【千里之行,始于足下】大数据高频面试题——Hadoop篇(一)
制作不易,各位大佬们给点鼓励!
点赞 ➕ 收藏⭐ ➕ 关注✅
欢迎各位大佬指教,一键三连走起!
1、 Hadoop 常用端口
➢ dfs.namenode.http-address:50070
➢ dfs.datanode.http-address:50075
➢ SecondaryNameNode 辅助名称节点端口号:50090
➢ dfs.datanode.address:50010
➢ fs.defaultFS:8020 或者 9000 hadoop3.x 9870
➢ yarn.resourcemanager.webapp.address:8088
➢ 历史服务器 web 访问端口:19888
2、Hadoop 配置文件以及简单的 Hadoop 集群搭
(1)8个配置文件:
core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml
hadoop-env.sh、yarn-env.sh、mapred-env.sh、slaves
(2)简单的集群搭建过程:
JDK 安装
配置 SSH 免密登录
配置 hadoop 核心文件:
格式化 namenode
3、Hadoop文件切片机制
1)简单地按照文件的内容长度进行切片
2)切片大小,默认等于 Block 大小
3)切片时不考虑数据集整体,而是逐个针对每一个文件单独切片
切片大小公式:max(0,min(Long_max,blockSize))
4、HDFS的读流程和写流程
(一)、HDFS的读流程

首先,client访问NameNode,查询元数据信息,获得这个文件的数据块位置列表,返回输入流对象。然后client会就近挑选一台datanode服务器,请求建立输入流 。再然后,DataNode向输入流中中写数据,以packet为单位来校验(用来保证数据传输的完整性)。最后,关闭输入流
那么,我们可以详细的解析下读文件的流程:
- 1.首先调用FileSystem对象的open方法,其实是一个DistributedFileSystem的实例
- 2.DistributedFileSystem通过rpc获得文件的第一个block的locations,同一block按照副本数会返回多个locations,这些locations按照hadoop拓扑结构排序,距离客户端近的排在前面.
- 3.前两步会返回一个FSDataInputStream对象,该对象会被封装成DFSInputStream对象,DFSInputStream可以方便的管理datanode和namenode数据流。客户端调用read方法,DFSInputStream最会找出离客户端最近的datanode并连接。
- 4.数据从datanode源源不断的流向客户端。(通过packet形式)
- 5.如果第一块的数据读完了,就会关闭指向第一块的datanode连接,接着读取下一块。这些操作对客户端来说是透明的,客户端的角度看来只是读一个持续不断的流。
- 6.如果第一批block都读完了,DFSInputStream就会去namenode拿下一批blocks的location,然后继续读,如果所有的块都读完,这时就会关闭掉所有的流。
- 7.如果在读数据的时候,DFSInputStream和datanode的通讯发生异常,就会尝试正在读的block的排第二近的datanode,并且会记录哪个datanode发生错误,剩余的blocks读的时候就会直接跳过该datanode。DFSInputStream也会检查block数据校验和,如果发现一个坏的block,就会先报告到namenode节点,然后DFSInputStream在其他的datanode上读该block的镜像
- 8.该设计的方向就是客户端直接连接datanode来检索数据并且namenode来负责为每一个block提供最优的datanode,namenode仅仅处理block location的请求,这些信息都加载在namenode的内存中,hdfs通过datanode集群可以承受大量客户端的并发访问。
(二 )、HDFS的写流程

- 客户端向NameNode发出写文件请求。
- 检查是否已存在文件、检查权限。若通过检查,直接先将操作写入EditLog,并返回输出流对象。
- client端按128MB的块切分文件。
- client将NameNode返回的分配的可写的DataNode列表和Data数据一同发送给最近的第一个DataNode节点,此后client端和NameNode分配的多个DataNode构成pipeline管道,client端向输出流对象中写数据。client每向第一个DataNode写入一个packet,这个packet便会直接在pipeline里传给第二个、第三个…DataNode。
- 每个DataNode写完一个块后,会返回确认信息。
- 写完数据,关闭输输出流。
- 发送完成信号给NameNode。注意:发送完成信号的时机取决于集群是强一致性还是最终一致性,强一致性则需要所有DataNode写完后才向NameNode汇报。最终一致性则其中任意一个DataNode写完后就能单独向NameNode汇报,HDFS一般情况下都是强调强一致性
同样的,我们可以详细的解析下写文件的流程:
- 1.客户端通过调用DistributedFileSystem的create方法创建新文件
- 2.DistributedFileSystem通过RPC调用namenode去创建一个没有blocks关联的新文件,创建前,namenode会做各种校验,比如文件是否存在,客户端有无权限去创建等。如果校验通过,namenode就会记录下新文件,否则就会抛出IO异常.
