HDFS的shell操作
目录
一、新课学习
(一)HDFS的Shell介绍
(二)了解HDFS常用Shell命令
1、三种shell命令方式
2、FileSystem Shell文档
3、常用HDFS的shell命令
(三)HDFS常用命令操作实战
1、创建目录
(1)创建单层目录
(2)创建多层目录
2、查看目录
3、上传本地文件到HDFS
4、查看文件内容
5、下载HDFS文件到本地
6、删除HDFS文件
7、删除HDFS目录
8、移动目录或文件
9、文件合并下载
10、检查文件信息
11、创建时间戳文件
12、复制文件或目录
(1)同名复制文件
(2)改名复制文件
(3)复制目录
13、查看文件大小
14、上传文件
15、下载文件
16、查看某目录下文件个数
17、检查hadoop本地库
18、进入和退出安全模式
(1)进入安全模式
(2)退出安全模式
(四)案例- Shell定时采集数据到HDFS
1、编程思路与步骤
(1)配置环境变量
(2)准备日志存放目录和待上传文件
(3)设置日志文件上传的路径
(4)实现文件上传
2、编写脚本,实现功能
3、运行脚本,查看结果
一、新课学习
(一)HDFS的Shell介绍
- Shell在计算机科学中俗称“壳”,是提供给使用者使用界面的进行与系统交互的软件,通过接收用户输入的命令执行相应的操作,Shell分为图形界面Shell和命令行式Shell。
- 文件系统(FS)Shell包含了各种的类Shell的命令,可以直接与Hadoop分布式文件系统以及其他文件系统进行交互。
(二)了解HDFS常用Shell命令
1、三种shell命令方式
| 命令 | 适用场合 |
|---|---|
| hadoop fs | 适用于任何不同的文件系统,比如本地文件系统和HDFS文件系统 |
| hadoop dfs | 只能适用于HDFS文件系统 |
