医学报告生成论文阅读笔记
1.Transformers in Medical Imaging: A Survey
综述了Transformers在医学图像分割、检测、分类、重建、合成、配准、临床报告生成和其他任务中的应用。
Shamshad F, Khan S, Zamir S W, et al. Transformers in Medical Imaging: A Survey[J]. arXiv preprint arXiv:2201.09873, 2022. [源码]
2.Methods for automatic generation of radiological reports of chest radiographs: a comprehensive survey
Kaur N, Mittal A, Singh G. Methods for automatic generation of radiological reports of chest radiographs: a comprehensive survey[J]. Multimedia Tools and Applications, 2021: 1-31.
基于编码器-解码器框架的ARRG系统使用编码器从输入图像中提取特征,使用解码器生成与提取的特征对应的语言描述。使用了[编码器]-[解码器]的不同组合,例如[CNN]-[RNN]、[CNN]-[HRNN]、[CNN]-[HRNN带双字LSTM]和[CNN带GLP机制]-[HRNN带主题匹配机制]。基于编码器解码器框架的ARRG系统考虑整个图像以生成输入图像中出现的异常的句子。然而,基于注意机制的ARRG系统关注图像的一部分来生成下一个单词。还指出,同时考虑生成报告的视觉和语义特性可以提高系统的性能。这两类ARRG系统都关注生成句子的可读性,而不是它们的临床相关性。基于强化学习的ARRG系统使用奖励生成具有最大临床相关性的报告。据观察,基于临床疗效和语言质量加强模型比单独考虑提供更好的结果。然而,生成的报告有反复出现的句子。基于图的ARRG系统解决了这个问题。在基于图形的ARRG系统中,人们注意到,在生成报告时,语言模型优于RNN;具体来说,预先训练的语言模型可以提供更好的结果。
3.Diagnostic captioning: a survey
Pavlopoulos J, Kougia V, Androutsopoulos I, et al. Diagnostic captioning: a survey[J]. arXiv preprint arXiv:2101.07299, 2021.
我们提供了诊断字幕(DC)方法、公开数据集和评估措施的广泛概述。
就方法而言,目前大多数DC工作使用编码器-解码器深度学习方法,这主要是因为它们在通用(非医学)图像字幕方面取得了成功。然而,我们已经指出,DC的目标是只报告有助于医疗诊断的信息。如果显示的突出物体(例如身体器官)没有临床上重要的报告,则无需提及,这与一般图像字幕不同,其中突出物体(以及发生的动作)通常必须报告。与普通图像字幕的另一个主要区别是,医学图像的差异小得多,因此,不同患者的相应诊断文本通常非常相似,甚至完全相同。这两个因素使得基于检索的方法在DC中表现得出奇地好,这些方法可以重用来自具有相似图像的训练示例的诊断文本。也可以使用常用句子或句子模板,而不是生成它们。
出于评估目的,DC工作迄今主要依赖于源自机器翻译和摘要的单词重叠度量,而机器翻译和摘要通常无法捕捉临床正确性,正如我们也使用人工示例所证明的那样。还采用了比较标签(也被视为标签或类别,对应于医学术语或概念)的措施,这些标签是手动提取的,或者更常见的是,从系统生成的和人类编写的诊断报告中自动提取的,作为更好地捕捉临床正确性的手段。然而,当自动提取标签的工具不准确,当人类注释指南不清楚应该分配或不分配哪些标签,以及当标签不能完全捕获诊断文本中要包含的信息时,它们也可能失败。人工评估在DC很少见,可能是因为雇佣具有足够医学专业知识的评估人员的难度和成本。
在数据集方面,我们专注于仅有的两个真正代表该任务的公共可用数据集(IU X-RAY、MIMIC-CXR),首先讨论了其他公共可用数据集的严重缺陷(例如,它们可能不包含真实检查的医学图像)。我们还收集并报告了之前发表的所有DC数据集、方法和评估指标的评估结果。尽管由于使用的数据集或分割不同,这些结果通常无法直接进行比较,但它们提供了不同类型DC方法执行情况的总体指示。我们收集的结果也可能帮助其他研究人员得出与之前报道的结果更直接可比的结果。
我们认为,将从头生成诊断文本的编码器-解码器方法与基于检索的方法相结合的混合方法,即重用过去类似案例中的文本的方法,更有可能成功。
4.Deep learning in generating radiology reports: A survey
Monshi M M A, Poon J, Chung V. Deep learning in generating radiology reports: A survey[J]. Artificial Intelligence in Medicine, 2020, 106: 101878.

针对CNN+RNN结构报告生成进行综述。
5.A survey on deep learning and explainability for automatic image-based medical report generation
Messina P, Pino P, Parra D, et al. A survey on deep learning and explainability for automatic image-based medical report generation[J]. arXiv preprint arXiv:2010.10563, 2020.
6.Improving factual completeness and consistency of image-to-text radiology report generation
Miura Y, Zhang Y, Tsai E B, et al. Improving factual completeness and consistency of image-to-text radiology report generation[J]. arXiv preprint arXiv:2010.10042, 2020. [源码]
7.Hierarchical x-ray report generation via pathology tags and multi head attention
Srinivasan P, Thapar D, Bhavsar A, et al. Hierarchical x-ray report generation via pathology tags and multi head attention[C]//Proceedings of the Asian Conference on Computer Vision. 2020. [源码]
1.采用分治方法。首先,从正常患者中识别出异常患者,并生成其MTI标签嵌入。然后根据标签进行条件学习。2.为了预测报告使用一种包含两个编码器和两个解码器的Transformer。3.标签嵌入和图像特征分别使用两个编码器编码。报告的findings和impressions通过两个堆叠的解码器学习,帮助前者改进后的生成。

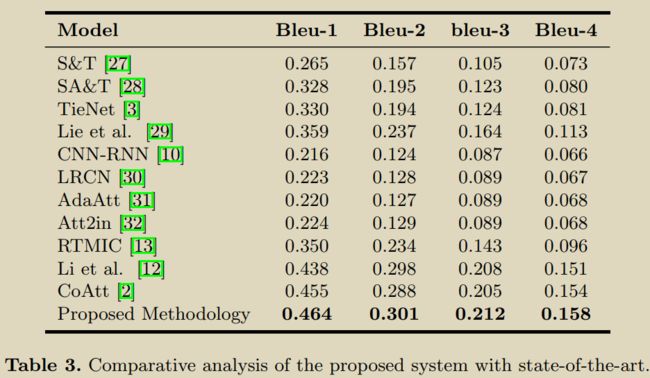
8.Exploring and distilling posterior and prior knowledge for radiology report generation
Liu F, Wu X, Ge S, et al. Exploring and distilling posterior and prior knowledge for radiology report generation[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 13753-13762.
模拟医生先确定异常区域和疾病类型,再利用先验知识进行报告书写的过程。分为: Posterior KnowledgeExplorer (PoKE), Prior Knowledge Explorer (PrKE) 和
Multi-domain Knowledge Distiller (MKD)。PoKE探索了后验知识,提供了显式的异常视觉区域来缓解视觉数据偏倚;PrKE从先前的医学知识图谱中(医学知识)和检索先前的放射学报告(工作经验)中探索先前的知识,以减轻文本数据的偏见。探索的知识被MKD提炼出来生成最终的报告。
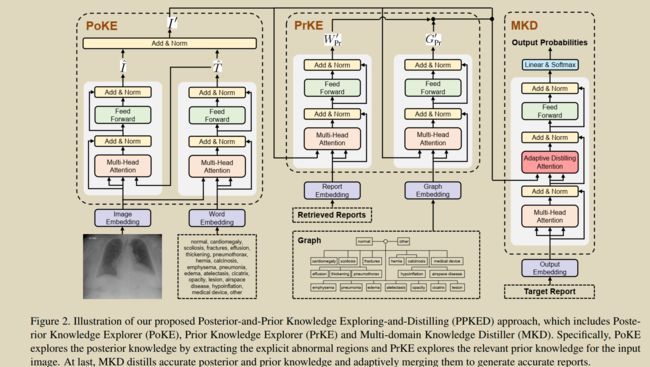