- 3.前两步结束后会返回FSDataOutputStream的对象,与读文件的时候相似,FSDataOutputStream被封装成DFSOutputStream.DFSOutputStream可以协调namenode和datanode。客户端开始写数据到DFSOutputStream,DFSOutputStream会把数据切成一个个小packet,然后排成队列data quene。
- 4.DataStreamer会去处理接受data queue,他先问询namenode这个新的block最适合存储的在哪几个datanode里,比如副本数是3,那么就找到3个最适合的datanode,把他们排成一个pipeline.DataStreamer把packet按队列输出到管道的第一个datanode中,第一个datanode又把packet输出到第二个datanode中,以此类推。
- 5.DFSOutputStream还有一个对列叫ack queue,也是由packet组成,等待datanode的收到响应,当pipeline中的所有datanode都表示已经收到的时候,这时akc queue才会把对应的packet包移除掉。
如果在写的过程中某个datanode发生错误,会采取以下几步:1) pipeline被关闭掉;2)为了防止丢包 ack queue里的packet会同步到data queue里;3)把产生错误的datanode上当前在写但未完成的block删掉;4)block剩下的部分被写到剩下的两个正常的datanode中;5)namenode找到另外的datanode去创建这个块的复制。当然,这些操作对客户端来说是无感知的。 - 6.客户端完成写数据后调用close方法关闭写入流
- 7.DataStreamer把剩余得包都刷到pipeline里然后等待ack信息,收到最后一个ack后,通知datanode把文件标示为已完成。
5、MapReduce 的 Shuffle 过程
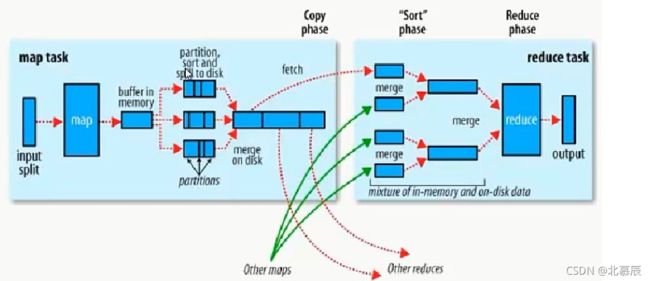
Shuffle 机制:
1)Map 方法之后 Reduce 方法之前这段处理过程叫 Shuffle
2)Ma方法之后,数据首先进入到分区方法,把数据标记好分区,然后把数据发送到 环形缓冲区;环形缓冲区默认大小 100m,环形缓冲区达80%时,进行溢写;溢写前对数 据进行排序,排序按照对 key 的索引进行字典顺序排序,排序的手段快排;溢写产生大量写文件,需要对溢写文件进行归并排序;对溢写的文件也可以进行 Combiner 操作,前提 汇总操作,求平均值不行。最后将文件按照分区存储到磁盘,等待 Reduce 端拉取。
3)每个 Reduce 拉取 Ma端对应分区的数据。拉取数据后先存储到内存中,内存不够 了,再存储到磁盘。拉取完所有数据后,采用归并排序将内存和磁盘中的数据都进行排序。在进入 Reduce 方法前,可以对数据进行分组操作。
MapReduce 的 详细流程解析归纳:
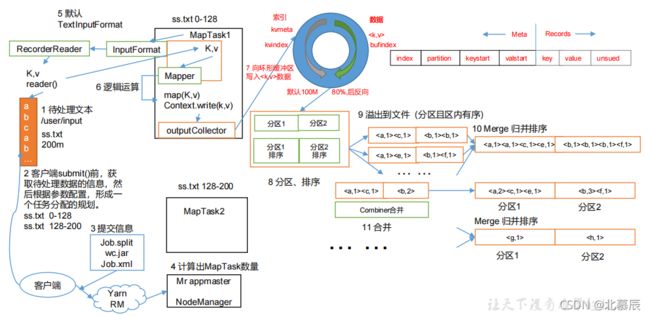

在map阶段,主要任务是处理从HDFS中输入的文件,在输入时会使用InputFormat类的子类(TextInputFormat)把输入的文件(夹)划分为很多切片(InputSplit),默认HDFS的每一个block块对应着一个切片,每一个切片默认大小为128MB,每一个切片会产生一个map任务。然后当map任务处理完后(就会进入到shuffle(中文译为“洗牌”)阶段,从map端的输出到reduce端的输入这一过程称为shuffle过程,该过程主要是负责map端的数据能够完整的发送到reduce端进行处理),就会将这些数据刷写到环形缓冲区(Buffer in mermory)中,环形缓冲区的默认大小位100MB,而当这些数据刷写到80%的时候,就会开始溢写到磁盘中去,那么溢写的过程中,会对数据进行分区(partition)和排序(sort)处理,然后每个map任务可能会产生多个(小)文件(这些小文件都采用了快速排序处理过),我们知道最后reduce任务会从map任务中拉取数据,对这些(小)文件进行拉取时会需要很多的网络IO以及磁盘IO的资源,那么,为了减少网络IO和磁盘IO的次数,我们会将多个(小)文件合并为一个(大)文件,该过程就是merge操作,使用hash