| hdfs dfs | hdfs dfs跟hadoop dfs的命令作用一样,也只能适用于HDFS文件系统 |
2、FileSystem Shell文档
Apache Hadoop 3.3.4 – Overview https://hadoop.apache.org/docs/r3.3.4/hadoop-project-dist/hadoop-common/FileSystemShell.html
https://hadoop.apache.org/docs/r3.3.4/hadoop-project-dist/hadoop-common/FileSystemShell.html
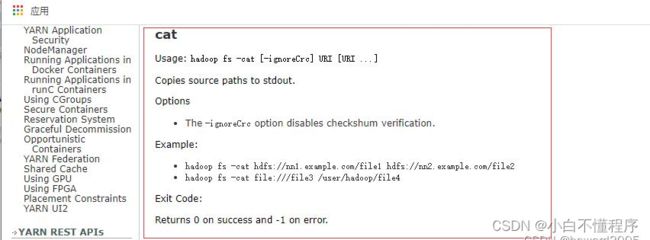
- 查看
cat命令用法
3、常用HDFS的shell命令
| 序号 | 命令 | 功能 |
| 1 | hdfs dfs -ls |
显示 |
| 2 | hdfs dfs -ls -R |
ls命令的递归版本。 |
| 3 | hdfs dfs -cat |
指定文件的内容输出到标准输出。 |
| 4 | hdfs dfs chgrp [-R] group |
将 |
| 5 | hdfs dfs -chown [-R] [owner][:[group]] |
改变 |
| 6 | hdfs dfs -chmod [-R] |
将 |
| 7 | hdfs dfs -tail [-f] |
指定文件最后1KB的内容输出到标准输出上,-f选项用于持续检测新添加到文件中的内容。 |
| 8 | hdfs dfs -stat [format] |
以指定格式返回 |
| 9 | hdfs dfs -touchz |
创建一个 |
| 10 | hdfs dfs -mkdir [-p] |
创建 |