a. P o K E : { I , T } → I ′ PoKE : \{I, T\} \rightarrow I^{\prime} PoKE:{I,T}→I′;
其中: T ^ = FFN ( MHA ( I , T ) ) ; I ^ = FFN ( MHA ( T ^ , I ) ) \hat{T}=\operatorname{FFN}(\operatorname{MHA}(I, T)) ; \hat{I}=\operatorname{FFN}(\operatorname{MHA}(\hat{T}, I)) T^=FFN(MHA(I,T));I^=FFN(MHA(T^,I))
I I I:输入图像 T T T:固定的异常病变(20种)词袋
b. PrKE : { I ′ , W P r } → W P r ′ ; { I ′ , G P r } → G P r ′ \operatorname{PrKE}:\left\{I^{\prime}, W_{\mathrm{Pr}}\right\} \rightarrow W_{\mathrm{Pr}}^{\prime} ; \quad\left\{I^{\prime}, G_{\mathrm{Pr}}\right\} \rightarrow G_{\mathrm{Pr}}^{\prime} PrKE:{I′,WPr}→WPr′;{I′,GPr}→GPr′
其中: W Pr ′ W_{\operatorname{Pr}}^{\prime} WPr′and G Pr ′ G_{\operatorname{Pr}}^{\prime} GPr′ which represent the prior knowledge relating to the abnormal regions of the input image .prior knowledge from existing radiology
report corpus and represent them as W Pr W_{\operatorname{Pr}} WPrand G Pr G_{\operatorname{Pr}} GPrrespectively
c. W P r ′ = F F N ( MHA ( I ′ , W P r ) ) G P r ′ = F F N ( MHA ( I ′ , G P r ) ) \begin{aligned} W_{\mathrm{Pr}}^{\prime} &=\mathrm{FFN}\left(\operatorname{MHA}\left(I^{\prime}, W_{\mathrm{Pr}}\right)\right) \\ G_{\mathrm{Pr}}^{\prime} &=\mathrm{FFN}\left(\operatorname{MHA}\left(I^{\prime}, G_{\mathrm{Pr}}\right)\right) \end{aligned} WPr′GPr′=FFN(MHA(I′,WPr))=FFN(MHA(I′,GPr))
d.MKD : { I ′ , W P r ′ , G P r ′ } → R \left\{I^{\prime}, W_{\mathrm{Pr}}^{\prime}, G_{\mathrm{Pr}}^{\prime}\right\} \rightarrow R {I′,WPr′,GPr′}→R.
e.Adaptive Distilling Attention (ADA)
ADA ( h t , I ′ , G P r ′ , W P r ′ ) = MHA ( h t , I ′ + λ 1 G P r ′ + λ 2 W P r ′ ) \operatorname{ADA}\left(h_{t}, I^{\prime}, G_{\mathrm{Pr}}^{\prime}, W_{\mathrm{Pr}}^{\prime}\right)=\operatorname{MHA}\left(h_{t}, I^{\prime}+\lambda_{1} G_{\mathrm{Pr}}^{\prime}+\lambda_{2} W_{\mathrm{Pr}}^{\prime}\right) ADA(ht,I′,GPr′,WPr′)=MHA(ht,I′+λ1GPr′+λ2WPr′)
λ 1 , λ 2 = σ ( h t W h ⊕ ( I ′ W I + G P r ′ W G + W P r ′ W W ) ) \lambda_{1}, \lambda_{2}=\sigma\left(h_{t} \mathrm{~W}_{h} \oplus\left(I^{\prime} \mathrm{W}_{I}+G_{\mathrm{Pr}}^{\prime} \mathrm{W}_{G}+W_{\mathrm{Pr}}^{\prime} \mathrm{W}_{W}\right)\right) λ1,λ2=σ(ht Wh⊕(I′WI+GPr′WG+WPr′WW))
优势:充分利用先验和后验
缺点:所有数据均来自样本数据集IU-Xray、MIMIC-CXR
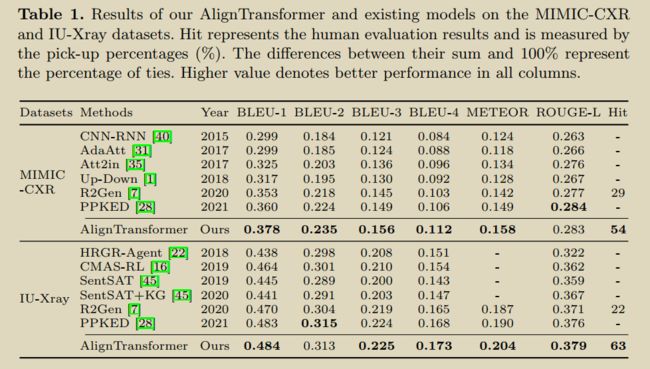
9.Aligntransformer: Hierarchical alignment of visual regions and disease tags for medical report generation
You D, Liu F, Ge S, et al. Aligntransformer: Hierarchical alignment of visual regions and disease tags for medical report generation[C]//International Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, Cham, 2021: 72-82.
论文内容与第8篇类似
提出AlignTransformer解决医学报告生成中的两个问题:(1)缓解data bias->Align Hierarchical Attention (AHA) (2)生成长报告->Multi-Grained
Transformer (MGT) modules
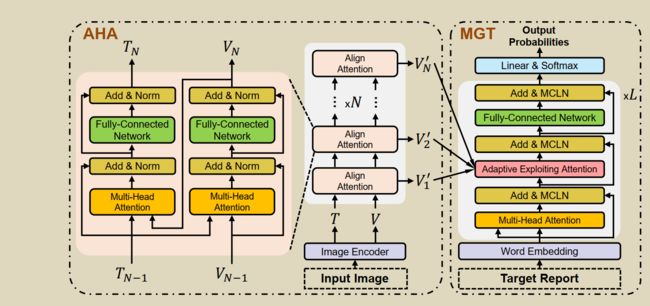
v i s u a l f e a t u r e s V visual features V visualfeaturesV :由ImageNET预训练CheXpert微调的ResNet-50提取
tags T :由multi-label classification产生Tags
A H A : { V , T } → V ^ \mathrm{AHA}:\{V, T\} \rightarrow \hat{V} AHA:{V,T}→V^:AHA首先从输入图像中预测疾病标签,然后通过分层对齐视觉区域和疾病标签学习多粒度的视觉特征。获得的基于疾病的视觉特征可以更好地代表输入图像的异常区域,可以缓解数据偏倚问题。
V ′ = F C N ( M H A ( T , V ) ) V^{\prime}=\mathrm{FCN}(\mathrm{MHA}(T, V)) V′=FCN(MHA(T,V)) T ′ = F C N ( M H A ( V ′ , T ) ) T^{\prime}=\mathrm{FCN}\left(\mathrm{MHA}\left(V^{\prime}, T\right)\right) T′=FCN(MHA(V′,T)) V ^ = LayerNorm ( V ′ + T ′ ) \hat{V}=\operatorname{LayerNorm}\left(V^{\prime}+T^{\prime}\right) V^=LayerNorm(V′+T′)
MGT : V ^ → R : \hat{V} \rightarrow R :V^→R: MGT模块有效地利用了多粒度特性和Transformer框架,生成了长时间的医疗报告。
h ^ t ( l ) = AEA ( h t ( l ) , { V ^ i } ) = ∑ i = 1 N λ i ⊙ MHA ( h t ( l ) , V ^ i ) \hat{h}_{t}^{(l)}=\operatorname{AEA}\left(h_{t}^{(l)},\left\{\hat{V}_{i}\right\}\right)=\sum_{i=1}^{N} \lambda_{i} \odot \operatorname{MHA}\left(h_{t}^{(l)}, \hat{V}_{i}\right) h^t(l)=AEA(ht(l),{V^i})=∑i=1Nλi⊙MHA(ht(l),V^i)
λ i = σ ( [ h t ( l ) ; MHA ( h t ( l ) , V ^ i ) ] W i + b i ) \lambda_{i}=\sigma\left(\left[h_{t}^{(l)} ; \operatorname{MHA}\left(h_{t}^{(l)}, \hat{V}_{i}\right)\right] \mathrm{W}_{i}+b_{i}\right) λi=σ([ht(l);MHA(ht(l),V^i)]Wi+bi)
10.Meshed-memory transformer for image captioning
Cornia M, Stefanini M, Baraldi L, et al. Meshed-memory transformer for image captioning[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 10578-10587. [源码]
11.Cross-modal Memory Networks for Radiology Report Generation
Chen Z, Shen Y, Song Y, et al. Cross-modal Memory Networks for Radiology Report Generation[C]//Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). 2021: 5904-5914. [源码] 【论文翻译】
提出了一种跨模态存储器网络(CMN)来增强用于放射学报告生成的编码器-解码器框架,其中共享存储器被设计为记录图像和文本之间的对齐,以便于跨模态的交互和生成设计了一个共享cross-modal memory networks 来记录图文的对齐。解决图文多模态映射和如何使用这种映射进行更好的报告生成。
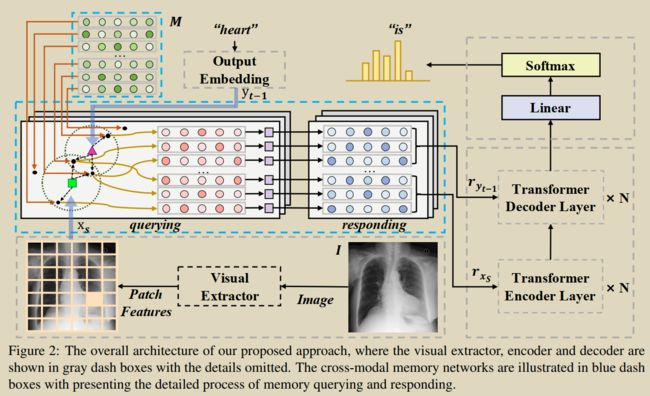
详细地,使用存储矩阵来存储跨模态信息并使用它来执行对视觉和文本特征的存储查询和响应,其中对于存储查询,从矩阵中提取最相关的存储向量并根据输入的视觉和文本特征计算它们权重,然后通过加权查询到的存储矢量来生成响应。之后,对于输入视觉和文本特征的响应被馈送到编码器和解码器中,以便通过显式的可学习的跨模态信息生成增强的报告。视觉和文本特征的存储响应被用作编码器和解码器的输入,以增强生成过程。

