第一次实战Kaggle比赛:预测房价
整理自《动手学深度学习》,有一些补充
一、 用到的库函数
1.1 pd.concat()
用于连接pandas数据表。本文中的用处是,连接测试集和数据集,做k交叉数据集。
pd.concat(object,axis=0,join='outer',join_axes=None,ignore_index=False,keys=None,levels=None,names=None,verify_integrity=False)
object:series,dataframe或则是panel构成的序列list
axis:需要合并连接的轴,0是行,1是列
join:连接的方式inner,或者outer
train_data = pd.read_csv('train.csv')
test_data = pd.read_csv('test.csv')
all_features = pd.concat((train_data.iloc[:,1:], test_data.iloc[:,1:]))
默认axis = 0
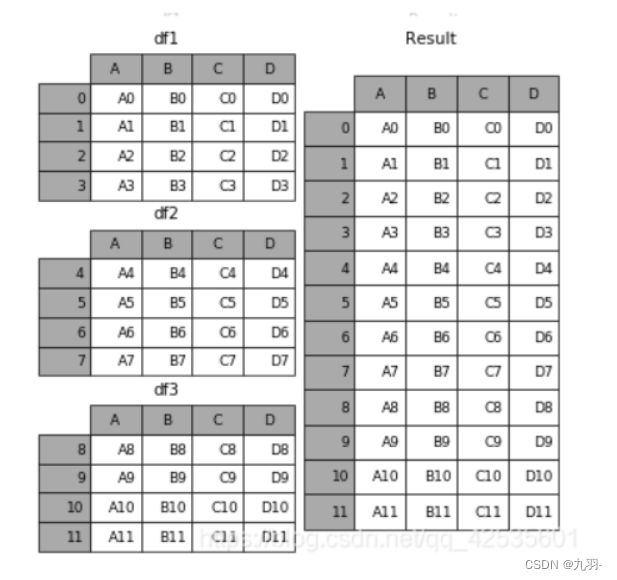
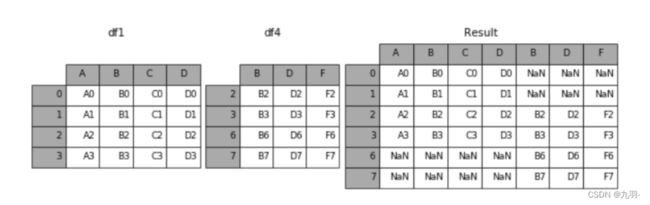
axis = 1
1.2 pd.dtype 、pd.index 、 pd.apply()、pd.get_dummies()、pd.fillna()
.index 返回行标签
.dtypes 返回数据类型
pandas中所有string 类型的 column 都是object类型
.fillna()会填充nan数据
pd.get_dummies() ⾃动生成独热编码列。
dummy_na表示增加一列表示空缺值,如果False就忽略空缺值,默认为False
1.3 clamp()函数
将输入input张量每个元素的夹紧到区间[min,max],并返回结果到一个新张量。
大于max的变为max,小于min的变为min
a = torch.Tensor([1,2,3,4,5,6,7,8,9])
print(a.clamp(4,6))
# tensor([4., 4., 4., 4., 5., 6., 6., 6., 6.])
2.下载数据集
比赛地址:https://www.kaggle.com/competitions/house-prices-advanced-regression-techniques/overview
Overview是此比赛的一些介绍。
Data是提供的数据集,进去可以直接下载数据,也可以在线查看。data_description介绍了csv中列名的具体含义,train.csv是训练集,含有最终房价,test.csv是测试集,没有最终房价。
需要写出程序来预测test.csv的最终房价,不需要提交程序,只需要提交csv文件。

3. 观察数据选择合适模型
数据集里提供了80个属性,有房区分类,所属街道,地块面积,公共设施,住宅类型,房屋的整体材料和饰面,建成年份等,有些很重要,有些不是特别重要。那么如何充分的利用好这些数据就是提升预测准确度至关重要的条件。
这一点暂时不展开,我们本文训练⼀个带有损失平⽅的线性模型。显然线性模型很难让我们在竞赛中获胜,但线性模型提供了⼀种健全性检查,以查看数据中是否存在有意义的信息。如果我们在这⾥不能做得⽐随机猜测更好,那么我们很可能存在数据处理错误。如果⼀切顺利,线性模型将作为基线(baseline)模型,让我们直观地知道最好的模型有超出简单的模型多少。
4. 数据预处理
csv --(read_csv)-> pandas -> 处理 --(.values)-> numpy --(torch.Tensor(numpy))-> Tensor
观察csv文件我们发现有几点问题:
- 有数据缺失,比如MSSubClass列应该是数字的,但有些行是NA,不存在
- 有非数字列,比如MSZoning(销售的分区)列是一些单词,没法带入线性回归模型中
- 不同列的数据取值范围不同,比如MSSubClass列取值范围为[20,190],而OverallCond列取值范围是[1, 10],那么MSSubClass的权重就可能大,就更可能的影响结果(自己猜测是这样),所以要将所有特征放在⼀个共同的尺度上
解决方法:
对于数字列的问题1,3做法是:标准化、na改成0。
标准化公式:x ← (x − µ) / σ , 即减均值除方差,得到正态分布。 在标准化数据之后,整个列均值消失(变为0),因此我们可以将缺失值NA设置为0。
对于非数字列的问题2,做法是:独热编码。
例如,“MSZoning”包含值“RL”和“Rm”。我们将创建两个新的指⽰器特征“MSZoning_RL”和“MSZoning_RM”,其值为0或1。根据独热编码,如果 “MSZoning”的原始值为“RL”,则:“MSZoning_RL”为1,“MSZoning_RM”为0。pandas软件包会⾃动 为我们实现这⼀点。
注:因为数据集和测试机都需要一样的预处理,所以我们连接后一起操作,操作完再分开。
import numpy as np
import pandas as pd
import torch
from torch import nn
from d2l import torch as d2l
train_data = pd.read_csv('train.csv')
test_data = pd.read_csv('test.csv')
print(train_data.shape,test_data.shape)
# (1460, 81) (1459, 80)
# 删除第一列,对结果没用的id和ylabel,然后拼接数据集和测试集
all_features = pd.concat((train_data.iloc[:,1:-1],test_data.iloc[:,1:]))
# .index 返回行标签
# .dtypes 返回数据类型
# pandas中所有string 类型的列都是object类型
# 正则化,3行代码
num_index = all_features.dtypes[all_features.dtypes!='object'].index # 返回的一个列表
all_features[num_index] = all_features[num_index].apply( lambda x:(x-x.mean())/(x.std()) )
all_features[num_index] = all_features[num_index].fillna(0)
# 独热编码,1行代码
all_features = pd.get_dummies(all_features, dummy_na=True) # dummy_na表示增加一列表示空缺值
print(all_features.shape)
# (2919, 332) 可以看到,此转换会将特征的总数量从79个增加到331个
# 处理完成,分离数据集测试集
n_train = train_data.shape[0]
train_features = torch.tensor(all_features[:n_train].values, dtype=torch.float32)
test_features = torch.tensor(all_features[n_train:].values, dtype=torch.float32)
train_labels = torch.tensor(
train_data.SalePrice.values.reshape(-1,1),
dtype = torch.float32
)
5. 模型和损失函数
全连接的带有损失平⽅的线性模型。

def get_net():
net = nn.Sequential(
nn.Linear(train_feature.shape[1], 1)
)
return net
loss = nn.MSELoss() # 均方根误差,即差值的平方
def log_rmse(net, features, labels): # 相对误差
pred = torch.clamp( net(features), 1, float('inf') )
rmse = torch.sqrt( loss( torch.log(pred), torch.log(labels) ) )
return rmse.item() # 。item() 将一个数的Tensor转成数
6. 开始训练
借助Adam优化器
from torch.utils import data
def train(net, train_features, train_labels, test_features, test_labels,
num_epochs, learning_rate, weight_decay, batch_size):
train_ls, test_ls = [],[]
train_iter = d2l.load_array((train_features,train_labels),batch_size)
