从SPDK Blobstore到 Blob FS
前言
SPDK通过绕过内核(kernel bypass)的方案,构筑了用户态驱动,并利用异步轮询、无锁机制等,极大地提升了I/O性能。然而,正因为采用了kernel bypass的设计,使得原本内核中的文件系统不能使用。因此,SPDK提供了Blobstore用来支持上层存储服务,并基于此封装了Blob FS(Blob Filesystem)文件系统。
当前Blob FS实现了对RocksDB的集成测试(对RocksDB的集成可参考[1]),由于前文[2]已经对Blobstore和Blob FS做过一些介绍,本文就续接前文,对其细节进行补充。
Blobstore设计框架
图1展示了Blobstore主要存储结构的层次关系以及调用关系,可以看到Blobstore位于Bdev层之上。在SPDK的设计中,Bdev作为子系统,用来支持各个块设备,并提供了通用块设备的抽象,其作用可以看作内核中通用块层,它屏蔽了底层的具体实现,而对外提供统一的接口,例如在Bdev子系统中实现了NVMe Bdev模块可以支持对NVMe设备的I/O操作。整个Blobstore的核心代码位于spdk/lib/blob/blobstore.c文件中。
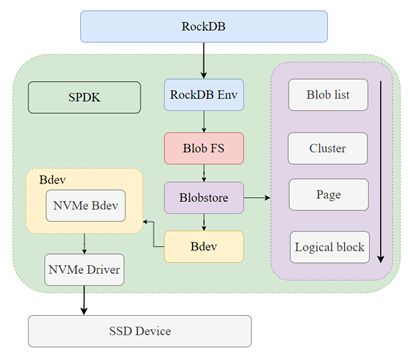
图1. RockDB调用关系和Blobstore存储结构
SPDK提供的Blobstore存储框架,其本质是维护blob分配管理,blob的概念类似文件,但并不与文件等同,本身并不满足POSIX接口,然而Blobstore可以作为底层存储基础用来支持更上层的存储业务,例如下文将提到的Blob FS以及逻辑卷管理等等。整个Blobstore的设计围绕异步与并行,即对多个Blob采用的是无锁、异步并行的I/O操作。而为了支撑逻辑卷管理[5],需要不同的操作粒度以及动态空间的划分,Blobstore定义了层次的存储单元结构,整个结构自上而下分为blob,cluster,page,logical block。
其中,logical block是存储设备本身的存储单元大小,通常一个logical block的大小为512B或者4KB,整体空间可以划分为0~N个logical block;page由一个或多个连续的logical block组成,page的大小通常为4KB,这是由于 Blobstore的原子操作主要依赖后端设备能支持的粒度,而NVMe SSD通常提供原子操作粒度为4KB;多个连续的page将构成我们的cluster,同样整个cluster的编号也是连续的,cluster的大小通常被定义为1MB,即由256个连续的page组成,可以发现cluster以下均是由连续存储单元组成,这样的设计出于性能的考虑,在进行I/O操作时,通过起始地址,长度以及偏移量就可以很快计算得到对应的存储位置;在cluster之上则是blob,存放在blob中的cluster并不要求一定连续,这与逻辑卷管理的动态空间划分有关,Blobstore将blob放在了blob list中进行统一的维护。
针对上层的业务,Blobstore屏蔽了cluster、page以及logical block的设计细节,仅暴露出blob单元。更多针对Blobstore存储单元的说明,可参考文献[3],这里仅强调一下cluster 0的作用,它包含了Blobstore所有信息以及元数据,实现了对blob的分配、查找等功能的依赖,其主要结构以及实现方式可参考文献[2],这里不再赘述。另外,出于性能的考虑Blobstore维护了两组元数据,其中一组保留在内存中,只有当程序显示调用或者正确关闭Blobstore时,才会将两组元数据进行同步。每组元数据的组成分为全局元数据和每个blob中的元数据,通常情况下,当Blobstore正常关闭时,元数据将保持一致,否则,在下一次启动时,将会根据需要利用每个blob中的元数据解析重建全局元数据,耗费额外的时间进行初始化,这将会造成一定的性能损失。
Blobstore example