共享矩阵类似于使用Transfomer机制方式对齐图文特征,对比效果次于AlignTransfomer。但相比AlignTransfomer只是用NLP metrics,本文使用了CE Metrics
12.Knowledge-driven encode, retrieve, paraphrase for medical image report generation
Li C Y, Liang X, Hu Z, et al. Knowledge-driven encode, retrieve, paraphrase for medical image report generation[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2019, 33(01): 6666-6673.
要生成长且语义一致的报告来描述医学图像,在衔接视觉和语言模式、整合医学领域知识以及生成真实准确的描述方面面临巨大挑战。我们提出了一种新的知识驱动的编码、检索、解释(KERP)方法,该方法将传统的基于知识和检索的方法与现代的基于学习的方法相协调,以实现准确和稳健的医学报告生成。具体来说,KERP将医学报告生成分解为明确的医学异常图学习和随后的自然语言建模。KERP首先使用Encode模块,将视觉特征转化为结构化的异常图,并结合先前的医学知识;然后是Retrieve模块,该模块基于检测到的异常检索文本模板;最后,一个释义模块,根据特定的情况重写模板。KERP的核心是提出的通用实现单元Graph Transformer (GTR),它可以在知识图、图像和序列等多个领域的图结构数据之间动态转换高级语义。实验表明,该方法生成结构化、健壮的报告,并支持准确的异常描述和可解释的注意区域,在两个医疗报告基准上取得了最先进的结果。具有最佳的医学异常和疾病分类精度,提高了人体评价性能

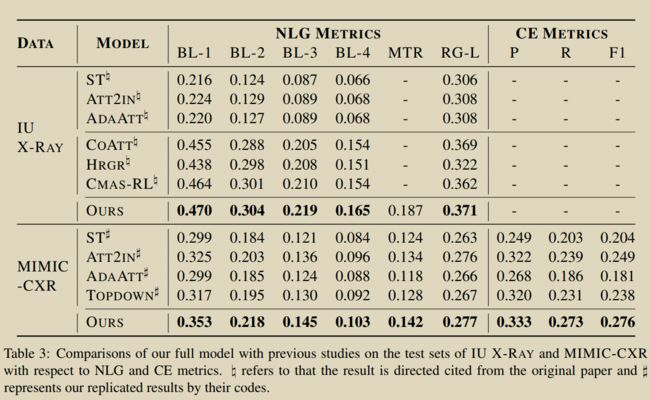
13.Generating radiology reports via memory-driven transformer
Chen Z, Song Y, Chang T H, et al. Generating radiology reports via memory-driven transformer[J]. arXiv preprint arXiv:2010.16056, 2020. [源码] 【博客翻译】 【博客解读2】
提出R2Gen模型。利用医疗影像报告的特点,在 Transformer 的解码端中引入关联记忆网络(Relational Memory,RM),从而能够使用 Transformer 建模影像报告长距离信息的同时,建模其中的模式化信息。
为了将 Relational Memory 引入到 Transformer 中,作者还提出了基于记忆的层归一化(Memory-driven Conditional Layer Normalization,MCLN),使模型达到更好的效果。为了将 Relational Memory 引入到 Transformer 中,作者还提出了基于记忆的层归一化(Memory-driven Conditional Layer Normalization,MCLN),使模型达到更好的效果。


