When Machine Learning Meets Congestion Control: A Survey and Comparison
机器学习邂逅拥塞控制:一个对比性研究
论文简介:此论文是一篇综述性的文章,通过阅读本论文可以对拥塞控制算法有一个较为清晰的认识,区分传统算法及辨识各种传统算法的优劣,特别是本文通过导引的方式可以让读者了解机器学习在拥塞控制算法中的应用现状,对应该使用哪种机器学习的方法给读者指明了方向,并使得读者认识到应用RL在CC中的优劣势及面临的挑战。
When Machine Learning Meets Congestion Control: A Survey and Comparison
摘要:
主要介绍机器学习目前跨学科的应用和激增趋势。随后介绍本文的创新点和贡献为:
1.对于基于机器学习的拥塞控制进行了详细的总结和比较。
2.与基于规则(Rule-based)相比是十分可取的。
3.并从一些文献中得出结论强化学习(RL)是一个主要趋势。
4.本文探讨了基于RL的CC算法的性能,并提出这种算法目前存在的问题。
5.概述了基于RL的CC算法相关的挑战和趋势 。
1 导言
数据中心(DCs)、WiFi、5G和卫星通信(satellite communications)、网络传输场景和协议的复杂性和多样性急剧增加给传输协议的设计带来了巨大的挑战,由此而产生了丰富多样的拥塞控制算法(Congestion contro CC)。
然而,网络场景的多样性 和网络内部的动态结构使得设计高效的CC算法异常困难。
因此,基于ML的CC算法提出了一种通用的CC机制可以支持不同的网络场景。
文章主题:对传统CC进行背景分析;在此基础上,研究了ML在CC领域的应用现状和面临挑战。
A 传统的CC
传统的CC算法可分为两大类 end-to-end CC(端到端的拥塞控制)and network-assisted CC(网络辅助的拥塞控制):
1.end-to-end
引用了文献:
[3]The newreno modification to tcp’s fast recovery algorithm
[4]TCP vegas: New techniques for congestion detection and avoidance
[5]Tcp new vegas: improving the performance of tcp vegas over high latency links in Fourth IEEE International Symposium on Network Computing and Applications. IEEE, 2005, pp. 73–82
对于端到端的拥塞控制,其主要挑战为从隐式会话信号(implicit session signals)中识别网络拥塞。隐式会话信号包括丢包和传输延迟。
端到端的拥塞控制主要被区分为三种:基于丢包的拥塞控制(loss-based CC),基于延迟的拥塞控制(delay-based CC),和混合拥塞控制(hybrid CC)。
1.2 loss-based CC
调整发送者在给定时间内没有收到相应的确认(ACK)时的发送速率,这通常被认为是数据包丢失。 当给定网络设备中的缓冲区超载时,就会发生损失,因此基于丢失的方法应该通过高带宽利用率来获得高吞吐量。 但是对于一些对延迟敏感的应用程序,无法保证较低的传输时间。 此外,网络拥塞(如随机丢包)可能不会触发丢包,这可能会误导任何CC决策。
参考文献
[9]Highspeed TCP for large congestion windows
[10]TCP hybla: a TCP enhancement for heterogeneous networks
[11]Binary increase congestion control (BIC) for fast long-distance networks
1.3 delay-based CC
基于延迟的方法依赖于检测到的传输延迟由网络引起的跨任务延迟。 与基于丢失的方法相比,基于延迟的方法更适合于高速和灵活的网络,如无线网络,因为它们不受随机丢包的影响。 然而,计算准确的传输延迟仍然是一个重大挑战。 如主机堆栈中分组处理时间的轻微变化可能会导致测量的传输延迟的偏差,导致与发送速率相关的错误决策。
参考文献
[12] Fast tcp: From theory to experiments IEEE network, vol. 19, no. 1, pp. 4–11, 2005.
[13] Tcp lola: Congestion control for low latencies and high throughput in 2017 IEEE 42nd Conference on Local Computer Networks (LCN). IEEE, 2017,pp. 215–218.
[14] Timely: Rtt-based congestion control for the datacenter in ACM SIGCOMM Computer Communication Review, vol. 45, no. 4. ACM, 2015, pp. 537–550.
1.4 hybrid CC
为了充分利用丢包和延迟策略的优点而提出了混合方法,虽然这些方法不能准确地确定网络状态与丢包和传输延迟有关的隐式信号。
参考文献
[15]TCP veno: TCP enhancement for transmission over wireless access networks
[16]Tcp-africa: an adaptive and fair rapid increase rule for scalable TCP
[17]A compound TCP approach for high-speed and long distance networks
2. network-assisted
引用了文献:
[6]Random early detection gateways for congestion avoidance
[7]Analysis and design of an adaptive virtual queue (AVQ) algorithm for active queue management
[8]Congestion control for cross-datacenter networks
为了解决不能准确地确定网络状态与丢包和传输延迟有关的隐式信号这个问题,网络辅助的拥塞控制提出了[18],[19]中的方法, 其中,网络设备提供与网络状态相关的显式信号,供主机进行发送速率决策:
[18]A proposal to add explicit congestion notification (ECN) to IP
[19]EMPTCP: an ECN based approach to detect shared bottleneck in MPTCP
当网络设备拥塞时,一些数据包将被标记为信号——显式拥塞通知(explicit congestion notification ECN)。 接收方将在ACK中发送ECN信号,发送方将附加相应地发送速率。 在[20]中采用了拥塞的ECN信号。 为了进一步提高CC的性能,在[21]中采用了用于拥塞的多级ECN信号,这提供了粒度更精细的CC。
[20]Improving ECN marking scheme with microburst traffic in data center networks
[21]Enabling ECN for datacenter networks with RTT variations
随着大量新技术和网络的出现,例如DCs(data centers)、WiFi、5G和卫星通信,网络传输场景的复杂性和多样性的急剧增加,给CC带来了重大挑战。虽然传统的CC方法在一个场景中可能很好地工作,但它们可能不能保证在不同的网络场景中的性能。 除此之外,一个网络场景中不断变化的流量模式也可能影响解决方案的性能,因此我们需要一种智能CC方法。
B 基于学习的拥塞控制
网络场景的动态性,多样性和复杂性给CC带来了重大挑战。 比如,很难为所有网络场景设计通用方案。此外,即使是相同网络的动态特性也会使CC的性能不稳定。当前的网络环境也可能包括有线网络和无线网络,这使得丢包检测更加困难。
参考文献:
[22]Improving tcp in wireless networks with an adaptive machine-learnt classifier of packet loss causes in International Conference on Research in Networking. Springer, 2005,pp. 549–560.
[23]Enhancement of tcp over wired/wireless networks with packet loss classifiers inferred by supervised learning Wireless Networks,vol. 16, no. 2, pp. 273–290, 2010.
[24]Bayesian packet loss detection for TCP
基于学习的方案是基于实时网络状态来做出控制决策,而不是使用预设的规则。这使他们能够更好地适应动态和复杂的网络场景。
基于不同的机制,基于学习的CC算法可以分为两组:绩效导向(performance-oriented)的CC算法和数据驱动(data-driven)的CC算法。 绩效导向的CC算法采用目标优化方法对模型进行训练得到输出。通常,这种算法需要手动确定效用函数中的参数。学习过程应该收敛于效用函数的最优值。
有一些典型的绩效导向的CC算法如:
Remy
[25]TCP ex machina: computergenerated congestion control
Remy是绩效导向的CC算法中的一个早期版本,其效用函数包括吞吐量和延迟。 为了最大化效用函数的期望值,Remy找到了基于预先计算的查找表的映射。 然后,估计相应的发送速率。
PCC and PCC Vivace
PCC和PCC Vivace表现出良好的性能,在设计效用函数的基础上这些功能涵盖了诸如往返时间(RTT)等基本性能指标。
[26]PCC:re-architecting congestion control for consistent high performance
[27]PCC vivace: Online-learning congestion control
GCC
GCC采用卡尔曼滤波方法,利用线性系统状态方程通过观测数据对系统状态进行最优估计。 基于卡尔曼滤波,GCC估计端到端的单向时延变化,动态控制发送速率。
Copa
Copa通过优化基于当前吞吐量和分组延迟的目标函数来调整发送速率。 与上述绩效导向的CC算法相比,数据驱动的CC算法更依赖于数据集,并存在收敛性问题。 然而,由于数据驱动的CC算法基于当前数据更新其参数,而不是依赖于给定的常数参数, 它们通过学习表现出更强的适应性,满足不同的网络场景。 此外,主流研究更多地集中在数据驱动的CC算法上。在本文中,我们的重点也是数据驱动的CC算法。
在数据驱动的CC算法方面,采用机器学习技术对模型进行了训练,包括监督学习技术、无监督学习技术和RL技术。 监督和无监督学习技术已被广泛应用于改进网络CC。
[22]Improving tcp in wireless networks with an adaptive machine-learnt classifier of packet loss causes in International Conference on Research in Networking. Springer, 2005,pp. 549–560.
[30]End-to-end inference of loss nature in a hybrid wired/wireless environment
然而,这些方案仅部分成功,因为它们是离线训练的,并且不能对实际的无线和拥塞丢失进行分类[23]。
[23]Enhancement of tcp over wired/wireless networks with packet loss classifiers inferred by supervised learning Wireless Networks,vol. 16, no. 2, pp. 273–290, 2010.
在具有动态和复杂状态空间的网络中,RL在处理实际的拥塞方面具有更大的优势 [31],[32]。
[31]Experience-driven networking: A deep reinforcement learning based approach in IEEE INFOCOM 2018-IEEE Conference on Computer Communications. IEEE, 2018, pp. 1871–1879.