SPDK官方网站上[3]提供了两个示例,方便用户快速了解使用Blobstore。hello_blob.c演示了基本的API的使用,并为了方便,后端存储并没有借助NVMe Bdev,而是采用了Malloc Bdev模块,也就是无需要求本地配有NVMe设备就可以运行,相关配置信息存放在hello_blob.json中,其测试命令如下:
./build/examples/hello_blob ./examples/blob/hello_world/hello_blob.json
另一个关于Blobstore示例是利用命令行的方法对Blobstore进行交互,其代码位于spdk/examples/blob/cli/blobcli.c。他提供了多种操作模式来完成对Blobstore的操作,例如快速交互的shell mode,同样需要进行相关json配置文件,一个简单的方法是直接利用挂载的本地NVMe设备。
./scripts/gen_nvme.sh --json-with-subsystems > blobcli.json
完成配置以后,可通过以下命令将进入shell mode对Blobstore下的Nvme0n1进行操作,更多命令可阅读help中的说明。
./build/examples/blobcli -b Nvme0n1 -S
Blob FS (Blob Filesystem) 设计框架
Blob FS被设计为面向Blobstore的轻量级文件系统,它提供给用户基本的文件操作: read、write、open、delete等。在介绍Blob FS的框架之前,首先介绍两个概念spdk_io_device和spdk_io_channel,在SPDK的早期设计中,spdk_io_device被设计为存储设备的抽象,并将特定线程的队列抽象为spdk_io_channel。这样的好处是为了避免竞争以及其带来的全局锁定,在SPDK线程模型中,每个spdk_thread通过各自的spdk_io_channel对spdk_io_device进行访问,这样不同的spdk_thread被隔离(无论是否同属于一个reactor,针对SPDK线程模型的介绍可参考[4])。这种类似的设计被推广,spdk_io_device被抽象成任何地址,不仅仅是底层存储设备的映射,也包含了对线程资源的逻辑管理结构。spdk_io_channel也随之被抽象成与spdk_io_device相关联的线程上下文,通过spdk_get_io_channel()函数,可以很方便的获取某个spdk_io_device上对应的channel。在SPDK中,所有的spdk_io_device会通过RB_TREE来维护,这有利于查找。

图2. SPDK io_device与io_channel
Blob FS在工作状态下会注册两个spdk_io_device,分别是blobfs_md以及blobfs_sync,前者带有md后缀,在Blob FS框架下,这被设计为与元数据(metadata)的操作有关,例如create,后者则是与I/O(read & write)操作有关。两个spdk_io_device绑定在一个reactor 0上,相当于对外提供了两个交互通道。根据前文所述,不同的spdk_thread没有办法共用一个spdk_channel,这就保证了只有reactor 0才能Blob FS进行交互,有效避免了多线程之间的竞争以及同步问题,例如对元数据的操作只能经由reactor 0实现,其他用户线程或者绑定在其他线程中的reactor对元数据的操作均需要通过SPDK中的消息机制来实现,交由reactor 0来进行处理,这种设计与SPDK的run-to-completion理念相符,所以工作流程可总结如下图所示。

图3. Blob FS调用层级关系
Cache机制
为了加速文件的I/O性能,Blob FS提供了一套cache机制。DPDK提供的大页管理是SPDK实现零拷贝机制的基础,实际上这也是Blob FS中cache机制的基础。借助DPDK内存池对大页的管理,一次性申请到了一块较大的缓冲区mempool,该区域除了头部以外主要由固定大小的内存单元组成,并构成了ring队列,可方便的用于存取数据。

图4. mempool 数据结构
针对内存池对大页的管理,DPDK用到的接口主要有三个,SPDK对其进行了封装:
rte_mempool_creat (count ,element…) |
