基于VggNet网络与ResNet神经网络的物体分类识别研究-附Matlab代码
⭕⭕ 目 录 ⭕⭕
- ✳️ 一、引言
- ✳️ 二、VGGNet网络与ResNet网络模型
-
- ✳️ 2.1 VGG16 网络
- ✳️ 2.2 ResNet-18网络
- ✳️ 三、训练与实验结果
-
- ✳️ 3.1 CIFAR-10 数据集
- ✳️ 3.2 ResNet-18训练与识别结果
- ✳️ 3.3 VGG16 网络训练与识别结果
- ✳️ 四、参考文献
- ✳️ 五、Matlab代码获取
✳️ 一、引言
近年来,随着计算机技术的飞速进步, 图像分类具有非常强的实际应用价值,一直是计算机视觉方向的一个重要研究课题, 图像分类是将具有相同属性的目标划分为一个类别,从分类的细致程度上分为粗粒度分类和细粒度分类两种。 早期分类类别属性差异较大的分类就是粗粒度分类,比如猫狗猴子的动物类别分类,目前粗粒度分类与人们日常生活息息相关,具有不可或缺的地位,粗粒度分类的研究还有很大发展空间。但随着技术和人们思维的发展,人们不再局限于粗粒度分类上,于是提出了细粒度图像分类这一概念,细粒度图像分类是指在识别出图像中目标物体的基础上,进行更细致类别区分,与粗粒度图像分类不同的是, 细粒度图像分类是在同一类属性的目标物体下进行类别区分,比如分类车的款式、鸟的品种、方便面的品牌等。在产品质量检测、生物多样性自动监测、智能零售、智能交通监测等方面有广泛的应用价值。
✳️ 二、VGGNet网络与ResNet网络模型
✳️ 2.1 VGG16 网络
深度卷积神经网络在细粒度图像分类任务中的应用非常普遍,常见的深度卷积神经网络有 AlexNet、 Res-Net、 VGG-Net 等。 VGG-Net 是由牛津大学的 Visual Geometry Group 于 2014 年提出。 VGG-Net 有多种配置方式例如 VGG-A、 VGG-B、 VGG-D 等。VGG-D 是 VGG-Net 中使用最普遍的配置方式, VGG-D 有 16 个权重层,其中包括13 个卷积层、 2 个全连接层和 1 个分类层,因此 VGG-D 又被称作 VGG16。本框架使用的基础神经网络是 VGG16 网络,同时 VGG16 网络也是本文的基准网络之一,本节将对 VGG16 网络展开详细的介绍,其结构如图1所示:

如图1所示, VGG16 网络由 5 个卷积块、 2 个全连接层和 1 个分类层组成。第一个卷积块由 2 个卷积层和 1 个池化层组成, 其中每个卷积层均含有 64 个卷积核,且卷积核的尺寸分别为 3× 3× 3 和 3× 3× 64,两个卷积层的像素填充值均为 1,步长也均为 1,可知图像经第一个卷积块的 2 个卷积层提取特征后并没有改变输出特征图的尺寸。 在第一个卷积块的池化层中滑动窗口的尺寸为 2× 2,滑动步长为 2,因此经一次池化操作后特征图的尺寸缩为输入特征图的 1/2。在其余后续四个卷积块中分别有 2、 3、 3、 3 个卷积层并且每一个卷积块之后都连接一个最大池化层。第二个卷积块的 2 个卷积层均有 128 个卷积核,第三个卷积块的三个卷积层均有 256 个卷积核,第四和第五个卷积块的所有卷积层均有 512 个卷积核,并且所有卷积层的卷积核的二维平面尺寸均为 3× 3,只是不同卷积层的卷积核在深度上不同,像素填充值为 1,步长为 1,因此可知在 VGG16 网络中卷积操作均不改变特征图的尺寸,而在后续 4 个卷积块中的池化层中滑动窗口的尺寸均为 2× 2,步长均为 2,因此每经一次池化操作,特征图缩小为原来的 1/2。假设原始图像的大小为 224× 224,则截取第五个卷积块的池化层的输出得到的特征图的尺寸为 7× 7× 512。在 VGG16 网络中全连接层均有 4096 个隐藏神经元,分类层有 1000个神经元。
✳️ 2.2 ResNet-18网络
在卷积神经网络构建过程中, 选择良好的特征提取基础网络,有助于模型获得更加有效的高维语义特征,在具体的任务中取得更加良好的表现。因此,本文使用由 He等人提出,并在 ImageNet 大规模视觉识别挑战赛(ILSVRC)中获得 2015 年冠军的ResNet 网络结构作为大气光估计的基础特征提取网络。
学者们通过研究发现,随着深度学习网络层数不断加深,网络所提取的特征维度也不断增加。然而更深的网络使得反向传播的链路也在不断变长,导致最上层的梯度难以良好的传播到底层, 指导底层参数的更新, 从而出现梯度弥散导致网络无法收敛,网络出现退化的现象。 为了解决该问题, He 等人[51]在网络中引入了“shortcut”分支,该分支与原始网络组成一个基本单元,被称为残差模块,其结构如图2所示。
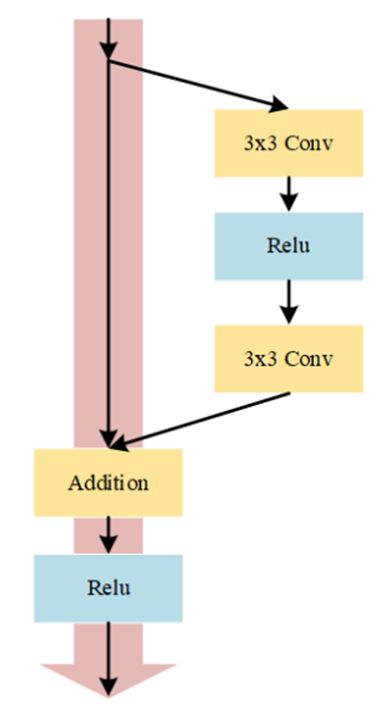
如上图所示, 左侧为“shortcut”结构,右侧为卷积分支。 He 等人[51]认为, 如果想使前层网络不受后面层的影响,使模型变为浅层网络,那么网络后面的层需要进行恒等映射。 但是如果让深层的网络直接学习这个潜在的恒等映射H(x)= x十分困难,因此 He[2] 等人将网络设计为如下公式:
![]()
其中 x 为上一层网络的输出,即改残差模块的输入, F(x)为卷积分支的映射函数, H(x)为最终输出, +由专门的 Element-wise addition 模块完成,卷积分支会保证F(x)与 x 的输出大小和维度相同。从上式中可以看出,当 F(x)=0时,构成恒等映射H(x)= x。其残差函数的可以表示为:

He 等人[2]认为拟合残差比直接拟合函数更加容易。例如把 10 映射到 10.1,那么引入残差分支前是 F’ (10)=10.1,引入残差分支后是H(10)=10.1,H(10)= F(10)+10,F(10)=0.1。 此处的 F’ 和 H 表示对输入数据进行映射, 引入残差分支后的,可以看出对于输出变化残差结构更为敏感。比如输出从 10.0 变到 10.1,映射 F` 的输出增加了 1%,而对于残差结构 F 输出从 10.0 到 10.1,映射 H 是从0.0到0.1,增加了 100%。更大的变化使得网络参数可以进行较大的调整,由于通过“shortcut”分支去掉相同的主体部分, 突出微小的变化, 所以效果更好。
