强化学习在图像分割上的新应用:协同分割
A Novel Image Co-Segmentation Algorithm with Deep Reinforcement Learning
单位:北京理工大学计算机学院北京智能信息技术实验室
作者:Xin Duan, Xiabi Liu, Xiaopeng Gong, Mengqiao Han
论文链接:https://arxiv.org/ftp/arxiv/papers/2204/2204.05951.pdf
1.Abstract
提出了一种基于深度强化学习的图像自动分割算法,现有分割的方法都是基于深度学习的方法,所得到的图像边缘是粗糙的,为了获得更精确的图像分割边缘,我们使用强化学习去解决这个问题,实现更精细的分割。这是首次将深度强化学习应用在图像协同分割上,我们将其定义为马尔可夫决策过程,并使用 Asynchronous advantage actor-critic(A3C)算法去训练网络。这个 RL 协同分割网络是利用一组相关图像来分割出共同和显著的目标,为了实现自动分割,我们的方法取消了用户提示(hints)。我们提出的 Siamese RL co-segmentation 网络 是为了获取协同分割图像之间的 co-attention。我们同时也改进了自注意力机制使其更适应 RL 算法去获得长距离感受域,增大感受域。
2.Method
利用深度学习的方法分割往往在边缘都是比较粗的轮廓,为了解决这个问题,我们使用深度强化学习方法来优化边缘粗糙分割问题。
该方法通过迭代的优化初始的粗糙分割概率图,来得到更准确的分割结果。初始的概率分割图可以通过任何方法得到。本文使用 Lee C, Jang WD, Sim JY, Kim CS (2015) Multiple random walkers and their application to image中的方法。在每个迭代步骤中,模型将上一次迭代输出的分割概率图和和原始图像连接,将他们输入到 Siamese network 中获得联合特征图。 Siamese network 根据联合特征图输出 actions 去调整分割概率图的每一个像素点的概率。actions 代表不同调整的概率值,如 { ± 0.05 , ± 0.1 , ± 0.2 , ± 0.5 } \{\pm0.05, \pm0.1,\pm 0.2,\pm0.5\} {±0.05,±0.1,±0.2,±0.5} 。
利用强化学习网络的作用调整每个像素位置的像素值以达到预期的图像处理效果的方法是由 Furuta (Furuta R, Inoue N, Yamasaki T. Fully convolutional network with multi-step reinforcement learning for image processing[C]//Proceedings of the AAAI conference on artificial intelligence. 2019, 33(01): 3598-3605. ) 等人首先提出的,并用于图像处理领域,如图像去噪.
在本文的方法中,首先提取初始分割图和原始图像的特征,然后根据联合特征映射来输入到 Deep reinforcement learning Siamese network 中获得概率调整的 action。为了获得一对图像的相关性,我们使用 correlation block 去计算他们的 co-attention,这个为 RL 方法提供了更多的相关信息。 两个图像将受到两个相关的图像环境影响,这个可以被看作是 A3C 算法。(因为 A3C 是异步的 A2C 算法,而在该模型中可以将其看作是异步的)。在本文的算法中,删去了在 RL 算法经常需要用户交互的步骤,它是 auto 的算法。不过为了弥补缺失的用户交互的信息,我们选择使用自注意力模块,并对其进行改进,使其更适合强化学习方法,获取更多的图像信息。将自注意力应用到分割的概率图中是使其对图像的目标区域进行聚焦,以便获得准确的动作和更精细的分割。
2.1 Correlated Reinforcement learning algorithm for co-segmentation
