数据级并行--计算机体系结构
参考书:《计算机体系结构量化研究方法》 作者:John L. Hennessy
一、 引言
指令流与数据流的并行分类
- 单指令流、单数据流(SISD)
- 单指令流、多数据流(SIMD)
- 多指令流、单数据流(MISD)基本不使用这种类型
- 多指令流、多数据流(MIMD)
SIMD相比于MIMD的优势
由于数据操作是并行的,所以程序员可以采用顺序思维方式但却能获得并行加速比
SIMD的三种变体
- 向量体系结构
- 多媒体SIMD指令集扩展
- 图形处理单元(GPU)
二、 向量体系结构
本质:以流水线形式来执行多数据操作
2.1 VMIPS指令集体系结构
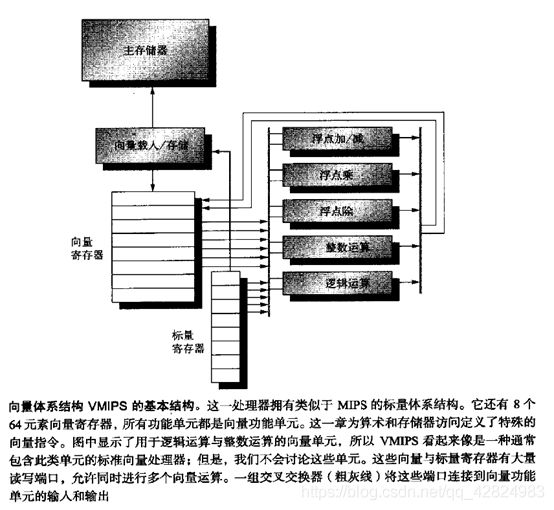
基于MIPS指令集,我们看一个向量处理器,VMIPS;它的标量部分为MIPS,它的向量部分是MIPS的逻辑向量扩展。主要组件如下:
示例:实现DAXPY(double precision ax plus y,ax+y)
MIPS代码如下,
L.D FO,a
DADDIU R4,Rx,#512 ;载入最后地址
LOOP: L.D F2,0(Rx) ;载入x[i]
MUL.D F2,F2,F0
L.D F4,0(Ry)
ADD.D F4,F4,F2
S.D F4,9(Ry)
DADDIU` Rx,Rx,#8 ;递增X
DADDIU Ry,Ry,#8
DSUBU R20,R4,Rx ;计算范围
BNEZ R20,LOOP ;检查是否完成
DAXPY的VMIPS代码:
L.D F0,a
LV V1,Rx
MULVS.D V2,V1,F0
LV V3,Ry
ADDVV.D V4,V2,V2
SV V4,Ry
向量处理器最大的好处就是大幅度缩短了动态指令带宽,仅执行6条指令,而MIPS几乎要执行600条。这一缩减是因为向量运算是对64个元素执行的,在MIPS中差不多占据一般循环的开销指令在VMIPS中是不存在的。如果循环的迭代之间没有相关性(循环间相关),那么这些循环就可以向量化。
2.2 向量执行时间
几个基础概念
- 护航指令组:其中指令不能包含任何结构性冒险的一组向量指令
- 钟鸣:用于估计护航指令组执行时间的度量单位,执行m个护航指令组构成的向量序列需要m次钟鸣
- 链接:将不存在结构性冒险的数据链接(转发)在一起
影响执行时间的因素
- 操作数向量的长度
- 操作之间的结构性冒险
- 数据相关
向量执行时间开销源
- 发射限制
- 向量启动时间
2.3 多车道
向量指令集的优点与特性
- 允许软件使用一条很短的指令就能向硬件传送大量并行任
务
- 所有向量算数指令只允许一条指令的向量寄存器N与其他向量寄存器的元素N进行运算
因此采用多车道来提高向量单元的峰值吞吐量。结构如图:

从单车道变为了四车道后,就会将1次钟鸣的时钟周期数由64变为了16个。由于多车道非常有利,所以应用程序和体系结构都必须支持长向量;否则,它们的快速执行速度会耗尽指令带宽。
需要注意的是四条车道彼此之间并不联系,这样避免通信就减少了构建高并行执行单元所需要的连接成本与寄存器端口。
2.4 向量长度寄存器:处理不等于64的循环
实际上,特定向量运算的长度在编译时通常是未知的。如下代码:
for (i=0;i
所有的向量长度都取决于n,而它的取值在执行前不可能知道。
解决方案:向量长度寄存器(VLR)
但VLR中的不能超过最大向量长度(MLR),但是一不小心大于MLR怎么办,毕竟长度都是未知的。所以就需要采用条带挖掘的技术
条带挖掘:生成一些代码,使每个向量运算都是针对小于或等于MVL的大小来完成的。一般条带挖掘采用两个循环:
- 循环处理迭代数为MVL倍数的情况
- 处理所有其他迭代及小于MVL的情况
