深度学习炼丹术 —— 与神经网络的初次邂逅:熟悉基本结构、设计和实现
在正式介绍神经网络之前,我们先对上篇文章中的感知器内容做个简短的回顾:
我们首先介绍了什么是感知器,直观上看到了感知器的基本结构以及能做些什么。其次,通过感知器详细讲解了与门的实现原理,并通过数学公式化(梯度下降算法)来剖析了参数的训练过程,之后以代码形式实现了与门的逻辑电路,最终同理得到与非门和或门的实现结果。此外,在第二节的最后,我们还抛出了单层感知器无法解决亦或门的问题,从而为第三节提供“引子”。最后,我们发现其实可以通过逻辑电路组合的形式来实现异或门,在模型结构中,也就是以一种多层感知器来解决的亦或问题,最终通过代码来验证了模型的真实有效性。
文章的具体内容可见:深度学习炼丹术 —— Taoye不讲码德,又水文了,居然写感知器这么简单的内容: https://www.zybuluo.com/tianxingjian/note/1762894
接下来就要触及到神经网络了,神经网络大体上和上述详解的感知器差不多,只不过激活函数有所不同,上述感知器用到的激活函数是阶跃函数,而在神经网络中使用到的激活函数则需要根据实际问题来进行不同的定义。此外,在神经网络中还做了一些其他的拓展,以发挥更加强大的功能。
在本篇文章中,我们并不会用各种数学公式来进行神经网络的原理推导,也不会搬出模型的学习训练以及反向传播等算法,更不会过多的进行代码实现,这些在后面Taoye会双手奉上。
本文主要介绍的内容是神经网络的基本结构、设计和实现,让读者从整体上对其有一个比较全面的认识,主要分为以下几个部分来讲解:
- 从感知器顺利过渡到神经网络
- 激活函数的闪亮登场
- 神经网络的设计与基本实现(正向传播)
- 基于手写数字数据集实现正向传播过程
一、从感知器顺利过渡到神经网络
我们可以用下图表示一个简单的神经网络:
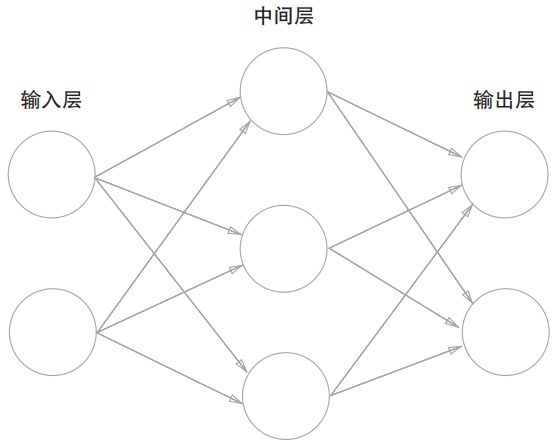
我们把最左边的一层称为输入层,主要是用于我们数据的输入,最右边的一层称之为输出层,用于神经网络的结果输出,而除了输入层和输出层,中间的所有层我们都称之为中间层,也叫作隐藏层。
注意:中间层/隐藏层有的时候可能因为实际而有多层结构,只不过在上图中只有一层。
上图神经网络中总共有三层神经元,而实际上只有两组权重参数进行处理,分别是输入层 -> 中间层、中间层 -> 输出层各有一组权重参数处理。这就好比我们想要乘坐火车从上海前往深圳,有个南昌中转站,所以途径路线为:
上 海 − > 南 昌 − > 深 圳 上海 -> 南昌 -> 深圳 上海−>南昌−>深圳
虽然说我们的地点有3个,但实际上火车的行驶过程只有两个,上面的神经网络的结构层数可同理理解。
在上篇文章中,我们有详细写到感知器的结构及处理过程,即将权重向量和样本数据的特征向量內积求和之后,将其交给一个阶跃函数处理,得到感知器的输出。该过程可用图表示如下:

其中 h ( ) h() h()表示的是激活函数,在这里具体指的是阶跃函数,即
h ( x ) = { 0 , x ≤ 0 1 , x > 0 h(x) = \begin{cases} 0, x \leq 0\\ 1, x>0\\ \end{cases} h(x)={0,x≤01,x>0
所以在这里,感知器最终的输出结果 y y y为:
y = h ( w 1 x 1 + w 2 x 2 + b ) y = h(w_1x_1 + w_2x_2 + b) y=h(w1x1+w2x2+b)
以上就是我们上篇文章中所提到的感知器,处理过程还是比较简单的。刚刚我们有提到激活函数,也就是将输入信号的总和进行特殊处理,从而转换为输出信号,起着这么一个作用的函数我们称之为激活函数(在这里这么理解就行)。
而激活函数就是从感知器过渡到神经网络之间的桥梁。
在上篇文章感知器的讲解中,使用到的激活函数是阶跃函数,而在神经网络中,则需要针对不同的实际问题而采用不同的激活函数,有的时候激活函数的选择会对神经网络模型的训练结果也会有着比较大的影响。
在神经网络中最常用的激活函数有Sigmoid、ReLU,当然还有其他以及各种变种形式。任重而道远,优质的激活函数还需要各位刮摩淬励的研究人员去发现。
下面,我们来具体看看神经网络中这些常用的激活函数。
二、激活函数的闪亮登场
Sigmoid函数是神经网络中使用比较频繁的激活函数之一,其表达形式及对应的代码图像如下:
h ( x ) = 1 1 + e − x h(x) = \frac{1}{1+e^{-x}} h(x)=1+e−x1