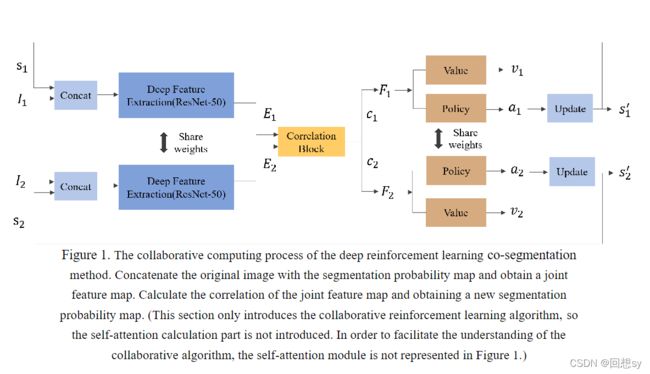
传统的 A3C 算法是针对相同环境下的对象的,agent 的action、state 和 reward 只受当前状态影响,对于 co-segmentation 问题,我们利用 A3C 算法同时处理两幅相关图像中的目标,并将每幅分割概率图看作一个 RL 环境。由于图像的相关性,相关图像环境的相关特征会影响两个分割概率图中主体的 action、state 和 reward 。因此我们使用的是相关的 A3C 强化学习算法。
为了获得一对图像之间的相关性,我们需要计算他们之间的 co-attention,co-attention 是指我们在一幅图像的编码特征中获得的共同注意力,用来指导另一幅图像中的注意力。
为了获得两对分割概率图和原始图像结合的特征图,我们使用 Siamese encoder 将它们映射到相同的特征空间。对于策略网络和价值网络,我们也采用了 Siamese structure,其中两个策略网络共享权重,两个价值网络共享权重。论文中利用 resnet50 提取原始图像和分割概率图的拼接图的深层特征,分别得到二者的联合特征图。然后使用 correlation block 计算 co-attention。
我们使用分割概率图作为强化学习算法中的状态 state,策略网络根据原始图像和分割概率图的联合特征映射来生成动作,这些动作 action 通过微调概率图的每个像素点的概率来生成新的状态。再将新的状态输入到下一次迭代步骤中。
具体的,对于一对图像 I 1 , I 2 I_1,I_2 I1,I2,首先,他们与他们各自的分割概率图连接,同时概率图也是强化学习的状态 s 1 , s 2 s_1, s_2 s1,s2。我们用 correlation block 去获得他们的一个 co-attention map。 E 1 , E 2 E_1, E_2 E1,E2 各自代表了两个图像的联结特征图( E i = I i + s i , i = 1 , 2 , ′ + ′ E_i=I_i+s_i, i=1, 2, '+' Ei=Ii+si,i=1,2,′+′代表连接操作)。我们用 Y 1 , Y 2 Y_1, Y_2 Y1,Y2 来分别代表 E 1 E_1 E1 和 E 2 E_2 E2 的 co-attention 的形式。并且 c 1 , c 2 c_1, c_2 c1,c2 是经过 co-attention 的相关图。步骤可以具体的用公式表示如下:
c 1 = E 1 ⊙ Y 2 c_1=E_1\odot Y_2 c1=E1⊙Y2
c 2 = E 2 ⊙ Y 1 c_2=E_2\odot Y_1 c2=E2⊙Y1
我们使用 c 1 , c 2 c_1, c_2 c1,c2 去连接 E 1 , E 2 E_1, E_2 E1,E2 的信息,去获得新的联结特征图 F 1 , F 2 F_1,F_2 F1,F2 。策略网络就根据 F 1 , F 2 F_1, F_2 F1,F2 输出动作 a 1 , a 2 a_1, a_2 a1,a2 , 然后执行动作获得新的状态 s 1 ′ , s 2 ′ s_1',s_2' s1′,s2′ 。
因此,我们基于 A3C 的协同分割模型中,agent 对图像 I 1 , I 2 I_1, I_2 I1,I2 的策略函数和值函数分别为:
π ( a 1 ∣ s 1 t , s 2 t ; θ 1 ) , V ( s 1 t , s 2 t ; θ 1 v ) \pi(a_1|s_1^t,s_2^t;\theta_1),V(s_1^t, s_2^t;\theta_{1v}) π(a1∣s1t,s2t;θ1),V(s1t,s2t;θ1v)
π ( a 2 ∣ s 1 t , s 2 t ; θ 2 ) , V ( s 1 t , s 2 t ; θ 2 v ) \pi(a_2|s_1^t,s_2^t;\theta_2), V(s_1^t, s_2^t;\theta_{2v}) π(a2∣s1t,s2t;θ2),V(s1t,s2t;θ2v)

2.2 Deep Reinforcement Learning Co-Segmentation Siamese Network Structure
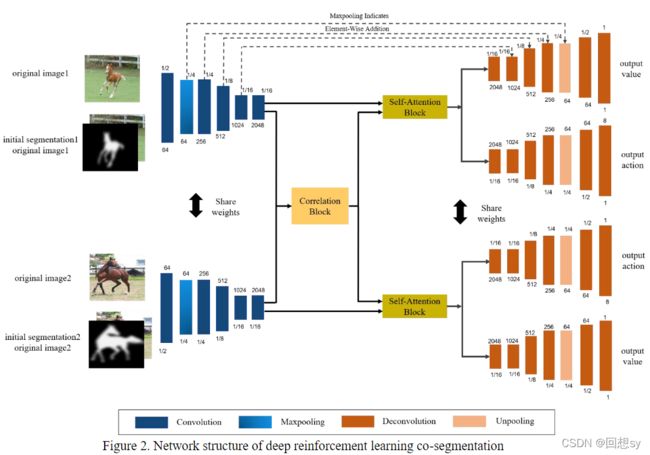
