Training Shallow and Thin Networks for Acceleration via Knowledge Distillation with Conditional Adve
目录
一.Abstract
二、相关介绍
三、算法步骤
3.1带有残余连接的神经网络
3.2Knowledge distillation
3.3对抗网络的学习损失
student update
总结
一.Abstract
1.提出使用条件对抗网络学习损失函数,将知识从教师传递给学生(该方法对于规模较小的学生网络尤其有效)
2.研究了推理时间与分类准确率之间的权衡关系,并对选择合适的学生网络提出了建议
二、相关介绍
①学生网络和教师网络都是残余连接的卷积神经网络(CNNs)
②引入GAN中的鉴别器,网络可以自动学习良好的损耗来传递班级之间的相关性(即来自老师的暗知识),同时也保留了多模态

基于gan的师生策略的动机是:教师网络产生的软目标信息量更大,学习损失可以转移多模态知识
在对抗学习过程中,GAN训练两个神经网络:生成器与鉴别器,并交替更新这两个网络。
我们在条件设置中应用GAN,生成器以输入图像为条件。并且生成器与鉴别器需要选择完全不同的体系结构。
三、算法步骤
本节介绍基于条件对抗网络的学习损失方法
3.1概述现代网络框架
3.2描述可以从教师网络转移到学生网络的暗知识
3.3基于gan的学习损失方法
3.1带有残余连接的神经网络

卷积神经网络(左)和多层感知器(右)的残块。Al表示第LTH块的输出。每个块由批归一化(BN)、激活ReLU、权值层和退出组成。
3.2Knowledge distillation
用于图像分类的神经网络的输出是类别间的概率分布。该概率是通过在最后一个全连接层(也称为logits)的输出上应用一个softmax函数生成的。

3.3对抗网络的学习损失

知识通过一个鉴别器从老师传递给学生;
鉴别器用来区分输出日志是来自教师网络还是学生网络;
学生(生成器)被反向训练来欺骗鉴别器(即输出日志类似于教师日志,因此鉴别器不能区分)
①深度和广度的老师是预先训练的离线
②学生网络和鉴别器交替更新(鉴别器的目标是区分学生网络和教师网络的logits,学生的目标是欺骗鉴别器)
③对学生和鉴别器都添加了额外的监督损失
④在知识蒸馏中,性能对鉴别器结构的敏感性不如对温度参数的敏感性
鉴别器的使用,缓解了师生之间的刚性耦合。从教师的多模态日志中训练出的鉴别器可以捕获类别之间的相对相似性。从鉴别器转移来的知识指导学生产生类似于上面两个向量的输出,而不同于类似于(0.5,0.1,0.4)的向量。
student update
在每次迭代更新鉴别器后更新学生网络F(.)。目标:通过固定鉴别器D(.)和最小化损失LA来欺骗鉴别器。同时,对学生网络进行训练,以满足鉴别器Lds的辅助分类器
除Lds提供的类别级对齐之外,还将教师和学生输出之间的实例级对齐介绍为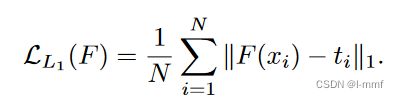
finally,最小化学生网络F(.)的以下目标
该式为知识蒸馏的学习损失与神经网络的监督损失的组合
实验表明,所提方法的性能对鉴别器架构相当不敏感,学习损失可以优于手工设计的知识蒸馏损失
总结
1.本文研究了网络加速的师生策略。提出了一种基于gan的学习损失的方法,将知识从老师传递给学生。研究表明,基于gan的方法可以提高学生网络的训练效果,尤其是在学生网络较浅、较薄的情况下。此外,我们还实证研究了采用现代网络作为学生时网络容量的影响,为合理选择学生以平衡错误率和推理时间提供了指导。在特定的环境下,我们可以训练一个比老师小7倍,快5倍的学生,而不会失去准确性。
2.在应用了GAN文献中的几种先进技术后,基于GAN的方法稳定且易于实现。目前的实现是利用从教师网络中存储的日志来节省GPU内存和计算量。动态生成辍学教师登录对对抗训练具有较高的可靠性。最后,基于gan的方法可以自然地扩展到使用网络集成作为教师。为了提高识别器的性能,可以将多个教师网络的日志输入识别器中。我们将在未来的工作中研究这些想法。