通过Sigmoid函数和阶跃函数的比较,我们可以发现它们主要有以下几个点的区别:
- 平滑性
比较两者的具体表达式或者图像,不难知道阶跃函数是一种分段形式,其以0为界,小于0输出0,大于0则输出1,阶跃函数的输出发生比较大的变化。
为反观Sigmoid激活函数,可以发现其是一种平滑的曲线,随着输入的改变,输出发生连续性的变换,而非像阶跃函数那种急剧态势。
- 输出值
对于阶跃函数来讲,其输出值非0即1,而Sigmoid函数的输出可以为0.1、0.21212、0.8231等实数。换句话说,阶跃函数的输出为0或1的两种信号结果(分类),而Sigmoid的输出是连续的实数值信号。
另外,对于Sigmoid来讲,其还有一个比较重要的性质就是其输出的区间在0-1之间,也就是说,无论输入Sigmoid的值是什么,都会映射至0-1中的某个值,这一点非常符合概率的性质。我们在之前讲解Logistic回归的时候就充分利用到了这一点,读者可暂且跳转至此进行了解:《Machine Learning in Action》—— Taoye给你讲讲Logistic回归是咋回事
以上简单介绍了阶跃函数和Sigmoid函数的不同点。
其实,无论是阶跃函数还是Sigmoid函数,它们都属于非线性函数。而神经网络中必须使用非线性函数才能作为激活函数,因为假如说神经网络使用线性函数作为激活函数,则就无法通过加深神经网络的层数来提高模型的表达能力了,非线性函数能为模型的输出提高更多的可能性,也能解决更多繁杂变化的问题。
上一段的内容,读者应该要重点理解。那么为什么说,神经网络中使用线性函数作为激活函数,则就无法通过加深神经网络的层数来提高模型的表达能力了呢???
因为假如说我们使用线性函数来作为激活函数的话,即使我们加深了网络的层数,我们依然能找到一个新的线性函数来代替前面多个线性函数,这就相当于的加深了网络的层数是徒劳的。比如说我们把 h ( x ) = c x h(x) = cx h(x)=cx作为激活函数,把 y ( x ) = h ( h ( h ( x ) ) ) y(x)=h(h(h(x))) y(x)=h(h(h(x)))作为三层神经网络的输出,则我们使用 y ( x ) = c 3 x y(x)=c^3x y(x)=c3x作为激活函数其实是可以替换掉前面三层神经网络的( c 3 c^3 c3依然是一个常数)
所以,使用线性函数作为激活函数的话,多层神经网络的定义也就没有意义了。
在神经网络的发展过程中,早期使用最多的激活函数就是Sigmoid了,而在ReLU激活函数出现之后,ReLU更受需求者的青睐,下面我们来看看ReLU。
ReLU的表达形式很简单,在输入小于0的时候,直接将0作为输出,在输入大于0的时候,则输出等于输入。其表达以及代码和图像如下所示:
h ( x ) = m a x ( 0 , x ) = { 0 , x ≤ 0 x , x > 0 h(x) = max(0, x)= \begin{cases} 0, x \leq 0\\ x, x>0\\ \end{cases} h(x)=max(0,x)={0,x≤0x,x>0

我们可以发现,对于ReLU激活函数来讲,其同样也是一个分段函数。并且相较于Sigmoid来讲,ReLU有两个比较明显的优势:
- 因为ReLU的表达式比较简单,所以相较于Sigmoid来讲在某种程度上效率更高
- ReLU激活函数在一定程度上能解决梯度消失的问题,而Sigmoid激活函数在实际进行反向传播的时候,很容易出现梯度消失的问题,从而导致参数几乎不再更新,所以Sigmoid不适合实现深层次神经网络的训练
对于上述两点,我们在后期会详细解释。
注意:神经网络中的激活函数可不止这两种,更多激活函数读者可自行学习了解。后期有用到其他激活函数的话,Taoye也会单独拎出来给大家安排上
三、神经网络的设计与基本实现(正向传播)
参考资料:《深度学习入门:基于Python的理论与实现》第三章内容
接着我们来详细介绍下神经网络的设计与基本实现,也就是其从输入到输出的前向处理过程。我们以下面这个三层神经网络为例:

上图中的 x 1 , x 2 x_1,x_2 x1,x2分别表示的是单个样本的两个不同属性特征, y 1 , y 2 y_1,y_2 y1,y2表示的是经过神经网络处理过后的两个最终输出。
上图中的每一个圆圈我们都可以看做一个神经元,或是说是一个节点。而中间的神经元/节点只是用作从输入节点得到输出节点的中间桥梁,且中间节点是通过前一层的神经元和权值参数计算得到的,我们以从输入层到第一层的神经元的信号传递为例,来详解下这个过程。

为了方便将偏执 b b b统一到神经元信号的传递过程中,我们额外引入一个输入节点/神经元,其值恒为1。
另外,还有一点需要值得注意的是,上一层和下一层的神经元两两之间都是通过一个 w w w权重参数紧密相连的,这就是一种笛卡尔积的形式相连。(关于笛卡尔积,有过Mysql基础的读者应该连接,可以理解成一种全连接)
为此,我们可以得到第一层中第一个神经元的运算结果 a 1 ( 1 ) a_1^{(1)} a1(1)的值:
a 1 ( 1 ) = x 1 w 11 ( 1 ) + x 2 w 12 ( 1 ) + b 1 ( 1 ) a_1^{(1)}=x_1w_{11}^{(1)}+x_2w_{12}^{(1)}+b_1^{(1)} a1(1)=x1w11(1)+x2w12(1)+b1(1)
同理,我们可以得到第一层神经元中 a 2 ( 1 ) , a 3 ( 1 ) a_2^{(1)},a_3^{(1)} a2(1),a3(1)的具体结果:
a 2 ( 1 ) = x 1 w 21 ( 1 ) + x 2 w 22 ( 1 ) + b 2 ( 1 ) a 3 ( 1 ) = x 1 w 31 ( 1 ) + x 2 w 32 ( 1 ) + b 3 ( 1 ) \begin{aligned} & a_2^{(1)}=x_1w_{21}^{(1)}+x_2w_{22}^{(1)}+b_2^{(1)} \\ & a_3^{(1)}=x_1w_{31}^{(1)}+x_2w_{32}^{(1)}+b_3^{(1)} \\ \end{aligned} a2(1)=x1w21(1)+x2w22(1)+b2(1)a3(1)=x1w31(1)+x2w32(1)+b3(1)
以上就是输入节点通过一次参数处理之后得到的结果,为了方便数学表示以及后期代码的实现,我们一般是通过矩阵以及向量的形式来表示上述过程,假如我们把第一层神经元输出的结果 a 1 ( 1 ) , a 2 ( 1 ) , a 3 ( 1 ) a_1^{(1)},a_2^{(1)},a_3^{(1)} a1(1),a2(1),a3(1)看做是一个向量,则我们可以通过如下方式表示:
( a 1 ( 1 ) a 2 ( 1 ) a 3 ( 1 ) ) = ( x 1 w 11 ( 1 ) + x 2 w 12 ( 1 ) + b 1 ( 1 ) x 1 w 21 ( 1 ) + x 2 w 22 ( 1 ) + b 2 ( 1 ) x 1 w 31 ( 1 ) + x 2 w 32 ( 1 ) + b 3 ( 1 ) ) = ( w 11 ( 1 ) w 12 ( 1 ) w 21 ( 1 ) w 22 ( 1 ) w 31 ( 1 ) w 32 ( 1 ) ) ( x 1 x 2 ) + ( b 1 ( 1 ) b 2 ( 1 ) b 3 ( 1 ) ) \begin{aligned} \left( \begin{matrix} a_1^{(1)}\\ a_2^{(1)}\\ a_3^{(1)}\\ \end{matrix} \right) & = \left( \begin{matrix} x_1w_{11}^{(1)}+x_2w_{12}^{(1)}+b_1^{(1)}\\ x_1w_{21}^{(1)}+x_2w_{22}^{(1)}+b_2^{(1)}\\ x_1w_{31}^{(1)}+x_2w_{32}^{(1)}+b_3^{(1)}\\ \end{matrix} \right) \\ & = \left( \begin{matrix} w_{11}^{(1)} & w_{12}^{(1)}\\ w_{21}^{(1)} & w_{22}^{(1)}\\ w_{31}^{(1)} & w_{32}^{(1)}\\ \end{matrix} \right) \left( \begin{matrix} x_1\\ x_2\\ \end{matrix} \right) + \left( \begin{matrix} b_1^{(1)}\\ b_2^{(1)}\\ b_3^{(1)}\\ \end{matrix} \right) \end{aligned} ⎝⎜⎛a1(1)a2(1)a3(1)⎠⎟⎞=⎝⎜⎛x1w11(1)+x2w12(1)+b1(1)x1w21(1)+x2w22(1)+b2(1)x1w31(1)+x2w32(1)+b3(1)⎠⎟⎞=⎝⎜⎛w11(1)w21(1)w31(1)w12(1)w22(1)w32(1)⎠⎟⎞(x1x2)+⎝⎜⎛b1(1)b2(1)b3(1)⎠⎟⎞
我们不妨对上述的向量和矩阵进行具体值的定义,然后来模拟上述的运算过程:
假 设 : ( x 1 , x 2 ) T = ( 0.6 , − 0.8 ) T ( w 11 ( 1 ) w 12 ( 1 ) w 21 ( 1 ) w 22 ( 1 ) w 31 ( 1 ) w 32 ( 1 ) ) = ( 0.05 1.6 0.3 − 0.7 0.8 − 1.2 ) ( b 1 ( 1 ) , b 2 ( 1 ) , b 3 ( 1 ) ) T = ( 0.05 , − 0.6 , 1.3 ) T \begin{aligned} & 假设:\\ & (x_1,x_2)^T=(0.6,-0.8)^T\\ & \left( \begin{matrix} w_{11}^{(1)} & w_{12}^{(1)}\\ w_{21}^{(1)} & w_{22}^{(1)}\\ w_{31}^{(1)} & w_{32}^{(1)}\\ \end{matrix} \right)=\left( \begin{matrix} 0.05 & 1.6\\ 0.3 & -0.7\\ 0.8 & -1.2\\ \end{matrix} \right) \\ & (b_1^{(1)},b_2^{(1)},b_3^{(1)})^T=(0.05, -0.6, 1.3)^T \end{aligned} 假设:(x1,x2)T=(0.6,−0.8)T⎝⎜⎛w11(1)w21(1)w31(1)w12(1)w22(1)w32(1)⎠⎟⎞=⎝⎛0.050.30.81.6−0.7−1.2⎠⎞(b1(1),b2(1),b3(1))T=(0.05,−0.6,1.3)T
则我们可以通过上述运算得到 ( a 1 ( 1 ) , a 3 ( 1 ) , a 3 ( 1 ) ) T (a_1^{(1)},a_3^{(1)},a_3^{(1)})^T (a1(1),a3(1),a3(1))T的值**(上述的具体值为随意定义,只为模拟前向传播的过程,不代表任何意义)**:
( a 1 ( 1 ) a 2 ( 1 ) a 3 ( 1 ) ) = ( 0.05 1.6 0.3 − 0.7 0.8 − 1.2 ) ( 0.6 − 0.8 ) + ( 0.05 − 0.6 1.3 ) = ( − 1.2 , 0.14 , 2.74 ) T \begin{aligned} \left( \begin{matrix} a_1^{(1)}\\ a_2^{(1)}\\ a_3^{(1)}\\ \end{matrix} \right) & = \left( \begin{matrix} 0.05 & 1.6\\ 0.3 & -0.7\\ 0.8 & -1.2\\ \end{matrix} \right) \left( \begin{matrix} 0.6\\ -0.8\\ \end{matrix} \right) + \left( \begin{matrix} 0.05\\ -0.6\\ 1.3\\ \end{matrix} \right) \\ & = (-1.2, 0.14, 2.74)^T \end{aligned} ⎝⎜⎛a1(1)a2(1)a3(1)⎠⎟⎞=⎝⎛0.050.30.81.6−0.7−1.2⎠⎞(0.6−0.8)+⎝⎛0.05−0.61.3⎠⎞=(−1.2,0.14,2.74)T
至此,我们已经完成了第一个隐藏层加权和(wx+b)的计算。前面我们也有提到,在神经网络中,为了提高模型的表达能力,我们在进行一次隐藏层的计算之后,往往会通过激活函数对计算结果进行处理。这里我们的激活函数不妨选用Sigmoid函数,设对 ( a 1 ( 1 ) , a 2 ( 1 ) , a 3 ( 1 ) ) (a_1^{(1)},a_2^{(1)},a_3^{(1)}) (a1(1),a2(1),a3(1))进行激活处理之后的结果为 ( z 1 ( 1 ) , z 2 ( 1 ) , z 3 ( 1 ) ) (z_1^{(1)},z_2^{(1)},z_3^{(1)}) (z1(1),z2(1),z3(1)),即:
( z 1 ( 1 ) , z 2 ( 1 ) , z 3 ( 1 ) ) T = S i g m o i d ( ( a 1 ( 1 ) , a 2 ( 1 ) , a 3 ( 1 ) ) T ) = ( S i g m o i d ( a 1 ( 1 ) ) , S i g m o i d ( a 2 ( 1 ) ) , S i g m o i d ( a 3 ( 1 ) ) ) T = ( 0.2315 , 0.5349 , 0.9393 ) T \begin{aligned} (z_1^{(1)},z_2^{(1)},z_3^{(1)})^T & = Sigmoid((a_1^{(1)},a_2^{(1)},a_3^{(1)})^T) \\ & = (Sigmoid(a_1^{(1)}),Sigmoid(a_2^{(1)}),Sigmoid(a_3^{(1)}))^T \\ & = (0.2315, 0.5349, 0.9393)^T \end{aligned} (z1(1),z2(1),z3(1))T=Sigmoid((a1(1),a2(1),a3(1))T)=(Sigmoid(a1(1)),Sigmoid(a2(1)),Sigmoid(a3(1)))T=(0.2315,0.5349,0.9393)T
我们可以同样可以通过代码来完成上述过程的运算(NumPy的操作):

