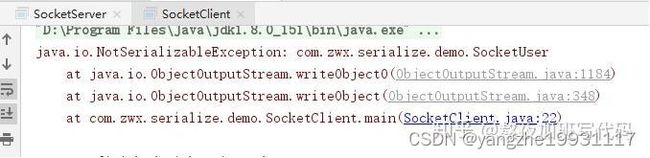
这时候我们把类SocketUser改一下,实现序列化接口:
public class SocketUser implements Serializable{
再次运行,发现这时候服务端可以正常输出我们传入的SocketUser对象了:
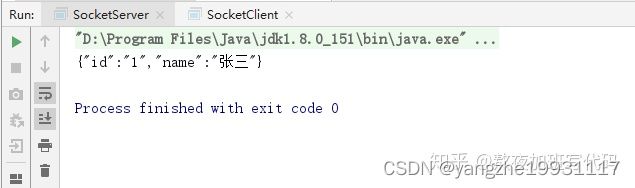
所以我们可以知道,当我们在远程通信的时候,必须要序列化数据才能正常传输,那么到底什么是序列化,什么又是反序列化呢?
什么是序列化和反序列化
序列化:是把对象的状态信息转化为可存储或传输的形式过程,也就是把对象转化为字节序列的过程称为对象的序列化。
反序列化:是序列化的逆向过程,把字节数组反序列化为对象,把字节序列恢复为对象的过程称为对象的反序列化。
为什么需要序列化
序列化的本质是为了进行网络数据传输,而数据又只能够以二进制的形式在网络中进行传输,所以我们就需要把对象转为二进制的形式,也就是需要序列化这么一个过程,而因为二进制形式对我们使用者来说是不方便的,所以就需要有一个反序列化的过程,将数据重新还原。
序列化方式
1、Java自带的序列化方式(实现Serializable 接口),2、json序列化,xml序列化等(变为字符数组传输二进制数据流,Restful接口里请求响应通用做法)。
serialVersionUID的作用
当我们在实现序列化接口Serializable时候,可以手动生成一个serialVersionUID,有两种表现形式:
private static final long serialVersionUID = -2426545572670767992L;
private static final long serialVersionUID = 1L;
那么这两种形式有什么区别?serialVersionUID 又到底有什么用呢?为了说明这两个问题,我们还是先来看一个例子:
SocketUser沿用上面的类,但是不要添加serialVersionUID属性
package com.zwx.serialize;
import com.alibaba.fastjson.JSONObject;
import com.zwx.serialize.demo.SocketUser;
import java.io.*;
public class TestJavaSerialize {
public static void main(String[] args) {
//代码片段A:序列化
SocketUser socketUser = new SocketUser("1","张三");
serialize(socketUser);
//代码片段B:反序列化
//SocketUser socketUser2 = deSerialize();
//System.out.println(JSONObject.toJSONString(socketUser2));
}
static void serialize(SocketUser user){
try {
ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream(new File("G:\\user")));
out.writeObject(user);
} catch (IOException e) {
e.printStackTrace();
}
}
static SocketUser deSerialize(){
try {
ObjectInputStream in = new ObjectInputStream(new FileInputStream(new File("G:\\user")));
return (SocketUser) in.readObject();
}catch (Exception e){
e.printStackTrace();
}
return null;
}
}
上面的例子中,我们把创建好的SocketUser对象初始化到了本地文件中,然后先不要反序列化,我们在SocketUser类中自动生成serialVersionUID = -2426545572670767992L;
然后把上面的代码片段A注释掉,把代码片段B打开注释,运行,发现反序列化成功,这个没有问题。好,那我们把serialVersionUID = -2426545572670767992L;换成serialVersionUID =1L,再去运行,这时候发现报错了:

这是因为如果我们没有生成serialVersionUID的话,那么当序列化的时候,会自动在序列化对象中自动生成serialVersionUID,而如果我们没有修改过类中的方法和属性,这个值是不会变的,所以我们序列化之后再去生成serialVersionUID,因为算法一直,所以两边的UID依然是相同的,但是我们改成了1L就不行了,会导致UID不相等,无法反序列化,当然,如果我们手动修改serialVersionUID值,也会导致匹配不上,或者说我们修改了类的属性和方法之后再去重新生成,也会导致匹配不上而无法反序列化。
serialVersionUID的两种表现形式
serialVersionUID默认有两种表现方式:
- 一种是根据类名、接口名、成员方法及属性等来生成一个 64 位的哈希字段。