[32]Dynamic TCP initial windows and congestion control schemes through reinforcement learning
因此,RL技术已被证明有利于CC,因为它更高的在线学习能力[33],[34]。
[33]A deep reinforcement learning perspective on internet congestion control
[34]Tcp-drinc: Smart congestion control based on deep reinforcement learning
目前,许多研究都集中在基于RL的CC方案上。
然而,基于学习的CC仍处于起步阶段。 大多数基于学习的CC算法通过调整拥塞窗口(CWND)来控制发送速率,而不是直接调整发送速率。 因此,在高速网络中,突发(burstiness)仍然是一个问题,因为当多个ACK到达时,CWND会急剧增加[35]。
[35]Advances in internet congestion control
目前基于学习的CC算法,如[36],[37]通常集中在端到端CC,而不是网络辅助CC。
[36]QTCP: adaptive congestion control with reinforcement learning
[37]Internet congestion control via deep reinforcement learning
设计一个通用的基于学习的CC方案,可以在实际的网络场景中工作,仍然是学术界和工业界的一个主要目标。
C 总体分析
除了考虑当前基于学习的CC算法,并提供系统的分析和比较, 我们在不同的动态网络场景下对基于学习的CC进行了全面的实验,并与更传统的算法进行了比较。 基于学习的CC算法在实际网络栈中的实现表明,它们往往是有所欠缺的的,因为智能学习决策不是足够快。即在100毫秒的顺序下,GPU具有1GB的实际网络数据传输。 因此,为了判断决策模型的利弊,我们使用NS3仿真器对各种方案进行了综合实验[38]。
[38]ns3-gym: Extending openai gym for networking research
在仿真中,我们将基于RL的深度Q学习(DQL)[39]、近似策略优化(PPO)[40]和深度决定策略梯度(DDPG)[41]的CC算法与传统CC算法NewReno[42]进行了比较。
[39]A deep reinforcementlearning based congestion control mechanism for NDN
[40]Reinforcement learning-based variable speed limit control strategy to reduce traffic congestion at freeway recurrent bottlenecks
[41]Self-learning congestion control of mptcp in satellites communications in IWCMC 2019, 2019.
[42]The newreno modification to tcp’s fast recovery algorithm
我们设计了三种不同的场景,具有不同的带宽和延迟配置。 高带宽,低时延的网络模拟一个典型的数据中心网络。 低带宽,高时延的网络模拟典型的广域网。 低带宽,低时延的网络模拟自组织无线网络。 这三种网络环境代表了基于学习的CC算法所需的不同环境。 为了充分评估基于学习的CC方案的性能, 我们生成网络流量跟踪,80%的大象流(长流)和20%的老鼠流(短流)进行实验。 实验结果表明,基于学习的CC算法更适合于带宽延迟乘积(Bandwidth Delay Product BDP)较高的动态环境。 对于低BDP的网络,即 链路带宽低或链路延迟低, 基于学习的CC算法过于激进,无法稳定地学习和处理动态网络。 此外,由于环境复杂性有限,这三种基于学习的CC算法的性能在我们的模拟环境中没有任何差异。 因此,它们都可以处理这些网络场景。
在实际场景中,基于RL的CC算法受到RL所需计算时间的影响。这影响了这些计划的可行性。 因此,我们提出了三种潜在的解决方案来处理这个问题。 首先,设计基于状态和动作映射表的轻量级模型,以减少学习决策的时间消耗。 其次,降低决策频率,在低动态网络场景下提供更好的可行性。 最后,异步RL可以提高基于RL的CC算法的决策速度。
在此基础上,我们进一步探讨了基于学习的CC领域未来工作的挑战和趋势。 基于学习的CC算法目前面临的挑战主要集中在参数选择、 计算复杂度高、 内存消耗高、 培训效率低、 难以收敛和不兼容等工程相关问题上。 在未来,基于学习的CC需要得到学术界和工业界更多的关注。基于对当前基于学习的CC解决方案的理解和分析, 我们确定了基于学习的CC的趋势。首先,由于它们具有处理动态和复杂状态空间网络拥塞的能力, 基于RL的CC将是一个重要的研究趋势。 第二,鉴于学习决策的时间和成本过高, 基于轻量级学习的CC将是一个关键的研究方向。第三,一个开放的网络测试平台,提供大规模差异化的动态网络场景,以支持基于学习的CC机制的探索和验证, 需要在基于学习的CC算法的研究中做出进一步的贡献。
论文的其余部分结构如下。 在第二节中,我们介绍了相关的背景知识。 在第三节、第四节和第五节中,我们分别将基于监督学习的CC算法、基于无监督学习的CC算法和基于RL的CC算法作为三组主要的基于学习的CC算法的代表。 在第六节中,我们概述了模拟的设置。 在第七节中,我们对基于RL的CC算法和传统CC算法进行了仿真和比较。 在第八节中,我们概述了基于学习的TCP的挑战和趋势。 最后,在第九节中,我们总结了这篇论文。
2 背景
CC机制
CC机制通常涉及四个关键问题:慢启动、避免拥塞、重传和快恢复[43]。
[43]TCP congestion control
为了说明CC的过程,我们采用了基于窗口的CC。 滑动CWND确定下一个要发送的数据包。
慢启动
避免拥塞
重传
快恢复
此处略去关于慢启动、避免拥塞、重传和快恢复理论的介绍。下面是这四个阶段中比较重要的窗口更新公式:
CWNDt+1 = CWNDt + SMSS ∗ SMSS / CWNDt (1)
SMSS是发送方的最大段包大小。 随着每个ACK的到来,CWND将有一个小的增长,总体增长率将略有非线性。
B 拥塞控制算法的速率调整机制
为了控制输入数据的发送速率,CC算法有三种速率调整机制:基于窗口的技术、基于速率的技术和Pacing。
基于窗口的策略直接调整CWND。 CWND反映了网络的传输容量。 发送方的实际窗口是CWND和接收方窗口中选择的较小的窗口。 考虑到基于窗口的策略的便利性, 有多种传统的CC算法,如经典算法DCTCP[35]。虽然基于窗口的技术是高效的,但突发性(burstiness)是一个大问题,特别是在高带宽的网络中。 当一堆ACK到达时,CWND将急剧增加。 因此,基于窗口的策略会导致变化、低吞吐量和高延迟。
[35]Advances in internet congestioncontrol
基于速率的策略直接控制实际发送速率,因此,他们能够充分利用带宽而不突发(burstiness)。 有许多基于速率的策略。在 [44]中,提出了一种基于速率策略的早期版本,用于控制异步传输模式(ATM)服务中的拥塞。 [45]将控制理论与基于速率的策略相结合,处理连续时间网络中的流量控制。 然而,由于基于速率的策略依赖于预先设计的规则,这些规则可以在每个间隔内进行调整,因此与基于窗口的策略相比,响应度相对较低。 此外,基于速率的复杂策略往往比较耗费资源。
[44]The rate-based flow control framework for the available bit rate atm service IEEE network, vol. 9, no. 2, pp.25–39, 1995.
[45]A control-theoretic approach to flow control
什么是Pacing?
Pacing uses the tcp window to determine how much to send but uses rates instead of acknowledgments to determine when to send.
因此,一种基于packet pacing的混合策略[46]被提了出来。 packet pacing是确认驱动的,这类似于基于窗口的策略。 因此,响应能力得到保证。 此外,基于packet pacing策略,发送器可以在给定的时间间隔内分配传输任务,从而避免突发(burstiness)。 在[47]中,packet pacing策略被证明可以避免由于密集到达的ACK引起的突发(burstiness)。 然而,在某些网络场景中,包括TCP通信的初始周期,packet pacing在吞吐量和公平性方面表现得更差[48]。
[46]Observations on the dynamics of a congestion control algorithm: The effects of twoway traffic
[47]The effects of asymmetry on TCP performance
[48]Understanding the performance of TCP pacing
如上所述,不同的调整策略可以满足多样化的网络场景。 在传统的CC算法中,大多数算法都是基于窗口的。 随着CC算法的发展,越来越多的基于速率和packet pacing的CC算法被设计出来。 根据文献得到,大多数基于学习的CC算法都采用基于窗口的CC算法。
C 拥塞控制算法的性能度量
CC算法被期望实现各种目标和目的,如表I所示。
| 目标 | 描述 |
|---|---|
| 最大化吞吐量 | 为了最大化吞吐量,带宽利用率应该很高。 高吞吐量与低RTT或流量完成时间相矛盾,因为高吞吐量意味着环境容忍高队列长度,这可能会造成长时间的延迟。 |
| 尽量减少RTT或流完成时间 | 基本要求。 对于每个任务,流程完成时间反映延迟,延迟应该尽可能小。 |
| 最小化丢包率 | 基本要求。低丢包率意味着网络环境稳定,时延低。 |
| 公平 | 公平对于多个用户来说很重要。 资源分配应尽可能在用户之间公平,并考虑不同的应用程序。 |
| 响应能力 | 更新CWND的频率和调整策略会影响算法的响应能力。 预期反应能力高,这也意味着资源消耗高。 因此, 响应需要基于不同的场景进行平衡。 |
作者接下来介绍了相关的目标
吞吐量 Throughput
往返时间RTT
数据包丢失率packet loss rate
公平性Fairness
响应能力Responsiveness
这些目标对于所有CC算法都很重要,但它们很难实现。为某些目标取得好的表现,可能意味着必须牺牲其他目标。 在不同的情况下,目标也可能有不同的优先级,因此必须进行权衡。 基于以往的文献,不同的CC研究侧重于不同的性能方面,包括:吞吐量、RTT和丢包率。 在我们的模拟中,我们详细测量了这三个参数。
3 基于监督学习的拥塞控制算法
在这一部分中,我们介绍了基于监督学习的CC算法。 监督学习技术训练给定的样本以获得最优模型,然后使用该模型将所有输入映射到相应的输出。 通过对输出及其实现分类的能力进行判断,监督学习技术具有执行数据分类的能力。 经典的监督学习方法包括决策树、随机森林、贝叶斯、回归和神经网络。
在网络领域,采用监督学习方法预测端到端网络的拥塞信号,并对网络辅助网络的队列长度进行管理。 拥塞信号预测包括损失分类( loss classification)和延迟预测。 如前所述,当传统CC算法发生拥塞时,基于丢包或延迟隐式检测拥塞。 在基于监督学习的CC算法中,基于当前和以前的网络状态,如队列长度和网络延迟,预先估计拥塞。 这种方法的关键基础是网络状态形成一个连续的时间序列,其中未来的状态可以通过过去的状态来预测。 通过这一点,与传统的CC算法相比,基于监督学习的CC算法可以更加智能一些。
A 端到端网络中的拥塞检测
1)损失分类(Loss Classification):损失是用于检测拥塞的关键但间接的信号。 只有当拥塞已经发生时,它才会给网络中的节点反馈。 此外,基本损失的CC算法无法区分丢包的原因。 因此,损失的分类对于理解CC是必不可少的。
无线网络提供了许多经典场景,以区分无线损耗和拥塞损耗。 在无线网络中,损失可能是由错误的无线链路、用户移动、信道条件和干扰造成的。 在传统CC算法的基础上,有大量对无线网络中的损失分类进行的研究。在[49]中,该算法(Biaz)利用分组到达时间对无线丢失和拥塞丢失进行分类。 如果分组到达时间限制在一个范围内,则丢失的分组是由于无线丢失而丢失。 否则,损失被认为是拥塞损失。在 [50]中,采用一种新的设计相对单向行程时间损失分类器(ROTT)来区分损失类型。 如果ROTT的连接相对较高,则损失应该是由拥塞引起的。 在其他情况下,损失被假定为无线损失。 在[51]中,使用损失数量和ROTT来区分损失类型。 该算法提供了一种比上述两种算法更有效的混合算法ZigZag。
[49]Discriminating congestion losses fromwireless losses using inter-arrival times at the receiver in Proceedings 1999 IEEE Symposium on Application-Specific Systems and Software Engineering and Technology. ASSET’99 (Cat. No. PR00122). IEEE,
1999, pp. 10–17.