如下是C语言中DAXPY条带挖掘的版=本:
low = 0;
VL = (n % MVL); //使用求模运算找出不规则大小部分
for (j=0;j<=(n/MVL);j++) {
for (i=low;i<(low+VL);i++) //执行长度为VL
y[i] = a * x[i] + y[i];
low = low + VL;
VL = MUL; //将长度复位为最大向量长度
}
主要思想是执行(n/MVL+1)次循环,在循环的第一次执行长向量的非规则部分。
2.5 向量遮罩寄存器:处理向量循环中的if语句
对于中低向量化级别的程序,加速比是非常有限的。导致循环向量化程度较低的两个主要原因:
- 循环内部存在条件(if语句)
- 稀疏矩阵的存在
因此引入遮罩寄存器。遮罩寄存器可以用来实现一条向量指令中每个元素的条件执行。在启用向量遮罩寄存器时,任何向量指令都只会针对符合特定条件的向量元素来执行,即这些元素在向量遮罩寄存器中的相应项目为1.如:
SNEVS.D V1,F0 ;只有V1向量不为F0,才继续执行后续指令
SUBVV.D V1,F1,V2 ;在向量遮罩下执行减法
遮罩寄存器的开销:
- 条件执行的指令在不满足条件时也需要执行时间
三、 图形处理器
GPU的祖先是图形加速器,极强的图形处理能力是GPU得以存在的原因。
GPU几乎拥有所有可以由编程环境捕获的并行类型:多线程、MIMD、SIMD、指令集并行。
NVIDIA开发了一种与C类似的语言和编程环境,通过客服异质计算及多种并行带来的双重挑战来提高GPU程序员的生产效率。这一效率的名称为CUDA:compute unified device architecture,计算统一设备体系。所有这些并行形式的统一主题就是CUDA线程。
以最低级别的并行作为编程原型,编译器和硬件可以将数以千计的CUDA线程聚合在一起,利用GPU中的各种并行类型:多线程,MIMD、SIMD、指令级并行。因此NVIDIA将CUDA编程定义为:单指令多线程(SIMT)。这些线程进行了分块,在执行时以32个线程为1组,称为线程块,我们马上就会明白其原因。我们将执行整个线程块的硬件称为多线程SIMD处理器。
我们只需要几个细节就能给出CUDA编程的示例。
为了区分GPU(设备)的功能与系统处理器(主机)的功能,CUDA使用__device__或__global__表示前者,使用__host__表示后者。
被声明为__device__或__global__functions的CUDA变量被分配给GPU存储器,可以供所有多线程SIMD处理器访问。
对于在GPU上运行的函数name进行扩展函数调用的语法为:
name<<>>(…parameter list…)
其中dimGrid和dimBlock规定了代码的大小(用块表示)和块的大小(用线程表示)
除了块识别符(blockIdx)和每个线程识别符(threadIdx)之外,CUDA还为每个块的线程数提供了一个关键字(blockDim),它来自上一个细节中提到的dimBlock参数。一下是DAXPY的cuda代码:
//调用DAXPY,每个线程块中有256个线程
__host__
int nblocks = (n+255)/256;
daxpy<<>>(n,2.0,x,y);
//CUDA中的DAXPY
__device__
void daxpy(int n,double a,double *x, double *y)
{
int i = blockIdx.x * blockDim.x +threadIdx.x;
if (i 如何理解tid为blockIdx.x * blockDim.x +threadIdx.x呢?
首先要了解网格与线程的关系,如下:
