《GraphSC: Parallel Secure Computation Made Easy》论文阅读笔记
文章目录
-
- 1、摘要
- 2、遇到的挑战
- 3、本文的主要贡献
- 4、图并行算法
- 5、应用场景
- 6、相关术语(ORAM,OPRAM)

The source code of GraphSC is available at http://www.oblivm.com.
1、摘要
我们建议对于安全计算引入现代并行编程范式,使其能够在大型数据集上安全执行。为了应对这一挑战,我们提出了GraphSC框架,它提供了一种编程范式,允许非密码专家编写安全代码;为此类安全实现带来并行性;以及满足不经意的需求,从而不泄露任何私人信息。使用GraphSC,开发人员可以高效地实现基于图的算法(包括复杂的数据挖掘和机器学习算法)的不经意版本,这些算法以最小的通信开销并行执行。重要的是,与非安全并行版本相比,我们的基于图的算法的安全版本产生了较小的对数开销。我们构建了GraphSC,并以几种算法为例,证明了安全计算可以应用于大数据分析。我们的安全矩阵分解实现可以在13小时内处理100万个评级,这比现有的唯一一次尝试(需要3小时才能处理16K评级)提高了多个数量级。
2、遇到的挑战
两个基本挑战:
①需要提供一种数据不经意(data oblivious)的解决方案,以防止任何信息泄漏并防止不必要的电路爆炸。
②以有效的方式将安全计算模型迁移到并行环境。
因为我们的解决方案侧重于基于图的并行算法,所以我们需要确保图结构本身不被泄露。明文并行化泄露了大量的信息:1、基于图的上述分区,顶点存储的数据量暴露了关于其邻居的信息;2、在scatter阶段访问顶点的次数将显示传出邻居的数量。3、在scatter过程中每个顶点与之通信的邻居暴露了整个图G。
3、本文的主要贡献
设计并实现了一个名为GraphSC的并行安全计算框架。使用GraphSC,开发人员可以使用类似于Pregel和GraphLab的编程抽象来编写程序。GraphSC使用并行安全计算后端执行程序。采用这种编程抽象允许GraphSC自然地支持广泛的数据挖掘算法。
①设计通用的解决方案
前人的研究侧重于特定功能,(针对某一个算法将其转换为并行不经意算法)。然而这种一次一个的方法不具备实用性,因为现实生活中的程序员可能不具备为手头的每项任务设计定制的不经意算法的专业知识;而且不应委托他们执行密码设计任务。我们为GraphSC的编程抽象接口设计了并行不经意算法,非专业程序员也可以使用我们的并行不经意算法。
②高效地转化为不经意程序
我们的工作是第一个设计出优于通用不经意平行RAM(Oblivious
Parallel RAM<理论性质的,实际不可行>)非平凡并行不经意算法(par-
allel oblivious algorithms)。每个处理器的计算和通信不应暴露图G的任何信息。

③保持并行性
设计一个以隐私保护方式实现GraphSC操作的安全计算框架,同时保持其并行性。
我们的设计应确保,在使用GraphSC原语实现程序时,只显示程序的最终输出;输入,即有向数据增强图G(V,E,D)不应在程序执行期间泄漏。

4、图并行算法
(1)graphlab
GraphLab将数据抽象成Graph结构,将算法的执行过程抽象成Gather、Apply、Scatter三个步骤。其并行的核心思想是对顶点的切分。
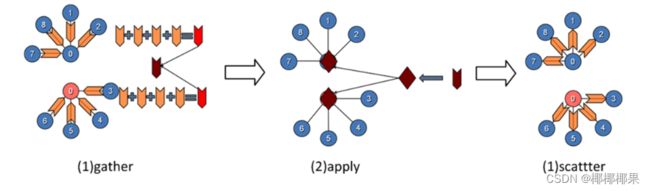
上图示例中,需要完成对V0邻接顶点的求和计算,串行实现中,V0对其所有的邻接点进行遍历,累加求和。而GraphLab中,将顶点V0进行切分,将V0的边关系以及对应的邻接点部署在两台处理器上,各台机器上并行进行部分求和运算,然后通过master顶点和mirror顶点的通信完成最终的计算。
①gather:从邻接顶点和自身收集数据,记为gather_data_i,各个边的数据graphlab会求和,记为sum_data。
②apply:Mirror将gather计算的结果sum_data发送给master顶点,master进行汇总为total。Master利用total和上一步的顶点数据,按照业务需求进行进一步的计算,然后更新master的顶点数据,并同步mirror。
③scatter:顶点更新完成之后,更新边上的数据,并通知对其有依赖的邻结顶点更新状态。
(2)graphsc
并行不经意算法( Parallel Oblivious Algorithms):

