解决在使用rtx2060跑算法时遇到显存不足的问题
解决在使用rtx2060跑算法时遇到显存不足的问题
打算在服务器上测试下图像分割算法速度的时候遇到了可能是显存不足的问题。具体报错如下:
WARNING:tensorflow:From /home/zhonghui/anaconda3/envs/py36/lib/python3.6/site-packages/tensorflow/python/framework/op_def_library.py:263: colocate_with (from tensorflow.python.framework.ops) is deprecated and will be removed in a future version.
Instructions for updating:
Colocations handled automatically by placer.
2021-11-18 10:40:20.034439: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
2021-11-18 10:40:20.153434: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:998] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-11-18 10:40:20.153808: I tensorflow/compiler/xla/service/service.cc:150] XLA service 0x55aa738506d0 executing computations on platform CUDA. Devices:
2021-11-18 10:40:20.153822: I tensorflow/compiler/xla/service/service.cc:158] StreamExecutor device (0): GeForce RTX 2060, Compute Capability 7.5
2021-11-18 10:40:20.172688: I tensorflow/core/platform/profile_utils/cpu_utils.cc:94] CPU Frequency: 3000000000 Hz
2021-11-18 10:40:20.173430: I tensorflow/compiler/xla/service/service.cc:150] XLA service 0x55aa7394ad20 executing computations on platform Host. Devices:
2021-11-18 10:40:20.173477: I tensorflow/compiler/xla/service/service.cc:158] StreamExecutor device (0): <undefined>, <undefined>
2021-11-18 10:40:20.173696: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1433] Found device 0 with properties:
name: GeForce RTX 2060 major: 7 minor: 5 memoryClockRate(GHz): 1.71
pciBusID: 0000:04:00.0
totalMemory: 5.79GiB freeMemory: 5.63GiB
2021-11-18 10:40:20.173741: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1512] Adding visible gpu devices: 0
2021-11-18 10:40:20.174744: I tensorflow/core/common_runtime/gpu/gpu_device.cc:984] Device interconnect StreamExecutor with strength 1 edge matrix:
2021-11-18 10:40:20.174780: I tensorflow/core/common_runtime/gpu/gpu_device.cc:990] 0
2021-11-18 10:40:20.174794: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1003] 0: N
2021-11-18 10:40:20.174928: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1115] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 5466 MB memory) -> physical GPU (device: 0, name: GeForce RTX 2060, pci bus id: 0000:04:00.0, compute capability: 7.5)
/home/zhonghui/unet/logs/1110-v1.h5 model loaded.
./raw/J036SAG14.jpg
2021-11-18 10:40:21.113571: E tensorflow/stream_executor/cuda/cuda_dnn.cc:334] Could not create cudnn handle: CUDNN_STATUS_INTERNAL_ERROR
2021-11-18 10:40:21.116589: E tensorflow/stream_executor/cuda/cuda_dnn.cc:334] Could not create cudnn handle: CUDNN_STATUS_INTERNAL_ERROR
Traceback (most recent call last):
File "/home/zhonghui/anaconda3/envs/py36/lib/python3.6/site-packages/tensorflow/python/client/session.py", line 1334, in _do_call
return fn(*args)
File "/home/zhonghui/anaconda3/envs/py36/lib/python3.6/site-packages/tensorflow/python/client/session.py", line 1319, in _run_fn
options, feed_dict, fetch_list, target_list, run_metadata)
File "/home/zhonghui/anaconda3/envs/py36/lib/python3.6/site-packages/tensorflow/python/client/session.py", line 1407, in _call_tf_sessionrun
run_metadata)
tensorflow.python.framework.errors_impl.UnknownError: Failed to get convolution algorithm. This is probably because cuDNN failed to initialize, so try looking to see if a warning log message was printed above.
[[{{node block1_conv1/convolution}}]]
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "predict.py", line 91, in <module>
predict('./raw/', './result/jiangxi_mask/')
File "predict.py", line 64, in predict
r_image = unet.detect_image(image)
File "/home/zhonghui/unet/unet.py", line 100, in detect_image
pr = self.model.predict(img)[0]
File "/home/zhonghui/anaconda3/envs/py36/lib/python3.6/site-packages/keras/engine/training.py", line 1835, in predict
verbose=verbose, steps=steps)
File "/home/zhonghui/anaconda3/envs/py36/lib/python3.6/site-packages/keras/engine/training.py", line 1330, in _predict_loop
batch_outs = f(ins_batch)
File "/home/zhonghui/anaconda3/envs/py36/lib/python3.6/site-packages/keras/backend/tensorflow_backend.py", line 2478, in __call__
**self.session_kwargs)
File "/home/zhonghui/anaconda3/envs/py36/lib/python3.6/site-packages/tensorflow/python/client/session.py", line 929, in run
run_metadata_ptr)
File "/home/zhonghui/anaconda3/envs/py36/lib/python3.6/site-packages/tensorflow/python/client/session.py", line 1152, in _run
feed_dict_tensor, options, run_metadata)
File "/home/zhonghui/anaconda3/envs/py36/lib/python3.6/site-packages/tensorflow/python/client/session.py", line 1328, in _do_run
run_metadata)
File "/home/zhonghui/anaconda3/envs/py36/lib/python3.6/site-packages/tensorflow/python/client/session.py", line 1348, in _do_call
raise type(e)(node_def, op, message)
tensorflow.python.framework.errors_impl.UnknownError: Failed to get convolution algorithm. This is probably because cuDNN failed to initialize, so try looking to see if a warning log message was printed above.