partitional分区原理来分区,采用归并排序对分区中的数据排序,并且会根据map端中输入的key的不同去计算hash值,再去对指定的reduce的个数进行取余,reduce的个数是指提前设定好的,几个reduce(个数)就会产生几个分区,然而,相同的key的数据会进入到同一个reduce任务中,一个reduce任务中可以处理不同key的数据,因为不同数据key的hash值对reduce个数进行取余,最后得到的结果可能一样的,所以一个reduce任务中也有可能会有不同的key,最后每一个map任务会生成一个(大)文件,而这个(大)文件是经过分区和排序得到的,之后,会通过HTTP将每一个输出文件的特定分区的数据拉取到reduce任务中,等reduce任务阶段处理完后会将最终的结果写入到磁盘(也就是HDFS)中。
6、Hadoop 优化(包括:压缩、小文件、集群优化)
1、HDFS 小文件影响
(1)小文件会影响 NameNode 的寿命,因为HDFS中文件的元数据都是存储在 NameNode 的内存中的。
(2)小文件会影响计算引擎的任务数量,比如每个小的文件都会生成一个 Map 任务,会导致因map task过多效率低下
2、数据输入小文件处理:
(1)合并小文件:对小文件进行归档(Har)、使用自定义 Inputformat 将小文件存储成
SequenceFile 文件。
(2)可以采用 ConbinFileInputFormat 来作为输入,解决输入端大量小文件场景。
(3)对于大量小文件 Job,可以开启 JVM 重用。
3、Map 阶段优化
(1)增大环形缓冲区大小。由 100m 扩大到 200m
(2)增大环形缓冲区溢写的比例。由 80%扩大到 90%
(3)减少对溢写文件的 merge 次数。(10 个文件,一次 20 个 merge)
(4)不影响实际业务的前提下,采用 Combiner 提前合并,减少 I/O。
4、Reduce 阶段优化
(1)合理设置 Map 和 Reduce 的个数:两个都不能设置太少,也不能设置太多。设置太少,会
导致 Task 等待,延长处理时间;设置太多,会导致 Map、Reduce 任务间竞争资源,造成处理超
时等错误。
(2)设置 Map、Reduce 共存:调整 slowstart.completedmaps 参数,使 Map 运行到一定
程度后,Reduce 也开始运行,减少 Reduce 的等待时间。
(3)规避使用 Reduce,因为 Reduce 在用于连接数据集的时候将会产生大量的网络消
耗。
(4)增加每个 Reduce 拉取 Map 中数据的并行数
(5)集群性能可以的前提下,增大 Reduce 端存储数据内存的大小。
5、IO 传输优化
(1)采用数据压缩的方式,减少网络 IO 时间。可以安装 Snappy 和 LZOP 压缩编码
器。
(2)可以使用 SequenceFile 二进制文件
6、Hadoop整体优化
(1)MapTask 默认内存大小为 1G,可以增加 MapTask 内存大小为 4-5g
(2)ReduceTask 默认内存大小为 1G,可以增加 ReduceTask 内存大小为 4-5g
(3)可以增加 MapTask 的 cpu 核数,增加 ReduceTask 的 CPU 核数
(4)增加每个 Container 的 CPU 核数和内存大小
(5)调整每个 Map Task 和 Reduce Task 最大重试次数
7、Hadoop的文件压缩格式

【面试】一般回答压缩方式为 Snappy,特点速度快,缺点无切分(可以回答在链式 MR 中,Reduce 端输出使用 bzip2 压缩,以便后续的 map 任务对据进行 split)
Hadoop 默认不支持 LZO 压缩,如果需要支持 LZO 压缩,需要添加 jar 包,并在 hadoo的 cores-site.xml 文件中添加相关压缩配置。
