获取VOC数据集xml标注文件的各类别的个数,更改类别名,删除某一类
1.获取xml文件各类别的数目:
import os
input_dir='./xml'
import xml.etree.ElementTree as ET
import xml.dom.minidom
n = 0
a = 0
b = 0
c = 0
d = 0
e = 0
f = 0
for filename in os.listdir(input_dir):
file_path = os.path.join(input_dir, filename)
dom = ET.parse(file_path)
root = dom.getroot()
for obj in root.iter('object'): # 获取object节点中的name子节点
#tmp_name = obj.find('name').text
if obj.find('name').text =='r':
n=n+1
elif obj.find('name').text=='l':
a=a+1
elif obj.find('name').text=='lf':
b=b+1
elif obj.find('name').text=='ic':
c=c+1
elif obj.find('name').text=='bt':
d=d+1
elif obj.find('name').text=='ipr':
e=e+1
elif obj.find('name').text=='c':
f=f+1
print('r类共有标注{}个,l类共有标注{}个,lf类共有标注{}个,ic类共有标注{}个,bt类共有标注{}个,ipr类共有标注{}个,c类共有标注{}个'.format(n,a,b,c,d,e,f))
print('共计标注{}个'.format(n+a+b+c+d+e+f))
2.删除xml中的某一类或几类
import os
import xml.etree.ElementTree as ET
yuan_dir = './xml' # 设置原始标签路径为 Annos
new_dir = './shan_lei_xml' # 设置新标签路径 Annotations
for filename in os.listdir(yuan_dir):
file_path = os.path.join(yuan_dir, filename)
new_path=os.path.join(new_dir,filename)
dom = ET.parse(file_path)
root = dom.getroot()
for obj in root.iter('object'): # 获取object节点中的name子节点
if obj.find('name').text== 'n':
root.remove(obj)
#print("change %s to %s." % (yuan_name, new_name1))
elif obj.find('name').text== 'a':
root.remove(obj)
##可以继续删除,继续用elif语句
# 保存到指定文件
dom.write(new_path, xml_declaration=True)
3.更改某一类或几类的类别名称
import os
input_dir='./xml'
shu=0
new_name1='n'
new_name2='a'
new_name3='b'
new_name4='c'
new_name5='d'
new_name6='e'
new_name7='f'
import xml.etree.ElementTree as ET
for filename in os.listdir(input_dir):
file_path = os.path.join(input_dir, filename)
dom = ET.parse(file_path)
root = dom.getroot()
for obj in root.iter('object'): # 获取object节点中的name子节点
if obj.find('name').text== 'r':
obj.find('name').text=new_name1
shu=shu+1
#print("change %s to %s." % (yuan_name, new_name1))
elif obj.find('name').text== 'l':
obj.find('name').text = new_name2
shu = shu + 1
elif obj.find('name').text== 'lf':
obj.find('name').text= new_name3
shu = shu + 1
elif obj.find('name').text == 'ic':
obj.find('name').text= new_name4
shu = shu + 1
elif obj.find('name').text== 'bt':
obj.find('name').text= new_name5
shu = shu + 1
elif obj.find('name').text== 'ipr':
obj.find('name').text= new_name6
shu = shu + 1
elif obj.find('name').text== 'c':
obj.find('name').text= new_name7
shu = shu + 1
# 保存到指定文件
dom.write(file_path, xml_declaration=True)
print("有%d个文件被成功修改。" % shu)
更改前:
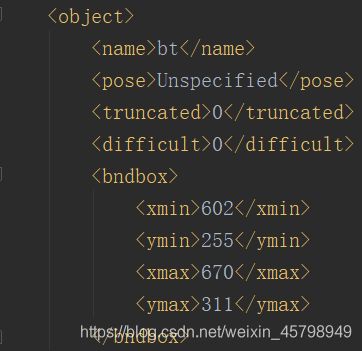
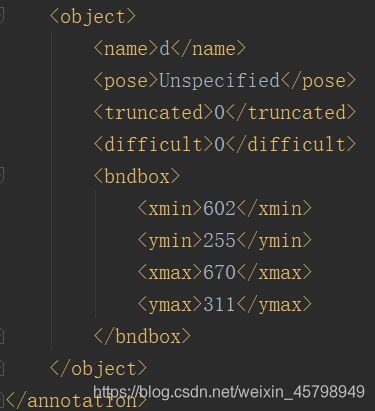
更改后:
删除前:

删除后:
参考链接1
参考链接2