[[node block1_conv1/convolution (defined at /home/zhonghui/anaconda3/envs/py36/lib/python3.6/site-packages/keras/backend/tensorflow_backend.py:3335) ]]
Caused by op 'block1_conv1/convolution', defined at:
File "predict.py", line 27, in <module>
unet = Unet()
File "/home/zhonghui/unet/unet.py", line 36, in __init__
self.generate()
File "/home/zhonghui/unet/unet.py", line 45, in generate
self.model = unet(self.model_image_size, self.num_classes)
File "/home/zhonghui/unet/nets/unet.py", line 18, in Unet
feat1, feat2, feat3, feat4, feat5 = VGG16(inputs)
File "/home/zhonghui/unet/nets/vgg16.py", line 11, in VGG16
name='block1_conv1')(img_input)
File "/home/zhonghui/anaconda3/envs/py36/lib/python3.6/site-packages/keras/engine/topology.py", line 619, in __call__
output = self.call(inputs, **kwargs)
File "/home/zhonghui/anaconda3/envs/py36/lib/python3.6/site-packages/keras/layers/convolutional.py", line 168, in call
dilation_rate=self.dilation_rate)
File "/home/zhonghui/anaconda3/envs/py36/lib/python3.6/site-packages/keras/backend/tensorflow_backend.py", line 3335, in conv2d
data_format=tf_data_format)
File "/home/zhonghui/anaconda3/envs/py36/lib/python3.6/site-packages/tensorflow/python/ops/nn_ops.py", line 851, in convolution
return op(input, filter)
File "/home/zhonghui/anaconda3/envs/py36/lib/python3.6/site-packages/tensorflow/python/ops/nn_ops.py", line 966, in __call__
return self.conv_op(inp, filter)
File "/home/zhonghui/anaconda3/envs/py36/lib/python3.6/site-packages/tensorflow/python/ops/nn_ops.py", line 591, in __call__
return self.call(inp, filter)
File "/home/zhonghui/anaconda3/envs/py36/lib/python3.6/site-packages/tensorflow/python/ops/nn_ops.py", line 208, in __call__
name=self.name)
File "/home/zhonghui/anaconda3/envs/py36/lib/python3.6/site-packages/tensorflow/python/ops/gen_nn_ops.py", line 1026, in conv2d
data_format=data_format, dilations=dilations, name=name)
File "/home/zhonghui/anaconda3/envs/py36/lib/python3.6/site-packages/tensorflow/python/framework/op_def_library.py", line 788, in _apply_op_helper
op_def=op_def)
File "/home/zhonghui/anaconda3/envs/py36/lib/python3.6/site-packages/tensorflow/python/util/deprecation.py", line 507, in new_func
return func(*args, **kwargs)
File "/home/zhonghui/anaconda3/envs/py36/lib/python3.6/site-packages/tensorflow/python/framework/ops.py", line 3300, in create_op
op_def=op_def)
File "/home/zhonghui/anaconda3/envs/py36/lib/python3.6/site-packages/tensorflow/python/framework/ops.py", line 1801, in __init__
self._traceback = tf_stack.extract_stack()
UnknownError (see above for traceback): Failed to get convolution algorithm. This is probably because cuDNN failed to initialize, so try looking to see if a warning log message was printed above.
[[node block1_conv1/convolution (defined at /home/zhonghui/anaconda3/envs/py36/lib/python3.6/site-packages/keras/backend/tensorflow_backend.py:3335) ]]
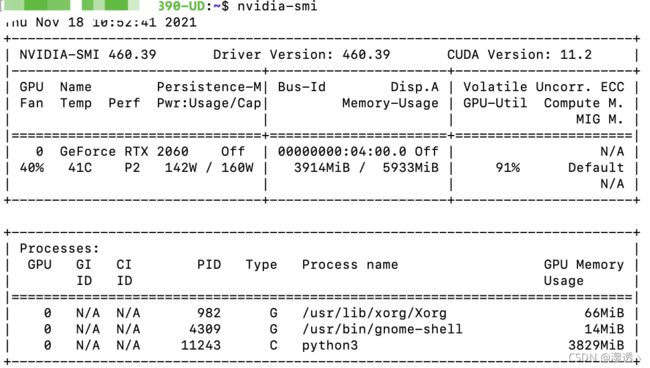
在报错的瞬间通过nvidia-smi查看了显存使用情况。

显存几乎是占满的。所以可能是因为2060显卡显存只有6g不够用的问题。同样的代码在2080上跑没有出现问题。
解决办法如下:
在代码里添加以下代码
import tensorflow as tf
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
session = tf.Session(config=config)
目的是设置gpu动态使用显存。当然也可以设置固定使用多少百分比,比如用30%、70%。这样可以让一台机器同时开两三个AI项目。
再次运行下代码通过nvidia-smi看显存使用情况如下。