黄佳《零基础学机器学习》chap1笔记
黄佳 《零基础学机器学习》 chap1笔记
这本书实在是让我眼前一亮!!! 感觉写的真的太棒了!
文章目录
- 黄佳 《零基础学机器学习》 chap1笔记
- 第1课 机器学习快速上手路径—— 唯有实战
- 1.1 机器学习族谱
- 1.2 云环境
-
- 入门实践:推断加州房价
- 1.3 基本的机器学习术语
- 1.4 python和机器学习框架
- 1.5 机器学习项目实战架构
-
- 1.5.1 问题定义
- 1.5.2 数据的收集和预处理
-
- 1.原始数据的准备
- 2.数据的预处理
- 3.特征工程和特征提取
- 4.载入MNIST数据集
- 1.5.3 模型(算法)的选择
- 1.5.4 选择机器学习模型
-
- 内部参数
- 超参数(hyperparameter)
- 在本环节确定内部参数
- 1.5.5 超参数调试和性能优化
-
- **训练集、验证集和测试集**
- K折验证
- 模型的优化和泛化
- 怎么看预测结果
- 反思
- 1.6 小结
- 1.7 练习
第1课 机器学习快速上手路径—— 唯有实战
1.1 机器学习族谱
参考:用mermaid在typora中画思维导图
- 下图使用mermaid在typora中绘制
- 一些常见的机器学习应用场景和机器学习模型
趋势预测
人脸识别
文档分类

1.2 云环境
- Kaggle 和 Colab 都挺好用的
入门实践:推断加州房价
-
读取数据
Kaggle的话注意打开Internet On的按钮
import pandas as pd #导入Pandas,用于数据读取和处理 # 读入房价数据,示例代码中的文件地址为internet链接,读者也可以下载该文件到本机进行读取 # 如,当数据集和代码文件位于相同本地目录,路径名应为"./house.csv",或直接放"house.csv"亦可 df_housing = pd.read_csv("https://raw.githubusercontent.com/huangjia2019/house/master/house.csv") df_housing.head() #显示加州房价数据

-
这是加州各地区房价的整体统计信息(不是 一套套房子的价格信息),是1990年的人口普查结果之一,共包含17 000个样本。其中包含每一个具体地区的经度(longitude)、纬度 (latitude)、房屋的平均年龄(housing_median_age)、房屋数量 (total_rooms)、家庭收入中位数(median_income)等信息,这些信息都是加州地区房价的特征。数据集最后一列“房价中位数” (median_house_value)是标签。
-
这个机器学习项目的目标,就是根据已有的数据样本,对其特征进行推理归纳,得到一个函数模型后,就可以用它推断加州其他地区的房价中位数。
-
构建特征集和标签集
X = df_housing.drop("median_house_value",axis = 1) #构建特征集X y = df_housing.median_house_value #构建标签集y- 上面的代码使用drop方法,把最后一列median_house_value字段去 掉,其他所有字段都保留下来作为特征集X,而这个median_house_value 字段就单独赋给标签集y
-
划分数据集
from sklearn.model_selection import train_test_split #导入数据集拆分工具 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0) #以80%/20%的比例进行数据集的拆分- 现在要把数据集一分为二,80%用于机器训练(训练数据集),剩下的留着做测试(测试数据集)如下段代码所示。这也就是告诉机器:你看,拥有这些特征的地方,房价是这样的,等一会儿你想个办法给我猜猜另外20%的地区的房价。
- 其实,另外20%的地区的房价数据,本来就有了,但是我们假装不知道,故意让机器用自己学到的模型去预测。所以,之后通过比较预测值和真值,才知道机器“猜”得准不准,给模型打分
-
选定模型,训练机器,拟合函数,确定参数
from sklearn.linear_model import LinearRegression #导入线性回归算法模型 model = LinearRegression() #使用线性回归算法 model.fit(X_train, y_train) #用训练集数据,训练机器,拟合函数,确定参数- 首先选择LinearRegression(线性回归)作为这个机器学习的模型,这是选定了模型的类型,也就是算法;
- 然后通过其中的fit方法来训练机器,进行函数的拟合。拟合意味着找到最优的函数去模拟训练集中的输入(特征)和目标(标签)的关系,这是确定模型的参数。
-
利用模型进行预测
y_pred = model.predict(X_test) #预测测试集的Y值 print ('房价的真值(测试集)',y_test) print ('预测的房价(测试集)',y_pred) -
给预测打分
print("给预测评分:", model.score(X_test, y_test)) #评估预测结果Sklearn线性回归模型的score属性给出的是R2分数, 它是一个机器学习模型的评估指标,给出的是预测值的方差与总体方 差之间的差异

-
可视化
import matplotlib.pyplot as plt #导入matplotlib画图库 #用散点图显示家庭收入中位数和房价中位数的分布 plt.scatter(X_test.median_income, y_test, color='brown') #画出回归函数(从特征到预测标签) plt.plot(X_test.median_income, y_pred, color='green', linewidth=1) plt.xlabel('Median Income') #X轴-家庭收入中位数 plt.ylabel('Median House Value') #Y轴-房价中位数 plt.show() #显示房价分布和机器习得的函数图形
- 轴的特征太多,无法全部展示,选择了与房价关系最密切的 “家庭收入中位数”median_income作为代表特征来显示散点图。
- 图中的点就是家庭收入/房价分布,而绿色线就是机器学习到的函数模 型,很粗放,都是一条一条的线段拼接而成,但是仍然不难看出,这 个函数模型大概拟合了一种线性关系。
1.3 基本的机器学习术语
| 术语 | 定义 | 数学描述 | 示例 |
|---|---|---|---|
| 数据集 | 数据的集合 | { ( X 1 , y 1 ) , ⋯ . ( X n , y n ) } \{(X_1,y_1),\cdots.(X_n,y_n)\} {(X1,y1),⋯.(Xn,yn)} | 1000个北京市房屋的面积、楼层、位置、朝向,以及部分房价信息的数据集 |
| 样本 | 数据集中的一条具体记录 | { ( X 1 , y 1 ) } \{(X_1,y_1)\} {(X1,y1)} | 一个房屋的数据记录 |
| 特征 | 用于描述数据的输入变量 | { x 1 , x 2 , ⋯ . x n } \{x_1,x_2,\cdots.x_n\} {x1,x2,⋯.xn}也是一个向量 | 面积( x 1 {x_1} x1)、楼层( x 2 {x_2} x2)、位置( x 3 {x_3} x3)、朝向( x 4 {x_4} x4) |
| 标签 | 要预测的真实事物或结果,也称为目标 | y | 房价 |
| 有标签样本 | 有特征、标签,用于训练模型 | (X,y) | 800个北京市房屋的面积、楼层、位置、朝向,以及房价信息 |
| 无标签样本 | 有特征,无标签 | (X, ?) | 200个北京市房屋的面积、楼层、位置、朝向,但是无房价信息 |
| 模型 | 将样本的特征映射到预测标签 | f(X),其实也就是函数 | 通过面积、楼层、位置、朝向这些信息来确定房价的函数 |
| 模型中的参数 | 模型中的参数确定了机器学习的具体模型 | f(X)这个函数的参数 | 如f(X)=3X+2中的3和2 |
| 模型的映射结果 | 通过模型映射出无标签样本的标签 | y’ | 200个被预测出来的房价 |
| 机器学习 | 通过学习样本数据,发现规律,得到模型的参数,从而得到能预测目标的模型 | 确定f(X)和其参数的过程 | 确定房价预测函数和具体参数的过程 |
1.4 python和机器学习框架
-
8个机器学习常用库
-
Pandas和Num Py提供数据结构,支持数学运算
-
Matplotlib和Seaborn用于数据可视化
-
4个库提供算法
-
Scikit-learn是机器学习框架
-
简称Sklearn
from sklearn.linear_model import Linear Regression #导入 线性回归算法模型 model = Linear Regression() #使用线性回归算法
-
-
Tesnsor Flow、Keras和PyTorch则是深度学习框架
-
-
1.5 机器学习项目实战架构
-
李宏毅老师曾用将大象装进冰箱来比喻机器学习。
- 大象怎么被装进冰箱?这分为3个步骤:打开冰箱门,将大象放进去,关闭冰箱门。
- 机器学习也就是个“三部曲”:选择函数模型,评估函数的优劣,确定最优的函数
-
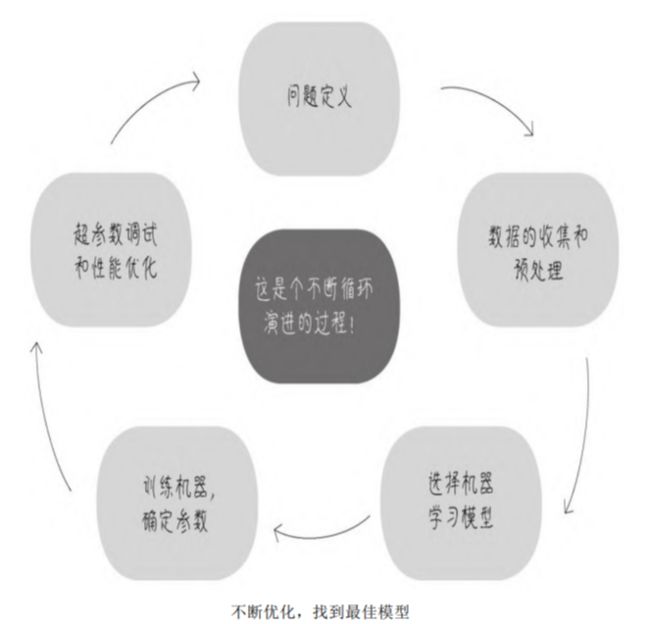
机器学习项目的实际过程要更复杂一些,大致分为以下5个环节。
- 问题定义
- 数据的收集和预处理
- 模型(算法)的选择
- 选择机器学习模型
- 超参数调试和性能优化
这5个环节,每一步的处理是否得当,都直接影响机器学习项目的 成败
用MNIST数据集为例
1.5.1 问题定义
-
要知道机器学习项目到底要解决什么问题
-
例
- MNIST数据集。这个数据集相当于是机器学习 领域的Hello World,非常的经典,里面包含60 000张训练图像和10 000 张测试图像,都是28px×28px的手写数字灰度图像
- 此处要解决的问题是:将手写数字灰度图像分类为0,1,2,3, 4,5,6,7,8,9,共10个类别。
1.5.2 数据的收集和预处理
1.原始数据的准备
- 自有数据(如互联网公司拥有的大量的客户资料、购物行为历史信息)
- 上网爬取数据
- 各种开源数据网站(Image Net、Kaggle、Google Public Data Explorer,甚至Youtube和维基百科,都是机器学习的重要数据源)
- 购买数据
2.数据的预处理
-
可视化(visualization)
- 要用Excel表和各种数据分析工具(如前面说的Matplotlib或者Seaborn)从各种角度(如列表、直方图、散点图等)看一看数据。对数据有了基本的了解,才方便进一步分析判 断。
-
数据向量化(data vectorization)
- 把原始数据格式化,使其变得机器可以读取。例如,将原始图片转换为机器可以读取的数字矩阵,将文字转换为one-hot编码,将文本类别(如男、女)转换成0、1 这样的数值。
-
处理坏数据和缺失值
- 一笔数据可不是全部都能用,要利用数据处理工具来把“捣乱”的“坏数据”(冗余数据、离群数据、错误数据)处理掉,把缺失值补充上
-
特征缩放(feature scaling)
- 特征缩放方法有很多,包括数据标准化(standardization)和规范化(normalization)等
- 标准化
- 是对数据特征分布的转换,目标是使其符合正态分布 (均值为0,标准差为1)。因为如果数据特征不符合正态分布的话, 就会影响机器学习效率。在实践中,会去除特征的均值来转换数据, 使其居中,然后除以特征的标准差来对其进行缩放
- 标准化的一种变体是将特征压缩到给定的最小值和最大值之 间,通常为0~1。因此这种特征缩放方法也叫归一化。归一化不会改变数据的分布状态。
- 规范化
- 是将样本缩放为具有单位范数的过程,然后放入机器学习模型,这个过程消除了数据中的离群值
- 标准化
