VIVIT+
我们提出了纯变压器为基础的视频分类模型,借鉴了最近成功的图像分类模型。我们的模型从输入视频中提取时空标记,然后通过一系列变换层对其进行编码。为了处理视频中遇到的长串令牌,我们提出了我们的模型的几个有效变体,这些变体分解了输入的空间和时间维度。虽然基于变压器的模型只有在大的训练数据集可用时才有效,但我们展示了如何在训练期间有效地正则化模型,并利用预训练的图像模型在相对较小的数据集上进行训练。我们进行了彻底的消融研究,并在多个视频分类基准上取得了最先进的结果,包括Kinetics 400和600、Epic Kitchens、Something v2和Moments in Time,优于基于深3D卷积网络的先前方法。为了便于进一步研究,我们在https://github.com/google-research/scenic.
1. Introduction
自AlexNet[38]以来,基于深度卷积神经网络的方法在许多标准数据集上提升了视觉问题的最新水平。同时,在序列到序列建模(如自然语言处理)中,最突出的选择架构是transformer[68],它不使用卷积,而是基于多头自我注意。这种操作在建模长期依赖关系时特别有效,并允许模型覆盖输入序列中的所有元素。这与卷积形成鲜明对比,卷积对应的“感受野”是有限的,并且随着网络的深度线性增长。NLP中基于注意的模型的成功最近启发了计算机视觉领域的方法,将变压器集成到CNN中[75,7],以及一些完全取代卷积的尝试[49,3,53]。然而,直到最近才有了视觉转换器(ViT)[18],在图像分类方面,一个纯粹的基于变换器的体系结构优于卷积结构。Dosovitskiy等人[18]密切关注[68]的原始变压器结构,并注意到其主要优点是在大范围内观察到的——因为变压器缺少卷积的一些电感偏差(如平移等变),它们似乎需要更多数据[18]或更强的正则化[64]。
受ViT的启发,以及基于注意力的架构是视频中远程上下文关系建模的直观选择,我们开发了几种基于转换器的视频分类模型。目前,性能最好的模型基于深度3D卷积结构[8,20,21],这是图像分类CNN的自然扩展[27,60]。最近,这些模型通过长距离的自我捕捉增强了注意力。
如图1所示,我们提出了用于视频分类的纯变压器模型。该架构中执行的主要操作是自我注意,它基于我们从输入视频中提取的一系列时空标记进行计算。为了有效地处理视频中可能遇到的大量时空标记,我们提出了几种沿时空维度分解模型的方法,以提高效率和可伸缩性。此外,为了在较小的数据集上有效地训练我们的模型,我们展示了如何在训练期间规范我们的模型,并利用预训练的图像模型。
我们还注意到,社区已经开发了几年卷积模型,因此有许多与此类模型相关的“最佳实践”。
由于纯变压器模型呈现不同的特征,我们需要确定此类架构的最佳设计选择。我们对标记化策略、模型架构和正则化方法进行了全面分析。根据这一分析,我们在多个标准视频分类基准上取得了最先进的结果,包括Kinetics 400和600[35]、Epic Kitchens 100[13]、Something v2[26]和Moments in Time[45]。
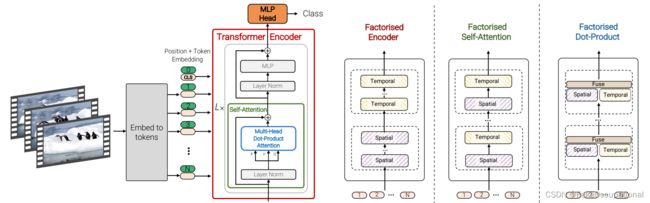
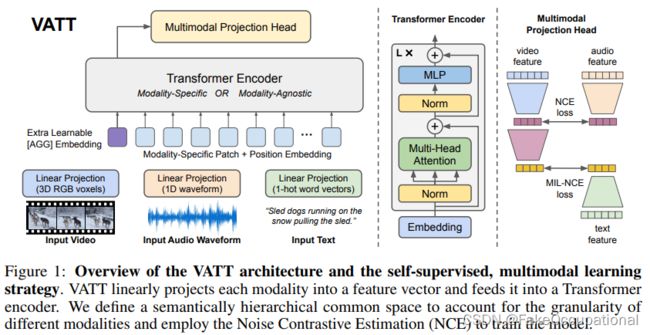
图1:我们提出了一种用于视频分类的纯transformer架构,其灵感来源于此类图像模型最近的成功[18]。为了有效地处理大量时空标记,我们开发了几个模型变体,这些变体在时空维度上分解变压器编码器的不同组件。如右图所示,这些因素对应于空间和时间上的不同注意模式
3. Video Vision Transformers
我们首先总结一下最近提出的愿景转换器[18],见第。3.1,然后讨论两种从视频中提取代币的方法。3.2. 最后,我们在Sec中开发了几种基于变压器的视频分类体系结构。3.3和3.4。
3.1. Overview of Vision Transformers (ViT)