以pagerank算法为例:

Oblivious GraphSC on a Single Processor:

如图所示,表示边的元组用黑色单元表示,表示点的元组用白色单元表示。
算法描述:


sort: M. Ajtai, J. Komlós, and E. Szemerédi, “An o(n log n) sorting network,”
in ACM symposium on Theory of computing, 1983.
Apply:在Apply过程中,Apply操作在新的图表示下很容易达到oblivious(不暴露图的结构和信息)。Apply操作对列表G进行线性遍历,对列表中每一个节点元组应用fA函数,并对每一个边元组应用虚拟操作。
Scatter:
step1: oblivious sort:将元组排序,将相同源顶点的边组合在一起,每个顶点元组应出现在源自该顶点的所有边之前。(源顶点在边之前)
step2: propagate:对排好序的元组进行线性遍历,用出现在黑色单元(边元组)前面最近的白色单元(顶点元组)的值应用fS函数更新每个黑色单元的值。
Gather:
step1: oblivious sort:将元组排序,将具有相同目标顶点的元组(边)组合在一起,每个顶点元组应该出现在顶点结束的边列表之后。(目标顶点在边之后)
step2: aggregate:对排好序的元组进行线性遍历,对每个白色单元前面最长黑色单元(边)序列使用⊕操作更新每个白色单元的值(顶点)。换言之,以某个顶点v结束的所有边上的值现在聚合到顶点v中。
Parallel Oblivious Algorithms for GraphSC:
该部分描述如何并行化顺序原语(Scatter, Gather, and Apply),假设我们有足够多的处理器(|V|+|E|)个。
①Apply操作可以被简单地并行化,而Scatter和Gather都是从一个不经意的排序(oblivious sort)开始的,然后是聚合或传播操作。oblivious sort是一个log(|V|+|E|)-depth电路,因此并行化(通过直接在电路级并行化)很简单。
②Aggragate操作的并行化:(没太看懂)


Cost analysis:
In comparison with Theorem 1, in this table, some |V| terms are absorbed by the |E| term since |E| = Ω (|V|).


5、应用场景
采用半诚实模型(在协议执行时参与者按照协议规定的流程执行,但是可能会被恶意攻击者监听获取到在协议执行过程中的自己的输入输出以及在协议运行过程中获得的信息)的两方安全计算,两方可以是两个不串通的云提供商(如谷歌和亚马逊),双方都有并行计算架构(多台机器具有多个核心)。在这种情况下,数据被外包给云提供商,在每个云中,秘密数据可以分布在多台机器上。在第二个场景中,单个云提供商将数据拆分,以实现抵御内部攻击或APT威胁的能力。

图并行化模型的一个典型用例是PageRank算法。我们考虑一个场景,在该场景中,多家社交网络公司,例如Facebook、Twitter和LinkedIn,希望计算用户在社交图上的“真实”社交影响,该社交图是每个公司的图的总和(假设用户通过其电子邮件地址在整个网络中唯一标识)。在安全版本中,每个公司都不愿意向另一个网络泄露用户数据及其社交图。
6、相关术语(ORAM,OPRAM)
ORAM:越来越多的企业和个人把数据外包到位于公有云上,然后数据安全和隐私保护就显得越来越重要。即云环境下的数据的机密性保护成为了重要的研究课题。常见的保护方式是在数据上传到云服务器上前进行加密,但是即使数据加密,攻击者也可以从数据访问模式(Access Patterns)推测出敏感信息。这里的访问模式是指程序对存储器的一系列访问所泄露的信息,包括命令(读或写)、地址和数据。已有工作证明攻击者可以从访问模式推测出敏感信息。
ORAM近来就是来解决这个问题,隐藏数据的访问模式。比如一种简单的方案,就是每次把云上存储的数据都读到本地,然后找到自己需要读取或者更新的数据,然后再全部写回到云服务器上。这样云服务器就不知道你读了或者更新了什么数据。这就是一种最简单的ORAM方案,只是开销太大了,ORAM研究的一大方向就是针对计算复杂度和带宽开销进行优化。
ORAM综述