[50]Achieving moderate fairness for udp flows by path-status classification in Proceedings 25th Annual IEEE Conference on Local Computer Networks. LCN 2000. IEEE, 2000, pp. 252–261.
[51]End-to-end differentiation of congestion and wireless losses
这些损失分类器在某些特定场景中是有效的,但有其局限性。 Biaz[49]适用于无线最后一跳拓扑,而不是具有竞争流的无线瓶颈链路,而Spike[50]在具有多个流的无线主干拓扑中表现出更好的性能。ZigZag[51]相对更通用,因此能够满足不同的拓扑场景,但是它对发送速率很敏感。
考虑到传统的无线网络损失分类器的局限性,监督学习技术提供了几个优点。 为了充分理解损失信息,可以考虑多个参数。在 [22]中,采用单向延迟和分组间时间作为状态来预测损失类别。 [23],排队延迟、到达时间和数据包列表被用作输入。 此外,还应用了各种监督学习技术。 [52]采用决策树、决策树组合、装袋算法(Bagging算法 Bootstrap aggregating 引导聚集算法)、随机森林、极端随机树(ET或Extra-Trees(Extremelyrandomized trees,极端随机树))、提升方法(Boosting 是一种可以用来减小监督式学习中偏差的机器学习算法)和多层感知器对损失类型进行分类。仿真表明,这些智能损失分类器在不同的网络场景下实现了较高的精度。
除了无线损失外,争用损失在光突发交换(OBS)网络中也很常见。 光突发交换提供了一种先进的网络,由于保留了波长而节省了资源。 然而,由于OBS中缺少缓冲区,当核心节点出现突发( burst)时,会产生争用损失。 有一些基于监督学习的CC算法旨在解决这一问题。在文献[53]中,讨论并测量了一些经典的竞争解决方案,包括波长转换、偏转路由选择和共享反馈光纤延迟线缓冲。 为了衡量这些策略的有效性,考虑了突发丢失概率和突发概率。这些策略在OBS争用问题上表现出良好的性能。 在文献[54]中采用隐马尔可夫模型分别对竞争损失、拥塞损失和控制拥塞进行分类。仿真结果表明了损失分类器在不同网络场景下的有效性。
[52]A machine learning approach to improve congestion control over wireless computer networks
[53]Comparison of contention resolution strategies in obs network scenarios in Proceedings of 2004 6th International Conference on Transparent Optical Networks (IEEE Cat. No. 04EX804), vol. 1. IEEE, 2004, pp. 18–21.
[54]Loss classification in optical burst switching networks using machine learning techniques:
improving the performance of TCP
在具有多信道路径的网络中,重排序损失是不可忽略的。 在网络中,当数据包被重新排序时,重新排序损失就发生了。 基于监督学习的CC算法能够处理相关的分类问题。 在文献[55]中,无序传递会导致RTT的变化。 因此,与重排相关的RTT和与拥塞相关的RTT表现出不同的分布。在文献 [24]中,用贝叶斯算法表示两种损失的RTT分布。 该算法具有较高的预测精度。
[55]End-to-end internet packet dynamics
综上所述,无线丢失、竞争丢失和重排序丢失会影响拥塞丢失的检测。 监督学习技术显示了在不同网络场景中对损失类型进行分类的优势。其机制如图1和表II所示,总结了基于监督学习方法的丢失分类器的研究。 然而,这些基于监督学习的CC算法存在一些问题。

| 算法 | 场景 | 输入 | 输出 |
|---|---|---|---|
| 决策树促进(Decision Tree Boosting) | 无线网络 | 单向延迟,包间时间 | 链路丢失或拥塞丢失 |
| 贝叶斯 | 具有重排事件的网络 | 丢失数据包的RTT | 重新排序丢失或拥塞丢失 |
| 隐马尔可夫模型 | 光突发交换(OBS) | 在任意两个脉冲之间的出口处成功接收到的脉冲数 | 竞争损失或拥塞损失 |
| DT,装袋,Boosting,神经网络 | 无线网络 | 排队延迟,包间到达时间,分组列表 | 无线丢失或拥塞丢失 |
| 决策树,决策树集合,装袋,随机森林,极端树,升压,多层感知器,K-最近邻 | 无线网络 | 标准差、最小值和最大值的单向延迟、包间时间 | 无线丢失或拥塞丢失 |
错误分类是一个问题。 在无线网络中,预定义的参数决定了拥塞损失和无线损失分类的误差。 如果拥塞丢失比无线丢失更容易分类,则分类器在无线网络中表现出不良的性能,因为当检测到丢失时,网络应该做出反应。 然而,由于分类错误,网络将拥塞丢失视为无线丢失,不能快速控制发送速率。 因此,拥塞无法减少。 否则,如果无线丢失更容易被归类为拥塞丢失,则该算法在无线场景中是无效的,因为存在相当大的无线丢失。 因此,无线网络可能对丢失信号反应过度。 因此,需要仔细考虑算法中的参数,以平衡不同网络场景下的性能。 计算复杂度和预测精度之间的平衡是另一个问题。 如在文献[52]中,与决策树相比,Boosting算法获得了更高的精度,但消耗了更多的网络资源。 因此,考虑到提升精度的有限改进,决策树显示出更多的优势,尽管总是有权衡。
2)延迟预测:作为一种拥塞信号,传输延迟反映了传输中数据量(in-flight data),反映了网络的整体负荷。有一些经典的基于延迟的CC算法,如Vegas,可以精确地测量延迟[4]。 然而,在动态网络中,传统的基于延迟的CC算法不够灵活。 如图2所示,表III得出结论,监督学习技术具有较高的学习能力,在预测未来延迟和快速反应以避免拥塞方面是有效的。

| 算法 | 场景 | 算法细节 |
|---|---|---|
| Fixed-share experts | 延迟敏感网络 | 利用专家框架对RTT进行预测,然后调整网络环境以提高产出 |
| 不增加计算复杂度的指数加权移动平均固定份额 | 具有波动时间尺度的网络 | 提出了一种不同RTT情景下的RTT估计方法 |
| 贝叶斯定理 | 实时视频应用和无线网络 | 根据估计的延迟调整发送速率 |
| 线性回归 | 交互式视频应用程序 | 在发送速率和RTT之间建立一个统计函数,并根据给定的RTT的线性回归调整发送速率 |
RTT预测是延迟预测的一个重要课题。 基于测量的RTT,可以计算其他参数,如RTO。基于RTT的RTO预测已经有大量的研究在探索。在文献[56]中,将RTT的估计动态地改变为无线网络中RTO的估计。在文献[57]中采用了使用RTT预测RTO和带宽利用率。在文献[58]中,固定份额专家被用来计算移动和有线场景下的RTO,这依赖于RTT估计。另外,在文献[59]和[60]中,固定份额杠杆指数加权移动平均技术证明了一种更精确的算法。
[56]Adaptive timer-based tcp control algorithm for wireless system in 2005 International Conference on Wireless Networks, Communications and Mobile Computing, vol. 2. IEEE, 2005,pp. 935–939.
[57]Improving round-trip time estimates in reliable transport protocols
[58]A machine learning framework for tcp round-trip time estimation EURASIP Journal on Wireless Communications and Networking, vol.2014, no. 1, p. 47, 2014.
[59]Smart experts for network state estimation
[60]Network state estimation using smart experts
此外,基于网络中其他参数测量RTT的研究也层出不穷。在文献[61]中,线性回归用于建立RTT与发送速率之间的关系。文献[62]中利用贝叶斯技术模拟时延与发送速率之间的分布,然后根据发送速率预测时延。 这是实时视频应用和无线网络所需要的。
[61]Statistical learning based congestion control for real-time video communication
[62]Learning-based congestion control for internet video communication over wireless networks
延迟预测对于要求网络具有更高响应性的延迟敏感网络也很重要。为了保证低计算复杂度和高响应性,提出了几种基于有限参数和简单技术的RTT预测智能算法。需要进一步的研究来突破限制,处理更复杂的相关参数和技术,以改善延迟预测。
B 网络辅助网络中的队列长度管理
队列长度管理是网络辅助CC算法的重点。已有大量的研究与AQM家族的ECN技术有关。 然而,最初的AQM算法检测当前队列长度并对环境作出反应。 有研究表明,未来的队列长度可以预测。 预测过程如图3所示。 此外,表IV总结了一些相关研究。

| 算法 | 场景 | 算法细节 |
|---|---|---|
| 神经网络 | ATM网络 | 根据过去的传输流量预测未来的传输值 |
| 模糊神经 | ATM网络 | 使用估计的平均队列长度计算损失,然后控制发送速率 |
| 线性最小均方误差估计 | 支持AQM的网络 | 建立远程流量之间的关系,根据过去的流量来估计未来的流量 |
| 归一化最小均方 | 支持AQM的网络 | 采用自适应技术估计瞬时队列长度 |
| 深度信念网络 | NDN | 基于pending interest table entries预测计算平均队列长度 |
在文献[63]和[64]中显示了以前的流量模式与未来排队行为之间的远距离( long-range)依赖性。已经有很多研究应用了多种监督学习技术,包括线性最小均方误差估计[65]、归一化最小均方算法[66]、神经网络[67][68]、深信度网络[69]和模糊神经[70]。
[63]Experimental queueing analysis with long-range dependent packet traffic
[64]Self-similarity and heavy tails: Structural modeling of network traffic A practical guide to heavy tails: statistical techniques and applications, vol. 23, pp. 27–53, 1998.
[65][On exploiting traffic predictability in active queue management](https://doi.org/10.1109/INFCOM.
2002.1019416)
[66]An adaptive prediction based approach for congestion estimation in active queue management (APACE)
[67]Nn-red: an aqm mechanism based on neural networks Electronics Letters, vol. 43, no. 19, pp. 1053–1055, 2007.