和上面代码一直,我分成了64块图片,加入位置信息,并且,多加了一个class维度,用来做分类,我的理解是,它可以整合我这64块图片的信息,最终判断这是个什么类。
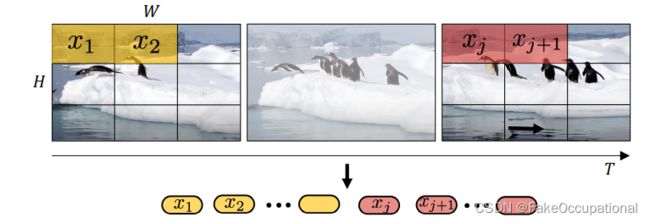
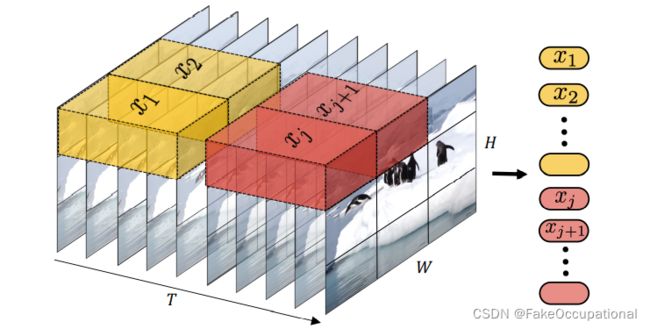
3.2. Embedding video clips
3.3 Model
Model 1:
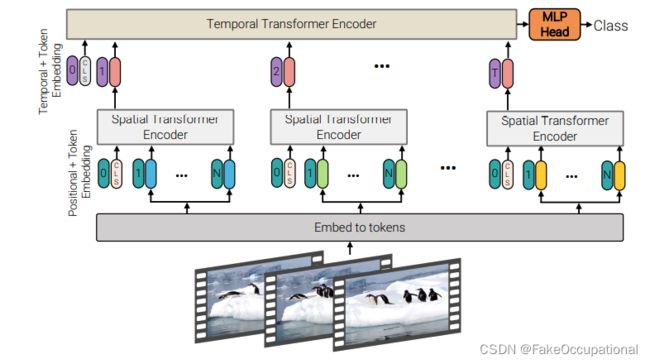
图4:分解编码器。该模型包括两个串联的转换器编码器:第一部分的空间编码器只交互同一帧抽出来的tokens,,以产生每个时间索引的潜在表示。第二个转换器对时间步之间的交互进行建模(不同帧的统一位置的tokens交互)。因此,它对应于时空信息的“后期融合”。
Model 2:
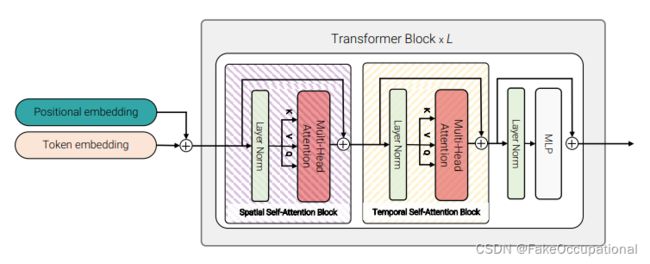
图5:因子化自我注意。在每个transformer块中,多头自我注意操作被分解为两个操作(用条纹框表示),首先只在空间上计算自我注意,然后在时间上计算自我注意
Model 3:
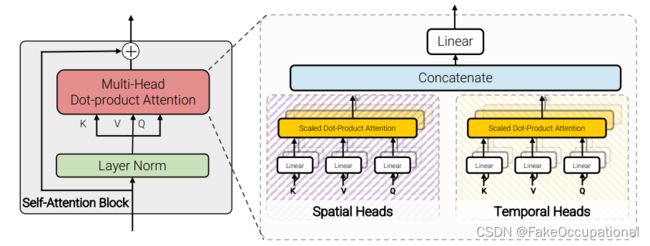
图6:因式网点产品关注度。对于一半的头部,我们只计算空间轴上的点积注意,而对于另一半,只计算时间轴上的点积注意。
实现
import torch
from torch import nn, einsum
import torch.nn.functional as F
from einops import rearrange, repeat
from einops.layers.torch import Rearrange
from module import Attention, PreNorm, FeedForward
import numpy as np
class Transformer(nn.Module):
def __init__(self, dim, depth, heads, dim_head, mlp_dim, dropout = 0.):
super().__init__()
self.layers = nn.ModuleList([])
self.norm = nn.LayerNorm(dim)
for _ in range(depth):
self.layers.append(nn.ModuleList([
PreNorm(dim, Attention(dim, heads = heads, dim_head = dim_head, dropout = dropout)),
PreNorm(dim, FeedForward(dim, mlp_dim, dropout = dropout))
]))
def forward(self, x):
for attn, ff in self.layers:
x = attn(x) + x
x = ff(x) + x
return self.norm(x)
class ViViT(nn.Module):
def __init__(self, image_size, patch_size, num_classes, num_frames, dim = 192, depth = 4, heads = 3, pool = 'cls', in_channels = 3, dim_head = 64, dropout = 0.,
emb_dropout = 0., scale_dim = 4, ):
super().__init__()
assert pool in {'cls', 'mean'}, 'pool type must be either cls (cls token) or mean (mean pooling)'
assert image_size % patch_size == 0, 'Image dimensions must be divisible by the patch size.'
