Qemu-KVM 网络性能优化实践
背景
在做优化之前,腾讯云上使用的母机单队列,性能只有14w pps。
已有的多队列版本,在20w+ pps左右,不是很理想。
主要问题性能
1 . 单队列成为性能瓶颈
物理主机环境,使用多队列已经有多年。
而在公有云上,虚拟化的virtio-net长期使用的多队列。
有如下原因:
- 早期的qemu-kvm版本只支持单队列。
- 为了稳定性,友商如阿里云,virtio-net的网卡到2016年底,仍然是单队列。
2 . 多队列性能并不理想
引入网卡多队列,目的是充分利用SMP处理器的性能。
在物理母机上,多队列性能提升非常明显。
但是在虚拟机上,性能却没有得到明显提升。
已有的kvm-2.0版本,当时是20w pps左右,单队列能到14w pps。
Qemu-kvm多队列原理
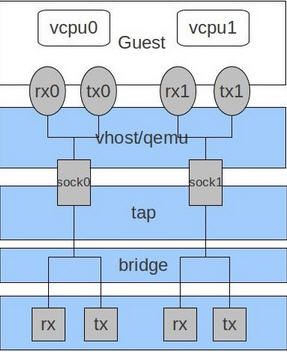
上图是多队列的示意图。
和物理机上的多队列类似。
一个virtio-net的队列,对应一个虚拟cpu。
这样,避免了多个虚拟cpu使用同一个队列带来的竞争问题。
性能优化实践
云上Overlay网络的实现
腾讯云网络使用了overlay网络技术。
在用户看来,每个用户都是一个独立的网络,相互隔离。
具体实现如下:
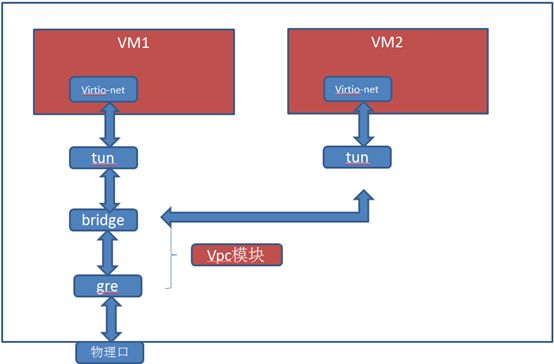
由上图可见,数据包的流程为
- 虚拟机向外发包,经过virtio-net网卡驱动外发(virtio-net前端)
- Qemu实现的tun口(内核态)收到包后,交给网桥
- 网桥上数据包会被VPC截获,实现overlay网络功能
- 数据包经过处理后,交给GRE口,进行overlay封装
- Gre口调用物理口的发包函数进行发送。
进来虚拟机方向的数据包处理流程相应反转即可。
初步分析
从上图可以看出,数据包是经过了一条较长的路径,最终从物理口发送出去。
其中每一个流程都是可以成为瓶颈。
于是,我们做了第一步,让虚拟机支持多队列。
虚拟机多队列的选择
两个方案:
- 升级kvm-2.0
- 在kvm-1.0上移植母机多队列
最终,我们选择了移植的方案,理由如下:
- 腾讯云的物理服务器基本上都是kvm-1.0版本,这个版本是不支持多队列的。
- 有kvm-2.0版本,但多队列性能提升并不明显。
- 在kvm-1.0上,我们已经做了大量的工作,也经过了长期运营的检验。
多队列功能的移植
移植涉及到了qemu-kvm虚拟化的所有核心组件:qemu,libvirt,Linux内核。
移植过程的主要问题:
- Patch非常多,Linux内核20+个patch,qemu 20+patch,libvirt patch相对少一点。
- 要兼容旧的qemu和内核。三个组件存在混合部署的情况。
- 热迁移要实现兼容。
最终,和yunfangtai一起,通过谨慎小心的移植,这些目标都实现了。
还有单队列性能瓶颈
多队列移植后,理论上也只能达到kvm-2.0的性能水平。实测也是如此,在20w pps左右。
当时业界Google的性能能达到40w pps。我们只有20w pps。
这其中存在着很大的提升空间。
Vpc overlay基本不配置规则的情况下,性能损失约10%。不是主要矛盾。
通过内核perf工具和流程分析,发现耗在spin_lock的cpu特别高。
主要是在dev_queue_xmit中加锁消耗的。
分析vpc的代码,发现GRE口实现,还是一个单队列网卡。
前面的并发处理,到了GRE口变成了独木桥,性能损失明显。
还是并发瓶颈
将vpc中的GRE虚拟口实现改为多队列之后,性能仍然没有太大的提升。
通过perf采样发现,spin_lock占用的cpu仍然很高,是最可疑的瓶颈点。
分析内核代码流程,最有可能的还是dev_queue_xmit中的队列锁。
这里存在这样一种情况,虚拟机选择队列后,经过一层层选择,最终到物理队列时,会有多个虚拟队列选中同一个物理网卡队列的情况。
问题基本定位清楚,需要做如下修改:
- 虚拟机virtio-net后端的tun实现,要保持虚拟机选的队列。
- Vpc中的gre口实现,不能修改队列映射关系
- 物理口发包时,要保持映射关系不变。
- 同时,多个虚拟机,要保证尽可能利用不同的物理队列,避免相互干扰。
以上修改做完后,性能有了明显提升,达到了业界第一梯队Google GCE的水平。实现了本身的突破。
其他优化
- Qemu自身队列长度限制位256,修改为1024,在大流量下减少丢包。
- 后端tun网卡队列长度优化。
展望
Virtio-net的性能优化,按目前的vhost-kernel框架下,潜力已经很小。
后续方向:
- 硬件offload方案
如智能网卡方案,将vpc部分逻辑offload到服务器之外的设备上。
- Dpdk+vhost-user方案
提升母机发包引擎的性能,同时poll mode能减少虚拟机发包的负担。
原文链接:https://cloud.tencent.com/developer/article/1005895
(免费订阅,永久学习)学习地址: Dpdk/网络协议栈/vpp/OvS/DDos/NFV/虚拟化/高性能专家-学习视频教程-腾讯课堂
更多DPDK相关学习资料有需要的可以自行报名学习,免费订阅,永久学习,或点击这里加qun免费
领取,关注我持续更新哦! !