为了提高网络执行效率,采用 ResNet 网络中最轻量级的结构 ResNet-18 作为基础网络,其网络结构如所示:
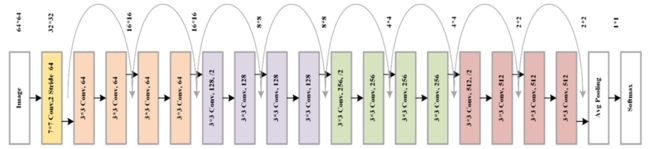
如上图所示, 网络在训练时输入图像为CIFAR-10 数据,每个卷积模块由一个 3x3 的卷积层,一个 BatchNorm 层和一个 ReLU 层组成,最后一层卷积后连接一个 Global Average Pooling层将特征尺寸改为 1x1,这样做的好处可以保证网络输入任意大小的图片。
✳️ 三、训练与实验结果
✳️ 3.1 CIFAR-10 数据集
该数据集共有 60 000 幅彩色图像, 分为 10 类, 每类 6000 幅图。如图3所示, CIFAR-10 数据集中 50000 幅用于训练, 另外10000 幅用于测试。
✳️ 3.2 ResNet-18训练与识别结果
基于ResNet-18网络训练结果如下,在单GPU环境下训练该网络共用时41分钟。随着训练迭代次数的增强,准确率逐渐上升,Loss曲线逐渐下降。
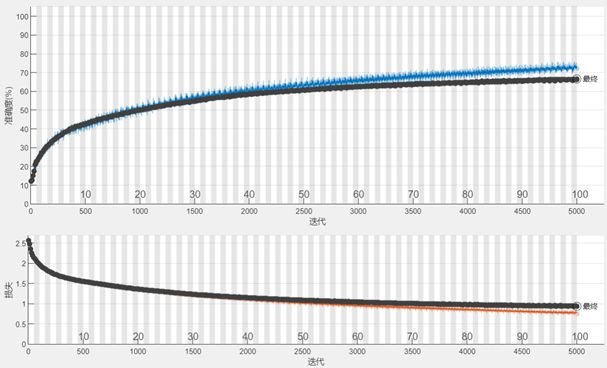
随后,导入一幅图像进行识别,该网络模型准确识别结果为“airplane”,整个识别过程共用时1.41秒。

✳️ 3.3 VGG16 网络训练与识别结果
基于VGG16网络训练结果如下,在单GPU环境下训练500轮共用时26分钟。随着训练迭代次数的增强,准确率逐渐上升,Loss曲线逐渐下降。
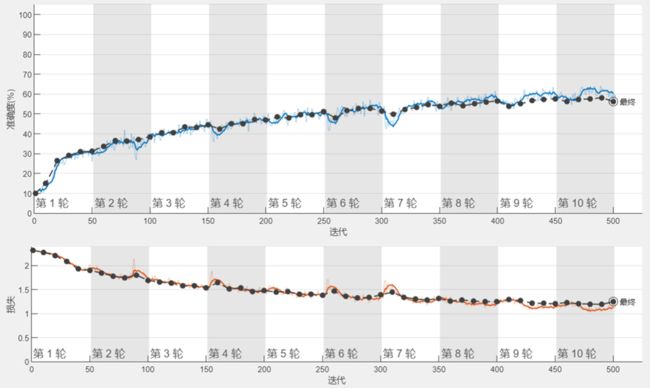
同样地,导入一幅图像进行识别,该网络模型准确识别结果为“airplane”,整个识别过程共用时0.19秒。

✳️ 四、参考文献
[1] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition [Online], available: https://arxiv.org/abs/1409.1556, April 10, 2015
[2] He K, Zhang X, Ren S. Deep Residual Learning for Image Recognition[C]. 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015: 770-778
✳️ 五、Matlab代码获取
上述演示实例,均由Matlab代码实现,可私信博主获取。
博主简介:研究方向涉及智能图像处理、深度学习、卷积神经网络等领域,先后发表过多篇SCI论文,在科研方面经验丰富。任何与算法、程序、科研方面的问题,均可私信交流讨论。