spdk_mempool_create (count ,element…) |
利用大页,创建一个内存池,内存池中存放有一定数量的固定大小内存单元 |
rte_mempool_get |
spdk_mempool_get |
获取内存池中的一个内存单元 |
rte_mempool_put |
spdk_mempool_put |
将不再使用的内存单元放回内存池中 |
表1 SPDK内存池调用主要接口
在Blob FS中,固定大小的内存单元其大小被设置为CACHE_BUFFER_SIZE,该值体现了cache机制中基本的存储单元,内存单元的数量可以采用默认值也可以通过Blob FS预留的接口进行重新设置。为了方便管理整个cache机制中的内存,Blob FS创建了一个新的spdk_thread线程g_cache_pool_thread。它主要维护了g_caches和g_cache_pool两个数据结构,前者维护了所有拥有cache的文件列表,后者则指向了前文提到的借助DPDK大页管理所申请到的内存池。与此同时,在该线程上还注册了一个poller函数用于监测内存池的使用情况,当内存池中空闲内存单元数量下降到20%以下时,会对已缓存的内存池对象进行清理释放,将内存单元返还给内存池,并且会优先释放低优先级的文件缓存,用户程序可根据需要调整缓存文件的优先级。
Blob FS对文件的管理依赖了spdk_file数据结构,在spdk_file中利用了cache_tree数据结构来对该文件的cache进行管理。cache tree由多层树状节点构成,维护了两种数据节点: tree node和buffer node,其中tree node充当了索引的作用,他可以根据根节点以及对应的offset,自上而下查找对应的buffer node;buffer node是实际缓存文件数据的节点,他位于整个cache tree的最底层,buffer node中用于缓存文件数据的空间实际上就是前文中提到的借助内存池申请到的一个个内存单元,因此单个buffer node中所能缓存文件数据的大小也就是CACHE_BUFFER_SIZE,在默认情况下,该值为256KB。
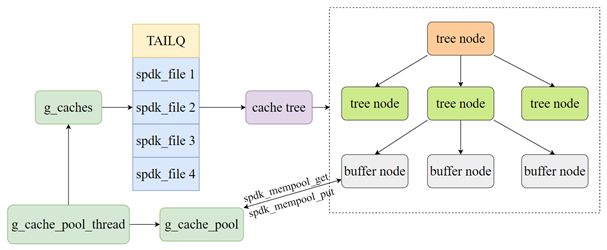
图5. Blob FS cache机制
Blob FS I/O操作
尽管Blob FS中提供了同步和异步两种I/O操作,但当前集成并使用的是同步读。因此,本文就I/O过程结合上述cache机制进行说明。
spdk_file_read
首先,Blob FS会依据本次读取数据的大小进行判断,当读取数据大于CACHE_READAHEAD_THRESHOLD(默认情况下,该值为128KB)时,触发异步预读(readahead)操作,提前将一部分数据读取到内存中,随后对读取的数据进行切分,使得每次读取数据不超过buffer node的大小,即CACHE_BUFFER_SIZE的值。切分以后的读取,会先根据当前offset的值在cache tree中查询对应的buffer node,如果可以找到对应的buffer node节点,即说明缓存命中,直接将其缓存的文件数据执行memcpy拷贝到payload中,否则则需要通过Blobstore提供的异步读取直接从存储设备读取,并利用sem信号量进行同步,直到所有的读取完成,一次性返回整个payload,所以整个读取过程需要等待所有的payload准备完成才会返回。
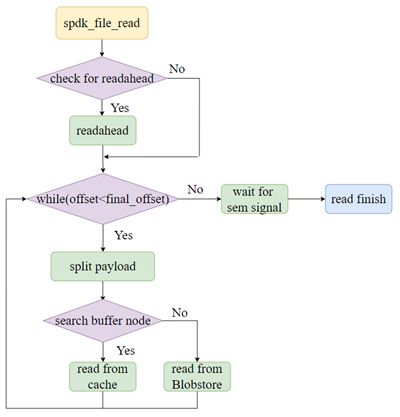
图6. spdk_file_read读取过程
spdk_file_write
目前SPDK主分支中的Blob FS提供的写入接口当前仅支持append类型,即不支持覆盖写入操作(注1)。对于append类型写入,Blob FS会首先检查其是否满足cache机制条件,如果不满足则借助Blobstore提供的写入接口,直接写入存储设备中。而一旦满足cache机制,则利用spdk_mempool_get函数向内存池中申请一个内存单元作为buffer node用于存储文件数据,随后将写入的payload进行切分,保证每次写入数据不超该buffer node的大小,并利用memcpy拷贝至buffer node中,当当前buffer node已被写满但存储文件还未被完全写入时,会将当前buffer node添加到cache tree中,再重新申请内存单元,重复上述操作,直到所有的payload都被写入buffer node中。随后触发异步flush操作,将cache tree中存储的文件数据利用Blobstore写入到存储设备中,并更新内存中的元数据。

