Pytorch基本知识与MNIST数据集
Pytorch基本知识
PyTorch和TensorFlow是流行的神经网络架构。
在之前MATLAB构建BP神经网络的过程中,最麻烦的部分是通过微积分计算反向传播误差(back-propagated error)和网络权重(weight)之间的关系。每当网络结构需要改变时,我们很可能需要重新计算一次。
Pytorch可以帮助我们简化这一点,使用PyTorch来取代大部分的底层工作,我们就可以专注于网络的设计。
PyTorch最强大且最便利的功能之一是,无论我们设想的网络是什么样子的,它都能替我们进行所有的微积分计算。即使网络设计改变了,PyTorch也会自动更新微积分计算,无须我们亲自动手计算梯度(gradient)。
pytorch代码简单编写
import torch
x = torch.tensor(3.5)
print(x) #该变量的值是3.5000,同时它被包装在一个PyTorch张量中tensor(3.5000)
y = x + 3
print(y) #变量类型的一致性tensor(6.5000)
pytorch的自动求导机制
x = torch.tensor(3.5, requires_grad = True)
print(x)tensor(3.5000, requires_grad=True)
# y以x的函数表示
y = (x-1) * (x-2) * (x-3)
print(y) #PyTorch记录了y在数学上是由x来定义的tensor(1.8750, grad_fn=)
#计算梯度,不要重复执行
y.backward() #只有区区一行代码,但y.backward()完成了大量的工作x.gradtensor(5.7500)
一个PyTorch张量可以包含以下内容:
除原始数值之外的附加信息,比如梯度值。
关于它所依赖的其他张量的信息,以及这种依赖的数学表达式。
这种关联张量和自动微分的能力是PyTorch最重要的特性,几乎所有的其他功能都基于这一特性。
MNIST数据集
介绍
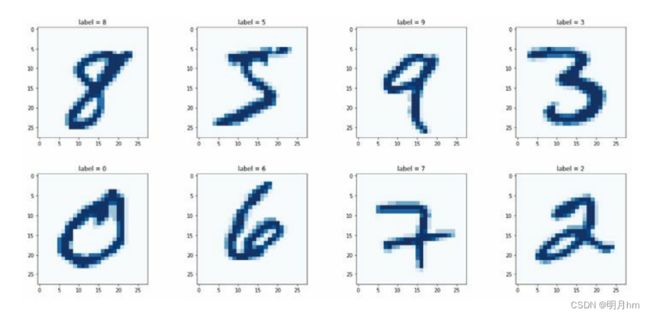
MNIST数据集是一组常见的图像,常用于测评和比较机器学习算法的性能。其中6万幅图像用于训练机器学习模型,另外1万幅用于测试模型。
这些大小为28像素×28像素的单色(monochrome)图像没有颜色。每个像素是一个0~255的数值,表示该像素的明暗度。
数据集下载
训练数据:https://pjreddie.com/media/files/mnist_train.csv
测试数据:https://pjreddie.com/media/files/mnist_test.csv
数据集处理代码:
# 导入pandas库,用于读取CSV文件
import pandas
df = pandas.read_csv('mnist_data/mnist_train.csv', header=None)
df.head() #使用head()函数查看一个较大DataFrame的前几行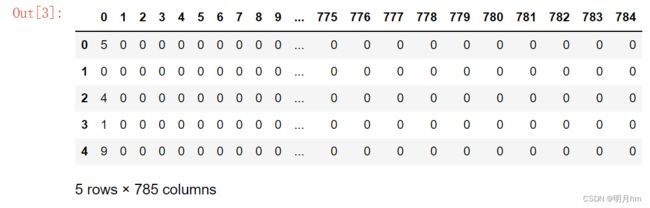
MNIST的每一行数据包含785个值。第一个值是图像所表示的数字,其余的 784个值是图像(尺寸为28像素× 28像素)的像素值。
df.info() #用info()函数查看DataFrame的概况。RangeIndex: 60000 entries, 0 to 59999 Columns: 785 entries, 0 to 784 dtypes: int64(785) memory usage: 359.3 MB
该DataFrame有60000行。这对应60000幅训练图像。同时,我们也可以确认每行有785个值。
通过绘图函数查看数据集中的具体图像
# 导入pandas库用于读取CSV文件
import pandas
# 导入matplotlib用于绘图
import matplotlib.pyplot as plt
# 从DataFrame读取数据
row = 6
data = df.iloc[row]
# 第一个值是标签
label = data[0]
# 图像是余下的784个值
img = data[1:].values.reshape(28,28)
plt.title("label = " + str(label))
plt.imshow(img, interpolation='none', cmap='Blues')
plt.show()