实时图像增强,基于“间距自适应查找表”的方法(CVPR 2022)
关注公众号,发现CV技术之美
本文分享一篇阿里巴巴大淘宝技术与上海交通大学图像通信与网络工程研究所(简称图像所)合作论文《AdaInt:Learning Adaptive Intervals for 3D Lookup Tables on Real-time Image Enhancement》,全部代码及模型均已开源。

结果示例
本文首次提出了通过深度学习对输入图像自适应地学习具有非均匀布局的三维颜色查找表,从而对输入图像进行高效色彩增强的创新性技术,并在学术界公开仿真数据集上取得了最优客观指标(PSNR)的同时做到了当前运行速度最快。文中提到的色彩增强技术具有效果优、速度快的特点,可做到对4K视频的实现高效处理并提升其色彩饱和度对比度,故而适用于实时流媒体场景,可用较普惠化的方式帮助改善直播间的画质呈现。

论文地址:
https://arxiv.org/abs/2204.13983
项目地址:
https://github.com/ImCharlesY/AdaInt
作者单位:
大淘宝技术,上海交通大学,大连理工大学
背景
色彩增强是图像处理的基本内容之一,是相机成像系统的核心部件之一,并广泛体现在数字图像成像链路中的各阶段应用中。其主要目的是通过处理原始图像,使其更加符合人的视觉特性或显示设备的展示要求。近年来,主流的基于深度学习的色彩增强方法将增强流程简化归并到单个全卷积网络中。通过数据驱动下的端到端学习,这类方法可以在公开数据集上取得先进的色彩增强效果。然而,全卷积范式也给网络的推理,特别是在超高分辨率的图像(如4K及以上分辨率)上,带来了高昂的时空计算复杂度,限制了这些方法的实际应用。
最新的研究工作[1]表明,大部分的色彩增强/美化算子(如白平衡、饱和度控制、色调映射、对比度调整、曝光补偿等)属于点运算的范畴。变换算子的参数会根据图像整体或局部统计特性来确定,但变换算子本身对图像的操作和编辑是位置无关、像素独立的。它们的级联在整体效应上近似等效为单次三维颜色变换,即一个![]() 的函数映射式。该映射将输入图像中的一个颜色点映射为同一颜色空间或不同颜色空间的另一个颜色点。一个直观的思路是将一系列增强变换算子合并为单个颜色变换算子,从而减少一系列变换操作带来的计算量,并减小累积误差对增强效果的影响。
的函数映射式。该映射将输入图像中的一个颜色点映射为同一颜色空间或不同颜色空间的另一个颜色点。一个直观的思路是将一系列增强变换算子合并为单个颜色变换算子,从而减少一系列变换操作带来的计算量,并减小累积误差对增强效果的影响。
在这种情况下,三维查找表(3D Lookup Tables,3D LUTs)是一种极具价值的数据结构,它通过遍历变换函数的所有可能输入颜色组合,记录对应的输出颜色结果,可以对一个复杂的颜色变换函数进行高效建模,在计算机硬件设计、相机成像系统中有广泛的应用。然而,完整输入空间的遍历往往带来沉重的内存开销,更常用的方式是稀疏查找表:对输入空间进行稀疏采样,仅记录采样点的对应输出;对于不被采样到的点,其变换输出由最近邻采样点的输出线性插值获得。因此稀疏查找表实质是对原始变换函数的一种有损近似,其变换能力的损失体现在通过分段线性函数拟合原始变换函数中潜在的非线性部分。
工作动机
由于3D LUT的计算高效性和稳定鲁棒的颜色变换能力,最新的研究工作[2]结合了3D LUT的高效计算性能和深度神经网络的强大数据特征提取能力,通过深度网络从图像中自适应地生成稀疏三维查找表以进行实时色彩增强,证明了3D LUT在基于深度学习的自适应色彩增强中的可行性和有效性。然而,通过深度网络自适应预测稀疏3D LUT时,现有工作仅考虑了3D LUT中记录的输出值的图像自适应性,而却对所有不同图像均采用统一的均匀稀疏点采样策略(将三维输入颜色空间等间隔地离散化成三维网格),未能有效考虑到稀疏3D LUT中采样点在输入空间中的分布也应根据图像内容自适应调整。这一重要建模能力的缺失导致该方法学习到的3D LUT中稀疏采样点分配策略次优,从而限制了最终所得3D LUT的模型变换能力。这具体表现为:由于采样点的稀疏性和3D LUT变换中采用的线性插值带来的非线性变换表达能力的损失,均匀采样策略可能将颜色相近的输入像素量化到3D LUT的同一网格区间内;当这些输入像素的对应输出值需要较高的非线性对比度时(如增强图像中处于暗光条件下具有显著色彩差异的纹理区域时),单个LUT网格却仅能提供线性的颜色拉伸变换,从而可能导致变换结果的颜色平滑。这种现象可以类比为数字信号处理领域中因采样频率不满足奈奎斯特-香农采样定律而导致的信号失真,如下左边示意图所示。理想情况下,增加稀疏采样点的数量或引入非线性插值也许可以有效缓解这种非线性变换能力不足的问题,但也会显著增加3D LUT方法的计算和内存复杂度,牺牲了LUT方法的实时性。此外,如下右半部分的示意图所示,在均匀采样策略中直接增加采样点的数量也会加剧3D LUT对颜色变换平坦区域(如输出颜色仅为输入颜色的线性拉伸)甚至对输入颜色空间中鲜有像素分布的区域的过采样,从而造成了3D LUT模型容量和内存消耗的浪费。

