双目立体匹配_DispNet网络
双目立体匹配_DispNet网络
19世纪,物理学家Wheaston偶然发现,如果两眼同时看到两块金属板上反射的稍有不同的蜡烛火焰图像,融合后就会产生实体感,他将这一深度感知现象称为"立体视觉",并在此基础上发明了实体镜,使得空间知觉研究从自然观察进入了实验室研究阶段。后续Bela Julesz使用计算机生成随机点立体图对,证实了只要存在视差就能产生深度感知,引起了立体视觉理论的革命。
20世纪60年代,MIT的Roberts通过计算机程序从数字图像中提取出了诸如立方体、棱柱体等多面体的三维结构,并对物体形状及空间关系进行描述,开创了以理解三维场景为目的的计算机视觉研究。20世纪70年代,MIT人工智能实验室创立了计算机视觉研究小组并开设相关课程,吸引许多学者投入到计算机视觉研究。
KITTI双目视觉数据集下载:https://www.it610.com/article/1280077151294472192.htm
文章目录
- 双目立体匹配_DispNet网络
- 一、引言
- 二、DispNet网络
- 三、实验过程
- 四、想法
- 五、源代码
一、引言
基于3D代价体的端到端立体匹配网络接近于传统的密集回归问题(如语义分割、光流估计等)的神经网络模型,受U-Net模型的启发,该类型端到端网络的设计中部署了编码器解码器结构,以减少内存需求并增加网络的感受野,从而更好的利用图像的上下文信息。
U-Net是Ronneberger等人针对细胞图像设计的图像分割网络,构建了一个近似对称的编解码结构。U-Net使用图像块进行训练,使得训练数据量远远大于训练图像的数量,非常适合只有少量样本的应用场景。后来还出现了很多基于U-net网络的变体,广泛应用到了各个领域。
二、DispNet网络
DispNet是Mayer等人基于光流估计网络FlowNet提出的一个非常经典的视差估计网络。与U-Net网络结构类似,DispNet先在收缩路径上进行特征提取与空间压缩,然后在扩张路径进行尺度恢复与视差预测,并通过长距离跳跃连接实现多层次特征融合,保留更多的网络层信息。根据对输入图像的处理方法不同,DispNet有DispNetS和DispNetC两种网络结构。
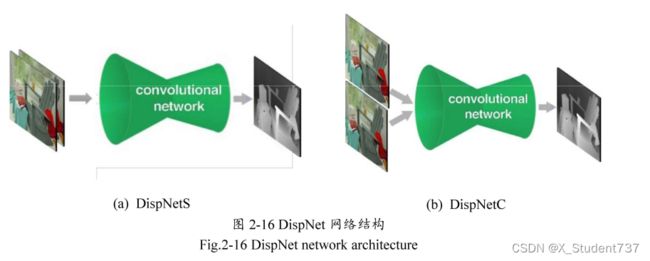
DispNetS网络将左右RGB图像对进行堆叠作为输入,让网络完全自主学习左右图像中的匹配关系。在收缩路径上进行了六次下采样操作,其中前三个卷积层分别使用了一个卷积核大小为(7, 7)和两个卷积核大小为(5, 5)的卷积层,然后交替使用卷积核大小为(3, 3),填充像素为1,步长为2和步长为1的卷积层,即提取一次特征后,就使用下采样将图像的分辨率缩小一半,重复四次,使得收缩路径的总下采样因子1/64。
DispNetC与DispNetS的最大区别是,DispetC使用参数共享的双分支网络对输入图像分开处理,每个分支对应一个特征提取模块,并在第三个卷积层后使用一个相关层(Correlation layer)对左右分支提取的特征图进行向量内积,来模拟标准立体匹配过程中的代价计算。然后将相关计算得到的代价匹配量与参考图像分支的特征图进行拼接,输入到网络的下一层,后续处理与DispNetS相同。相关层的主要优点是,在不增加额外训练参数的情况下引入了先验几何知识,提升了网络精度和效率。
DispNet的扩张路径由一系列反卷积层构成,主要目的是实现尺度恢复与视差优化。编码器的最后一层卷积层会在1/64特征图上进行视差预测,得到一个粗糙的低尺度视差图,然后对该尺度的特征图与视差图进行反卷积,扩大到1/32分辨率。由于下采样操作会损失部分空间信息,已经丢失的信息无法通过反卷积进行恢复。为了弥补因特征空间尺度缩小而损失的位置信息,DispNet使用跳跃连接的方法将扩大后的特征图、视差图和收缩路径中对应尺度的特征图进行拼接,使得下一个反卷积层进行尺度恢复时可以同时利用深层的语义信息与浅层的细节信息,得到更精细准确的视差图。将该操作重复五次以后,最终可以得到分辨率大小为输入图像尺度1/2的视差图。