模型结构
模型上使用的是编码器-解码器框架,由三个模块构成,分别是视觉提取器、编码器和解码器。视觉提取器使用的是预训练的卷积神经网络,编码器和解码器是基于 Transformer 骨架,本文提出的创新点关注于解码器部分,编码器上使用是标准的 Transformer 编码器。
视觉编码器使用的是预训练的卷积神经网络。医疗影像经过视觉编码器后得到一个 width x height x dim 的特征,将二维图像特征 flatten 之后得到一个(width x height) x dim的序列特征作为编码器的输入。之后,编码器的输出将输入给解码器。
关于解码器部分,最自然的想法是直接用标准的 Transformer 解码器,但论文作者尝试后发现简单地使用 Transformer 不能完全解决生成报告长度短和生成内容准确性不足的问题,于是引入了 RelationalMemory 模块,改进了层归一化模块。
Relational Memory 旨在学习影像报告的模式化信息,把 Relational Memory 引入层归一化,使得影像报告生成时,用 Memory 控制 Transformer 输出特征的均值和方差,从而深度利用了影像报告的模式化信息。
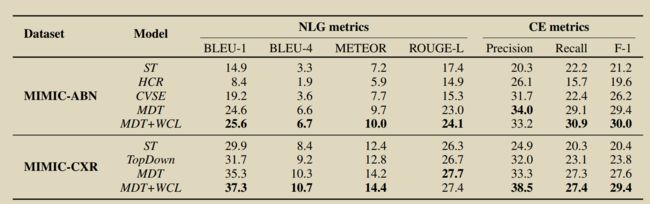
14.Weakly Supervised Contrastive Learning for Chest X-Ray Report Generation
Yan A, He Z, Lu X, et al. Weakly Supervised Contrastive Learning for Chest X-Ray Report Generation[J]. arXiv preprint arXiv:2109.12242, 2021.

为解决交叉熵损失函数导致的文本生成输出中出现高频标记或句子过于频繁,在交叉熵之外引入对比学习损失,提升报告生成的多样性。
GroundTruth报告用ChexBERT生成标签,标签通过聚类划分为簇,用于对比损失。给与类似的报告更多的惩罚从而鼓励多样性。 α \alpha α取值为2。
L W C L = ∑ i = 1 N log exp ( s i , i ) ∑ l i ≠ l j exp ( s i , j ) + α ∑ l i = l j exp ( s i , j ) \mathcal{L}_{W C L}=\sum_{i=1}^{N} \log \frac{\exp \left(s_{i, i}\right)}{\sum_{l_{i} \neq l_{j}} \exp \left(s_{i, j}\right)+\alpha \sum_{l_{i}=l_{j}} \exp \left(s_{i, j}\right)} LWCL=∑i=1Nlog∑li=ljexp(si,j)+α∑li=ljexp(si,j)exp(si,i)
15.Automatic Generation of Chest X-ray Reports Using a Transformer-based Deep Learning Model
Amjoud A B, Amrouch M. Automatic Generation of Chest X-ray Reports Using a Transformer-based Deep Learning Model[C]//2021 Fifth International Conference On Intelligent Computing in Data Sciences (ICDS). IEEE, 2021: 1-5.
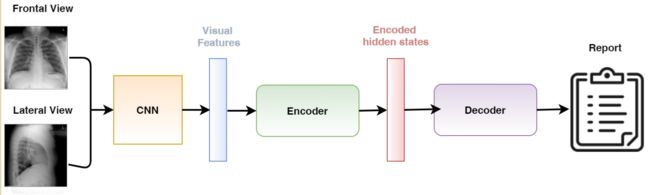
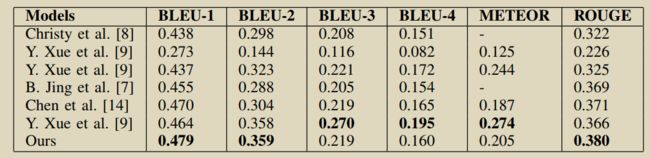
16.RATCHET: Medical Transformer for Chest X-ray Diagnosis and Reporting
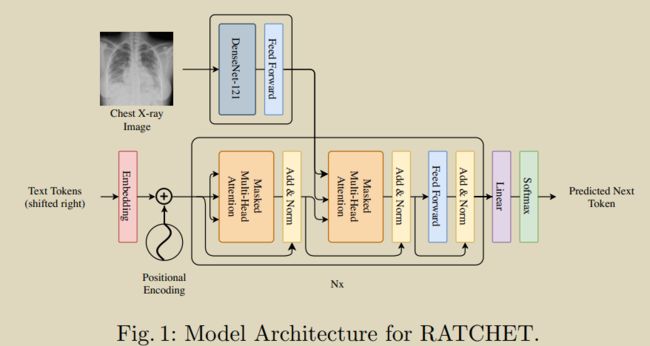
Hou B, Kaissis G, Summers R M, et al. RATCHET: Medical Transformer for Chest X-ray Diagnosis and Reporting[C]//International Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, Cham, 2021: 293-303. [[源码]

17.Progressive Transformer-Based Generation of Radiology Reports
Nooralahzadeh F, Gonzalez N P, Frauenfelder T, et al. Progressive Transformer-Based Generation of Radiology Reports[J]. arXiv preprint arXiv:2102.09777, 2021. [源码]
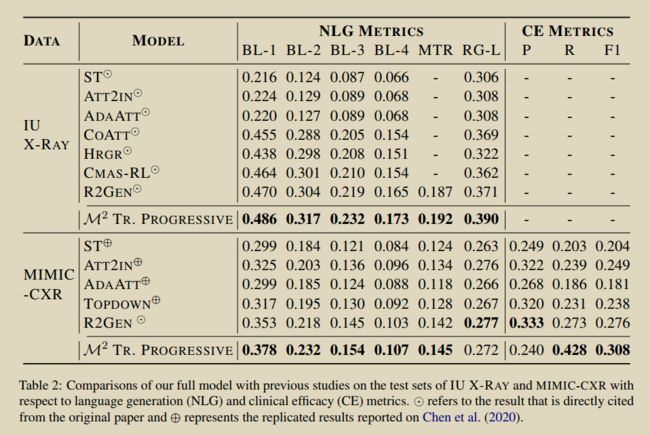
受受课程学习的启发,提出了一个连续的(即,图像到文本到文本)生成框架,在这个框架中,将放射学报告的生成问题分为两个步骤。与立即从图像生成完整的放射学报告相反,该模型在第一步中从图像生成全局概念,然后使用Transformer架构将它们转换为更精细和一致的文本。我们在每一步都遵循基于Transformer的序列到序列范式。我们在两个基准数据集(IU X-RAY 和MIMIC-CXR )上改进了最新的技术。


19.Automated Generation of Accurate& Fluent Medical X-ray Reports
Nguyen H T N, Nie D, Badamdorj T, et al. Automated Generation of Accurate& Fluent Medical X-ray Reports[J]. arXiv preprint arXiv:2108.12126, 2021. [源码]

提出一个分类-生成-解释框架,特别强调临床准确性,同时保持生成报告的语言流利性。
提出了一种可微分的端到端方法,包括三个模块(分类器生成器-解释器),其中分类器模块通过上下文建模(第和疾病状态感知机制学习疾病特征表示;生成模块将疾病嵌入转化为医学报告;解释器模块是一个完全可微的网络模块,根据生成器的输出来估计疾病相关主题的清单,并与分类模块的原始输出进行比较,从而形成反馈环路增强生成的报告和分类器输出的一致性。
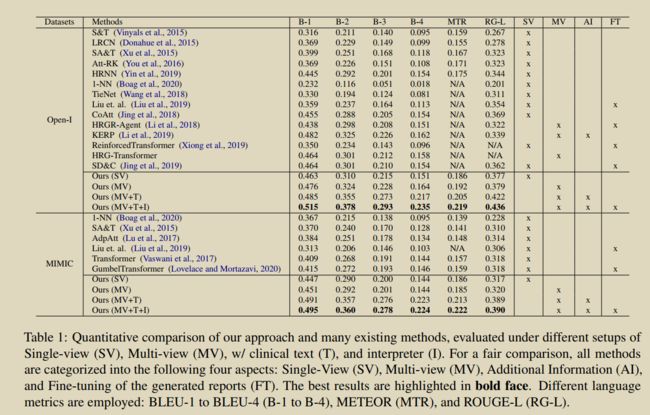

20.Auto-encoding knowledge graph for unsupervised medical report generation
Liu F, You C, Wu X, et al. Auto-encoding knowledge graph for unsupervised medical report generation[J]. Advances in Neural Information Processing Systems, 2021, 34.
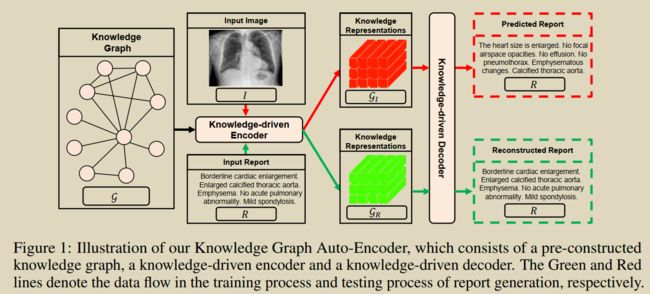
本文提出了一种无监督模型知识图谱自动编码器(KGAE),它利用独立的图像集和报告集(图像和报告集是独立的,没有重叠)训练。KGAE由预先构造的知识图谱、知识驱动的编码器和知识驱动的解码器组成。如图所示,知识图谱作为图像和报告的共享潜在空间。知识驱动编码器可以将图像 I I I或报告 R R R作为查询,并将其投影到潜空间中相应的坐标GI和GR上。这样,由于 G I \mathcal{G}_{I} GI和 G R \mathcal{G}_{R} GR享同一个潜空间,可以利用潜空间中的位置来衡量图像和报告之间的关系,从而缩小了视觉域和文本域之间的差距。总之,为了在没有成对的图像和报告前提下,为缩小视觉和语言之间的差距,采用知识图谱创建一个潜在的空间。编码器可以提取图像和报告知识表示形式,即知识相关的图像和报告,(图片,报告知识)分享共同的潜在空间,它允许在没有图文对的情况下缩小视觉和语言领域的差距。接下来,我们引入知识驱动解码器,利用 G I \mathcal{G}_{I} GI和 G R \mathcal{G}_{R} GR生成报告。在训练阶段,我们通过基于 G R \mathcal{G}_{R} GR重构输入报告 R R R来估计解码器的参数,即 R → G R → R R \rightarrow \mathcal{G}_{R} \rightarrow R R→GR→R;在预测阶段,我们直接将 G I \mathcal{G}_{I} GI输入训练好的解码器,生成报告。通过这种方式,我们的方法可以在不使用任何标记的图像-报告对的情况下生成理想的报告。
除了无监督模式外,KGAE还可以以半监督或监督的方式应用。在半监督设置下,KGAE仅使用60%的配对数据集,就能获得与当前最先进模型竞争的结果;在监督设置下,通过对现有工作中的全配对数据集进行训练,KGAE可以分别在IU x射线和MIMIC-CXR上设置新的最先进的性能。


21.Learning to generate clinically coherent chest X-ray reports
Lovelace J, Mortazavi B. Learning to generate clinically coherent chest X-ray reports[C]//Findings of the Association for Computational Linguistics: EMNLP 2020. 2020: 1235-1243. [源码]

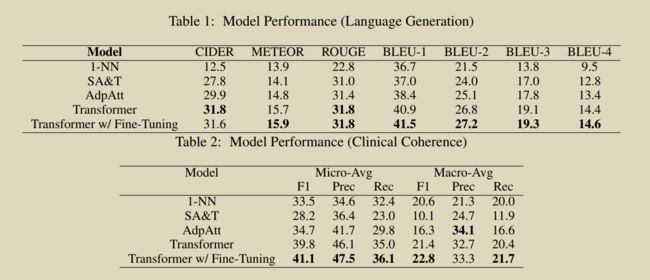
利用Transfomer架构的放射学报告生成模型,并证明它比竞争的基线更流畅和临床一致。我们还开发了一种程序,从生成的报告中可区分地提取临床信息,并利用这种可区分性进一步调整我们的临床一致性模型
(1)将transformer模型应用于CXR报告的生成,并通过语言生成指标和生成报告的临床一致性来证明它优于竞争性基线。(2)设计了一种,可微分地从生成的报告中提取临床信息,并利用这种可微分性性来进一步微调报告生成模型,以产生更一致的临床报告。
Image-Encode: Pretrained DenseNet-121
Word: Word2Vec
Differentiable CheXpert :为了直接训练模型生成临床准确的报告,必须能够从生成的放射学报告中区分地提取临床观察结果。然而,疾病标签通常是使用不可区分的基于规则的标签器从放射科报告中提取的。通过训练一个可微模型来预测从我们的训练集中的报告中由CheXpert分配的标签,从而开发了一个CheXpert标签的可微近似。利用CNN和双向LSTM进行预测。
Differentiable Language Generation :utilize the Gumbel-Softmax trick[参见博客介绍],利用Softmax的连续性,微分近似argmax。
Fine-Tuning Procedure :先用NLG指标生成报告,然后将Gumbel-Softmax技巧应用于解码器的可微分样本令牌,然后将可微分CheXpert应用于采样报告,从而引入第二个训练目标,测量真实CheXpert标签和通过将我们的可微CheXpert应用于采样报告而获得的标签之间的一致性。最终的目标函数为两种方式损失函数的加权和。
22.Automated radiology report generation using conditioned transformers
Alfarghaly O, Khaled R, Elkorany A, et al. Automated radiology report generation using conditioned transformers[J]. Informatics in Medicine Unlocked, 2021, 24: 100557. 【源码】
针对IU-Xray dataset. :(1)对预先训练的Chexnet进行微调,从图像中预测特定的标签。(2)从预测标签的预训练嵌入中计算加权语义特征。(3)在视觉和语义特征上使用预先训练的GPT2模型生成完整的医学报告
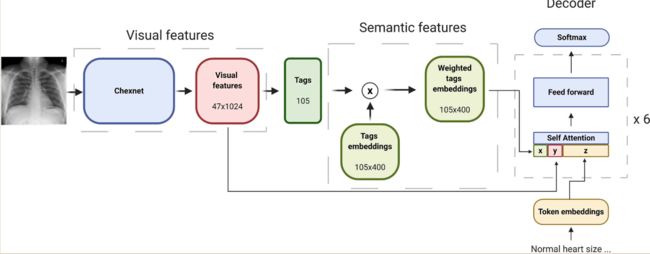
模型体系结构由三个主要组件组成:可视化模型、语义特征生成和解码器。视觉模型作为编码器,负责预测与图像相关的标签,并生成视觉特征。语义特征是通过将标签置信度分数与相应的预训练嵌入值相乘来计算得到。解码器是基于视觉和语义特征的基于Transfomer(distilGPT2 )的预训练模型。

