NVIDIA CUDA 高度并行处理器编程(一):CUDA简介
NVIDIA CUDA 高度并行处理器编程(一):CUDA简介
-
- 1. 数据并行性
- 2. CUDA的程序结构
- 3. 向量加法kernel函数
- 4. 设备全局存储器与数据传输
- 5. kernel 函数与线程
1. 数据并行性
数据并行性是一种属性,这种属性支持算数操作按照程序的数据结构同时安全的执行。CUDA设备通过采用大量的数据并行性的方式来加快应用程序的执行速度。
在并行编程中,数据并行并不是唯一一种广泛使用的并行性,任务并行性在并行编程中也有广泛的使用。任务并行性通常对应用进行任务分解得到。例如,对于向量加法和矩阵向量乘法的简单应用来说,每个操作都可以看做一个任务,如果这两个任务可以独立执行,那么就能得到任务并行性。
一般情况下,数据并行性是并行程序可拓展性地的主要来源。对于大型数据集很容易找到大量的数据并行性,以充分利用大规模并行处理器,随着每一代硬件提供更多执行单元,应用的性能也能大幅度提升。然而,任务并行性对于性能的提升也很重要,在介绍CUDA流的时候再介绍。

2. CUDA的程序结构
CUDA程序结构反映了在计算机中有一个主机(CPU)和一个或多个设备(GPU)。每个CUDA源文件包含主机代码和设备代码。默认情况下,任何只包含主机代码的C程序都可以看做CUDA程序。可以对任何C源文件添加设备函数和设备数据声明。针对设备的函数的数据声明都带有CUDA关键字标记。这些函数通常体现了丰富的数据并行性。
一旦设备函数和数据声明添加进C源文件中,编不能通过gcc或其他编译器的编译。这些代码需要用能够识别这些设备函数和数据声明的编译器编译,比如NVCC(NVIDIA C Compiler)。如下图上部所示
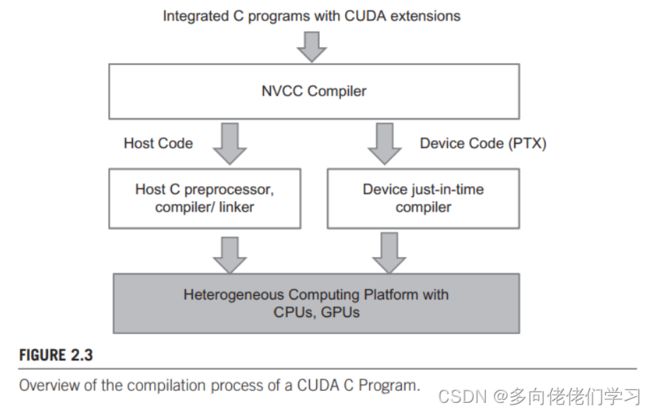
NVCC处理程序时通过CUDA关键字区分主机程序和设备程序。主机代码由主机标准的C或C++编译器编译,而设备代码用CUDA关键字来标示数据并行函数 (称为kernel) 。通常由NVCC编译器进一步编译,并在GUP上执行,如果没有GPU或者kernel更适合在CPU上执行,则可以通过MCUDA等工具将kernel函数转到CPU上执行。
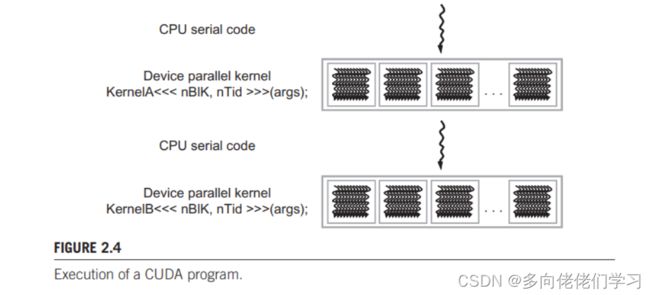
典型的CUDA程序的执行过程如下图所示。这是个简化的执行过程,其中GPU和CPU的执行过程没有重叠,然而很多模型都会采用CPU和GPU重叠执行的模型,以充分利用两者。
执行过程始于主机,遇到kernel函数时函数转移到设备上大量线程同时执行。在调用kernel函数时生成的所有线程统称网络,下图就包含了两个网络。当kernel函数中所有线程都完成他们的执行任务后,相应的网格也会终止,在调用下一个kernel函数时程序会转到主机上继续执行。
3. 向量加法kernel函数
在主机代码的每一段中,给主机处理的变量名加上前缀h_,在设备要处理的变量名前加上前缀d_,以示区别。先看传统的C程序:
// Compute vector sum h_C = h_A+h_B
void vecAdd(float* h_A, float* h_B, float* h_C, int n)
{
for (inti= 0; i < n; i++) h_C[i] = h_A[i] + h_B[i];
}
int main()
{
// Memory allocation for h_A, h_B, and h_C
// I/O to read h_A and h_B, N elements each
…
vecAdd(h_A, h_B, h_C, N);
}
此程序通过for循环顺序执行向量加法,在第[i]轮循环中,计算A[i]和B[i]的和并存入C[i]。并行执行向量加法的简单方法是修改vecAdd函数:
#include 注意,这里要添加一个预处理命令:#include
4. 设备全局存储器与数据传输
通常来讲,设备就是一种有DRAM的硬件卡。例如NVIDIA的GTX480处理器配备了称为全局存储器的4GB的DRAM芯片。
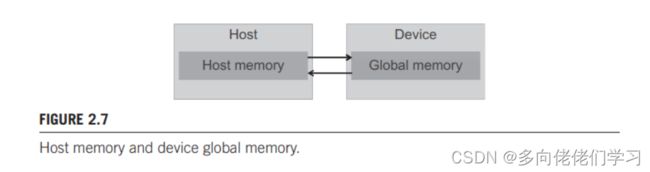
主机存储器和设备存储器模型的框架如下图所示,这种模型为分配,移动和使用设备上各种存储器类型的设备。主机可以访问设备全局存储器,与设备之间传输和复制数据。
下图展示了从在设备存储器中分配和释放内存的两个API函数,

- 指针变量的地址(也就是**),这个指针变量指向分配存储空间后的对象。指针变量的地址应被强制转化为(void**)的形式,因为 cudaMalloc() 的返回值是泛型指针。
- 对象所需的空间大小,以字节为单位,
下面演示 cudaMalloc() 函数如何使用。首先定义了一个单精度浮点指针 d_A, 将 d_A 的地址(即&d_A)强制转化为 void 指针后,作为 cudaMalloc() 函数的第一个参数传入。 即 d_A 指向在设备全局存储器中分配给 A 数组的空间,长度为单精度浮点数长度的 n 倍。计算结束后,调用 cudaFree() 释放设备全局存储器中 A 数组的空间。
float *d_A;
int size=n * sizeof(float);
cudaMalloc((void**)&d_A, size);
... //computing
cudaFree(d_A);
d_A, d_B 和 d_C 的地址是设备存储器上的地址,主机代码不能解引用这些地址,否则会引起异常或运行时类型错误。
在设备全局存储器分配空间后, 就可以调用CUDA API函数从主机存储器向设备传输数据了,下图展示了 cudaMemcpy() 函数。cudaMemcpy() 函数接受4个参数。
- 第一个参数是指针,指向数据复制操作的目的地址。
- 第二个参数指向要复制的源数据对象。
- 第三个参数指定要复制数据的大小(以字节为单位)。
- 第四个参数指出复制中所涉及的存储器的类型:从主机存储器到主机存储器、从设备存储器到设备存储器、从主机存储器到设备存储器和从设备存储器到主机存储器。但 cudaMemcpy() 不能用于多GPU系统中GPU与GPU之间的数据复制

cudaMemcpy(d_A, A, size, cudaMemcpyHostToDevice); //cudaMemcpyHostToDevice is constant, no need to define
cudaMemcpy(d_B, B, size, cudaMemcpyHostToDevice);
cudaMemcpy(C, d_C, size, cudaMencpyDeviceToHost); //cudaMencpyDeviceToHost is constant too
自己动手实现一下CUDA 版 vecAdd() 的第1、3步吧!