方法介绍
针对现有工作因其在输入空间中通过均匀量化间隔的有限稀疏采样点完成3D LUT的构建而存在的局部非线性颜色变换建模能力不足的挑战,我们提出基于采样间距自适应学习的3D LUT方法来为上述挑战提供一种先进的解决方案,即Adaptive Intervals Learning (AdaInt)。具体而言,我们提出并设计一种轻量紧支的三维颜色空间动态采样间隔预测机制,作为3D LUT方法的一种即插即用模块,自适应地根据输入图像内容预测3D LUT中稀疏采样点的分布方式。通过提供给模型在三维颜色空间中自适应、非均匀采样的能力,模型有望在需要较强非线性变换的颜色空间内分配更多的采样点以提高3D LUT的局部非线性变换能力,在变换较为平坦的区域分配较少的采样点以减少3D LUT的容量冗余,从而提高3D LUT方法的灵活性和图像自适应性。
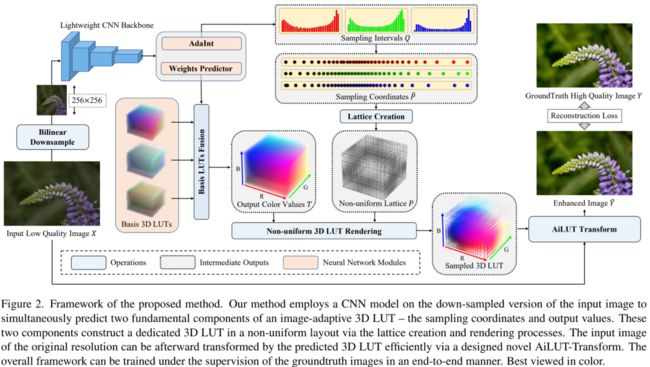
所提方法的整体模型框架如上图所示。我们以待增强的图像作为模型输入,自动输出经过颜色增强的高质图像,并将输出图像与经过人为美化的目标图像计算MSE重建损失,从而实现整个方法框架的端到端学习。
具体模型结构上,我们使用一个轻量的卷积神经网络将下采样到固定分辨率(256x256像素)的输入图像作为输入,通过该网络同时预测图像自适应3D LUT的两个核心组成部件——非均匀的输入颜色采样坐标和相应的输出颜色值。
在3D LUT的输出颜色值上,我们延续现有工作[2]采用的方式——通过网络自动预测系数来针对每张图像动态加权合并若干个可学习的Basis 3D LUTs,以避免直接回归全部输出颜色值所带来的大量网络参数和计算复杂度的引入。
对于非均匀输入颜色采样坐标,我们假设在查找过程中3D LUT的三个颜色维度是相互独立的;通过这种方式,我们可以分别预测每个颜色维度的一维采样坐标序列,并通过笛卡儿积(n-ary Cartesian Product)得到对应的三维采样坐标。
这两个组成部件组合在一起构成一个具有自适应、非均匀三维布局的3D LUT,它可以通过我们精心设计的一种称为 AiLUT-Transform 的新型可微算子对原始输入图像进行高效的颜色变换和增强。具体而言,我们通过在标准的查找表变换的查找过程中引入低复杂度的二分搜索来确定输入颜色在非均匀布局查找表中所在的网格,并通过推导偏微分为网络自动预测的非均匀颜色采样坐标提供梯度以进行端到端学习。
实验结果
本文所提出的AdaInt模块可以在可忽略不计的参数和计算量增加下显著提高基线三维查找表方法的增强效果,如下图所示。