三、实验过程
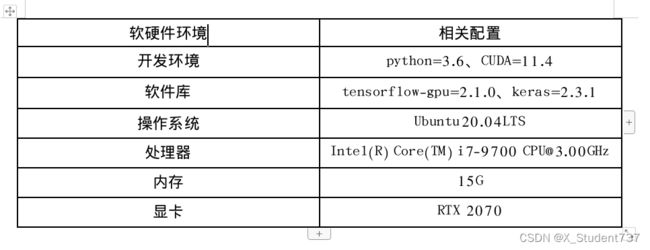
选用KITTI2015数据集中的image_2、image_3、disp_occ_0文件夹训练,共含有200对双目图像,其中180对用作训练,20对用作测试。原始图像尺寸为(375, 1242),真实视差图尺寸为(375, 1242),由激光雷达采集得到(稀疏视差图),仅在视差大于0的像素位置提供真值。实验在Ubuntu环境下进行,具体的计算机硬件及相关环境配置如下表所示:
模型训练时使用到一些特殊处理技巧如下:
1、DispNet最后一层采用relu激活函数,img_left、img_right除以255归一化,disp数值不做归一化处理,其取值范围在[0, img_w]范围内。
2、KITTI2015的视差图为稀疏视差图,只在视差大于0的像素位置提供真值。在计算损失时,依旧采用L2回归损失,但仅对y_true大于0的像素部分进行处理,其余像素位置的损失值忽略。
3、KITTI2015数据集的原始图像尺寸为(375, 1242),近似4:1的长宽比,为防止图像产生形变,修改网络输入为input_w=512、input_h=128,降低对视差匹配的影响。
4、在对图像尺寸做resize后,原始视差图的数值也应相应缩放,以保证视差偏移正好对应于缩放后左目和右目,否则网络学习的逻辑是错误的,即视差数值乘以input_w / (2 * raw_w)。
将优化器设置为Adam,学习率设置为1e-4,batch_size设置为4,epoch设置为100,训练过程中的损失和视差精度如下图所示,其中视差精度表示为视差偏差在3像素以内(包括3像素)的像素占所有有效像素(含视差真值)的比例。
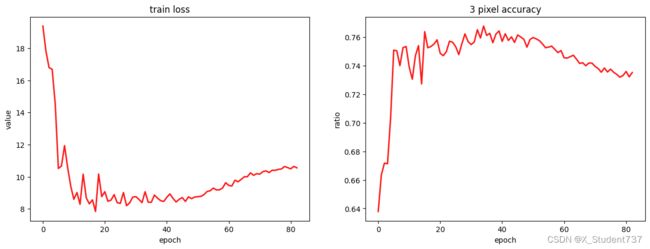
由训练结果可知,模型在epoch=35左右训练效果较佳,因为KITTI2015数据量较小,随着epoch增大,后续出现了一些过拟合现象,模型效果反而下降。选取epoch=39时的训练权重,对KITTI2015测试集中20对双目图像进行测试,预测视差效果如下图所示,其中左图代表DispNet网络预测视差图,右图代表真实稀疏视差图。
计算测试集20对双目图像的计算耗时和视差精度,视差精度表示为视差偏差在3像素以内(包括3像素)的像素占所有有效像素(含视差真值)的比例,可得测试集20对双目图像的平均视差精度为76.82%,平均计算耗时为0.081s。
四、想法
1、KITTI2015数据量太小,难以训练出好的效果,而且KITTI2015本身视差图是稀疏的,对网络学习带来了很大干扰。
目前通用处理技巧是,先在sceneflow数据集上预训练,后在KITTI2015数据集上微调。
2、DispNet算法运行速度足够优异,在RTX2080硬件下,单张图片在(512, 128)分辨率下接近0.08s的推理速度。
3、针对DispNet网络输出层对视差值的预测,到底是输出[0, 1]归一化结果,还是直接输出[0, img_w]的视差偏移数值,仍有待仔细思考。此处我偏向于后一种,因为不同图片的最大视差值都不一样,难以找到一个合适的归一化数值,另外在传统立体匹配构建视差代价体时,也是直接从视差绝对值这个方向处理的。
4、切记,在对图像尺寸做resize后,原始视差图的数值也应相应缩放,即视差数值乘以input_w / (2 * raw_w),以保证视差偏移正好对应于缩放后左目和右目,否则网络学习的逻辑是错误的,网络训练时效果会很差,而且loss难以下降,因为本身强行拟合的逻辑就是错误的。
五、源代码
如果需要源代码,或者想直接使用数据集,可以去我的主页寻找项目链接,以上代码和实验结果都由本人亲自实验得到:
https://blog.csdn.net/Twilight737