基于TADK的应用分类
基于TADK的应用分类
Traffic Analytics Development Kit (TADK) 是Intel 推出的针对IA平台高度优化的流量分析开发套件。其核心模块流特征提取库Flow Feature Extraction Library (FFEL) 和 基于机器学习的模型 (Model) 可以为用户提供精确的应用分类能力。基于机器学习的应用分类较传统基于深度报文检测的方法有着更广泛的适用性,并且对于加密报文也有一定的检测能力。
FFEL 可以从离线pcap文件或者在线网口获得流量并提取其特征输出到指定文件。其主要提取的特征包括: 包的上下行数目, 包头长度及其分布, 载荷长度及其分布, 包的持续时间等包级别的特征; 协议类型及字符串信息等流级别的特征。对于包头及包载荷分布的计算 (本质上是直方图计算),利用AVX512进行优化,其性能(吞吐量)较传统C实现的方法有着1.33~11. 73倍的提升。对于字符串信息(从tls 的sni及http的url等提取),采用词袋(BOW)模型将其转化成数值特征。统计学特征加上BOW特征构成最终的特征向量,两者结合也能有效提升模型推理的精确度。另外,FFEL也提供了用户增加自己所需特征的接口,方便用户对特征进行定制化。特征提取的流程见图1。

图1. 特征提取流程
模型选用的是Intel oneDAL (数据分析加速库)提供的随机森林(Random Forest, RF)算法。RF算法因其具有较高的推理精度及较快的推理速度在分类问题上应用非常广泛。oneDAL针对IA平台做了高度优化(指令集优化,内存优化等),故oneDAL的RF较传统的基于python实现的SK-LEARN的RF推理速度 有着3个数量级的提升,为实际部署应用中进行实时推理提供了更多的可能性。模型部分包括离线训练和在线推理两部分。
获得干净并带有标签的训练样本是训练模型的前提条件,只有足够多的干净的样本才能训练出有效的模型。传统人工打标签的方法需要逐条流检查,筛选出适合训练的数据并打上标签,如果数据量很大,则可能耗费数小时甚至数天才能完成数据清洗的工作。
因此TADK提出了一种基于聚类的半自动打标签方法,借助python脚本,辅以少量的人工干预即可获得干净的带有标签的训练样本并保存成CSV文件。聚类是一种非监督式学习算法,其根据数据自身在某些维度的相似性将数据自动分为不同的类。
图2以发送字节数和接收字节数两个维度来举例,将数据分成ABCD四类,可以明显观察到A类是下载类应用而D类是上传类应用。通过聚类算法也可以很容易的去除数据中的杂流,因为杂流通常会被划分为远离干净数据的孤立的点。

图2. 聚类效果图
oneDAL读入CSV文件,调用RF算法训练生成所需模型并将其序列化保存成磁盘文件(model.txt)便于分布式的部署进行线上推理。模型的精确度及推理速度受特征影响很大,oneDAL也提供了特征选择算法帮助我们选择最合适的特征集(selected_feature.txt)。由于训练样本是日渐积累的,故TADK也提供模型增量更新的能力,每次加进新的训练样本,脚本会将其与旧样本结合训练出一个新的模型。离线训练的过程如图3所示。
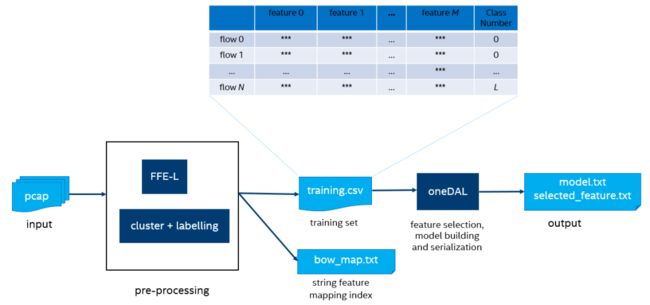
图3. 离线训练流程
TADK提供了名为tadk_probe的application来演示流量特征提取及推理的效果。tadk_probe在初始化的时候读入模型文件,将其反序列化并保存在模型目标变量中。同时读入特征映射文件,为后续做特征选择提供帮助。tadk_probe可以从pcap文件或者网口获得应用流量,根据每个报文的五元组将其统计在不同的流结构体内。
当每条流满足一定的条件时(达到最大报文数目或者达到老化时间)调用FFEL获得特征向量,经过特征选择后将其传递给模型变量进行推理得到所属应用的分类ID。模型在训练的时候会将应用名称映射成数字 (0, 1, 2…)并保存成app_map.json文件。推理结果可参考此文件获得应用名称。整个过程如图4所示。

图4. 线上推理流程
TADK 21.08发布包提供了参考模型,位于$TADK_ROOT(TADK根目录)/model/traffic_classify/下。该模型是由8个类型的应用数据训练而成,参考目录下的app_map.json ({"baidu": 0, "baidu (no string)": 1, "Youku": 2, "Youku (no string)": 3, "iqiyi (no string)": 4, "WXWork": 5, "WXWork (no string)": 6, "iqiyi": 7}) 即可知道应用名和ID的对应关系。
发布包也提供了测试数据baidu_test.pcap, 位于$TADK_ROOT/test/data/目录下。用户可以快速测试tadk_probe的效果。步骤如下(Linux 平台) :
>> sh tadk_v21.08.sh
>> cd tadk_v21.08/
>> make
>> ./build-root/install-root/bin/tadk_probe -i ./test/data/baidu_test.pcap
-m model/traffic_classify/
结果如图5所示。可以看到class:0对应的正是baidu,推理结果是正确的。tadk_probe不但可以提取特征及给出推理结果,还统计了流量的协议类型占比及总的流, 包及字节数目,提供了较为完善的流量分析。
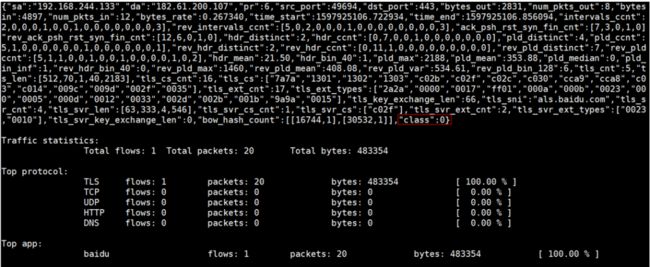
图5. 测试结果

转载须知
DPDK与SPDK开源社区
公众号文章转载声明
推荐阅读
基于TADK的SQLI检测
2021美国峰会系列三 | SPDK性能基准测试
SPDK动态负载均衡
2021美国峰会系列二 | SPDK与云原生
基于英特尔平台的三星5G核心网高性能UPF 305 Gbps解决方案


点点“赞”和“在看”,给我充点儿电吧~