- 在Sklearn的preprocessing工具中可以找到很多特征缩放的方法。 在实战中,要根据数据集和项目特点选择适宜的特征缩放方法。
- 特征缩放方法有很多,包括数据标准化(standardization)和规范化(normalization)等
-
数据预处理原则
- 全部数据应转换成数字格式(即向量、矩阵、3D、4D、5D)的数组(张量)
- 大范围数据值要压缩成较小值,分布不均的数据特征要进行标准化。
- 异质数据要同质化(homogenous),即同一个特征的数据类型要尽量相同
3.特征工程和特征提取
-
特征工程和特征提取仍然是在机器对数据集学习之前进行的操作,广义上也算数据预处理。
-
特征工程是使用数据的领域知识来创建使机器学习算法起作用的特征的过程。特征工程是机器学习的重要环节,然而这个环节实施困难又开销昂贵,相当费时费力。
- 在深度学习时代,对于一部分机器学习问题,自动化的特征学习 可以减少对手动特征工程的需求。但特征工程在另一些机器学习问题 中,仍然是不可或缺的环节。
-
特征提取(feature extraction)则是通过子特征的选择来减少冗余特征,使初始测量数据更简洁,同时保留最有用的信息。
-
为什么要对数据的特征进行处理?因为机器学习之所以能够学到 好的算法,关键看特征的质量。那就需要思考下面的问题。
-
如何选择最有用的特征给机器进行学习?(进行特征提 取。)
-
如何把现有的特征进行转换、强化、组合,创建出来新的、 更好的特征?(进行特征工程。)
-
-
4.载入MNIST数据集
import numpy as np # 导入NumPy数学工具箱
import pandas as pd # 导入Pandas数据处理工具箱
from keras.datasets import mnist #从Keras中导入mnist数据集
#读入训练集和测试集
(X_train_image, y_train_lable), (X_test_image, y_test_lable) = mnist.load_data()
数据向量化的工作MNIST数据集已经为我们做好了,可以直接显 示这些张量里面的内容:
print ("特征集张量形状:", X_train_image.shape) #用shape方法显示张量的形状
print ("第一个数据样本:\n", X_train_image[0]) #注意Python的索引是从0开始的
shape方法显示的是X_train_image张量的形状。灰度图像数据集是 3D张量,第一个维度是样本维(也就是一张一张的图片,共60 000 张),后面两个是特征维(也就是图片的28px×28px的矩阵)。可以发现灰度 信息主要集中在矩阵的中部,边缘部分都是0填充,是图片的背景。数字矩阵的内容差不多如下图所示。

再看一下标签的格式:
print ("第一个数据样本的标签:", y_train_lable[0])
第一个数据样本的标签: 5
上面的数据集在输入机器学习模型之前还要做一些数据格式转换 的工作:
# from keras.utils.np_utils import to_categorical # 导入keras.utils工具箱的类别转换工具
from tensorflow.python.keras.utils.np_utils import to_categorical # 导入keras.utils工具箱的类别转换工具
X_train = X_train_image.reshape(60000,28,28,1) # 给标签增加一个维度
X_test = X_test_image.reshape(10000,28,28,1) # 给标签增加一个维度
y_train = to_categorical(y_train_lable, 10) # 特征转换为one-hot编码
y_test = to_categorical(y_test_lable, 10) # 特征转换为one-hot编码
print ("数据集张量形状:", X_train.shape) # 特征集张量的形状