condition Transformer: C S A ( X , Y , Z ) = softmax ( ( Z W q ) [ X U k Y H k Z W k ] T ) [ X U v Y H v Z W v ] C S A(X, Y, Z)=\operatorname{softmax}\left(\left(Z W_{q}\right)\left[\begin{array}{c}X U_{k} \\ Y H_{k} \\ Z W_{k}\end{array}\right]^{T}\right)\left[\begin{array}{l}X U_{v} \\ Y H_{v} \\ Z W_{v}\end{array}\right] CSA(X,Y,Z)=softmax⎝⎜⎛(ZWq)⎣⎡XUkYHkZWk⎦⎤T⎠⎟⎞⎣⎡XUvYHvZWv⎦⎤
CSA表示条件自我注意,Z表示嵌入的输入令牌,X表示语义特征,Y表示视觉特征,Uk、Hk、Uv、Hv分别表示语义特征和视觉特征添加的新键和值。 本文中的condition Transformer借鉴自论文Encoder-agnostic adaptation for conditional language generation
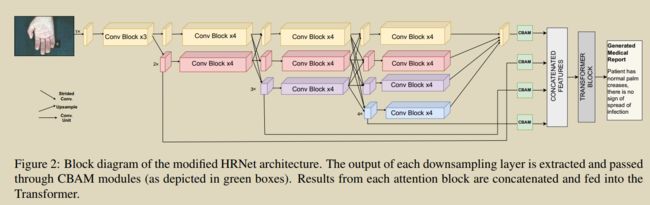
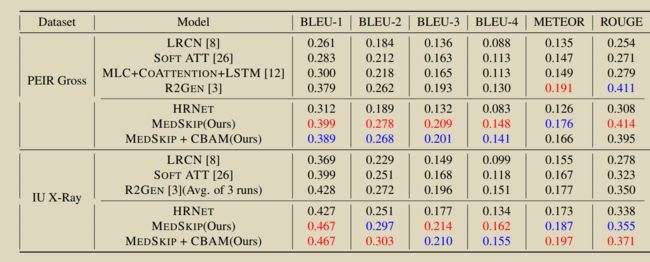
23. Medskip: Medical report generation using skip connections and integrated attention
Pahwa E, Mehta D, Kapadia S, et al. Medskip: Medical report generation using skip connections and integrated attention[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021: 3409-3415.
提出新颖的视觉提取器MEDSKIP,将skip连接和卷积块注意模块与HRNet结合起来,并结合Memory Transformer来生成医疗报告。
24.Big self-supervised models advance medical image classification
Azizi S, Mustafa B, Ryan F, et al. Big self-supervised models advance medical image classification[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021: 3478-3488.
【博客解读】

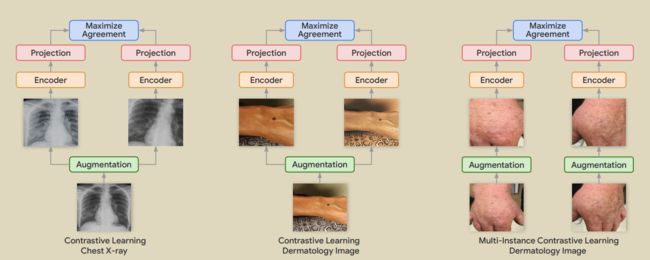
在无标签医学图像上进行的自监督预训练显著优于标准ImageNet预训练和随机初始化训练。提出了多实例对比学习(MICLe)作为现有对比学习方法的一个泛化,以利用每个医疗条件的多个图像。MICLe提高了自监督模型的性能,产生了最先进的结果。在胸片分类上,自监督学习的平均AUC比在ImageNet上预训练的强监督基线的平均AUC要高出1.1%。在ImageNet 和CheXpert均进行预训练的效果比单独在这两个数据集上预训练要好。

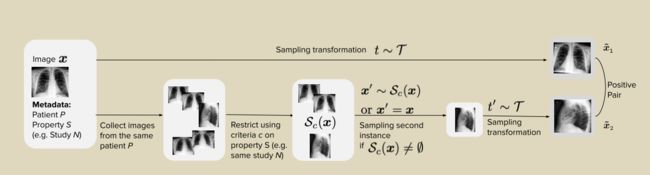
25.Medaug: Contrastive learning leveraging patient metadata improves representations for chest x-ray interpretation
Vu Y N T, Wang R, Balachandar N, et al. Medaug: Contrastive learning leveraging patient metadata improves representations for chest x-ray interpretation[C]//Machine Learning for Healthcare Conference. PMLR, 2021: 755-769.
(1)开发了一种方法MedAug,使用患者元数据(关于患者、研究和图像的侧性的具体信息)在对比学习中选择positive pair,并将该方法应用于胸部x光片,用于胸腔积液分类的下游任务,使用两幅不同的图像作为对比学习的正对,比只使用同一图像的两个增强物提供更好的预训练表征。因此,其他医学影像的对比学习方法可以通过使用患者元数据来扩展正对的构建来获益。(2)与ImageNet预训练的基线相比,提出的最佳预训练表征在平均AUC方面的性能提高了14.4%,这表明使用患者元数据从多幅图像中选择positive pair可以显著改善表征。(3)对标签信息进行了比较实证分析,结果表明:(A)使用来自相同患者的正对不同图像,这些图像具有相同的潜在病理,改善了预先训练的表征,(2)增加每个图像查询中选择形成正对的不同图像的数量,提高了预训练表示的质量.(4)对使用患者元数据选择消极对的策略进行了探索性分析,没有发现与不使用元数据的默认策略相比有什么改进
26.Learning visual-semantic embeddings for reporting abnormal findings on chest x-rays
Ni J, Hsu C N, Gentili A, et al. Learning visual-semantic embeddings for reporting abnormal findings on chest x-rays[J]. arXiv preprint arXiv:2010.02467, 2020. [源码]
自动生成医学图像报告因其减轻放射科医生工作负担的潜力而受到越来越多的关注。现有的报告生成工作经常训练编码器-解码器网络生成完整的报告。然而,这些模型受到数据偏差(如标签不平衡)的影响,并面临文本生成模型固有的共同问题(如重复)。在这项工作中,我们的重点是报告异常发现的放射图像;我们提出了一种方法,除了用无监督的聚类和最小规则对报告进行分组外,还可以从报告中识别异常结果,而不是对完整的放射学报告进行培训。我们将该任务定义为跨模态检索,并提出条件视觉语义嵌入方法,以在联合嵌入空间中对齐图像和细粒度异常发现。我们证明了我们的方法能够检索异常结果,并且在临床正确性和文本生成度量上优于现有的生成模型。
27.Chexbert: combining automatic labelers and expert
annotations for accurate radiology report labeling using bert
Smit A, Jain S, Rajpurkar P, et al. CheXbert: combining automatic labelers and expert annotations for accurate radiology report labeling using BERT[J]. arXiv preprint arXiv:2004.09167, 2020.【源码】
引入了一种基于BERT的方法来标记医学图像报告,该方法利用了可用的基于规则的系统和专家标注的质量。在MIMIC-CXR 完成了标注。
先从生物医学上预先训练的BERT模型开始(Devlin等人,2019;Peng等人,2019年)对现有标注器的输出进行培训,并对使用自动反向翻译增强的专家标注的小语料库进行进一步的微调。将这种方法应用于胸部x光

28.Encoder-agnostic adaptation for conditional language generation
Ziegler Z M, Melas-Kyriazi L, Gehrmann S, et al. Encoder-agnostic adaptation for conditional language generation[J]. arXiv preprint arXiv:1908.06938, 2019. [源码]
论文解读
探究了改造预训练语言模型使得它能够接收任意encoder输入的方法