5. kernel 函数与线程
CUDA采用 SPMD 的并行编程风格。SPMD 与 SIMD 不同,SPMD 系统中,并行处理单元在数据的多个部分处理相同的程序,但不用执行同一指令。SIMD 系统中在任意时刻所有并行处理单元都在执行同一指令。
当主机代码启动一个 kernel 函数时,CUDA运行时系统产生一个两级层级结构的网络。每个网络是线程块组成的数组,所有线程块大小一样,每个线程块最多有1024个线程。每个线程块的线程数是 kernel 函数启动时主机函数指定的。同一个 kernel 函数可以用在主机代码中用不同的线程数启动。对于给定一个网格一个线程块可用的线程数信息在 blockDim 变量中保存。下图中的 blockDim.x 的值为256。一般地,线程块的大小都是32的倍数。
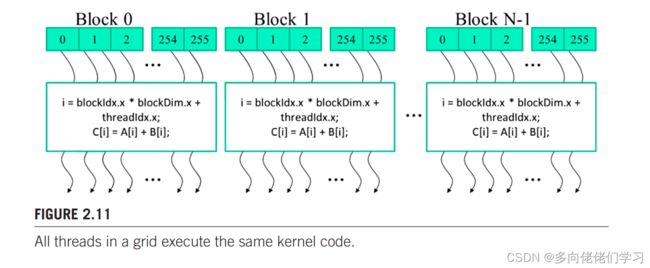
下面是向量加法的 kernel 函数。采用 ANSI C 编写。在 vecAddKernel 函数声明前的关键字__global__表示此函数时 kernel 函数且从主机调用它时会在设备上生成网络线程。
//compute vector sum C = A + B
//Each thread performs one one pair-wise addition
__global__ void vecAddKernel(float *A, float *B, float *C, int n){
int i = threadId.x + blockDim.x * blockIdx.x;
if(i < n) C[i] = A[i] + B[i];
}
kernel函数解释:
一般情况下,CUDA 对 C 函数的声明的拓展只有3个限定符关键字:
| 函数声明拓展 | 执行位置 | 调用位置 |
|---|---|---|
| __device__ | 设备 | 设备 |
| __global__ | 设备 | 主机 |
| __host__ | 主机 | 主机 |
__global__指出它声明的函数为 CUDA 的 kernel 函数。__device__表明声明的函数为 CUDA 的设备函数,该函数在设备上执行,且只能在 kernel 函数或其他设备函数中调用。_\host__声明的函数就是普通的主机函数,与C函数相同,通常可以省略。__device__和__host__可以同时使用,同时使用时出发编译系统,从而生成同一个函数的两个不同版本,一个只能在主机上执行,另一个只能在设备上执行。
kernel函数中的局部变量 i ,局部变量对于每个线程都是私有的,每个线程都会创建 i 的副本,假如有1000个线程,那么 i 就有 1000 个副本,它们的值分别为 0 ~ 999。
大家可能发现,vecAddKernel 中没有循环,传统的 C vecAdd 有一层循环,vecAddKernel 中少的一层循环被过程网格替代了。整个网格等价于一重循环,网格中的每个线程相当于每次循环中的一次迭代。
if(i < n) 语句是因为不一定所有向量长度都为块大小的整数倍,该语句是为了确保最后一个线程只有前 n - n / blockDim.x 个线程被调用。
kernel函数调用:
当主机代码启动一个kernel函数时,通过执行配置参数来设置网格和线程块的大小:
int vecAdd(float *A, float *B, float *C, int n)
{
//...
vecAddKernel<<<ceil(n/256.0), 256>>>(d_A, d_B, d_C, n);
//...
}
第一个参数为线程块的数目,第二个参数为线程块中的线程数。
vecAdd() 函数的最终主机代码:
#include 程序所需的线程块数取决于数组长度 n 的大小,小型 GPU 只有一到两个线程块, 大型的 GPU 可能有 64 或 128 个线程块。所以程序的执行时间取决于 GPU 的性能。
该CUDA vecAdd() 函数的执行速度可能比传统 C vecAdd() 慢,因为相对大量时间浪费在设备存储器上的内存分配与数据传输,而少量时间用来计算浮点加法。当线程进行的计算较复杂时,用于设备存储器上的内存分配与数据传输的比例会减少,速度也就相比于传统 C 更快。
参考:大规模并行编程处理器实战(第二版)David B. Kirk, Wen-mei W. Hwu 著,赵开勇 汪朝晖 程亦超 译
Programming Massively Parallel Processors A Hands-on Approach(3-rd)David B. Kirk, Wen-mei W. Hwu