[68]An intelligent architecture for ATM traffic congestion control
[69]ACCP:adaptive congestion control protocol in named data networking based on deep learning
[70]A neural-fuzzy system for congestion control in atm networks IEEE Transactions on Systems, Man, and Cybernetics,Part B (Cybernetics), vol. 30, no. 1, pp. 2–9, 2000.
这些算法具有相似的特征,因为它们使用以前流量的时间序列作为输入,而不考虑网络中的不同参数。因此,这些算法为进一步探索相关参数与队列长度之间的依赖关系留下了空间。
4 基于无监督学习的拥塞控制算法
在本节中,提出了另一类基于学习的CC算法:基于无监督学习的CC算法。在数据类别未知的情况下,采用无监督学习技术,根据样本之间的相似度对样本集进行聚类,以达到最小化类内差距和最大化类间差距的目的。 经典的无监督学习算法包括K均值和期望最大化。 与基于监督学习的CC算法相比,基于无监督学习的CC算法没有得到广泛的应用。 它们主要用于聚类损失和延迟特性。
A 端到端拥塞控制算法中的拥塞检测
1) 损失聚类:在网络中,使用无监督学习技术将损失分为几个组,并为每个组分配资源以实现CC,如图4所示。详细摘要见表V。

| 算法 | 场景 | 算法细节 |
|---|---|---|
| 隐马尔科夫模型 | 有线/无线网络 | 使用延迟损失对将数据分组到几个组中,并为每个组分配特定的发送速率 |
| 期望最大化聚类 | 光突发交换网络(OBS) | 聚类损失分为争用损失和拥塞损失,并分别调整环境 |
在文献[71]中,分组延迟变化反映了可用带宽和损失类型。因此,在网络中,损失延迟对被用来对网络中的损失进行聚类。 在[30]和[72]中,损失延迟信息被利用。当一个包丢失时,它将被标记并标记RTT值。基于RTT分布,这些损失可以分为两组:无线损失和拥塞损失。仿真结果表明,拥塞损失具有较高的RTT均值,而无线损失具有较低的均值和较高的变化。在文献[54]中,采用期望最大化聚类技术将OBS中的损失聚类为争用损失和拥塞损失。
[71] V. Paxson Measurements and analysis of end-to-end internet dynamics 1997.
[72]Model-based loss inference by tcp over heterogeneous networks in Proceedings of WiOpt,2004, pp. 364–73.
无监督学习技术对训练是有用的,但它们本身不能满足复杂网络的要求。 与监督学习技术相比,无监督学习方法相对基本,多用于表示状态空间[73]和处理数据聚合[74]。 因此,基于这种方法的研究是有限的。
[73]An unsupervised ensemble learning method for nonlinear dynamic state-space models
[74]A neural network model to minimize the connected dominating set for self-configuration of wireless sensor networks
2) Delay Prediction: 由于延迟计算的处理要求很高,因此只有有限数量的无监督学习CC算法适合于延迟预测。 典型的算法如k均值[75]和相关的机制,如图5和表VI所示。根据信息大小、信息有效性、车辆与RSU之间的距离、消息类型和消息发送方的方向将数据分组,并为每个簇分配一个发送速率。 根据通信参数,将为每个集群分配特定的发送速率。 因此,基于延迟的测量,可以实现CC。

| 算法 | 场景 | 算法细节 |
|---|---|---|
| K均值 | 车载自组网 | 根据信息大小、信息有效性、车辆与RSU之间的距离、消息类型和消息发送方的方向将数据分组,并为每个簇分配一个发送速率 |
基于网络状态的延迟特性,聚类是可以实现的,但是,在动态多变的网络环境下,与有监督学习算法相比,无监督学习技术并不适合。
5 基于RL的拥塞控制算法
RL算法通常包括价值函数(value function)和策略函数(policy function)。值函数负责测量给定网络状态的特定动作的值,以确定是否可以选择给定的动作。策略函数用于根据给定的规则选择操作。 在给定的迭代中,系统根据策略选择一个动作,并且系统提供反馈。 值函数然后计算动作的值并相应地更新它。 基于不同的机制,RL算法分为基于价值的方案和基于策略的方案。 典型的基于价值的方案包括Q学习和DQL。典型的基于策略的方案包括策略梯度、演员评判家(AC)、优势演员评判家(A2C)和异步优势演员评判家(A3C)。基于值的方案和基于策略的方案的区别在于,基于策略的方案估计动作的策略以及是否能够满足不同动作的场景,而基于值的方案则直接预测动作的值。 因此,它们只适合于小范围的行动。 可以将RL算法应用于特定的网络中,以提高CC的效率。 在不同的基于学习的CC算法中,RL得到了最多的关注。与有监督学习方法不同,RL算法不断地监测环境的状态,利用环境中的信息,并对环境做出反应以优化效用函数。 因此,RL算法更适合于可变和不稳定的网络环境。 这类网络有两个主要趋势。 首先,普遍存在的数据中心和云计算应用需要高效的CC算法来处理复杂的网络拓扑[76]。在这种情况下,考虑到系统中可能出现的差异,可靠性可能非常重要。 基于环境学习的RL算法可以及时地适应错误。 第二,移动设备,如智能手机,通常以一种临时的方式连接到无线网络,包括WiFi和4G蜂窝。 因此,更灵活的网络拓扑和多样化的流量是一个主要的挑战[77]。 传统的ML方法不像RL算法那样,不能动态地处理基于训练模型的不同网络环境。这两种趋势正在推动基于RL的CC算法。 在基于RL的CC算法中,RL用于根据端到端网络中的不同场景更新CWND,并在网络辅助环境中管理队列长度。
[75]Centralized and localized data congestion control strategy for vehicular ad hoc networks using a machine learning clustering algorithm
[76]A congestion control method of SDN data center based on reinforcement learning
[77]A reinforcement learning approach to congestion control of high-speed multimedia networks
端到端网络中的窗口更新
与监督学习和无监督学习技术相比,RL算法更能响应环境变化。与基于有监督和无监督学习的CC算法不同,基于RL的CC算法直接根据不同的环境信息学习CC规则。 由于RL算法可以结合实时网络条件并相应地定义动作,因此在RL算法中实时控制是可能的。 各种探索都集中在基于RL的CC算法上,这些算法使用RL更新特定场景的CWND。 基于RL的CC算法的机制如图6所示,摘要如表VII所示。
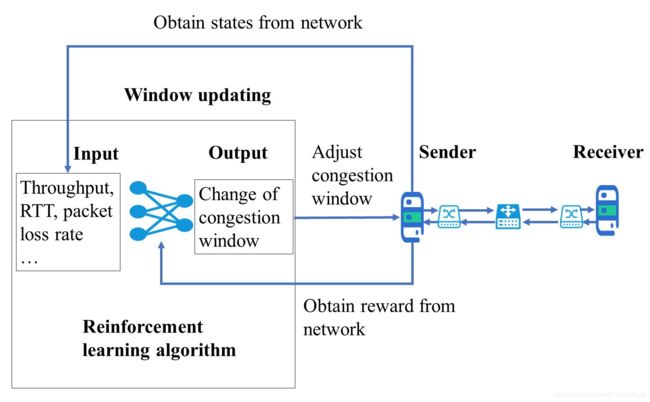
| 算法 | 场景 | 算法细节 |
|---|---|---|
| AC | ATM网络 | 使用演员评论家算法,以尽量减少丢包率和保持视频/语音质量 |
| Q学习和Sarsa | SDN | 训练基于Q学习的离线策略和基于Sarsa的在线策略方法来控制拥塞。 这两种算法都实现了良好的链路利用率 |
| DQL | NDN | 利用NDN中的多样化内容,学习最优的CC策略 |
| DDPG | MPTCP在卫星通信中的应用 | 提出了一种提高低地球轨道卫星通信性能的智能算法 |
| 基于模糊Kanerva的Q学习 | 物联网(IoT) | 减少存储算法历史记录所需的内存量,以支持更大的状态空间和操作空间 |
| Q学习 | 带缓冲瓶颈链路的有线网络 | 输入确认到达时间、分组间隔时间、当前RTT比、最小RTT、慢启动阈值和CWND大小以获得调整信息 |
| 有限动作集学习自动机 | AWNs | 输入包括ack和重复包的到达间隔时间的数据,并输出窗口大小 |
| 连续动作集学习自动机 | AWNs | 保持动作概率分布 |
| Q学习 | AWNs | 在将状态空间映射到动作空间时,要考虑吞吐量和RTT |
| DQL | 无线网络 | 输入由CWND、RTT和到达时间组成的状态,然后输出发送速率 |
| 连续动作集学习自动机 | 无线网络:多跳、单跳,如无线局域网、蜂窝和卫星网络 | 保持动作概率分布 |
| AC | 具有时变流的网络 | 基于参与者-批评框架设计了多智能体拥塞控制器 |
| AC | 具有时变流的网络 | 将AC算法应用于基于LSTM的表示网络中,与wVegas等著名的MPTCP-CC算法相比,显示出了有效性和优越性 |
| A3C | 任务与稀疏奖励,如电子游戏 | 提出一种支持延迟和部分奖励的部分动作学习方法 |
| Q学习 | 连续或大的状态动作空间 | 基于Kanerva编码抽象出状态空间和动作空间 |
| PPO | 互联网服务,如现场视频,虚拟现实和物联网 | 检测网络和数据模式,如延迟,以获得必要的调整 |
| Q学习 | 动态网络 | 检测平均分组到达间隔,平均ACK间隔和平均RTT来调整CWND大小 |
| A3C | 流量大小多样化的网络 | 使用RL算法配置初始窗口和CC策略 |
