天池龙珠计划_金融风控训练营——Task1 赛题理解学习打卡
天池龙珠计划_金融风控训练营
天池龙珠计划_金融风控训练营链接
Task1 赛题理解学习打卡
目录
- 天池龙珠计划_金融风控训练营
-
- Task1 赛题理解学习打卡
- 1. 赛题总览
- 1.1赛题概要
- 1.2 赛题数据
-
- 1.2.1 数据预览
- 2. 评价指标
-
- 2.1 AUC
- 2.2 AUC面积的由来
- 3.学习心得体会
- 参考文献
1. 赛题总览
1.1赛题概要
- 比赛题目:零基础入门金融风控之贷款违约预测挑战赛
- 题目背景:以金融风控中的个人信贷为背景
- 赛题目标:要求选手根据贷款申请人的数据信息预测其是否有违约的可能,以此判断是否通过此项贷款
- 赛题意义:通过这道赛题来引导大家了解金融风控中的一些业务背景,解决实际问题,帮助学生们进行自我练习、自我提高
1.2 赛题数据
#导入pandas
import pandas as pd
# 显示所有列,所有行
pd.set_option('display.max_columns', None)
pd.set_option('display.max_rows', None)
# 读取数据
train_data = pd.read_csv('train.csv')
test_data = pd.read_csv('testA.csv')
1.2.1 数据预览
train_data.head()
train_data.info()
test_data.info()
train_data.isnull().sum()
test_data.isnull().sum()
训练集和测试集中在相同的变量数据上都存在null值
print('数据集维度:')
print('Train data shape:',train_data.shape)
print('Test data shape:',test_data .shape)
数据集维度:
Train data shape: (800000, 47)
Test data shape: (200000, 46)
从数据集维度中可以看出
- 训练集中共有80w条数据,47列变量数据
- 测试集中共有20w条数据,46列变量数据
- 测试集中少了一列变量数据
list1=train_data.columns.tolist()
list2=test_data.columns.tolist()
print('训练集多了',set(list1).difference(set(list2)),'变量数据')
#训练集多了 {'isDefault'} 变量数据
2. 评价指标
由于本次比赛采用的评价指标为AUC,因此对与AUC指标的学习十分必要.
2.1 AUC
AUC(Area Under Curve)被定义为ROC曲线下与坐标轴围成的面积,显然这个面积的数值不会大于1。
又由于ROC曲线一般都处于y=x这条直线的上方,所以AUC的取值范围在0.5和1之间。
AUC越接近1.0,检测方法真实性越高;等于0.5时,则真实性最低,无应用价值。
因此AUC更大的分类器效果更好
从AUC 判断分类器(预测模型)优劣的标准:
- AUC = 1,是完美分类器。
- AUC = [0.85, 0.95], 效果很好
- AUC = [0.7, 0.85], 效果一般
- AUC = [0.5, 0.7],效果较低,但用于预测股票已经很不错了
- AUC = 0.5,跟随机猜测一样(例:丢铜板),模型没有预测价值。
- AUC < 0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测。
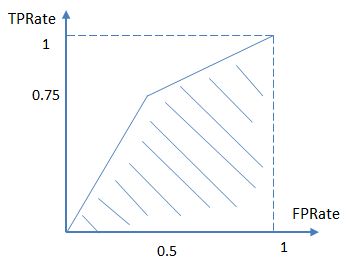
图中阴影部分为AUC得分
## 绘制ROC曲线
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import roc_curve ,roc_auc_score
y_pred = [0, 1, 1, 0, 1, 1, 0, 1, 1, 1]
y_true = [0, 1, 1, 0, 1, 0, 1, 1, 0, 1]
FPR,TPR,thresholds=roc_curve(y_true, y_pred)
plt.title('ROC')
plt.plot(FPR, TPR,'b')
plt.plot([0,1],[0,1],'r--')
plt.ylabel('TPR')
plt.xlabel('FPR')
# 获取AUC得分
print('AUC socre:',roc_auc_score(y_true, y_pred))
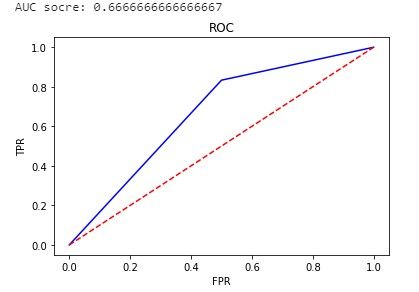
2.2 AUC面积的由来
如果两条ROC曲线没有相交,我们可以根据哪条曲线最靠近左上角哪条曲线代表的学习器性能就最好。但是,实际任务中,情况很复杂,如果两条ROC曲线发生了交叉,则很难一般性地断言谁优谁劣。
在很多实际应用中,我们往往希望把学习器性能分出个高低来,在此引入AUC面积。
在进行学习器的比较时,若一个学习器的ROC曲线被另一个学习器的曲线完全“包住”,则可断言后者的性能优于前者;若两个学习器的ROC曲线发生交叉,则难以一般性的断言两者孰优孰劣。
如果一定要进行比较,则比较合理的判断依据是比较ROC曲线下的面积,即AUC(Area Under ROC Curve)。
3.学习心得体会
从本次训练营的Task1学习中,我理解了该次赛题的目的与意义,通过AUC的定义我们知道了AUC是什么,怎么算,以及其的含义.
从本次赛题数据中可以得知该问题是一个二分类问题,利用AUC进行评价,因为AUC是衡量二分类模型优劣的一种评价指标,表示预测的正例排在负例前面的概率。
此外数据中特征较多,因此如何利用这些特征是一个关键点,因此特征工程的处理非常重要,也是影响最终数据结果的关键步骤.
因此对于金融知识以及数据之间的关系需要做好准备工作.
参考文献
如何理解机器学习和统计中的AUC?
AUC百度百科
模型评估指标AUC(area under the curve)