图7. spdk_file_write写入流程
从上述I/O过程可以发现,cache机制起到的加速作用主要体现在两点:
Read阶段中利用预读机制,先将当前offset附近的部分数据从存储设备中读入到内存中,方便下次直接从内存中读取,而不借助Blobstore,从而提升效率。
Write阶段中将payload优先写入到cache tree中,再利用异步flush操作写入到存储设备中,write本身不需要等待在落盘结束。
值得注意的是,分析Blob FS中cache的默认参数配置以及机制设计,可以发现Blob FS提供的cache机制更适用于大文件的读取。
注1:Blob FS对随机写的支持可参考 https://review.spdk.io/gerrit/c/spdk/spdk/+/5420,但是对目前的Blob FS cache机制有影响。更多Blob FS的patch,也可以关注https://review.spdk.io/。
SPDK FUSE (Filesystem in Userspcae)
SPDK提供了FUSE插件,可以将Blob FS像内核文件系统一样挂载,方便测试。可利用本地NVMe设备,基于SPDK FUSE挂载Blob FS,方法可参考以下步骤:
(代码部分建议手机横屏或电脑网页端阅读~)
1. ./configure --with-fuse && make
2. scripts/gen_nvme.sh --json-with-subsystems > config.json
3. ./test/blobfs/mkfs/mkfs config.json Nvme0n1
4. mkdir /mnt/fuse
5. ./test/blobfs/fuse/fuse config.json Nvme0n1 /mnt/fuse
当然,也可以借助rpc框架,调用bdev子系统中Malloc Bdev模块,启用Blob FS文件系统,启用方法如下:
1. ./build/bin/spdk_tgt // Terminal A
2. ./scripts/rpc.py bdev_malloc_create 512 4096 // Terminal B
3. ./scripts/rpc.py blobfs_create Malloc0
4. ./scripts/rpc.py blobfs_mount Malloc0 /mnt/fuse
注意:Blobstore本身提供了持久化存储服务,但是这也要求面向的Bdev对象提供持久化存储,例如NVMe Bdev,而前文rpc调用的Malloc Bdev并不能提供持久化存储,因此基于Malloc Bdev模块的Blobstore不具有持久化存储能力。
总结
本文续借前文[2]对SPDK提供的用户态存储服务Blobstore以及Blob FS进行了更为深入的探讨,对其设计细节进行了补充,并结合cache机制,分析了Blob FS所提供的I/O操作的流程,最后提供了借助FUSE插件对Blob FS进行调试分析的两种方法。
参考文献
[1]. https://spdk.io/doc/blobfs.html
[2]. 打造用户态存储利器,基于SPDK的存储引擎Blobstore & BlobFS
[3]. https://spdk.io/doc/blob.html
[4]. SPDK线程模型
[5]. https://spdk.io/doc/logical_volumes.html

转载须知
DPDK与SPDK开源社区
公众号文章转载声明
推荐阅读
Intel Scalable IOV介绍及应用实例
SPDK Delay Bdev 介绍及应用实例
支持非对称命名空间访问的SPDK多路径验证
TADK v22.03 Release


点点“赞”和“在看”,给我充点儿电吧~