比如:private static final long serialVersionUID = -2426545572670767992L;。 - 另一种就是1L。
比如private static final long serialVersionUID = 1L;
如果我们没有手动生成serialVersionUID,则系统会默认采用第一种方式生成,如果我们此时又手动采用了第二种方式生成serialVersionUID,那么反序列化的时候就会发现两边的UID匹配不上,导致反序列化失败。
Transient关键字
Transient 关键字的作用是控制变量的序列化,在变量声明前加上该关键字,可以阻止该变量被序列化到文件中,在被反序列化后,transient 变量的值被设为初始值,如 int 型的是 0,对象型的是null。
如我们把上面的name属性加上transient 关键字之后再去序列化:
private transient String name;
然后反序列化可以看到name=null:
不过,我们有办法可以绕开transient 关键字,从而使得transient 关键字失效。这就是下面的两个方法:writeObject和readObject的作用了。
writeObject和readObject
我们把上面的SocketUser类进行一下改写:
package com.zwx.serialize.demo;
import java.io.IOException;
import java.io.Serializable;
public class SocketUser implements Serializable{
public SocketUser(String id, String name) {
this.id = id;
this.name = name;
}
private String id;
private transient String name;
private void writeObject(java.io.ObjectOutputStream s) throws IOException {
s.defaultWriteObject();
s.writeObject(name);
}
private void readObject(java.io.ObjectInputStream s) throws IOException, ClassNotFoundException {
s.defaultReadObject();
name=(String)s.readObject();
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
然后再去序列化和反序列化,发现name属性已经可以被反序列化出来了:
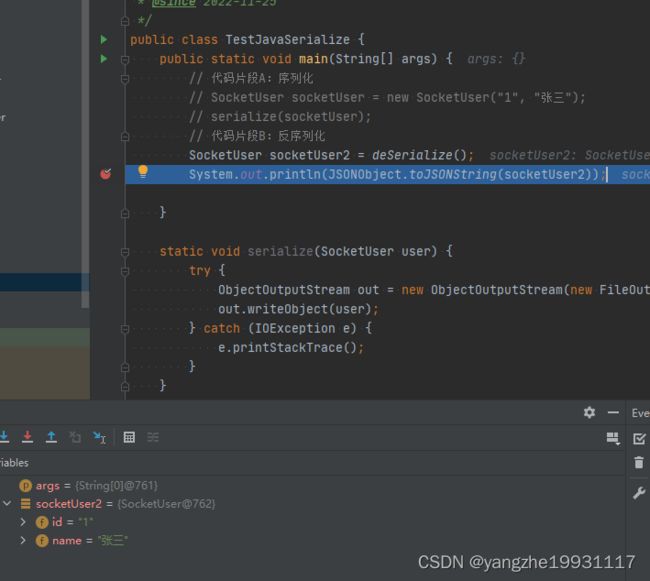
实际输出的时候还是没有name的属性
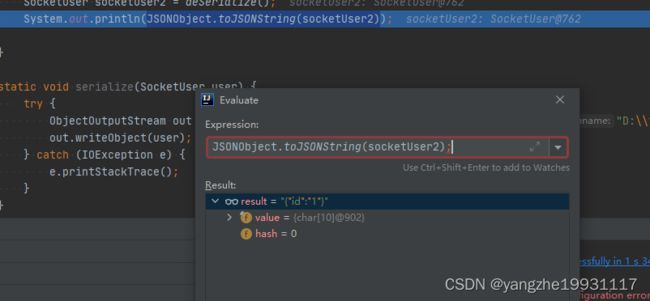
Java序列化特点
1、Java序列化只是针对对象的状态进行保存,至于对象中的方法,序列化不关心。
2、当一个父类实现了序列化,那么子类会自动实现序列化,不需要显式实现序列化接口。
3、当一个对象的实例变量引用了其他对象,序列化这个对象的时候会自动把引用的对象也进行序列化(实现深度克隆)。
4、当某个字段被申明为transient后,默认的序列化机制会忽略这个字段。
5、被申明为transient 的字段,如果需要序列化,可以添加两个私有方法:writeObject 和 readObject 。
Java序列化缺点
如果会用Java序列化会有两个缺点:
- 不能跨语言。序列化本身就是为了数据传输,那么不能跨语言,就说明通信的对方也必须是Java语言才行,这一点就造成了很大的局限性。
- 序列化之后数据比较大。远程通信数据包越小效率就越高,所以序列化之后的二进制流越小,性能越高。
常用三种序列化方式对比
同样一个对象,序列化之后的大小FastJson是最小的,而XML最大。而数据包越大,相对来说通讯的性能就会越低。
针对性能要求不高的场景,可以采用基于XML的SOAP协议。
基于前后端分离,或者独立的对外的 api 服务,选用JSON是比较好的,对于调试、可读性都很不错。
其他序列化
Hessian序列化:
Hessian是一个支持跨语言传输的二进制序列化协议,相对于Java默认的序列化机制来说, Hessian具有更好的性能和易用性,而且支持多种不同的语言。实际上Dubbo采用的就是Hessian 序列化来实现,只不过Dubbo对Hessian进行了重构,性能更高。
Protobuf 序列化:
Protobuf是Google的一种数据交换格式,它独立于语言、独立于平台。Google提供了多种语言来实现,比如Java、C、Go、Python,每一种实现都包含了相应语言的编译器和库文件, Protobuf是一个纯粹的表示层协议,可以和各种传输层协议一起使用。 Protobuf使用比较广泛,主要是空间开销小和性能比较好,非常适合用于公司内部对性能要求高的 RPC调用。 另外由于解析性能比较高,序列化以后数据量相对较少,所以也可以应用在对象的持久化场景中。
Protobuf使用会相对麻烦些,因为他有自己的语法,有自己的编译器,如果需要用到的话必须要去投入成本在这个技术的学习中 。
protobuf还有个缺点就是要传输的每一个类的结构都要生成对应的proto文件,如果某个类发生修改,还得重新生成该类对应的proto文件。