以上就是从输入层到第一个隐藏层中处理的全部过程,整体上来讲还是非常简单的,无非就是加权和之后通过激活函数处理并将结果信号传递给下一层,我们也可以发现通过激活之后的结果范围在0-1之间。
整体过程是挺简单的,最重要的还是要弄清楚输入、输出以及w权重参数和b偏执参数的shape值,这一点还是挺重要的。权重参数w的shape主要取决于输入和输出,因为它们进行的是笛卡尔积形式的运算,是彼此紧密连接的,假如输入是m,输出是n,则w的shape值为(m,n),这一点可以通过矩阵的运算去理解**(不要去死记硬背,最重要的是能够理解)。另外b权值参数个数则主要取决于输出,因为每一个输出都对应一个偏执,所以偏执个数与输出保持一致(重在理解)**
输入层到第一个隐藏层的信号传递过程如下左图:

如上右图,同样的,我们将信号从第一个隐藏层传递到第二个隐藏层类似如上过程,改变的仅仅是数据,而内部的细节处理完全是一模一样的,即通过 w ( 2 ) 、 b ( 2 ) w^{(2)}、b^{(2)} w(2)、b(2)参数对 z ( 1 ) z^{(1)} z(1)进行处理可见下:
( a 1 ( 2 ) a 2 ( 2 ) ) = ( z 1 ( 1 ) w 11 ( 2 ) + z 2 ( 1 ) w 12 ( 2 ) + z 3 ( 1 ) w 13 ( 2 ) + b 1 ( 2 ) z 1 ( 1 ) w 21 ( 2 ) + z 2 ( 1 ) w 22 ( 2 ) + z 3 ( 1 ) w 23 ( 2 ) + b 2 ( 2 ) ) = ( w 11 ( 2 ) w 12 ( 2 ) w 13 ( 2 ) w 21 ( 2 ) w 22 ( 2 ) w 23 ( 2 ) ) ( z 1 ( 1 ) z 2 ( 1 ) z 3 ( 1 ) ) + ( b 1 ( 2 ) b 2 ( 2 ) ) \begin{aligned} \left( \begin{matrix} a_1^{(2)}\\ a_2^{(2)}\\ \end{matrix} \right) & = \left( \begin{matrix} z_1^{(1)}w_{11}^{(2)}+z_2^{(1)}w_{12}^{(2)}+z_3^{(1)}w_{13}^{(2)}+b_1^{(2)}\\ z_1^{(1)}w_{21}^{(2)}+z_2^{(1)}w_{22}^{(2)}+z_3^{(1)}w_{23}^{(2)}+b_2^{(2)}\\ \end{matrix} \right) \\ & = \left( \begin{matrix} w_{11}^{(2)} & w_{12}^{(2)} & w_{13}^{(2)} \\ w_{21}^{(2)} & w_{22}^{(2)} & w_{23}^{(2)}\\ \end{matrix} \right) \left( \begin{matrix} z_1^{(1)}\\ z_2^{(1)}\\ z_3^{(1)}\\ \end{matrix} \right) + \left( \begin{matrix} b_1^{(2)}\\ b_2^{(2)}\\ \end{matrix} \right) \end{aligned} (a1(2)a2(2))=(z1(1)w11(2)+z2(1)w12(2)+z3(1)w13(2)+b1(2)z1(1)w21(2)+z2(1)w22(2)+z3(1)w23(2)+b2(2))=(w11(2)w21(2)w12(2)w22(2)w13(2)w23(2))⎝⎜⎛z1(1)z2(1)z3(1)⎠⎟⎞+(b1(2)b2(2))
( z 1 ( 2 ) , z 2 ( 2 ) ) = S i g m o i d ( ( a 1 ( 2 ) , a 2 ( 2 ) ) T ) = ( S i g m o i d ( a 1 ( 2 ) ) , S i g m o i d ( a 2 ( 2 ) ) ) T \begin{aligned} (z_1^{(2)},z_2^{(2)}) & = Sigmoid((a_1^{(2)},a_2^{(2)})^T) \\ & = (Sigmoid(a_1^{(2)}),Sigmoid(a_2^{(2)}))^T \\ \end{aligned} (z1(2),z2(2))=Sigmoid((a1(2),a2(2))T)=(Sigmoid(a1(2)),Sigmoid(a2(2)))T
OK,第二层的处理也已经完成了,可以发现前两次的处理几乎完全一样。接下来就是最后一层的处理了,也就是第二隐藏层到最后神经网络最终结果输出的信号传递过程。在这个过程里面,一般与前面隐藏层的处理不大一样,需要根据我们的实际问题来进行定义。
一般地,对于回归问题,我们可以借用恒等函数,二元分类问题可以使用Sigmoid函数,而多元分类问题则可以采用softmax函数进行处理。
在这里,我们不妨通过恒等函数来完成最后一层的信号传递。所谓的“恒等函数”就是讲输入不进行任何处理,然后对其进行直接输出。
以上就是该三层全连接神经网络的前向传播的完整过程,接下来,我们可以通过代码的形式来实现该前向传播的过程。注意:这里不涉及参数的训练,仅仅让读者对神经网络的前向传播有个比较熟悉的了解。
首先,我们先定义一下激活函数,通过如上三层神经网络的处理过程,我们可以知道涉及到了两种激活函数,第一层和第二层的处理使用到了Sigmoid,而第三层则使用到了恒等函数,该两种激活函数的定义如下:

随后,我们需要定义一个forward方法来实现一层中信号的处理,主要涉及到了NumPy的操作内容,通过NumPy来实现矩阵的运算,关于NumPy,之前Taoye也是整理过一篇文章来详细介绍的,需要充电的读者可暂且跳转至:啊!这样玩NumPy,真香!,该forward的定义如下:

由于我们该部分内容旨在给读者详细介绍神经网络前向传播的过程,不涉及参数的训练过程(留在下篇文章肝),所以我们需要额外手动定义各层所需要处理的参数,我们用initial_params方法来完成这个功能,最后完成该三层神经网络的信号前向传播过程:

上述过程的完整代码如下:
import numpy as np
def sigmoid(in_data):
return 1 / (1 + np.exp(-in_data))
def identity(in_data):
return in_data
"""
Explain:实现单层前向传播的过程
Parameters:
x_data:上一层的神经元数据
w_data:w权值矩阵参数
b_data:b偏置参数
"""
def forward(x_data, w_data, b_data):
return np.matmul(w_data, x_data) + b_data
"""
Explain:权重参数w和偏置参数b的手动定义
"""
def initial_params():
w_1 = np.array([[0.05, 1.6], [0.3, -0.7], [0.8, -1.2]])
b_1 = np.array([[0.05], [-0.6], [1.3]])
w_2 = np.array([[0.15, 0.65, -0.3], [-1.4, 0.38, 0.53]])
b_2 = np.array([[-1.3], [0.72]])
return w_1, b_1, w_2, b_2
if __name__ == "__main__":
x_data = np.array([[0.6], [-0.8]]) # 初始输入信号的定义,也就是我们的样本数据
w_1, b_1, w_2, b_2 = initial_params() # 获取权重参数w和偏置参数b
a_1 = forward(x_data, w_1, b_1) # 从输入层到第一个隐藏层的信号传递
z_1 = sigmoid(a_1) # 第一次sigmoid激活
a_2 = forward(z_1, w_2, b_2) # 从第一个隐藏层到第二个隐藏层的信号传递
z_2 = sigmoid(a_2) # 第二次sigmoid激活
y = identity(z_2) # 恒等函数进行结果输出的处理
print(a_1.T, z_1.T) # 第一个隐藏层的输出结果
print(a_2.T, z_2.T) # 第二个隐藏层的输出结果
print(y.T) # 该三层神经网络的最终输出
四、基于手写数字数据集实现正向传播过程
关于手写数字识别,我们之前在讲解KNN的时候详细讲解过其算法原理,具体内容可跳转:《Machine Learning in Action》—— 女同学问Taoye,KNN应该怎么玩才能通关
而在神经网络当中,要想进行手写数字识别,则需要训练模型的w参数和b参数,关于模型的训练过程,我们留在后面的文章来进行讲解,本节只是模拟神经网络在手写数字识别的前向传播过程,也就是说假如我们已经获得了w和b参数,要如何通过神经网络计算出模型的结果。
在上节中,我们已经通过小的案例来模拟了前向传播。有一点需要注意的是,上节针对的是单个样本的信号传递过程,而在实际问题中,我们往往是多个样本进行批次处理,比如说这次的手写数字识别。另外,我们发现对于上述的神经网络来讲,每个样本的输入都应该是一个向量的形似,而手写数字的shape=(28, 28),相当于一个矩阵的输入,对此我们还需要对其进行flatten拉直才能作为输入信号,处理意图和KNN当中一致。
下面我们具体来看看这个过程。
首先是手写数字数据的导入,这里我们通过tensorflow.keras.datasets.mnist.load_data()来进行数据的加载。注意:我们这里使用到的Tensorflow仅仅用作数据的导入,而非使用其内部接口来完成整个手写数字的前向传播过程。