num_patches = (image_size // patch_size) ** 2
patch_dim = in_channels * patch_size ** 2
self.to_patch_embedding = nn.Sequential(
Rearrange('b t c (h p1) (w p2) -> b t (h w) (p1 p2 c)', p1 = patch_size, p2 = patch_size),
nn.Linear(patch_dim, dim),
)
self.pos_embedding = nn.Parameter(torch.randn(1, num_frames, num_patches + 1, dim))
self.space_token = nn.Parameter(torch.randn(1, 1, dim))
self.space_transformer = Transformer(dim, depth, heads, dim_head, dim*scale_dim, dropout)
self.temporal_token = nn.Parameter(torch.randn(1, 1, dim))
self.temporal_transformer = Transformer(dim, depth, heads, dim_head, dim*scale_dim, dropout)
self.dropout = nn.Dropout(emb_dropout)
self.pool = pool
self.mlp_head = nn.Sequential(
nn.LayerNorm(dim),
nn.Linear(dim, num_classes)
)
def forward(self, x):
# 嵌入
x = self.to_patch_embedding(x) # torch.Size([1, 16, 3, 64, 64]) -> torch.Size([1, 16, 16, 192])
b, t, n, _ = x.shape
# self.space_token size : torch.Size([1, 1, 192])
# cls_space_tokens size : torch.Size([1, 16, 1, 192])
cls_space_tokens = repeat(self.space_token, '() n d -> b t n d', b = b, t=t)
x = torch.cat((cls_space_tokens, x), dim=2) # + ([1, 16, 1, 192]) ->torch.Size([1, 16, 17, 192])
x += self.pos_embedding[:, :, :(n + 1)]
x = self.dropout(x)
# 编码
x = rearrange(x, 'b t n d -> (b t) n d') # torch.Size([16, 17, 192])
x = self.space_transformer(x) # torch.Size([16, 17, 192])
x = rearrange(x[:, 0], '(b t) ... -> b t ...', b=b) # torch.Size([16, 192]) -> torch.Size([1, 16, 192])
cls_temporal_tokens = repeat(self.temporal_token, '() n d -> b n d', b=b)
x = torch.cat((cls_temporal_tokens, x), dim=1) # + torch.Size([1, 1, 192]) -> torch.Size([1, 17, 192])
x = self.temporal_transformer(x)
x = x.mean(dim = 1) if self.pool == 'mean' else x[:, 0]
return self.mlp_head(x)
if __name__ == "__main__":
img = torch.ones([1, 16, 3, 64, 64]).cuda()
model = ViViT(224, 16, 100, 16).cuda()
parameters = filter(lambda p: p.requires_grad, model.parameters())
parameters = sum([np.prod(p.size()) for p in parameters]) / 1_000_000
print('Trainable Parameters: %.3fM' % parameters)
out = model(img)
print("Shape of out :", out.shape)
其中cls_token借鉴的bert,代表图像的整体特征
代码与更多
VIVIT pdf
https://github.com/rishikksh20/ViViT-pytorch/blob/master/vivit.py
https://github.com/drv-agwl/ViViT-pytorch/blob/master/models.py
https://github.com/noureldien/vivit_pytorch/blob/master/modules/vivit.py
一文梳理Visual Transformer:与CNN相比,ViT赢在哪儿?
https://paperswithcode.com/method/vision-transformer
VATT:从原始视频、音频和文本进行多模态自我监督学习的变形金刚