print ("第一个数据标签:",y_train[0]) # 显示标签集的第一个数据

书上那个 from keras.utils.np_utils import to_categorical # 导入keras.utils工具箱的类别转换工具
会报错

改成上面那个tensorflow.python.keras.utils就
- 为何需要新的格式。
- Keras要求图像数据集导入卷积网络模型时为4阶张量,最后 一阶代表颜色深度,灰度图像只有一个颜色通道,可以设置其值为1。
- 在机器学习的分类问题中,标签[0.0.0.0.0.0.0.0.1.0.]就代表着类别值8。这是等会儿还要提到的one-hot编码。
from keras import models # 导入Keras模型, 和各种神经网络的层
from keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPooling2D
model = models.Sequential() # 用序贯方式建立模型
model.add(Conv2D(32, (3, 3), activation='relu', # 添加Conv2D层
input_shape=(28,28,1))) # 指定输入数据样本张量的类型
model.add(MaxPooling2D(pool_size=(2, 2))) # 添加MaxPooling2D层
model.add(Conv2D(64, (3, 3), activation='relu')) # 添加Conv2D层
model.add(MaxPooling2D(pool_size=(2, 2))) # 添加MaxPooling2D层
model.add(Dropout(0.25)) # 添加Dropout层
model.add(Flatten()) # 展平
model.add(Dense(128, activation='relu')) # 添加全连接层
model.add(Dropout(0.5)) # 添加Dropout层
model.add(Dense(10, activation='softmax')) # Softmax分类激活,输出10维分类码
# 编译模型
model.compile(optimizer='rmsprop', # 指定优化器
loss='categorical_crossentropy', # 指定损失函数
metrics=['accuracy']) # 指定验证过程中的评估指标
1.5.3 模型(算法)的选择
-
第3个环节先是选择机器学习模型的算法类型,然后才开始训练机器确定参数。 各种Python机器学习框架中有很多类型的算法,主要包括以下几种
-
线性模型(线性回归、逻辑回归)
-
非线性模型(支持向量机、k最邻近分类)
-
基于树和集成的模型(决策树、随机森林、梯度提升树等)
-
神经网络(人工神经网络、卷积神经网络、长短期记忆网络等)
那么究竟用哪个呢? 答案是—这与要解决的问题有关。没有最好的算法,也没有最差 的算法。
随机森林也许处理回归类型问题很给力,而神经网络则适合处理特征量巨大的数据,有些算法还能够通过集成学习的方法组织在一起使用。只有通过实践和经验的积累,深入地了解各个算法,才能 慢慢地形成“机器学习直觉”。遇见的多了,一看到问题,就知道大 概何种算法比较适合。
-
-
那么我们为MNIST数据集手写数字识别的问题选择什么算法作为 机器学习模型呢?试试卷积神经网络
from keras import models # 导入Keras模型, 和各种神经网络的层 from keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPooling2D model = models.Sequential() # 用序贯方式建立模型 model.add(Conv2D(32, (3, 3), activation='relu', # 添加Conv2D层 input_shape=(28,28,1))) # 指定输入数据样本张量的类型 model.add(MaxPooling2D(pool_size=(2, 2))) # 添加MaxPooling2D层 model.add(Conv2D(64, (3, 3), activation='relu')) # 添加Conv2D层 model.add(MaxPooling2D(pool_size=(2, 2))) # 添加MaxPooling2D层 model.add(Dropout(0.25)) # 添加Dropout层 model.add(Flatten()) # 展平 model.add(Dense(128, activation='relu')) # 添加全连接层 model.add(Dropout(0.5)) # 添加Dropout层 model.add(Dense(10, activation='softmax')) # Softmax分类激活,输出10维分类码 # 编译模型 model.compile(optimizer='rmsprop', # 指定优化器 loss='categorical_crossentropy', # 指定损失函数 metrics=['accuracy']) # 指定验证过程中的评估指标-
这段代码把数据集放入卷积神经网络进行处理。
- 两个Conv2D(二维卷积)层
- 两个MaxPooling2D(最大池 化)层
- 两个Dropout层用于防止过拟合
- 还有Dense(全连接)层
- 最后通过Softmax分类器输出预测标签y’值,也就是所预测的分类值。这 个y’值,是一个one-hot(即“一位有效编码”)格式的10维向量。我们 可以将y’与标签真值y进行比较,以计算预测的准确率

-
1.5.4 选择机器学习模型
- 确定机器学习模型的算法类型之后,就进行机器的学习,训练机器以确定最佳的模型内部参数,并使用模型对新数据集进行预测。之所以说在这一环节中确定的是模型内部参数,是因为机器学习中还有超参数的概念。
内部参数
- 机器学习模型的具体参数值,例如线性函数 y=2x+1,其中的2和1就是模型内参数。在机器学习里面这叫作权重 (weight)和偏置(bias)。神经网络也类似,每一个节点都有自己的权重(或称kernel),网络的每一层也有偏置。模型内参数在机器的训练过程中被确定,机器学习的过程就是把这些参数的最佳值找出来。
超参数(hyperparameter)
- 位于机器学习模型的外部,属于训练和调试过程中的参数。机器学习应该迭代(被训练)多少次?迭代时模型参数改变的速率(即学习率)是多大?正则化参数如何选择? 这些都是超参数的例子,它们需要在反复调试的过程中被最终确定。 这是机器学习第5个环节中所着重要做的工作。
在本环节确定内部参数
from tqdm.keras import TqdmCallback
model.fit(X_train, y_train, # 指定训练特征集和训练标签集
validation_split = 0.3, # 部分训练集数据拆分成验证集
epochs=5, # 训练轮次为5轮
batch_size=128,callbacks=[TqdmCallback(verbose=2)]
) # 以128为批量进行训练
在上面的训练过程中,fit方法还自动地把训练集预留出30%的数据 作为验证集(马上就会讲到什么是验证集),来验证模型准确率。 输出结果如下:

以上显示的5轮训练中,准确率逐步提高。
-
accuracy:代表训练集上的预测准确率,最后一轮达到0.9726
-
val_accuracy:代表验证集上的预测准确率,最后一轮达到0.9798
1.5.5 超参数调试和性能优化
- 机器学习重在评估,只有通过评估,才能知道当前模型的效率, 才能在不同模型或同一模型的不同超参数之间进行比较。
- 举例来说, 刚才的训练轮次–5轮,是一个超参数。我们想知道对于当前的卷积神经网络模型来说,训练多少轮对于MNIST数据集最为合适。这就是一个调试超参数的例子,而这个过程中需要各种评估指标作为调试过程的“风向标”。正确的评估指标相当重要,因为如果标准都不对,最终模型的效果会南辕北辙,性能优化更是无从谈起。 下面介绍两个重要的评估点。