ATM(asynchronous transfer mode 异步传输模式)是一种典型的适用于基于RL的CC算法的网络。ATM网络是支持多媒体应用的经典网络。 对于不同的多媒体流量,ATM提供了不同的QoS,如信元丢失率和延迟。 然而,在ATM中,高度时变的流量模式会增加网络流量的不确定性。 此外,ATM网络中的小单元传输时间和低缓冲区大小需要更多的自适应和高响应CC算法。在文献[78]中,应用演员评论家算法来处理这些问题。 在所提出的CC算法中,AC侧重于基于信元丢失率和语音质量的性能函数。 在每个步骤中,算法根据性能来测量动作。 这样,不同的传输模式就会与相应的动作连接起来。仿真结果表明,该算法在保证话音质量的前提下,具有较低的信元丢失率。
软件定义网络(SDN)为未来分离转发和控制平面的网络提供了一种新的体系结构。 控制平面具有集中管理整体网络的能力。 有效的CC算法对于SDN是必不可少的。 在文献[76]中,Q学习被用来解决这种先进的网络。 训练的算法表明,其可以实现更高的链路利用率。
数据网络(NDN)也是一个新兴的未来网络体系结构。NDN的主要特点是无连接,提供内容感知和网络缓存。 NDN的典型应用是移动通信和实时通信。 因此,CC算法有望应对多样化和动态的内容。在[39]中,deep-RL算法考虑了不同内容的多样性,并在向网络中请求内容时添加了前缀。因此,当一个给定的动作被执行时,要考虑内容的多样性。
卫星通信网络是动态的,具有时变的流。高带宽和高弹性是关键特性。 视频流是一个有代表性的应用。在卫星通信网络中,频繁的卫星切换会造成路由故障、分组阻塞和信道质量的影响。 为了解决这些问题,在文献[41]中使用DDPG设计了一个多路径TCP。通过测量各子流的重传率,考虑了RTT和ACK数,降低了切换的可能性。
物联网(IoT)是快速发展的无线技术的产物。 物联网的一些核心特征是局部计算、高可变性和潜在的计算需求。在文献[79]中,Q学习被用来满足不同的物联网网络,减少了计算需求,具有很强的学习能力。该算法表明,该调整动作适用于实时处理器和物联网环境下的内存需求。
有线网络不是基于学习的CC领域的典型场景。 与无线网络相比,有线网络相对稳定。当然,一些研究也涵盖了这种情况,例如在文献[80]中。 在[80]中,考虑了高带宽和缓冲不足的瓶颈链路,作为有线网络的典型特征。该算法的状态包含多个参数,如包间发送时间和输入ACK的到达时间等,这些参数反映了当前可用缓冲区信息的信息。因此,该算法在吞吐量和延迟之间取得了较好的平衡。
无线网络是基于学习的CC算法特别是无线自组织网络(AWNs)的研究热点。 AWNs是没有任何固定基础设施的移动无线节点的集合。因此,AWNs具有有限的资源,有限的处理和不可预测的流动性。它们也是高度动态的。在文献[81]中,有限动作集学习自动机是一种学习自动机,它的特点是以较少的信息和可忽略的计算需求更快地学习网络状态,包含有限个动作。该算法在资源消耗有限的动态无线环境中具有良好的学习效果。 在文献[82]中,连续动作集学习自动机被应用于AWNs中。 有限动作集学习自动机的离散化可能不是所有情况下都合适的,例如。 离散化粒度可能太粗或太细。因此,连续动作集学习自动机被用来处理无限多个动作。 它保持了动作概率分布。先进的算法实现了更好的性能。 当然,会消耗更多的计算和训练资源。 此外,在文献[83]中,Q学习结合灰色模型被用来预测AWNs中CC算法的吞吐量和性能。 由于吞吐量的实时评估,该算法更好地适应了动态环境。 上述基于RL的CC算法侧重于单个场景,但是有一些基于RL的设计用于更复杂(多个)的网络场景。 例如,文献[84]、[85]、[36]和[32]中提出了一种AC算法来处理时变流网络中的拥塞问题。 在[77]中,基于RL的CC算法被用于具有稀疏奖励的网络,如电子游戏,而在[86]中,场景集中在连续的、大的状态-动作空间。从以上可以看出,基于RL的CC算法可以满足不同的网络场景,具有较高的适应性和较强的灵活性。 但也存在一定的局限性。 例如,对于连续任务和复杂算法,收敛性很难保证。 此外,状态抽象也很具有挑战性。 目前的算法需要大量的存储空间来存储状态和动作,并需要大量的内存资源。 此外,它们的计算复杂度相对较高。 因此,虽然RL算法具有很强的学习能力,但由于所确定的工程问题,实际应用需要进一步探索。
[78]Reinforcement learningbased neural network congestion controller for atm networks in Proceedings of MILCOM’95, vol. 2. IEEE, 1995, pp. 668–672.
[79]Learning-based and data-driven TCP design for memory-constrained iot
[80]Improving TCP congestion control with machine intelligence
[81]Learningtcp: A novel learning automata based reliable transport protocol for ad hoc wireless networks
[82]Learning-tcp: A stochastic approach for efficient update in TCP congestion window in ad hoc wireless networks
[83]Tcp-gvegas with prediction and adaptation in multi-hop ad hoc networks Wireless Networks, vol. 23, no. 5, pp. 1535–1548, 2017.
[84]Multi-agent congestion control for high-speed networks using reinforcement co-learning
[85]Experience-driven congestion control: When multi-path TCP meets deep reinforcement learning
[86]Dynamic generalization kanerva coding in reinforcement learning for TCP congestion control design
B 网络辅助网络中的队列长度管理
对于基于RL的CC算法的队列长度管理,RL根据当前状态管理队列长度,如图7和表VIII所示。 在队列管理中,比例积分微分器(PID)是最常用的RL技术。 在[88]-[90]中,PID通过计算丢弃概率来维持给定目标阈值的队列长度。在[91]中,拥塞通知也用于控制队列长度。该算法利用Q学习来合理利用网络中的缓冲区大小。 以基于队列长度管理的链路利用率最大化为目标,[92]和[93]利用加载信息来优化依赖RL算法的路由器决策。在队列长度管理的基础上,以最大化链路利用率为目标,[92]和[93]利用负载信息来优化基于RL算法的路由决策。

| 算法 | 场景 | 算法细节 |
|---|---|---|
| PID控制器 | 支持AQM的网络 | 通过稳定路由器队列长度,采用PID调节网络参数 |
| 自适应神经元PID | 支持AQM的网络 | 给定不同的流量负载、场景、RTTs、瓶颈链路容量,保持队列长度在目标队列长度附近 |
| Q学习 | 支持AQM的网络 | 使用RL根据历史流量优化路由器决策 |
| 神经元RL | 支持AQM的网络 | 控制队列长度,基于队列管理最大化链路利用率 |
| 神经网络PID控制器 | 支持AQM的网络 | 基于学习率,计算丢弃概率 |
| Q学习 | 抗干扰网络 | 使用拥塞状态支持拥塞通知 |
[88]Neuron pid: a robust aqm scheme in Proceedings of ATNAC, vol. 2006. Citeseer,2006, pp. 259–262.
[89]An adaptive neuron AQM for a stable internet
[90]A new active queue management algorithm based on self-adaptive fuzzy neural-network pid controller in 2011 International Conference on Internet Technology and Applications. IEEE, 2011, pp.
1–4.
[91]Smart congestion control for delay- and disruption tolerant networks
[92]An adaptive aqm algorithm based on neuron reinforcement learning in 2009 IEEE International Conference on Control and Automation. IEEE, 2009, pp. 1342–1346.
[93]Deep blue: A fuzzy q-learning enhanced active queue management scheme in 2009 International Conference on Adaptive and Intelligent Systems. IEEE,2009, pp. 43–48.
与端到端网络的窗口更新相比,网络辅助CC算法的队列长度管理需要更多的计算资源,因为网络辅助网络中可以使用多个节点来控制拥塞,例如路由器。因此,在状态空间较大、计算复杂度较高的情况下,支持基于RL的CC算法可能成为网络的负担。 此外,基于RL技术的当前队列长度管理只涵盖有限的状态参数,如过去的队列长度和缓冲区大小。 然而,需要更多的参数来提高基于RL的CC算法的性能。