7、Yarn 的 Job 提交流程

8、 Yarn 的默认调度器、调度器分类、以及他们之间的区别
1)Hadoop 调度器重要分为三类:
FIFO 、Capacity Scheduler(容量调度器)和 Fair Sceduler(公平调度器)。
Hadoop2.7.2 默认的资源调度器是 容量调度器
2)区别:
FIFO 调度器:先进先出,同一时间队列中只有一个任务在执行。

容量调度器:多队列;每个队列内部先进先出,同一时间队列中只有一个任务在执行。队列的并行度为队列的个数。

生产环境中不是使用的 FifoScheduler,企业生产环境一定不会用这调度的
公平调度器:多队列;每个队列内部按照缺额大小分配资源启动任务,同一时间队列有多个任务执行。队列的并行度大于等于队列的个数。

9、Hadoop 参数调优
1)在 hdfs-site.xml 文件中配置多目录,最好提前配置好,否则更改目录需要重新启集群
2)NameNode 有一个工作线程池,用来处理不同 DataNode 的并发心跳以及客户端并的元数据操作dfs.namenode.handler.count=20 * log2(Cluster Size),比如集群规模为 10 台时,此参数置为 60
3 )编辑 日 志 存 储 路 径 dfs.namenode.edits.dir 设 置 与 镜 像 文 件 存 储 路 dfs.namenode.name.dir 尽量分开,达到最低写入延迟
4)服务器节点上 YARN 可使用的物理内存总量,默认是 8192(MB),注意,如果的节点内存资源不够 8GB,则需要调减小这个值,而 YARN 不会智能的探测节点的物理存总量。yarn.nodemanager.resource.memory-mb
5)单个任务可申请的最多物理内存量,默认是 8192(MB)。yarn.scheduler.maximumallocation-mb
10、HDFS的设计特点?
1)流式数据访问:是指收集到部分数据就开始处理,而不是收集到全部数据再处理,否则会导致比较大的延迟,也会消耗大量内存。
2)大规模数据集:HDFS对大文件存储比较友好,HDFS上的一个典型文件大小一般都在GB至TB级。
3)一次写入多次读取:文件经过创建、写入和关闭之后就不能够改变。这也简化了数据一致性问题,并且使高吞吐量的数据访问成为可能
4)不支持低延时数据访问:HDFS关系的是高吞吐量,不适合那些低延时数据访问的应用
5)单用户写入,不支持任意修改:HDFS的数据以读为主,只支持单个写入者,并且写操作总是以添加的形式在文末追加,不支持在任意位置进行修改。
11、 HDFS中block块的大小为什么默认为64MB(或者是128MB)
hadoop 分布式文件系统hdfs中bliock块的大小设置是有一个原则的,就是最小化寻址开销。在磁盘中数据块的大小默认是512byte,而hdfs中的块的大小要比磁盘中的数据块大得多,其目的就是为了最小化寻址开销。
那么,我们对block块大小的设计一般会考虑以下原则:
- 1.减少磁盘的寻道时间
- HDFS设计的背景就是适合大量(海量)数据的流式访问或操作,那么在我们读写数据时的数据量是非常大的。我们知道
数据块的数量(这里的数据块就是我们说的block块)取决于数据量和数据块的大小,这时,如果我们的数据块的大小设置过小时,数据块数量就会过大,那么我们读取数据时拉取的数据块就会过多,又因为数据块在磁盘上是非连续存储的,这样磁盘在随机寻址时需要移动磁头,就会导致寻址速度较慢,寻址时间较长,最终,这样就会导致我们总的磁盘寻道时间增加,那么当我们的磁盘寻道时间比我们的 IO 时间还要长的多时,此时磁盘的寻道时间就称为系统的一个瓶颈;同样的,如果我们的数据块的大小设置过大时,数据块数量就会过小,而MapReduce中的map任务一般一次只处理一个数据块中的数据(默认一个切片对应一个block块,切片大小也默认等于block块大小),而当数据块的数量过少,少于集群中节点的数量时,那么就会导致mapreduce作业的运行速度较慢,任务的执行效率底下。(在实际开发过程中,我们会把block块的大小设置的远大于128MB,比如我们存储 1T 的文件时,一般会把BLock块大小设置为512MB,当然也不会设置的过大)所以,合适的数据块大小有助于减少磁盘的寻道时间,可以提高系统的吞吐量。所以我们传输一个由多个块组成的文件时取决于磁盘的传输效率。