opt = torch.optim.Adam(net.parameters(), lr=learning_rate, weight_decay=weight_decay)
for epoch in range(num_epochs):
for X,y in train_iter:
opt.zero_grad()
l = loss(net(X),y)
l.backward()
opt.step()
train_ls.append(log_rmse(net, train_features, train_labels))
if test_labels is not None:
test_ls.append(log_rmse(net, test_features, test_labels))
return train_ls, test_ls
上述代码中的d2l.load_array将整个大的Tensor数据,返回一个迭代器,分批次的读取数据。
from torch.utils import data
def load_array(data_arrays, batch_size, is_train=True):
"""构造⼀个PyTorch数据迭代器"""
dataset = data.TensorDataset(*data_arrays)
return data.DataLoader(dataset, batch_size, shuffle=is_train)
7.K折交叉验证
第k块数据是测试集,剩余的是训练集。
def get_k_fold_data(k, i , X, y):
assert k>1, "k<=1了"
fold_size = X.shape[0] // k # 每个块的大小
X_train, y_train = None, None
for j in range(k):
idx = slice(j*fold_size, (j+1)*fold_size)
X_part, y_part = X[idx,:], y[idx]
if j==i:
X_valid, y_valid = X_part, y_part
elif X_train is None:
X_train, y_train = X_part, y_part
else:
X_train = torch.cat([X_train, X_part], dim=0)
y_train = torch.cat([y_train, y_part], dim=0)
return X_train, y_train, X_valid, y_valid
当我们在K折交叉验证中训练K次后,返回训练和验证误差的平均值。
def k_fold_train( k, X_train, y_train, num_epochs,
learning_rate, weight_decay, batch_size ):
train_l_sum, valid_l_sum = 0,0
for i in range(k):
data = get_k_fold_data(k, i, X_train, y_train)
net = get_net()
train_ls, valid_ls = train(net, *data, num_epochs,
learning_rate, weight_decay, batch_size )
train_l_sum += train_ls[-1]
valid_l_sum += valid_ls[-1]
if i==0:
d2l.plot(list(range(1, num_epochs + 1)), [train_ls, valid_ls],
xlabel='epoch', ylabel='rmse', xlim=[1, num_epochs],
legend=['train', 'valid'], yscale='log')
print(f'折{i + 1},训练log rmse{float(train_ls[-1]):f}, '
f'验证log rmse{float(valid_ls[-1]):f}')
return train_l_sum/k, valid_l_sum/k
8.调整参数
这也是一个大工作,我们这里只选择了⼀组未调优的超参数。
找到⼀组调优的超参数可能需要时间,这取决于⼀个⼈优化了多少变量。有了⾜够⼤的数据集和合理设置的超参数,K折交叉验证往往对多次测试具有相当的稳定性。然⽽,如果我们尝试了不合理的超参数,我们可能会发现验证效果不再代表真正的误差。
k, num_epochs, lr, weight_decay, batch_size = 5, 100, 5, 0, 64
train_l, valid_l = k_fold_train(k, train_features, train_labels, num_epochs, lr, weight_decay, batch_size)
print(f'{k}-折验证: 平均训练log rmse: {float(train_l):f}, '
f'平均验证log rmse: {float(valid_l):f}')

9. 提交Kaggle预测
既然我们知道应该选择什么样的超参数,我们不妨不再使用k交叉,而是使用所有数据对模型进⾏训练。然后得到测试集的答案提交。
def train_and_pred(train_features, test_features, train_labels, test_data,
num_epochs, lr, weight_decay, batch_size):
net = get_net()
train_ls, _ = train(net, train_features, train_labels, None, None,
num_epochs, lr, weight_decay, batch_size)
d2l.plot(np.arange(1,num_epochs+1), [train_ls], xlabel='epoch',
ylabel='log rmse', xlim=[1,num_epochs], yscale='log')
print(f'训练log rmse:{float(train_ls[-1]):f}')
# 将⽹络应⽤于测试集。
preds = net(test_features).detach().numpy()
# 将其重新格式化以导出到Kaggle
test_data['SalePrice'] = pd.Series(preds.reshape(1,-1)[0])
submission = pd.concat([test_data['Id'], test_data['SalePrice']], axis=1)
submission.to_csv('submission.csv', index=False)
train_and_pred(train_features, test_features, train_labels, test_data,
num_epochs, lr, weight_decay, batch_size)

10. 提交结果