绿色表示参数初始化使用预训练的权值,灰色表示随机初始化。红色向量表示每一层的目标激活,蓝色向量表示编码器输出处的源特征。可以用于IMAGE PARAGRAPH CAPTIONING 任务(Caption是单句或句子片段,需要模型生成整个段落)
29.Self-supervised learning for cardiac MR image segmentation by anatomical position prediction
Bai W, Chen C, Tarroni G, et al. Self-supervised learning for cardiac mr image segmentation by anatomical position prediction[C]//International Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, Cham, 2019: 541-549.
提出一种利用预测解剖结构为辅助任务的自监督特征学习方法用于心脏MR分割。

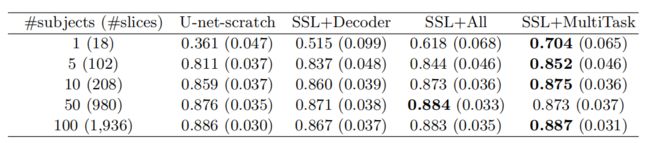
31.Rubik’s cube+: A self-supervised feature learning framework for 3d medical image analysis
Zhu J, Li Y, Hu Y, et al. Rubik’s cube+: A self-supervised feature learning framework for 3d medical image analysis[J]. Medical image analysis, 2020, 64: 101746.
32.Contrastive learning of global and local features for medical image segmentation with limited annotations
Chaitanya K, Erdil E, Karani N, et al. Contrastive learning of global and local features for medical image segmentation with limited annotations[J]. Advances in Neural Information Processing Systems, 2020, 33: 12546-12558. [源码] 【CSDN博客翻译】
本文提出的策略通过扩展对比学习框架在数据量较为局限(标注数据少)的医学标注数据中,利用半监督学习进行三维医学图像分割。具体来说:①提出了一种全新的对比学习策略,通过利用三维医学图像(特定领域)的结构相似性;②设计了一种局部对比损失以学习独特的局部特征表达,其在像素级图像分割(特定问题)中性能提升显著。作者应用该方法在三个医学数据集上进行了实验验证,实验设定使用较为有限的标注数据上进行训练(限定训练集的大小),与已提出的自监督和半监督学习方法相比,该方法对分割性能有大幅的提升。
introduction
尽管对比学习已取得不错的成绩,但根据现有的文献作者发现有两个重要方向还未进行深入的探索和研究。首先,大量的研究工作聚焦在让模型提取全局特征表达,而忽略了明确地学习每个局部区域的独有特征表达。这也是作者认为可能对像素级图像分割有益的地方。其次,对比学习的策略往往是使用数据增强,(即前文提到的同一图像进行不同图像变换也就是不同的数据增强方法,同一原始图像经变换后相互之间的特征表达相似,不同图像之间的特征表达不同),而没有用到不同数据之间的相似性(注意:作者为什么要在前文摘要中就提出是特定领域domain-specific cue 和特定问题 problem-specific cues。因为MRI/CT是三维数据,每层数据之间是存在相似性的,而自然场景的图像一般是不存在这种相似性)。因此作者利用针对特定领域数据结构(三维数据,本质上就是多个二维数据在新增维度上的堆叠),通过数据结构之间的内在联系,以获取相比传统单个数据源进行数据增强方式更多的性能提升。
Method
使用编码器提取全局表示,使用解码器层提取互补的局部表示

1.全局对比损失
对于给定的一对相似的图像
l ( x ~ , x ^ ) = − log e sim ( z ~ , z ^ ) / τ e sim ( z ~ , z ^ ) / τ + ∑ x ˉ ∈ Λ − e sim ( z ~ , g 1 ( e ( x ˉ ) ) ) / τ , z ~ = g 1 ( e ( x ~ ) ) , z ^ = g 1 ( e ( x ^ ) ) l(\tilde{x}, \hat{x})=-\log \frac{e^{\operatorname{sim}(\tilde{z}, \hat{z}) / \tau}}{e^{\operatorname{sim}(\tilde{z}, \hat{z}) / \tau}+\sum_{\bar{x} \in \Lambda^{-}} e^{\operatorname{sim}\left(\tilde{z}, g_{1}(e(\bar{x}))\right) / \tau}}, \tilde{z}=g_{1}(e(\tilde{x})), \hat{z}=g_{1}(e(\hat{x})) l(x~,x^)=−logesim(z~,z^)/τ+∑xˉ∈Λ−esim(z~,g1(e(xˉ)))/τesim(z~,z^)/τ,z~=g1(e(x~)),z^=g1(e(x^))
全局对比损失: L g = 1 ∣ Λ + ∣ ∑ ∀ ( x ~ , x ^ ) ∈ Λ + [ l ( x ~ , x ^ ) + l ( x ^ , x ~ ) ] L_{g}=\frac{1}{\left|\Lambda^{+}\right|} \sum_{\forall(\tilde{x}, \hat{x}) \in \Lambda^{+}}[l(\tilde{x}, \hat{x})+l(\hat{x}, \tilde{x})] Lg=∣Λ+∣1∑∀(x~,x^)∈Λ+[l(x~,x^)+l(x^,x~)]
2.局部对比损失
l ( x ~ , x ^ , u , v ) = − log e sim ( f ~ ( u , v ) , f ^ ( u , v ) ) / τ e sim ( f ~ ( u , v ) , f ^ ( u , v ) ) / τ + ∑ ( u ′ , v ′ ) ∈ Ω − e sim ( f ~ ( u , v ) , f ^ ( u ′ , v ′ ) ) / τ l(\tilde{x}, \hat{x}, u, v)=-\log \frac{e^{\operatorname{sim}(\tilde{f}(u, v), \hat{f}(u, v)) / \tau}}{e^{\operatorname{sim}(\tilde{f}(u, v), \hat{f}(u, v)) / \tau}+\sum_{\left(u^{\prime}, v^{\prime}\right) \in \Omega^{-}} e^{\operatorname{sim}\left(\tilde{f}(u, v), \hat{f}\left(u^{\prime}, v^{\prime}\right)\right) / \tau}} l(x~,x^,u,v)=−logesim(f~(u,v),f^(u,v))/τ+∑(u′,v′)∈Ω−esim(f~(u,v),f^(u′,v′))/τesim(f~(u,v),f^(u,v))/τ
3.训练
首先使用全局对比损失训练Encoder(需要设置一个全连接层 g 1 g1 g1),然后固化 E n c o d e r Encoder Encoder参数,利用局部对比损失训练 D e o c d e r Deocder Deocder的第1层至第L层(需要设置一个全连接层 g 2 g2 g2)。最后补全 D e c o d e r Decoder Decoder后续部分,该部分采用随机参数进行初始化,并利用标注数据进行微调,完成整个模型的训练。
33.Sample-efficient deep learning for COVID-19 diagnosis based on CT scans
He X. Sample-efficient deep learning for COVID-19 diagnosis based on CT scans[J]. IEEE transactions on medical imaging, 2020. 【源码】
1.构建一个公开的数据集,其中包含数百次Covid-19阳性的CT扫描(在216例covid-19患者中,伴有临床表现的349例CT图像)
2.设计了不同的迁移学习策略,并进行了综合研究,以调查迁移学习对covid-19诊断的影响。
domain difference in data:ImageNet、 Lung Nodule Maligancy
neural architectures:VGG16 ,ResNet18, ResNet50, DenseNet-121 , DenseNet-169 , EffificientNet-b0 , and EffificientNet-b1 .
light-weight architecture: CRNet