6 模拟设置
在这一节中,我们将介绍作为基于RL学习CC方法为代表的仿真设置。 我们基于实际的网络环境进行实验,这些环境带来了大延迟和高复杂度带来的挑战。 我们在NS3平台上进行了实验,并探讨了基于RL的CC算法和传统CC算法的性能。 在NS3平台中,与RL算法相关的计算过程与管道中的数据传输分离。 因此,RL算法的计算复杂度对网络通信没有影响。
在下面的章节中,我们比较了算法、性能度量和网络环境。
A 比较算法
在仿真中,选取了三种RL算法:DQL、DDPG和PPO作为RL算法的典型实例。一般来说,DQL是这三种算法中最简单的一种,因此它适用于相对简单的环境。 DDPG和PPO具有更强的学习能力,因此它们可以应用于更复杂的场景。考虑到我们的网络环境的有限复杂性,这三种算法预计将执行类似的操作。 为了将它们与基准算法进行比较,选择了New Reno,这是一种经典的传统CC算法,也是NS3的默认CC算法。 表IX总结了这四种算法。
| 技术 | 应用场景 | 机制 | 优点 | 缺陷 |
|---|---|---|---|---|
| DQL | 有线/无线网络,NDN | 基于神经网络的输入状态和输出动作值 | 具备解决大规模RL问题的能力 | 不能保证网络的收敛性 |
| DDPG | MPTCP在卫星通信中的应用 | 结合DQL和AC算法,由两个Actor网络和两个Critic网络组成。 此外,他们在每一步都采用确定性政策 | 在连续动作空间中获得良好的性能并快速收敛 | 不适合随机环境 |
| PPO | 互联网服务,如现场视频,虚拟现实和物联网 | 提出一个新的目标函数,可以用多个训练步骤进行小批量更新,解决了策略梯度算法中步长难以确定的问题 | 保证收敛性和性能 | 策略更新的速度与策略梯度的方向有关,忽略了策略参数的空间结构。因此,培训政策的速度可能会很慢 |
| NewReno | 有线网络 | 由慢启动,拥塞避免,重传和快速恢复四部分组成 | 避免慢启动过程的低效和保证吞吐量 | 无法主动确定拥塞并预测丢包 |
1) 基于DQL的拥塞控制算法:与Q学习或Sarsa将状态看作离散有限集不同,DQL可以处理大规模问题。 在DQL算法中,值函数由卷积神经网络(CNN)、递归神经网络(RNN)和长期短期记忆(LSTM)等神经网络表示。对于DQL算法的价值函数,主要有两种方法。 一种方法使用状态和动作作为输入,从神经网络中得到动作值作为输出。另一种方法是,状态是输入,动作和相关动作值是输出。 这两种方法意味着动作空间提供了有限数量的离散动作。 由于DQL通过神经网络逼近值函数,所以DQL可以解决大规模问题。 然而,DQL有一个问题,因为它不一定保证Q网络的收敛性。 因此,收敛后可能无法得到Q网络参数。这将导致一个训练不足的模型。 然而,在网络领域,DQL仍然表现出高性能,特别是在处理复杂网络时。
TCP-Drinc是一种高效的基于RL的CC算法,它使用与LSTM网络连接的深度CNN来学习历史数据。 它可以确定下一个动作,然后调整CWND大小。LSTM适用于处理和预测具有很长时间间隔和时间序列延迟的重要事件。在Drinc中,LSTM用于处理由延迟和相关信息引入的时间序列内的自相关。 因此,DQL框架具有较强的鲁棒性,具有较好的学习能力。此外,Drinc是为多智能体网络设计的,可以处理各种网络条件[34]。
与其他深度RL相比,DQL相对简单,具有处理相对简单网络的能力。 除了收敛问题外,DQL是有前途的,因为模型更轻量化。
2)基于DDPG的拥塞控制算法:DDPG是AC算法的优化版本,可以快速收敛并且性能良好。 为了更好地理解DDPG算法,先引入AC算法。
演员评判家算法是基于策略梯度方法的,是一种基于策略的RL算法。 对于基于价值的RL算法,如Q学习和DQL,这些方法通常只处理离散的动作,因此它们不能处理连续的动作,也不能解决随机问题。因此,需要涵盖这些方案的新方法,例如基于策略的方法。在基于值的方法中,值函数是近似值,用于基于状态输入和关联的操作来计算操作值。在基于策略的方法中,该算法采用了类似的方法,但却近似于策略。
演员评判家算法将基于策略的方法和基于价值的方法结合起来。演员(Actor)部分用于近似策略函数,并负责生成与环境交互的操作。 给定一个策略函数πθ(s,a),使用批评部分来逼近值函数并评估下一阶段参与者的表现。 最常用的策略函数是Softmax策略函数。 主要用于离散空间。Softmax策略使用描述状态和参数θ的特征(ψ(s,a))的线性组合来衡量行为发生的概率。 给定函数为:
∏ θ ( s , a ) = e ψ ( s , a ) T θ ∑ b e ( s , b ) T θ ( 2 ) \prod_{\theta} (s,a) \quad = \quad \frac{e^{\psi(s, a)^T\theta}}{\sum_be(s,b)^T\theta} \quad\quad\quad\quad\quad\quad\quad(2) θ∏(s,a)=∑be(s,b)Tθeψ(s,a)Tθ(2)
通过推导得到相应的得分函数,如下所示:
∇ θ l o g ∏ θ ( s , a ) = ψ ( s , a ) − E ∏ θ ψ ( s , a ) ( 3 ) \nabla\theta log \prod_{\theta} (s,a) \quad = \quad \psi (s, a) - E_{\prod_{\theta}} \psi(s, a) \quad(3) ∇θlogθ∏(s,a)=ψ(s,a)−E∏θψ(s,a)(3)
策略更新参数的函数为θ:
θ = θ + α ∇ θ l o g p r o d θ ( s t , a t ) v t ( 4 ) \theta \quad = \quad \theta \quad + \quad \alpha\nabla_{\theta} logprod_{\theta}(s_t,a_t)v_t \quad \quad \quad(4) θ=θ+α∇θlogprodθ(st,at)vt(4)
其中vt是给定状态st和动作at的Q值。评判家单元,指的是基于DQL的CC算法在更新Q学习参数之前,采用Q学习作为评判家并获得动作值。演员评判家算法利用了两种主流的RL算法,但它们很难收敛,因为有两个神经网络相互关联,并且都需要对梯度进行更新。
基于演员评判家的CC算法的早期版本是为基于路由的算法设计的。在文献[78]中可知,该算法是针对ATM网络中的多媒体业务,通过深层神经网络设计的。结果表明,该算法通过减少损失和延迟[94],实现了较高的语音/视频质量。后来,一种基于AC的算法被用作多路径CC的有效技术。与基于DQL的算法相似,所提出的基于AC的算法集成了LSTM来表示状态动作空间。仿真结果表明,该算法对具有连续作用空间的网络具有较强的灵活性,并且对传统的CC算法具有较好的性能[85]。
[94]Reinforcement learning congestion controller for multimedia surveillance system
基于AC的CC算法提供了先进的探索,这些探索并不总是稳健的。这种算法的性能取决于两个神经网络的相互作用。这需要进一步的研究来保证它们的收敛性和整体效率。
DDPG是RL算法中处理AC收敛问题的另一类别。它采用经验回复和双网络。一方面,与传统的策略梯度算法相比,DDPG输出的是确定性策略,而不是随机策略。传统的策略梯度算法基于随机策略梯度计算梯度。另一方面,DDPG采用双演员网络和双评判家网络。对于双演员网络,一个负责更新策略参数,另一个基于从经验回放数据集的采样来选择下一个操作。对于双评论家网络,一个更新与Q值相关的参数,另一个计算Q值。在卫星通信中,设计了一种基于DDPG的算法来处理多路径CC问题,取得了很高的效果[41]。
如上所述,与DQL相比,DDPG在更复杂的环境中具有更强的训练模型的能力。然而,DDPG还存在其他问题,使其不适合于随机环境。此外,训练DDPG模型可能更困难。
3)基于PPO的拥塞控制算法:PPO是一种基于AC方案的深度RL算法。使用PPO来解决传统策略梯度法不足以确定学习速率或步长的问题。如果步长太大,策略将继续移动,不会收敛。然而,如果步长太小,则比较耗时。为了解决这个问题,PPO利用新旧策略之间的比率来限制新策略的更新范围,使策略梯度对稍大的步长不太敏感。为了实现这一点,PPO使用自适应惩罚来控制策略的变化。这样,PPO提供了一种优化的AC算法,并提高了收敛效率。
为了适应可变的网络环境,如可变的链路流和端到端时延,PPO被提出为RL引导的CC算法[95]。被设计出的算法Aurora就利用PPO生成高效的学习策略,保证学习过程稳定。仿真结果表明,该算法通过生成最优策略,在不同的环境下优于传统的CC算法。
PPO已被证明是一种杰出的深度RL方法,与CC的结合显示了PPO在广泛的网络应用中的潜力。然而,还存在一些挑战,如训练与参数结构相关的策略的速度。因此,PPO的训练效率可能是一个重要问题。
4) NewReno:NewReno是一种基于Reno的基于损失的CC算法。它提供了一个缓慢的开始,拥塞避免,重传和快速恢复。与经典的CC算法相比,New Reno修改了快速恢复部分。在Reno的快速恢复中,发送方在收到新的ACK后退出快速恢复状态。在New Reno中,只有在所有消息都被确认后,它才进入快速恢复状态。因此,TCP将一次拥塞中丢失多个数据包的情况与多个拥塞场景区分开来,然后在每次拥塞发生后只将CWND减半一次,从而提高了健壮性和吞吐量。在我们的实验中,NewReno算法被用作传统CC算法的代表。
B 性能度量
从文献的中可知,网络关心吞吐量、RTT和丢包率等关键参数。因此,在我们的实验中,我们的性能指标集中在吞吐量、RTT和丢包率上。吞吐量计算在给定的时间单位中成功传输的数据量,以Mbps为单位测量。RTT根据平均RTT以秒为单位测量从发送方到接收方的数据传输时间。丢包率计算给定时间间隔内丢包率。