我们可以知道,对于一张手写数字图片来讲,将其flatten拉直之后的shape为784,即每张手写数字有784个属性特征。所以,对于单个手写数字数据来讲,输入信号的个数为784,而我们知道每张数字图片对应0-9中的一个标签,所以其输出信号的个数为10。
以上是输入信号和输出信号个数的确定,接下来我们来考虑下隐藏层的设计。
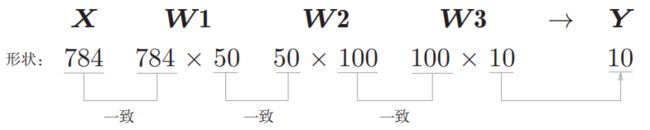
对于隐藏层,我们通常是通过自身的经验以及多次数的尝试来确定其参数数目(参数矩阵的维度以及神经网络的层数)。在这里我们不妨定义两个隐藏层来处理,第一个隐藏层中神经元的个数为50,第二个隐藏层中神经元的个数定义为100。如此一来,处理第一个隐藏层的参数信息为 w _ 1. s h a p e = ( 784 , 50 ) , b _ 1. s h a p e = ( 50 ) w\_1.shape=(784, 50),b\_1.shape=(50) w_1.shape=(784,50),b_1.shape=(50),处理第二个隐藏层的参数信息为 w _ 2. s h a p e = ( 50 , 100 ) , b _ 2. s h a p e = ( 100 ) w\_2.shape=(50, 100),b\_2.shape=(100) w_2.shape=(50,100),b_2.shape=(100),而第二个隐藏层到最终输出层的参数信息为 w _ 3. s h a p e = ( 100 , 10 ) , b _ 3. s h a p e = ( 10 ) w\_3.shape=(100, 10),b\_3.shape=(10) w_3.shape=(100,10),b_3.shape=(10)。该神经网络的参数信息总结如下:
w _ 1. s h a p e = ( 784 , 50 ) , b _ 1. s h a p e = ( 50 , ) w _ 2. s h a p e = ( 50 , 100 ) , b _ 2. s h a p e = ( 100 , ) w _ 3. s h a p e = ( 100 , 10 ) , b _ 3. s h a p e = ( 10 , ) \begin{aligned} & w\_1.shape=(784, 50),b\_1.shape=(50,) \\ & w\_2.shape=(50, 100),b\_2.shape=(100,) \\ & w\_3.shape=(100, 10),b\_3.shape=(10,) \end{aligned} w_1.shape=(784,50),b_1.shape=(50,)w_2.shape=(50,100),b_2.shape=(100,)w_3.shape=(100,10),b_3.shape=(10,)
对应的数组shape变换:
神经网络的前向传播的处理过程基本与第三节讲到的一致,前两次向隐藏层传递信号都是进行加权和(wx+b)的计算,然后通过Sigmoid激活函数进行处理。有一点需要区别的是在第二个隐藏层到最终结果输出的时候,这里我们可以采用Softmax进行处理,而非恒等函数。因为我们这里的输出有十种可能性,其是一个10分类的问题,我们可以通过Softmax来将结果转化为概率的形式,并且概率最大所对应的索引可以将其作为模型的最终输出结果。
Softmax的具体表达如下:
y k = e a k ∑ i = 1 n e a i y_k = \frac{e^{a_k}}{\sum_{i=1}^ne^{a_i}} yk=∑i=1neaieak
使用Softmax的确能够将结果转化为概率的形式,以到达一个分类的目的。但是我们在计算的过程中,数值过大并且再进行次方,有可能造成内存溢出问题。对此我们可以对Softmax进行如下优化处理:

我们可以将上述的 C ′ C^{'} C′替换为 m a x ( a 1 , a 2 , . . . , a n ) max(a_1,a_2,...,a_n) max(a1,a2,...,an),为此定义softmax方法实现最后一层的结果输出:

我们知道,单个样本经过softmax处理过后的数据表示的是一个概率向量,内部的每个元素的值都代表一个数字的预测概率,而我们如果需要得到最大概率所对应的数字,我们可以使用np.argmax(),如下:
np.argmax(y, axis = 1)
为此,我们来看看完整代码的正向传播操作能否正常运行:

我们可以发现,手写数字的前向传播已经能够正常实现,并且最终得到了每个数据样本的预测结果。由于我们这里只是对模拟手写数字识别的前向传播过程,不涉及模型的真实训练与预测,所以参数的训练以及结果精度等内容就不在这里介绍了。该部分的完整代码如下所示:
from tensorflow import keras
from matplotlib import pyplot as plt
def establish_data():
# 加载手写数字数据集
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
# 我们只是模拟前向传播的过程,所以选取前100个样本,然后将它们进行flatten拉直
x_data = x_train[:100].flatten().reshape([100, -1])
return x_data / 255
def sigmoid(in_data):
return 1 / (1 + np.exp(-in_data))
def identity(in_data):
return in_data
def softmax(in_data):
in_data = in_data - np.tile(in_data.max(axis = 1).reshape([in_data.shape[0], 1]), [1, in_data.shape[1]])
exp_data = np.exp(in_data)
exp_sum_data = np.tile(exp_data.sum(axis = 1).reshape([in_data.shape[0], 1]), [1, in_data.shape[1]])
return exp_data / exp_sum_data
"""
Explain:实现单层前向传播的过程
Parameters:
x_data:上一层的神经元数据
w_data:w权值矩阵参数
b_data:b偏置参数
"""
def forward(x_data, w_data, b_data):
return np.matmul(x_data, w_data) + b_data
"""
Explain:权重参数w和偏置参数b的手动定义
"""
def initial_params():
w_1 = np.random.randn(784, 50)
b_1 = np.random.rand(50)
w_2 = np.random.randn(50, 100)
b_2 = np.random.rand(100)
w_3 = np.random.randn(100, 10)
b_3 = np.random.rand(10)
return w_1, b_1, w_2, b_2, w_3, b_3
if __name__ == "__main__":
x_data = establish_data()
w_1, b_1, w_2, b_2, w_3, b_3 = initial_params()
a_1 = forward(x_data, w_1, b_1)
z_1 = sigmoid(a_1)
a_2 = forward(a_1, w_2, b_2)
z_2 = sigmoid(a_2)
a_3 = forward(z_2, w_3, b_3)
y = softmax(a_3)
print(np.argmax(y, axis = 1))
本篇文章就暂时写到这了,内容写的虽然多,但实际其实并没有多少,这么做主要是为了让读者把神经网络的前向传播过程搞明白。关于神经网络的前向传播,重要的是要弄明白信号传递过程中shape值的变换以及参数的数量多少,还有一点就是我们最终输出层的设计应当如何实现。明白了这些内容,前向传播也就理解的差不多到位了,本篇文章的价值也就有了,后面我们再来详细介绍神经网络的学习过程。
我是Taoye,爱专研,爱分享,热衷于各种技术,学习之余喜欢下象棋、听音乐、聊动漫,希望借此一亩三分地记录自己的成长过程以及生活点滴,也希望能结实更多志同道合的圈内朋友,更多内容欢迎来访微信公主号:玩世不恭的Coder。
我们下期再见,拜拜~~~

参考资料:
[1] 《深度学习入门:基于Python的理论与实现》:斋藤康毅 人民邮电出版社
推荐阅读
深度学习炼丹术 —— Taoye不讲码德,又水文了,居然写感知器这么简单的内容
《Machine Learning in Action》—— Taoye给你讲讲Logistic回归是咋回事
《Machine Learning in Action》—— 浅谈线性回归的那些事
《Machine Learning in Action》—— 白话贝叶斯,“恰瓜群众”应该恰好瓜还是恰坏瓜
《Machine Learning in Action》—— 女同学问Taoye,KNN应该怎么玩才能通关
《Machine Learning in Action》—— 懂的都懂,不懂的也能懂。非线性支持向量机
《Machine Learning in Action》—— hao朋友,快来玩啊,决策树呦
《Machine Learning in Action》—— Taoye给你讲讲决策树到底是支什么“鬼”
《Machine Learning in Action》—— 剖析支持向量机,优化SMO
《Machine Learning in Action》—— 剖析支持向量机,单手狂撕线性SVM
手撕机器学习系列文章暂时停止更新了,目前已经完成了支持向量机SVM、决策树、KNN、贝叶斯、线性回归、Logistic回归,其他算法还请允许Taoye在这里先赊个账,后期有机会有时间再给大家补上。
该系列文章的全部内容都是Taoye纯手打,也是参考了不少书籍以及公开资源,系列总字数在15W左右(含源码),总页数为138,后期会再慢慢填补。为了提高大家的阅读体验,手撕机器学习系列文章Taoye已经整理成PDF和和HTML,阅读效果都很不错,在公众号【玩世不恭的Coder】下回复【666】即可免费获取,相信大家看完后一定会有所收获。文档可以随意传播,但注意不可修改其中的内容。