| 11 | hdfs dfs -copyFromLocal |
将本地源文件 |
| 12 | hadoo fs -copyToLocal [-ignorcrc] [-crc] |
将目标文件 |
| 13 | hdfs dfs -cp |
将文件从源路径 |
| 14 | hdfs dfs -du |
显示 |
| 15 | hdfs dfs -expunge | 清空回收站。 |
| 16 | hdfs dfs -get [-ignorcrc] [-crc] |
复制 |
| 17 | hdfs dfs -getmerge [-nl] |
指定目录内所有文件进行合并,写入 |
| 18 | hdfs dfs -put |
从本地文件系统中复制 |
| 19 | hdfs dfs moveFromLocal |
与put命令功能相同,但是文件上传结束后会从本地文件系统中删除 |
| 20 | hdfs dfs -mv |
将文件或目录从源路径 |
| 21 | hdfs dfs -rm |
删除 |
| 22 | hdfs dfs -rm -r |
删除 |
| 23 | hdfs dfs -setrep [-R] |
改变 |
| 24 | hdfs dfs -test [-ezd] |
检查 -e (exist)检查文件是否存在,如果存在则返回0,否则返回1 -z (zero)检查文件是否是零字节,如果是则返回0,否则返回1 -d(directory)检查路径是否是目录,如果是则返回0,否则返回1 |
| 25 | hdfs dfs -text |
指定的文件输出为文本格式,文件格式允许是zip和TextRecordInputStream。 |
(三)HDFS常用命令操作实战
- 启动Hadoop集群
1、创建目录
(1)创建单层目录
- 执行命令:
hdfs dfs -mkdir /ied
- 利用Hadoop WebUI查看创建的目录
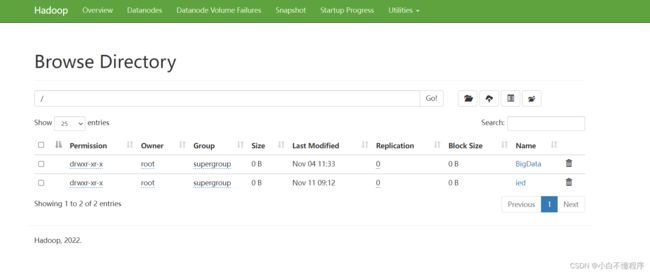
(2)创建多层目录
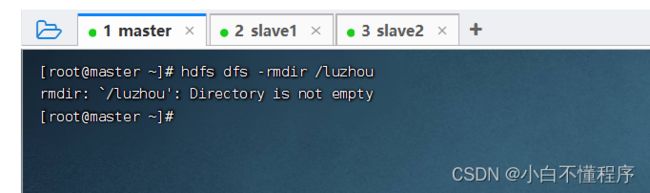
- 执行命令:hdfs dfs -mkdir /luzhou/lzy,会报错,因为/luzhou目录不存在
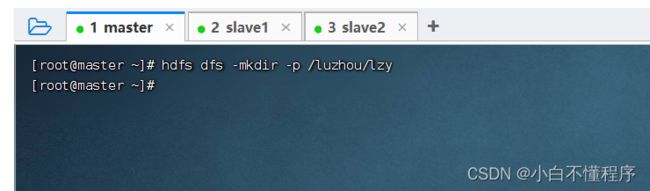
- 执行命令:hdfs dfs -mkdir -p /luzhou/lzy
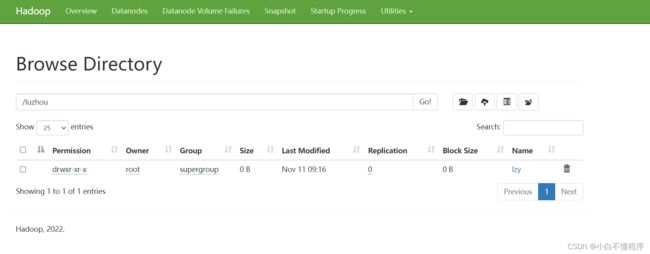
- 利用Hadoop WebUI查看创建的多层目录
2、查看目录
- 执行命令:hdfs dfs -ls /,查看根目录(可以在任何节点上查看,结果都是一样的)
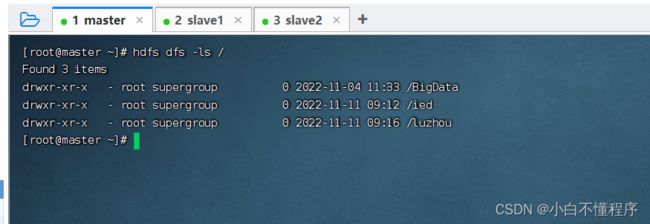
- 执行命令:hdfs dfs -ls /luzhou
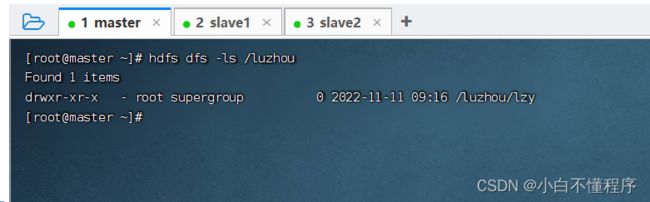
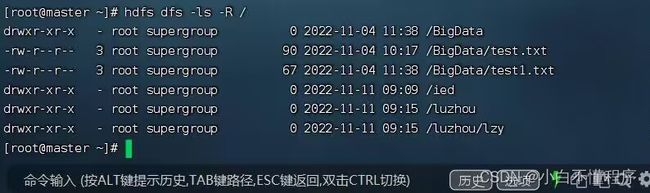
- 如果我们要查看根目录里全部的资源,那么要用到地柜参数
-R(必须大写) - 执行命令:hdfs dfs -ls -R /,递归查看/目录
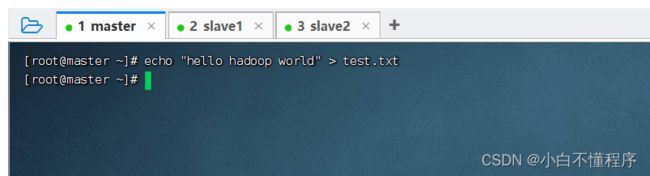
3、上传本地文件到HDFS
- 创建test.txt文件,执行命令:echo "hello hadoop world" > test.txt
- 查看test.txt文件内容
- 执行命令:cat test.txt
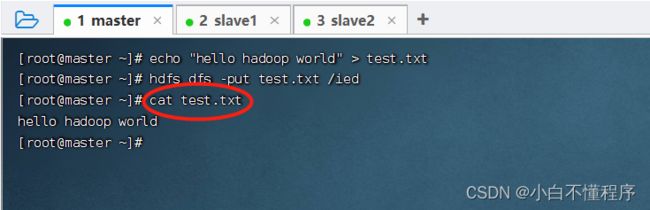
- 上传test.txt文件到HDFS的/ied目录,执行命令:hdfs dfs -put test.txt /ied

- 查看是否上传成功 ,执行命令:hdfs dfs -ls /ied
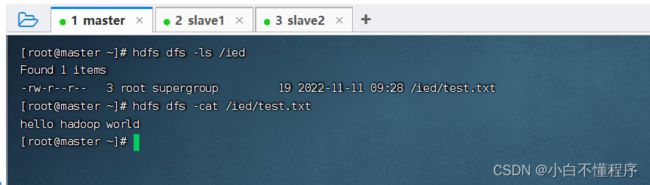
- 利用Hadoop WebUI界面查看
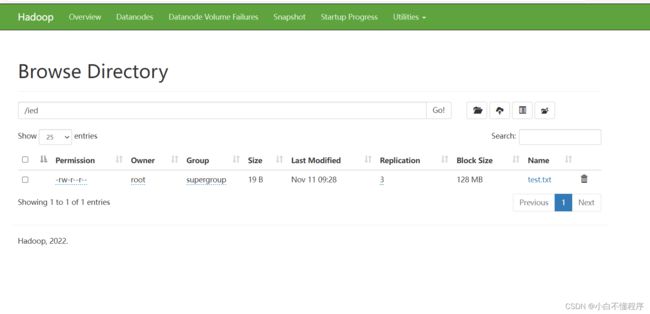
4、查看文件内容
- 执行命令:hdfs dfs -cat /ied/test.txt
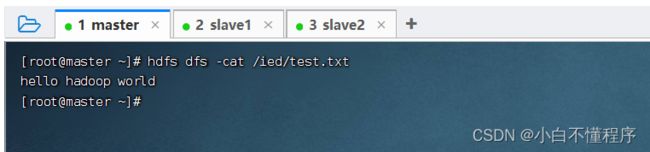
5、下载HDFS文件到本地
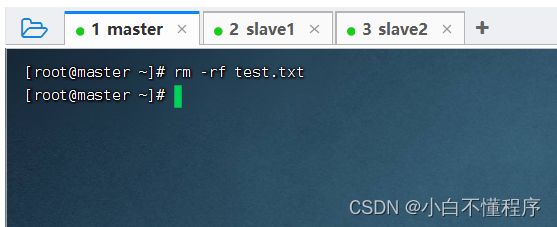
- 先删除本地的test.txt文件,执行命令:rm -rf test.txt
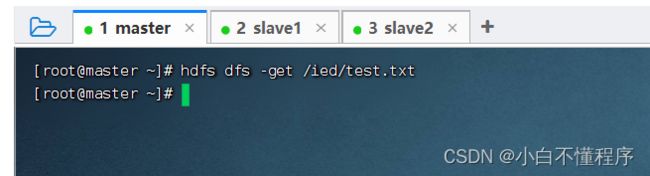
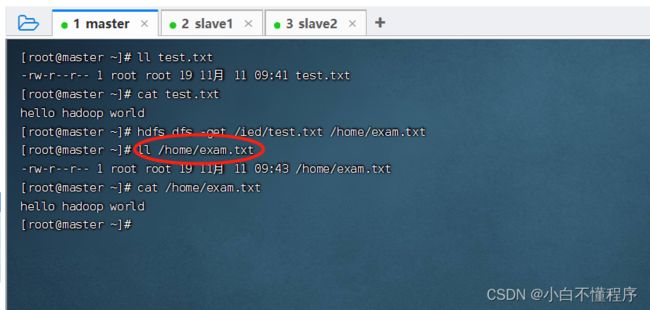
- 下载HDFS文件系统的/ied/test.txt到本地当前目录,执行命令:hdfs dfs -get /ied/test.txt
- 检查是否下载成功 ,执行命令:ll test.txt
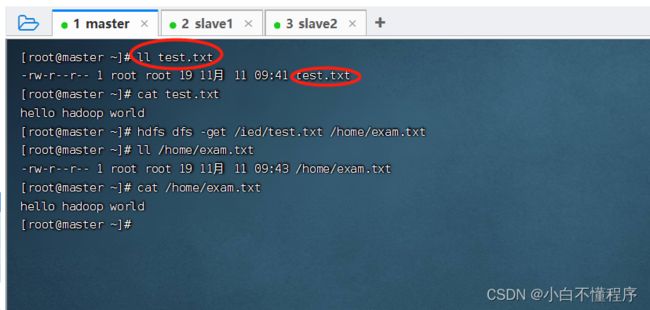
- 可以将HDFS上的文件下载到本地指定位置,并且可以更改文件名
- 执行命令:hdfs dfs -get /ied/test.txt /home/exam.txt
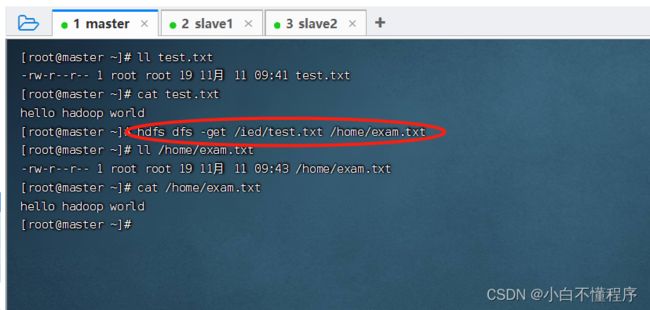
- 检查是否下载成功 执行命令:ll /home/exam.txt
6、删除HDFS文件
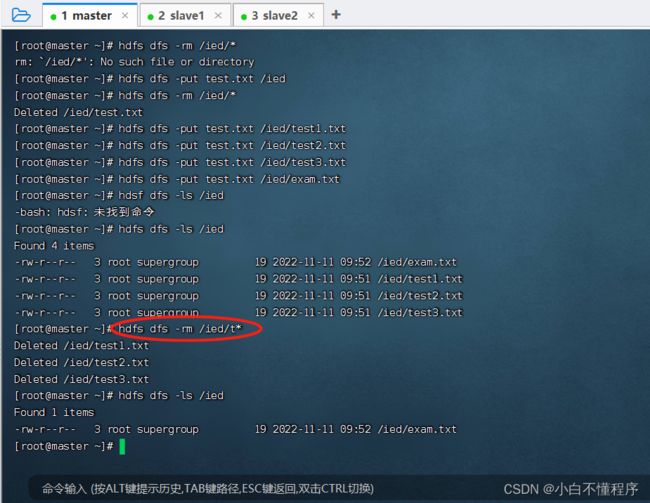
- 执行命令:hdfs dfs -rm /ied/test.txt

- 检查是否删除成功,执行命令:hdfs dfs -ls /ied/test.txt

- 使用通配符,可以删除满足一定特征的文件 执行命令:hdfs dfs -rm /ied/t*
- 解析:“t*”,意为删除以‘t’开头的文件。
7、删除HDFS目录
- 执行命令:hdfs dfs -rmdir /luzhou
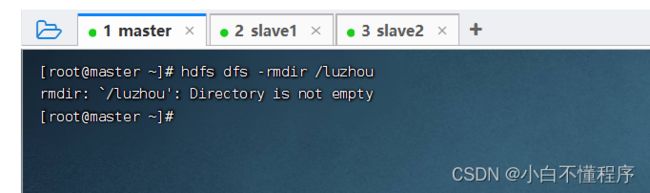 解析:‘not empty’:目录非空
解析:‘not empty’:目录非空
- 提示-rmdir命令删除不了非空目录。
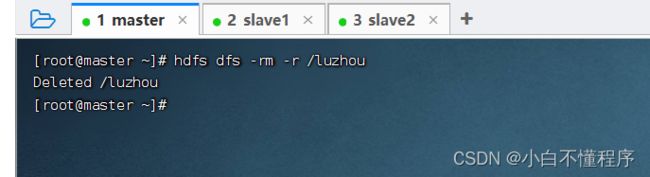
- 要递归删除才能删除非空目录:hdfs dfs -rm -r /luzhou(-r:recursive)
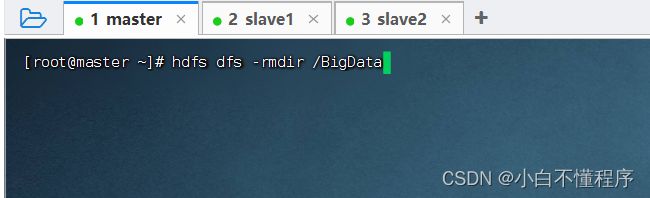
- 删除空目录/BigData,执行命令:hdfs dfs -rmdir /BigData
8、移动目录或文件
- -mv命令兼有移动与改名的双重功能
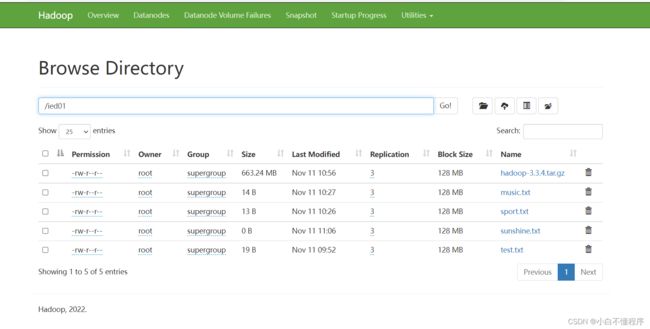
- 将/ied目录更名为/ied01,执行命令:hdfs dfs -mv /ied /ied01

- 利用Hadoop WebUI查看是否更名成功
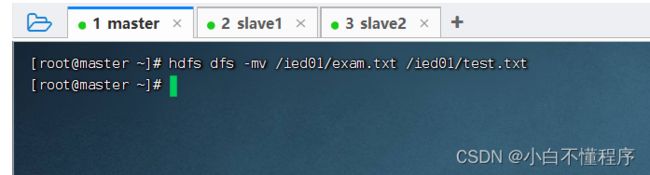
- 将/ied01/exam.txt更名为/ied/test.txt,执行命令:hdfs dfs -mv /ied01/exam.txt /ied01/test.txt
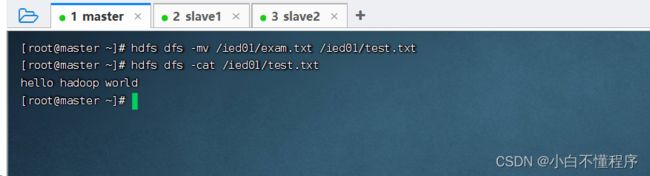