- HDFS设计的背景就是适合大量(海量)数据的流式访问或操作,那么在我们读写数据时的数据量是非常大的。我们知道
- 2.降低NameNode的内存消耗
- HDFS只有一个NameNode节点,并且其内存相对于DataNode来说是很有限的,在NameNode内存中有一个FSImage文件记录着DataNode中的数据块的信息,那么如果我们数据块的大小设置过小,数据块数据就会过大,那么需要维护的数据块的信息就会过多,这样,在NameNode中就会占用过多的内存资源,内存消耗就会过大。
- 3.考虑Map崩溃问题
- 当我们的系统需要重新启动的时候,在重启过程中,会需要重新地加载数据,而,当数据块越大则数据的加载时间就会越长,那么这样,系统的恢复过程也就会越长。
- 4.考虑监管时间问题
- 在集群中,主节点负责监管其他节点的情况,而每个子节点会周期性的将完成的工作和状态的更新报告给主节点。那么当有一个节点一直没有更新报告给主节点,而且当该时间超过了预设的时间间隔时,那么,主节点就会这个节点记录为死亡状态,并且会将计划分配给该节点数据发送到其它正常的节点上。对于这个“预设的时间间隔”是从数据块的大小,这样的角度大概估算的:例如对于一个128MB的数据块,我们可以估算给20分钟之内可以完成处理,那么如果实际处理时间超过了这个20分钟的(预设的时间间隔)时间,就会认为为死亡状态。所以如果我们设置的数据快大小过大或者过小,就会有很大可能造成因“预设时间间隔”的“估算”不准,而导致误判死亡状态。
- 5.考虑问题分解问题
- 数据量大小与问题解决的复杂度是成线性关系的。对于同一个算法,它处理的数据量越大时,它的时间复杂度也就越大。当数据块的大小太大时,一个map任务处理一个数据块,处理的任务数就会减少,作业的运行速度就会变慢。
- 6.约束Map输出
- 在MapReduce框架里,Map任务输出的数据是要经过shuffle过程之后才传输数据到Reduce端操作的。在shuffle过程中,有一个归并排序对小文件进行排序,然后将小文件归并成大文件。
Hadoop如何设置HDFS的块大小
12、Hadoop 宕机
1)如果 MR 造成系统宕机。此时要控制 Yarn 同时运行的任务数,和每个任务申请的大内存。调整参数:yarn.scheduler.maximum-allocation-mb(单个任务可申请的最多物内存量,默认是 8192MB)
2)如果写入文件过量造成 NameNode 宕机。那么调高 Kafka 的存储大小,控制从 Kafk到 HDFS 的写入速度。高峰期的时候用 Kafka 进行缓存,高峰期过去数据同步会自动跟上。
13、MapReduce中如何处理跨行的Block和InputSplit
以行记录形式的文本,可能存在一行记录被划分到不同的Bloc,甚至不同的DataNode上。因为FileInputFormat对文件的切分是严格按照偏移量来的,所以当一行记录比较长时,是可能会被切分到不同的切片中去的,但是这样对于map任务并没有影响。原因是与FileInputFormat关联的RecordReader类能够实现读取跨InputSplit的行记录,直到将这行记录读取完整。而对于下一个InputSplit的第一行记录是不是完整的记录,我们会通过LineRecordReader来处理,使用一个简单而巧妙的方法: 既然我们无法断定每一个Split开始的一行是独立的一行还是被切断的一行的一部分,那么就跳过每个Split的开始一行(当然要除第一个Split之外),从第二行开始读取,然后在到达Split的结尾端时总是再多读一行,这样数据既能接续起来又避开了断行带来的麻烦。
好文解析:MapReduce中如何处理跨行的Block和InputSplit
本文参考文献:尚硅谷大数据高频面试题