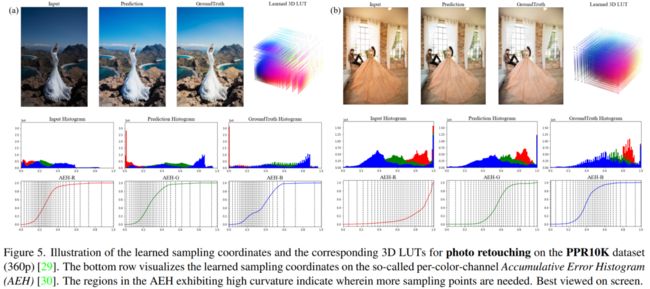
通过对不同输入图像可视化网络学习得到3D LUTs,如下图所示,我们可以观察到针对曝光较弱(左子图)和曝光较强(右子图)的不同输入图像,网络预测的采样坐标(如第三行中竖线所示)分别聚集在了图像的不同灰度值区域。这体现了所提方法如预期一般在大规模数据先验中一定程度学习到了在三维颜色空间自适应采样3D LUT的能力。
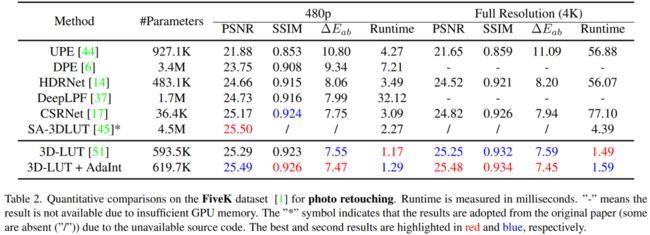
在两个公开图像增强/美化数据集FiveK和PPR10K上,所提方法以总体较低的参数量和实时推理时间在增强图像的客观评价指标上超过了现有方法,达到了先进性能。

总结
在本文中,我们简要介绍了一种新颖的,可用于强化可学习 3D LUT 以进行实时颜色增强的学习机制——AdaInt。其中心思想是引入图像自适应采样间隔来学习非均匀的3D LUT布局。两个公开数据集的实验结果验证了方法在性能和效率方面优于其他先进的现有方法。此外,作者相信本文方法中所蕴含的思想,即对复杂的底层变换函数或表示进行非均匀采样的观点不仅局限于 3D LUTs,也有望指导其他应用的改进,我们将其留作我们未来的工作。
参考文献
[1] Liu Y, He J, Chen X, et al. Very lightweight photo retouching network with conditional sequential modulation[J]. arXiv preprint arXiv:2104.06279, 2021.
[2] Zeng H, Cai J, Li L, et al. Learning image-adaptive 3D lookup tables for high performance photo enhancement in real-time[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020.
团队介绍
该工作主要在大淘宝技术中支持内容业务的音视频算法与基础技术团队的带领下完成,该团队依托淘宝直播、逛逛和点淘等内容业务,致力于打造行业领先的音视频技术。团队成员来自海内外知名高校,先后在MSU世界编码器大赛,NTIRE视频图像增强领域这样的领域强相关权威赛事上夺魁,并重视与学界的合作与交流。
本工作的色彩增强任务与团队实际业务场景中调色的功能需求密切相关。调色是淘宝主播提升直播间画质的重要手段之一,往往依赖专业人员以及配套软件,使用门槛和成本较高。我们的色彩增强工作,旨在自动化的帮助用户完成原本专业性强操作复杂度较高的调色工作,更好地帮助主播提升直播间画质,改善直播画质体验。
这项工作的主要合作方为上海交通大学张文军教授领衔的图像所团队,是数字电视广播及数字媒体处理与传输领域的主要研究力量之一。近年来,团队面向国家战略性新兴产业,顺应网络化、融合化的发展趋势,在包括智能媒体融合网络、视频智能分析处理与传输在内的多个重点研究领域开展工作,并取得了多项重大成果。
作者|杨璨乾、金美光
编辑|橙子君

END
欢迎加入「图像增强」交流群备注:增强