C 网络环境
1)互联网:所有模拟采用相同的网络拓扑,包括相同的哑铃拓扑,具有相同的访问延迟和带宽。为了模拟不同的网络环境,瓶颈带宽和瓶颈延迟是不同的。基于之前的研究,基于学习的CC算法更适合于高速网络,如卫星通信网络[25]、ATM网络[68]和具有时变流量的网络[84]。我们推测基于学习的CC算法适用于高BDP(带宽延迟积)的网络,因为它们更积极地利用更高的BDP。BDP可以作为衡量网络的一个关键参数,并且它也用于控制BBR中的拥塞[96]。因此,我们设计了三个场景,如表X所示,比较了新Reno算法和基于RL的CC算法的性能。
| 场景 | 实验环境 | BDP |
|---|---|---|
| 场景一 | 接入带宽:1000M 接入时延:0.01ms 瓶颈带宽:5秒内由100M变为140M(瓶颈带宽每秒增加10M) 瓶颈时延:2.5ms |
高 |
| 场景二 | 接入带宽:1000M 接入时延:0.01ms 瓶颈带宽:15秒内由10M变为50M(瓶颈带宽每秒增加10M) 瓶颈时延:25ms |
高 |
| 场景三 | 接入带宽:1000M 接入时延:0.01ms 瓶颈带宽:5秒内由10M变为50M(瓶颈带宽每秒增加10M) 瓶颈时延:2.5ms |
低 |
[96]BBR: congestion-based congestion control
在这些场景中,哑铃形网络中有两个发送器和两个接收器。接入带宽为1000Mbps,接入延时0.01毫秒。在我们的实验中,高BDP和低BDP是相对的,而不是绝对的。在场景一中,BDP高,瓶颈带宽也高。然而,瓶颈延迟较低。在场景二中,BDP高,但瓶颈带宽低,瓶颈延迟高。在场景三中,BDP较低,瓶颈带宽和瓶颈延迟也较低。
在场景一中,瓶颈延迟设置为2.5毫秒。瓶颈带宽在5秒内从100M变为140M。更具体地说,瓶颈带宽最初是100M,每秒增加10M,最多增加140M。
在方案二中,瓶颈延迟设置为25毫秒。瓶颈带宽在15秒内从10M变为50M。每隔三秒,瓶颈带宽增加10M。 由于瓶颈延迟较长,与场景一相比,场景二需要更多的模拟时间。这允许观察不同CC算法的性能。
在场景三中,瓶颈延迟设置为2.5毫秒,瓶颈带宽在5秒内从10M更改为50M,即。 每秒钟瓶颈带宽增加10M。
2)状态:状态在不同的研究方法上往往各不相同。在基于DQL的CC算法中,状态主要集中在CWND差异、RTT和ACKs的到达时间上[34]。在基于AC的多智能体CC中,状态是基于缓冲区长度和发送速率[84]的。在A3C框架中,状态基于吞吐量、损失和RTT[32]。在基于DDPG的自学习CC算法中,状态是基于CWND、RTT、ACK和子流[97]的累积重传速率数。在PPO中,状态分为三个部分:延迟梯度、延迟比和发送比[95]。很明显,没有必然的规则支持基于RL的CC算法。根据前人的文献,状态被用来处理两个关键领域:RTT、丢失、ACK、吞吐量以及用于控制拥塞的参数,如CWND大小和发送速率。在CC算法中,环境根据拥塞信号调整发送速率或CWND大小。
[97]Self-learning congestion control of MPTCP in satellites communications
考虑到性能指标的重点,这里考虑的状态是吞吐量、RTT、丢包率。
3)行动:在模拟中,所有调整都是基于窗口的。通过调整CWND大小,有不同的规则被应用。在[80]中,有四个动作:-1, 0, +1, +3。当动作为-1时,CWND将减少一个分组大小。在[36]中,设计了三个动作:-1,0,+10。 增加的动作更具攻击性(最多10个)。在文献[75]中,动作空间要大得多。七个动作是预定义的:+1,*1.25,*1.5,0,-1,*0.75,0.5。当动作为1.25时,新的CWND的大小是原来CWND的1.25倍。在我们的实验中,我们考虑了四个动作:-1,0,+1,+3,与[80]对齐。
4)奖励:与状态类似,奖励也可以有不同的定义。在基于DQL的CC算法中,奖励的效用函数定义如下[75]所示:
U t i l i t y = α i ∗ l o g ( t h r o u g h p u t ( t ) ) − β i ∗ R T T i ( t ) − γ i ∗ l o s s i ( t ) − δ ∗ r e o r d e r i n g i ( t ) ( 5 ) Utility = \alpha_i * log(throughput(t)) - \beta_i * RTT_i(t) - \gamma_i * loss_i (t) - \delta * reordering_i (t) (5) Utility=αi∗log(throughput(t))−βi∗RTTi(t)−γi∗lossi(t)−δ∗reorderingi(t)(5)
在基于PPO的CC算法[95]中,效用函数定义如下:
U t i l i t y = 10 ∗ t h r o u g h p u t − 1000 ∗ l a t e n c y − 2000 ∗ l o s s ( 6 ) Utility = 10 * throughput - 1000 * latency - 2000 * loss (6) Utility=10∗throughput−1000∗latency−2000∗loss(6)
在一个基于A3C的算法[32]中,实用函数被给出为:log(吞吐量/RTT)。在基于DDPG的算法中,效用函数更复杂[97]并给出如下:
U t i l i t y = ∑ i ( α C W N D t − β r t t t − ϵ r t a t − k a c k t ) ( 7 ) Utility = \sum_i(\alpha CWND_t - \beta rtt_t - \epsilon rta_t - k ack_t) \quad(7) Utility=i∑(αCWNDt−βrttt−ϵrtat−kackt)(7)
要定义奖励,首先应该定义模拟的目的。奖励用于反馈给定当前状态的动作。利用这一点,它衡量动作的表现。因此,奖励是动作表现的反映。由上可知,奖励的定义包括吞吐量,时延和丢包率。考虑到这些因素,奖励包括RTT和吞吐量。效用函数如下所示,其中效用奖励的值是基于[75]的。方程中的bandwidth表示瓶颈带宽。MinRTT是指管道的最小RTT。最小RTT是指管道的最小RTT。
U t i l i t y = l o g ( t h r o u g h p u t / ( b a n d w i d t h ) ) − l o g ( R T T − M i n R T T ) + l o g ( 1 − p ) ( 8 ) Utility = log(throughput / (bandwidth)) - log(RTT - MinRTT) + log(1 - p) \quad (8) Utility=log(throughput/(bandwidth))−log(RTT−MinRTT)+log(1−p)(8)
在这一部分中,我们给出了四种算法的模拟结果:传统的CC算法NewReno和基于RL的CC算法、DQL、DDPG和PPO。模拟是在NS3平台上进行的。
在前人研究的基础上,考虑的状态空间包括五个参数:吞吐量、RTT和丢包率。给定的奖励函数为log(throughput / bandwidth) ) - log(RTT - MinRTT) +
log(1 - p)。一旦新的ACK到达,该操作用于调整CWND。本网络采用哑铃型网络拓扑结构。
A 仿真结果
总体模拟结果如表XI和图8-30所示,包括显示性能变化的时间轴图、显示性能平均值和方差的条形图以及显示性能粗略分布的累积分布函数(CDF)图。
| 场景 | BDP | CWND | 吞吐量 | RTT | 丢包率 |
|---|---|---|---|---|---|
| 场景一 | 高 | 大幅增加 | 大幅增加 | 有限增加 | 有限增加 |
| 场景二 | 高 | 大幅增加 | 大幅增加 | 有限增加 | 有限增加 |
| 场景三 | 低 | 没什么区别 | 没什么区别 | 没什么区别 | 有限增加 |



为了检验基于RL的CC算法在现实网络中的性能,我们使用Python构建套接字(Socket),并使用Linux平台发送真实数据。结果表明,ACK间隔受算法计算复杂度的影响。如图12所示,基于RL的CC算法的ACK间隔比NewReno大得多,导致CWND的速度增长缓慢。由于基于RL的CC算法需要相当长的时间来计算和获得动作,ACK将不会及时转移。值得注意的是,即使在基于RL的CC算法中,也存在差异。此外,延迟的ACK会影响实际吞吐量和RTT的测量。因此,基于RL的CC算法可能不适用于现实网络。
为了比较基于RL的CC算法和New Reno算法的性能,我们给出了基于NS3的输出,其中排除了RL算法引起的延迟。在下面的部分中,将讨论详细的性能,包括CWND和性能度量。
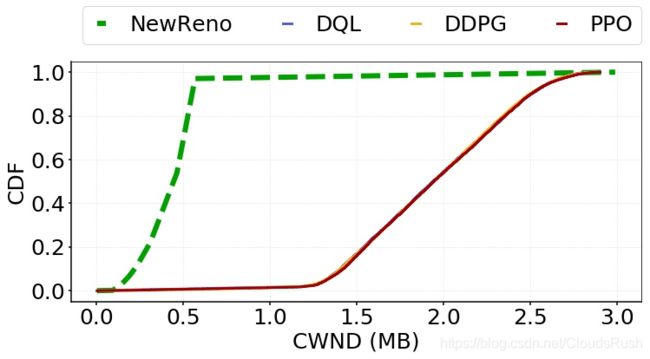
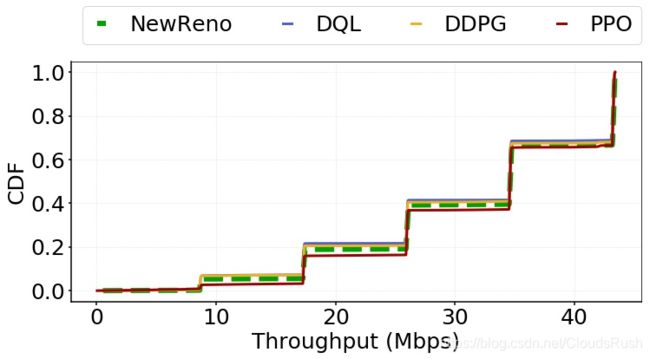
1)CWND:在三种基于RL的CC算法中,它们在三种场景中的差异最小,如图8所示。此外,我们还观察到,在场景一和场景二中,基于RL的CC算法的CWND的大小远远大于基于规则的CC算法,这两种算法都具有很高的BPD。而在场景三中,这四种算法之间没有太大的区别。从图13到图15,CDF图显示了CWNDs在三种情况下的分布。正如预期的那样,在场景一和场景二中,当应用基于RL的CC算法时,CWND的大小往往更大。


2) Throughput:理论上,基于RL的CC算法的吞吐量预计将超过NewReno的吞吐量,这是由于在场景一和场景二中基于RL的CC算法的CWND平均值增加。如图9所示,我们的推测得到了验证。 在场景一和场景二中,当使用基于RL的CC算法时,吞吐量得到了提高。而在场景三中,基于RL的CC算法没有优势。对于吞吐量的详细分布和时间表,从图16到图21的更多数字增加了结果和解释。