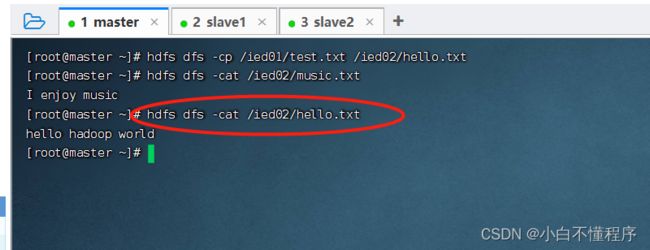
- 查看改名后的test.txt文件内容,执行命令:hdfs dfs-cat /ied01/test.txt
9、文件合并下载
- 现在/ied01里有一个test.txt,创建sport.txt和music.txt并上传
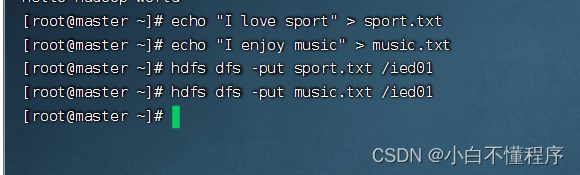
- 合并/ied01目录的文件下载到本地当前目录的merger.txt,执行命令:hdfs dfs -getmerge /ied01/* merger.txt
- 下面,查看本地的merger.txt,看是不是三个文件合并后的内容
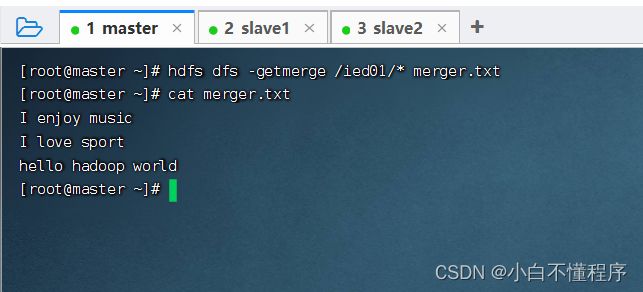
- 由此可见,merger.txt是music.txt、sport.txt与test.txt合并后的结果
10、检查文件信息
- 检查test.txt文件,执行命令:hdfs fsck /ied01/test.txt -files -blocks -locations -racks
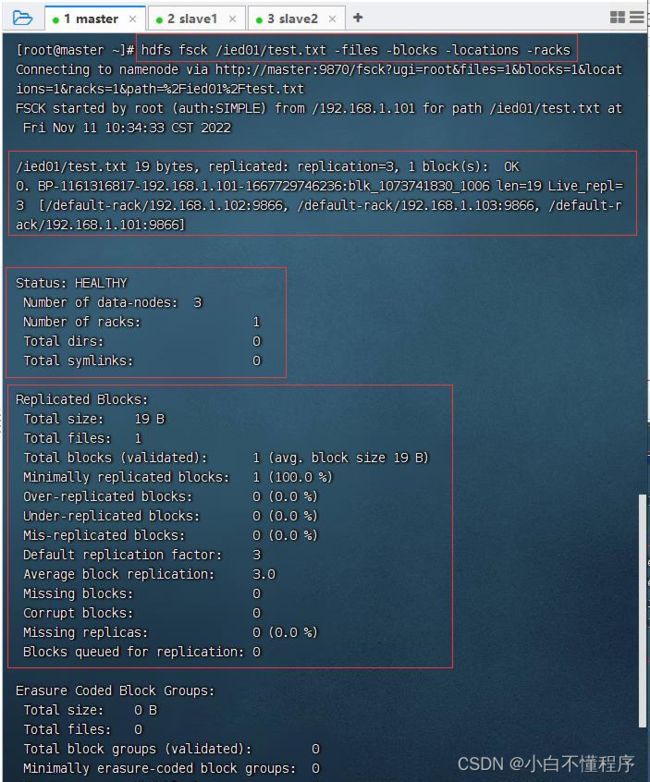
- 我们知道HDFS里一个文件块是128MB,上传一个大于128MB的文件,hadoop-3.3.4.tar.gz大约663.24MB
- 128 M B × 5 = 640 M B < 663.24 M B < 768 M B = 128 M B × 6 128 MB\times 5 = 640MB \lt 663.24MB \lt 768MB = 128 MB\times 6128MB×5=640MB<663.24MB<768MB=128MB×6 ,HDFS会将hadoop-3.3.4.tar.gz分割成6块。