3.为了从有限的标记数据中学习,提出了 Self-Trans网络,该网络将对比自监督学习与迁移学习协同集成,以学习强大的无偏特征表示,以减少过拟合的风险。


4.在COVID19-CT数据集上,F1得分为0.85,AUC为0.94,准确率为0.86。
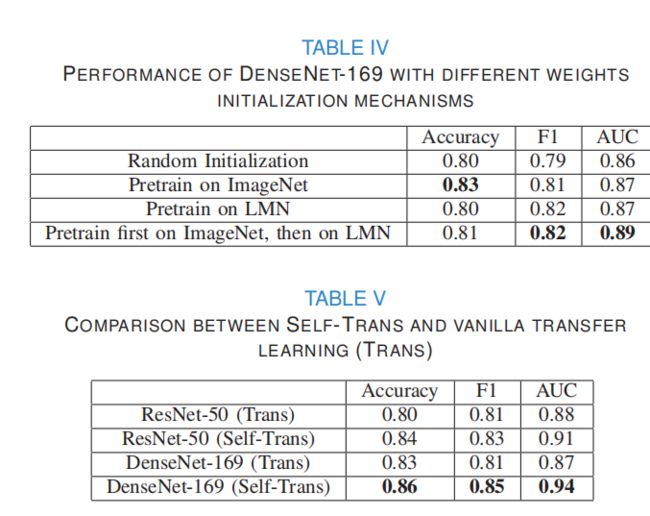
34.Comparing to learn: Surpassing imagenet pretraining on radiographs by comparing image representations
Zhou H Y, Yu S, Bian C, et al. Comparing to learn: Surpassing imagenet pretraining on radiographs by comparing image representations[C]//International Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, Cham, 2020: 398-407. [知乎解读] 【源码】
提出了一种全新的基于动量的teacher-student自监督预训练方法C2L(Compare to Learn)。此方法旨在利用大量(70万X光数据 ChestX-ray14、MIMIC-CXR、CheXpert、 MURA)的未标注的X光图像预训练一个2D深度学习模型,提出Batch mixup 、 feature mixup和存储先前epoch中提取到feature的memory queue,使得模型能够在有监督信息的条件下,通过对比不同图像特征的差异,提取通用的图像表达。


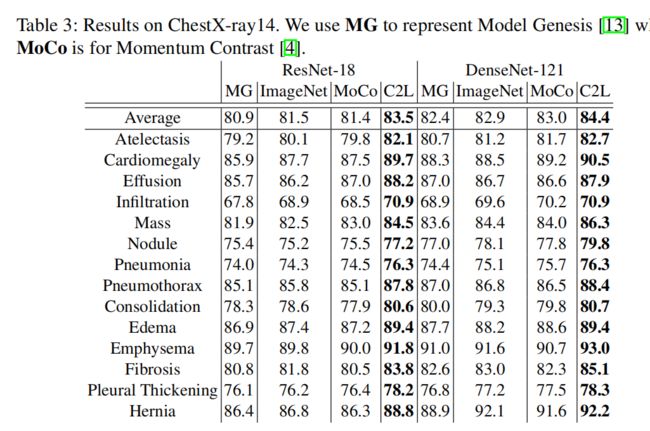
35.Moco pretraining improves representation and transferability of chest x-ray models
Sowrirajan H, Yang J, Ng A Y, et al. Moco pretraining improves representation and transferability of chest x-ray models[C]//Medical Imaging with Deep Learning. PMLR, 2021: 728-744. [源码]
提出基于MoCo的MoCo-CXR。

37.Semi-supervised medical image classification with relation-driven self-ensembling mode
Liu Q, Yu L, Luo L, et al. Semi-supervised medical image classification with relation-driven self-ensembling model[J]. IEEE transactions on medical imaging, 2020, 39(11): 3429-3440.
对半监督,多实例,和迁移学习在医学成像,包括在诊断或分割任务上进行综述( 2018年前)。
38.Focalmix: Semi-supervised learning for 3d medical image detection
Wang D, Zhang Y, Zhang K, et al. Focalmix: Semi-supervised learning for 3d medical image detection[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 3951-3960. [博客解读]
39.Contrastive learning of medical visual representations from paired images and text
Zhang Y, Jiang H, Miura Y, et al. Contrastive learning of medical visual representations from paired images and text[J]. arXiv preprint arXiv:2010.00747, 2020.
提出Contrastive VIsual Representation Learning from Text (ConVIRT):通过在图像和文本模式之间的双向对比目标,最大限度地提高真实图像-文本对与随机对之间的一致性,从而改善视觉表示。在医学图像分类、图像获取任务上对比学习获得很好的性能。 [Pytorch代码] [Connected Papers]

41.Trust It or Not: Confidence-Guided Automatic Radiology Report Generation
Wang Y, Lin Z, Tian J, et al. Confidence-Guided Radiology Report Generation[J]. arXiv preprint arXiv:2106.10887, 2021.
提出一种用于评价生成的射线报告不确定信的可信度度量方法。
设计方法,在视觉和文本领域,明确量化放射科报告的生成模型的不确定性。这种多模态不确定性度量可以充分捕获报告和句子级别的模型置信分数,进一步利用这些分数来衡量损失,以实现更全面的模型优化。
医学报告生成的不确定性导致原因:首先,从不充分的样本中学习可能导致不可靠的模型,从而容易生成不准确的报告。其次,现有的评价指标大多是针对主流的NLP任务设计的,已经被证明不适合从医学图像生成放射学报告的任务。一些传统的因素,如图像质量差、方案选择不当、临床资料缺乏、经验和技术的限制、缺乏既定的诊断标准等,可能会影响诊断报告的不确定性,从而影响临床结果。
文章贡献:证实视觉提取器在image-caption结构中的重要性,并加入了一个辅助的AutoEncoder分支来编码特定的特征,并进一步获得视觉不确定性。提出了一种新的度量放射医学报告语义相似度的方法SMAS(Sentence Matched Adjusted Semantic Similarity),该方法能够更好地捕捉诊断信息的特征。基于SMAS进一步量化文本的不确定性。得到的不确定性可以整合到模型中,平衡报告/句子的损失函数,有利于整个优化过程。
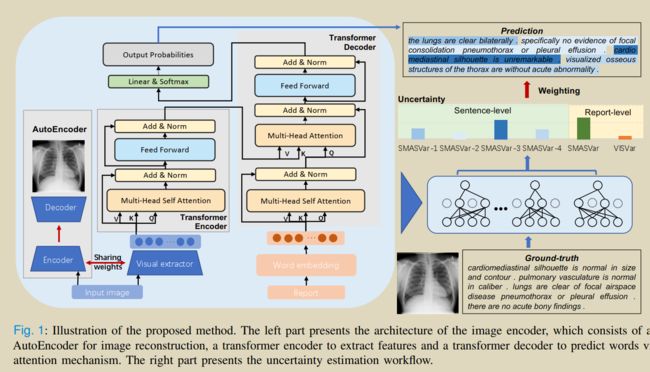
visual uncertainty measured by variance VISVar and textual SMAS uncertainty measured by variance SMASVar.
visual uncertainty–>Monte Carlo (MC) dropout variational inference method
Textual Uncertainty: ->the variance of semantic similarity scores among generated diagnostic reports


42.Medical transformer: Gated axial-attention for medical image segmentation
Valanarasu J M J, Oza P, Hacihaliloglu I, et al. Medical transformer: Gated axial-attention for medical image segmentation[C]//International Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, Cham, 2021: 36-46. 【源码】
知乎解读