上图是深度强化学习网络的结构图,网络中包括 correlation calculation 部分和 self-attention calculation 部分。 correlation calculation 部分的输入是分割概率图和原始图像的联结,self-attention calculation 部分的输入是原始图像。correlation calculation 部分和 self-attention calculation 部分共享 Siamese 的编码网络,即 correlation calculation 部分和 self-attention calculation 部分的输入都要一次使用 Siamese network 进行特征提取。即每个编码分支获得两个特征映射输出,一个输出的特征是分割概率图和原始图像的联结特征,一个输出特征是原始图像的特征。将这个输出特征分别输入到 correlation calculation 部分和 self-attention calculation 部分,得到两个新的特征,再将这两个特征做一个联结,策略网络和价值函数网络就根据这个联结特征输出动作和值。
2.3 Self-attention mechanism
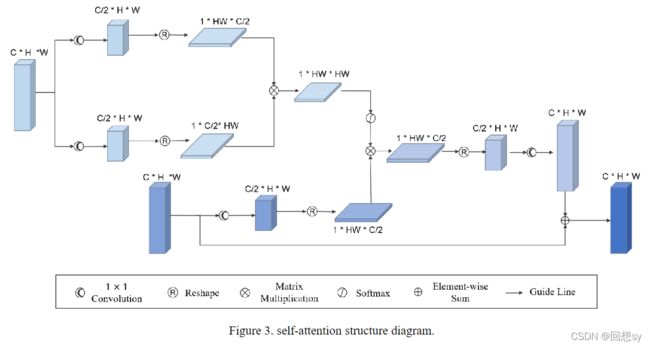
受自注意力机制的启发,该网络能够捕捉到原始图像的长距离的相关性,并将其应用到分割图概率图中,在分割概率图中使其特征映射更加注意显著目标,得到更合适的动作和值来调整分割概率。自注意力机制计算每个像素和原始图像上所有其他像素之间的相应,以表示像素之间的相似性。self-attention机制将注意力集中在与自己相似的像素上,忽略低相似度的像素。同时,将其看作 CNN,它也是扩大感受野的 CNN。关于 self-attention 在上图作出了说明。
具体的说,给定原始图像的特征图 E E E 和其联合特征图 P P P,我们计算 E E E 的 self-attention ,并且乘以联合特征图 P P P 。最后获得新的联合特征图 P ′ P' P′,计算步骤如下:
f ( E ) = w 1 ( e n ) T w 2 ( e m ) f(E)=w_1(e_n)^Tw_2(e_m) f(E)=w1(en)Tw2(em)
g ( E ) = w 3 ( p ( n ) ) g(E)=w_3(p(n)) g(E)=w3(p(n))
P ′ = w 4 ( σ ( f ( E ) ) g ( E ) ) + P P'=w_4(\sigma(f(E))g(E))+P P′=w4(σ(f(E))g(E))+P
其中 w 1 , w 2 , w 3 , w 4 w_1, w_2, w_3, w_4 w1,w2,w3,w4 分别代表 1*1 卷积核的参数。 σ ( ⋅ ) \sigma(\cdot) σ(⋅) 代表激活函数,本文是 s o f t m a x softmax softmax , e n e_n en 代表 E E E 的计算输出响应位置, e m e_m em 代表 E E E 中所有可能的位置。 f f f 代表获得的 e n e_n en 和 e m e_m em 的相关性, g ( E ) g(E) g(E) 计算特征图 P P P 上有代表性的位置。 P ′ P' P′ 是我们最后得到的特征图,是要输入到策略和值函数网络中的。
2.4 Fine-tune segmentation probabilities with reinforcement learning
我们仍把每个像素点看作一个智能体, i i i 代表第 i i i 个像素点,其状态 s i s_i si 和动作 a i a_i ai 已经给出介绍,该强化学习算法在时刻 t t t 采用的奖励是 r i t = ( y i − p i t − 1 ) 2 − ( y i − p i t ) 2 r_i^{t}=(y_i-p_{i}^{t-1})^2-(y_i-p_{i}^{t})^2 rit=(yi−pit−1)2−(yi−pit)2,其中 p i t p_{i}^t pit 是概率值, y i y_i yi 是 ground truth,为1或0。