- 在机器训练过程中,对于模型内部参数的评估是通过损失函数进行的。以后还要详细介绍各种损失函数,例如回归问题的均方误差函数、分类问题的交叉熵(就是本例中的categorical_crossentropy)函数,都是内部参数的评估方法。这些损失函数指出了当前模型针对训 练集的预测误差。这个过程在第4个环节中,调用fit方法后就已经完成 了。
- 在机器训练结束后,还要进行验证,验证过程采用的评估方式包括前面出现过的R2分数以及均方误差函数、平均绝对误差函数、交叉熵函数等各种标准。目前的这个卷积神经网络模型中的参数设定项 metrics=[‘accuracy’],指明了以accuracy,即分类的准确率作为验证指标。验证过程中的评估,既评估了模型的内部参数,也评估了模型的超参数。
- 举例来说, 刚才的训练轮次–5轮,是一个超参数。我们想知道对于当前的卷积神经网络模型来说,训练多少轮对于MNIST数据集最为合适。这就是一个调试超参数的例子,而这个过程中需要各种评估指标作为调试过程的“风向标”。正确的评估指标相当重要,因为如果标准都不对,最终模型的效果会南辕北辙,性能优化更是无从谈起。 下面介绍两个重要的评估点。
训练集、验证集和测试集
-
为了进行模型的评估,一般会把数据划分成3个集合:训练数据 集、验证数据集和测试数据集,简称训练集(trainsing set)、验证集 (validation set)和测试集(test set)。在训练集上训练模型,在验证集上评估模型。感觉已经找到最佳的模型内部参数和超参数之后,就在测试集上进行最终测试,以确定模型。
-
机器学习模型训练时,会自动调节模型内部参数。
这个过程中经常出现 过拟合(overfit) 的现象。
可以把过拟合理 解为模型对当前数据集的针对性过强了,虽然对训练集拟合效果很好,但是换一批新数据就不灵了。这叫作模型的泛化能力弱。
-
解决了在训练集上的过拟合问题之后,在继续优化模型的过程中,又需要反复地调整模型外部的超参数,这个过程是在训练集和验证集中共同完成的。这个调试、验证过程会导致模型在验证集上也可能过拟合,因为调试超参数本身也是一种训练。这个现象叫作信息泄露(information leak)。也就是说,即使我们选择了对验证集效果最好的超参数,这个好结果也不一定真的能泛化到最终的测试集。
-
即使得到的模型在验证集上的性能已经非常好,我们关心的还是模型在全新数据上的性能。因此,我们需要使用一个完全不同的、前所未见的数据集来对模型进行最终的评估和校正,它就是测试集。在最终验证之前,我们的模型一定不能读取任何与测试集有关的任何信息,一次也不行。
-
下面就在MNIST测试集上进行模型效率的验证,如下段代码所示。这个测试集的任何数据信息都没有在模型训练的过程中暴露过。
-
score = model.evaluate(X_test, y_test) # 在测试集上进行模型评估 print('测试集预测准确率:', score[1]) # 打印测试集上的预测准确率 -

K折验证
- 上面的测试集测试结果相当不错,但问题是,如果最终验证结果仍不尽如人意的话,那么继续调试和优化就会导致这个最终的测试集
又变成了一个新的验证集。因此需要大量新数据的供给,以创造出新的测试数据集。 - 数据,很多时候都是十分珍贵的。因此,如果有足够的数据可用,一般来说按照60%、20%、 20%的 比例划分为训练集、验证集和测试集。但是如果数据本身已经不大够用,还要拆分出3个甚至更多个集合,就更令人头疼。而且样本数量过少,学习出来的规律会失法代表.性。因此,机器学习中有重用同一个数据集进行多次验证的方法,即K折验证,如下图所示。
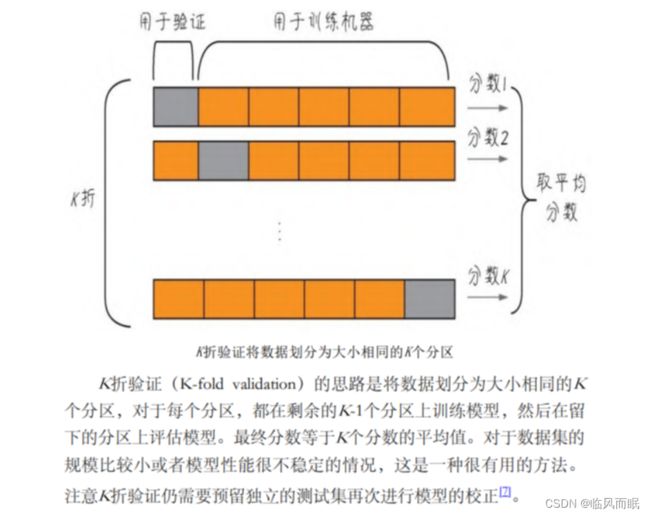
模型的优化和泛化
-
优化(optimization)和泛化(generalization),这是机器学习的两 个目标。它们之间的关系很微妙,是一种此消彼长的状态。
- 如何成功地拟合已有的数据,这是性能的优化
- 但是更为重要的是如何把当前的模型泛化到其他数据集
-
模型能否泛化,也许比模型在当前数据集上的性能优化更重要。
-
经过训练之后100张猫图片都能被认出来了,但是也没什么了不起,因为这也许是通过死记硬背实现的(书上这里说的好好),再给几张新的猫图片,就不认识 了。这就有可能是出现了“过拟合”的问题—机器学习到的模型太过于关注训练数据本身。
-
对于目前的MNIST数据集,卷积神经网络模型是没有出现过拟合的问题的,因为在训练集、验证集和测试集中,评估后的结果都差不多, 预测准确率均为98%以上,所以模型泛化功能良好。
-
怎么看预测结果
-
怎么看预测结果
- 其实在测试集上进行评估之后,机器学习项目就大功告成了。想 知道具体的预测结果,可以使用predict方法得到模型的预测值。下面看看代码吧
pred = model.predict(X_test[0].reshape(1, 28, 28, 1)) # 预测测试集第一个数据 print(pred[0],"转换一下格式得到:",pred.argmax()) # 把one-hot码转换为数字 import matplotlib.pyplot as plt # 导入绘图工具包 plt.imshow(X_test[0].reshape(28, 28),cmap='Greys') # 输出这个图片前两行代码,是对测试集第一个数据(Python索引是从0开始的) 进行预测,并输出预测结果。argmax方法就是输出数组里面最大元素的索引,也就是把one-hot编码转换为实际数值。 输出结果如下

果然是正确答案7,与预测结果的one-hot编码相匹配,证明预测对了!
反思
1.6 小结
-
机器学习的内涵:
-
机器学习的关键内涵在于从大量的数据中发现一个“模型”,并通过它来模拟现实世界事物间的关系, 从而实现预测或判断的功能。
-
从这个定义出发,机器学习可以分为监督学习、无监督学习、 半监督学习,以及深度学习、强化学习等类型。这些学习类型之间的界限是比较模糊的,彼此之间有交集,也可以相互组合。比如,深度 学习和强化学习技术同时运用,可以形成深度强化学习模型。
-
-
基本的机器学习术语
-
机器学习项目实战流程中的5个环节
- 问题定义
- 数据的收集和预处理
- 选择机器学习模型
- 训练机器,确定参数
- 超参数调试和性能优化
1.7 练习
-
使 用 Linear Regression线性回归算法对波士顿房价数据集进行建模
-
代码
import numpy as np # 导入NumPy数学工具箱 import pandas as pd # 导入Pandas数据处理工具箱 from keras.datasets import boston_housing #从Keras中导入Boston Housing数据集 #读入训练集和测试集 (X_train, y_train), (X_test, y_test) = boston_housing.load_data() print ("数据集张量形状:", X_train.shape) #shape方法显示张量的形状 print ("第一个数据样本:\n", X_train[0]) #注意Python的索引是从0开始的 print ("第一个数据样本的标签:", y_train[0]) from sklearn.linear_model import LinearRegression #导入线性回归算法模型 model = LinearRegression() #使用线性回归算法 model.fit(X_train, y_train) #用训练集数据,训练机器,拟合函数,确定参数 y_pred = model.predict(X_test) #预测测试集的Y值 print ('房价的真值(测试集)',y_test) print ('预测的房价(测试集)',y_pred) print("给预测评分:", model.score(X_test, y_test)) #评估预测结果