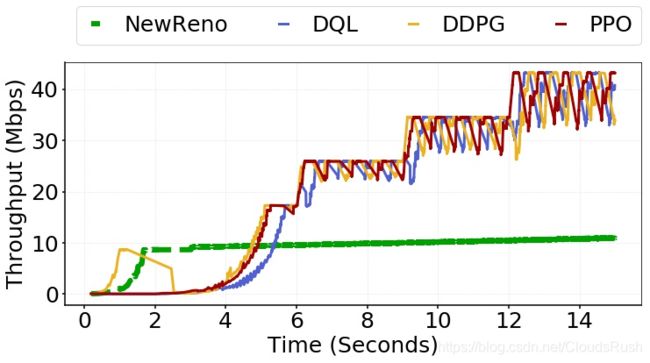



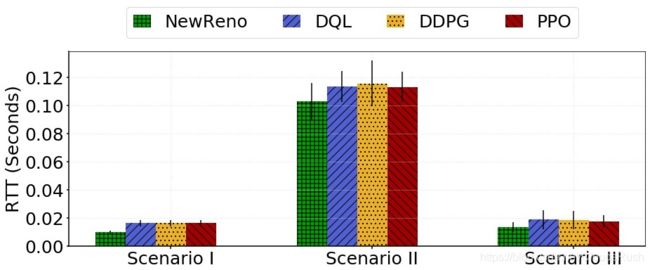
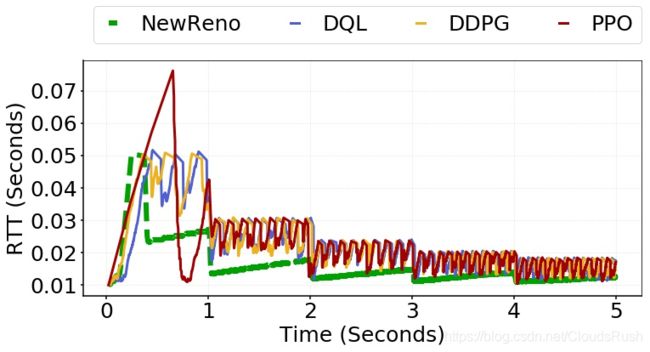
3) RTT:NewReno的RTT小而稳定,代表了RTT的基准。 在三种情况下,与NewReno相比,RTT在基于RL的CC算法的网络中更高,如图10、25、26、27所示。由于基于RL的CC算法中CWND的增加更具有攻击性( aggressive),因此RTT更高是可以理解的。然而,从图22到24,它表明RTT的增量与场景一和场景二中的吞吐量增量相比是有限的和有界的。





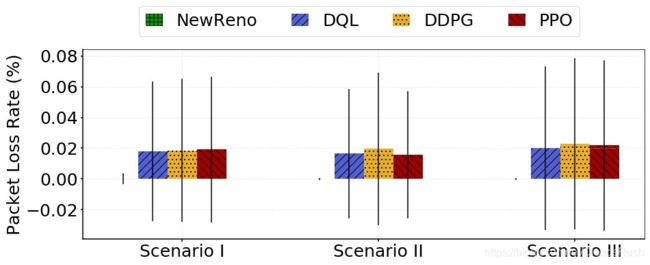
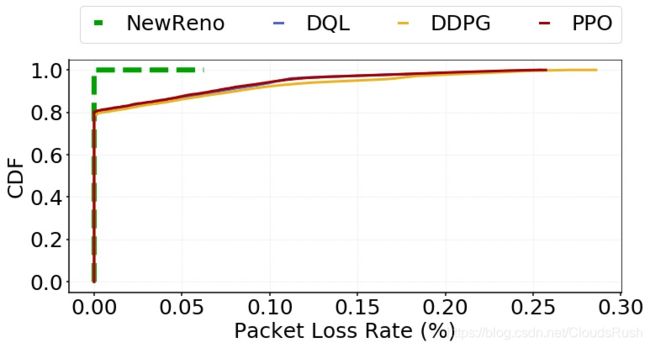
4)分组丢失率:如图11所示,NewReno的丢包率几乎为零,而基于RL的CC算法的网络中的丢包率最小。此外,从图28到图30,分布信息显示了基于RL的CC算法中丢包率的增加。考虑到基于RL的CC算法的攻击性,有界分组丢失是可以理解的。


B 结果分析
从仿真结果可以看出,在BDP相对较高的网络中,基于RL的CC算法可以在有限增加RTT和丢包率的情况下实现高吞吐量。此外,在我们的网络环境中,三种基于RL的CC算法表现出相似的性能。由于空间复杂度不高,动态波动有限,这三种算法很好地处理了这些场景。因此,我们的实验表明,基于RL的CC算法在高BDP网络中具有优势(用NS3进行模拟)。
在现实网络中,CC算法对ACK到达时间做出反应。当新的ACK出现时,该算法检测网络中的延迟或丢失,然后调整CWNDs或发送速率。对于传统的CC算法,由于调整规则是预先设计和稳定的,因此计算动作的时间成本很小,而基于RL的CC算法需要大量的时间来输入 神经网络的状态;得到输出;更新操作值,然后采取适当的操作。这个过程显然非常耗时,尤其是对于ACK传输速率的潜在大小。因此,基于RL的CC算法很难测量ACK的实际传输时间,几乎不可能测量实际网络吞吐量、RTT和丢包率。在NS3平台上,这些问题没有被揭示,因为NS3平台将计算和传输部分分开。因此,无论算法多么耗时,对ACK传输都没有影响。然而,在现实世界的应用中,必须考虑这样的时间。因此,虽然基于RL的CC算法适用于NS3平台,但它们仅限于现实环境。
C 提倡的解决办法
根据仿真结果和分析,可以观察到目前基于RL的CC算法基于ACKs的到达处理奖励,这些奖励是逐个转移和接收的。如前所述,这些基于RL的CC算法在NS3模拟器上是可行的,该模拟器将计算和ACK传输分开,但是基于RL的CC算法的实现仍然是一个问题。因此,有几个可能的未来研究趋势。
首先,设计基于映射表的较轻模型,以解决基于RL的CC算法耗时的问题。在网络模拟器中训练基于RL的模型后,它可以将状态和动作保存到表中。因此,可以提前准备一个映射表。这个过程可以离线完成。模型部署时,只使用映射表。给定网络环境的状态,根据映射表给出动作。这个过程的时间比较小。这种方法既高效又省时。然而,也存在一些挑战。在连续场景中,简单的映射表可能很大,也很笨拙。因此,可以探索更有效的映射表来解决这些限制。
另一个解决方案是减少决策的频率,例如使用RL在给定的时间间隔内选择CC算法,而不是根据ACK到达间隔选择CWND大小。这意味着更新的时间间隔远大于计算RL引起的延迟。因此,延迟的影响可以忽略不计。当然,缺点是RL算法的更新速度和响应速度会更慢。为了平衡这两个绩效问题,需要进一步的研究。
最后,由于异步RL算法的计算复杂度,需要对延迟ack进行处理。在异步RL框架中,有多个参与者(actors)。这些参与者异步生效,这可以消除延迟ACK的影响。因此,在网络线程中,ACK不会被RL代理线程阻塞。在[98]中,为了处理奖励的延迟,一个操作生成几个部分操作。因此,每个部分动作都可以独立地与网络环境交互。此外,在[99]中还使用异步RL训练框架TorchBeast与 Pantheon网络模拟器相结合来处理延迟动作。提出的算法MVFST-RL基于多个异步动作,将现实网络通信中的网络传输代理和RL代理分离开来。虽然该算法消除了延迟动作的影响,但由于训练对象多,状态空间比基于RL的同步CC算法大,因此训练过程对资源的要求很高。因此,培训过程比较困难。 需要更多的研究来解决这个问题。
[98]Rax: Deep reinforcement learning for congestion control
[99] Mvfst-rl: An asynchronous rl framework for congestion control with delayed actions arXiv preprint arXiv:1910.04054, 2019.
8 基于学习的拥塞控制方案的挑战和趋势
A 基于学习的拥塞控制方案的挑战
对于基于规则的CC算法,主要问题是及时检测拥塞,快速反应。这种算法的挑战是处理灵活性。单一算法难以满足不同场景。对于基于学习的CC算法,灵活性得到了提高,但也存在一些需要解决的问题。
参数选择对性能有很大影响,特别是RL算法。状态空间,动作空间,奖励设计等与算法结构相关的超参数需要仔细考虑。以奖励设计为例。在基于RL的CC算法中,吞吐量和RTT被用来计算奖励。在其他基于RL的CC算法中,在计算奖励时考虑丢包率和延迟。对于监督学习,预定义的参数决定了影响CC性能的潜在分类错误。对于无监督学习算法,聚类群数目和初始聚类中心等参数会影响最终的聚类结果。因此,优化参数是一种非平凡的活动。
高计算复杂度是基于学习的CC算法的一个重要问题。对于监督学习技术,特别是boosting和bagging等混合和复杂的方法,预测精度可以非常高,但计算复杂度也可能很高。对于RL算法,计算复杂度会导致延迟动作和奖励。这影响到带宽的利用。
高内存消耗也需要考虑。基于RL的CC算法的训练需要相当大的存储空间,特别是对于连续的网络环境。因此,为了有效的训练过程,需要抽象出状态-动作空间并获得有代表性的数据。例如,使用LSTM[85]和Kanerva编码[86]来表示和抽象网络状态。一些先进的RL框架,如DDPG[97]和A3C[98]具有很强的能力,通过使用复杂的神经网络表示状态-动作空间来处理连续的网络环境。 因此,提取代表性状态是关键。目前,巨大的空间表示是复杂场景的主要限制。
低培训效率与部署的可行性有关。对于基于学习的CC算法,训练过程可能是时间和资源消耗。状态抽象对于提高训练效率很重要。最优参数选择也有助于提高训练效率。解决这个问题需要更多的研究。目前基于学习的CC算法需要大量的训练数据来保证基于仿真的性能。然而,虽然可以模拟不同的网络拓扑和流量,但算法并不总是能避免过拟合和欠拟合问题。
硬收敛性影响基于RL的CC算法。考虑到具有多个神经网络的复杂算法,很难达到收敛。目前的RL算法提出了不同的方法来促进收敛,但是对于现实的网络,这并不总是能保证的。
不相容是一个有待未来研究的未决问题。当前基于学习的CC算法通常被用作内置组件或独立控制器来控制拥塞。基于学习的CC算法与传统的CC算法之间的兼容性问题还有待解决。
B 基于学习的拥塞控制算法的发展趋势
考虑到上述基于学习的CC算法相关的问题,有几个趋势应该考虑。
首先,由于RL算法具有较高的在线性能,与基于RL的CC算法相关的工程问题是一个关键的研究课题。基于以往的文献,大多数基于RL的CC算法都是基于网络模拟器的仿真。一方面,网络仿真器的仿真消除了不相关的因素,更适合于网络场景的设计。另一方面,工程问题可以被忽略,例如。 参数选择和计算复杂度。在现实的网络通信中,这些工程问题对于基于RL的CC算法是非常重要的。为了设计更适用的算法,在现实的网络环境中进行模拟将是前进的主要焦点。
此外,基于轻量级学习的CC算法将是未来的研究热点。实现基于轻量级学习的CC算法需要鲁棒性的领域知识。目前基于学习的CC算法具有很高的复杂性,需要相当长的时间来决策,对内存和存储有很大的要求。因此,基于轻量级学习的CC算法需要更适用和可部署。为了使模型更轻,支持模型驱动技术的领域知识看起来很有前途。与传统的CC算法(包括不同场景下的RTT分布和重新排序方案)等传统CC算法的坚实基础相比,现有的基于学习的CC算法相对粗糙,知识支持有限。基于学习的CC算法需要一个完整和详细的状态空间来训练模型,使模型变得更重。需要使用较少的最佳选择参数的轻量级模型。
最后,需要一个开放的网络平台来提供大规模差异化的动态网络场景,以支持各种基于学习的CC算法的探索和评估,以促进基于学习的CC算法的进一步研究。Pantheon[?] 属于这种平台。虽然该平台涵盖不同的节点,但没有提供专业和特定的网络环境,例如灵活的自组织无线网络。因此,需要一个通用的平台,提供一个专业和实际的模拟环境来训练基于学习的CC算法。这样,基于学习的算法的发展就会更快。
9 总结
由于传统CC算法在动态网络中的局限性,基于学习的CC算法在学术界已经出现了一种新的趋势。本文综述了基于学习的CC算法的研究现状,并以学习型CC算法为代表,对不同的基于RL的CC算法进行了仿真研究。仿真结果表明,与传统的CC算法相比,基于RL的CCs算法在高带宽、低时延的网络环境下具有更好的性能。我们介绍并讨论了目前基于RL的CC算法在实际部署中的局限性,并概述了一些可用于未来研究的方法。我们确定了与基于学习的CC算法相关的挑战和趋势,包括处理与基于RL的CC算法相关的工程问题。在未来,网络环境预计将越来越复杂。有鉴于此,显然需要处理这种复杂性和灵活性。为了提高系统的性能和鲁棒性,需要进一步研究如何处理计算时间、数据存储和预先设计的参数等问题。我们认为,需要具有通用学习平台的轻量级和高效的基于学习的模型,并将成为未来的研究重点。