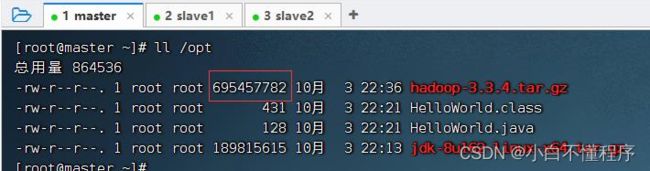
- 执行命令:hdfs dfs -put /opt/hadoop-3.3.4.tar.gz /ied01,将hadoop压缩包上传到HDFS的/ied01目录
- 查看HDFS上hadoop-3.3.4.tar.gz文件信息,执行命令:hdfs fsck /ied01/hadoop-3.3.4.tar.gz -files -locations -racks
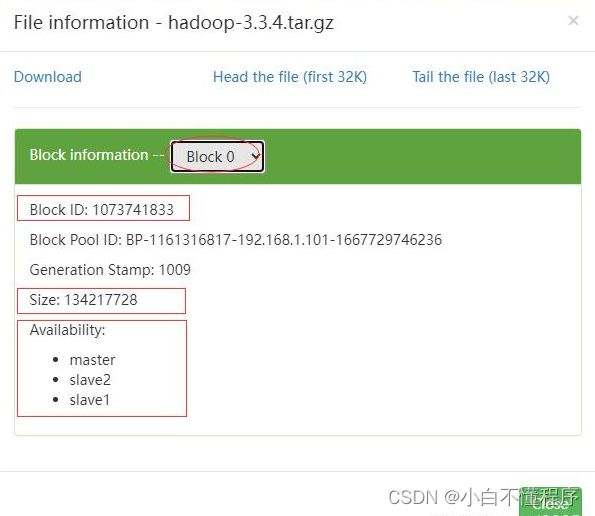
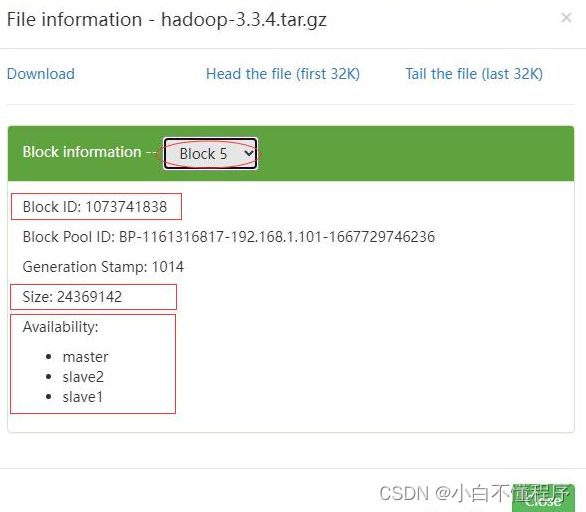
- 利用Hadoop WebUI来查看文件块信息更加方便,总共有6个文件块:Block0、Block1、Block2、Block3、Block4、Block5
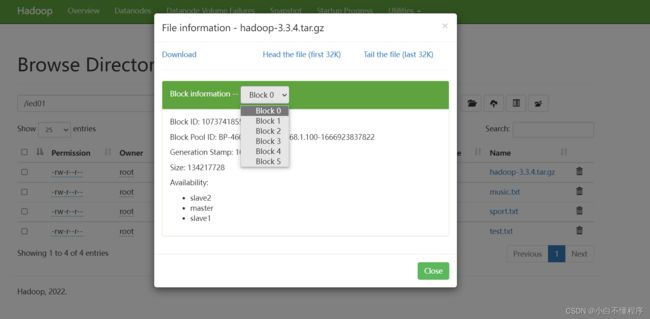
- 第1个文件块信息
- 第6个文件块信息
11、创建时间戳文件
- 在/ied01目录里创建一个文件sunshine.txt,执行命令:hdfs dfs -touchz /ied01/sunshine.txt
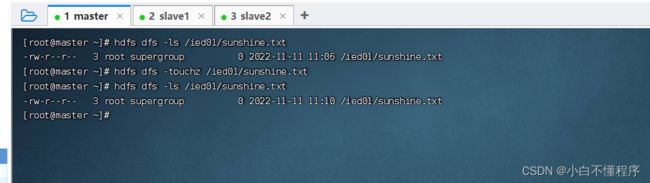
- 创建的是一个空文件,大小为0字节
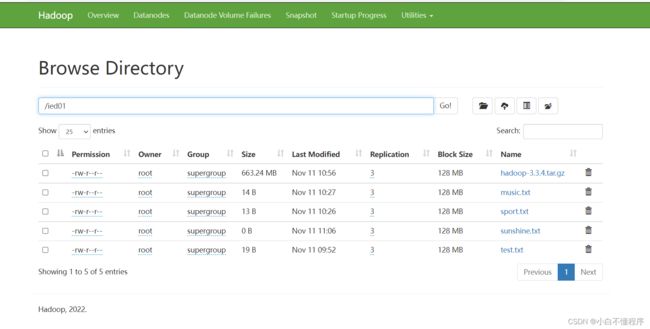
- 这种空文件,一般用作标识文件,也可叫做时间戳文件,再次在/ied01目录下创建sunshine.txt同名文件
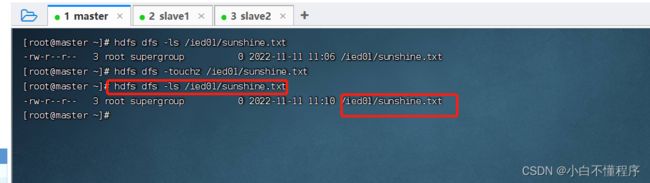
- 说明:如果touchz命令的路径指定的文件不存在,那就创建一个空文件;如果指定的文件存在,那就改变该文件的时间戳。
12、复制文件或目录
- 准备工作:创建/ied02目录
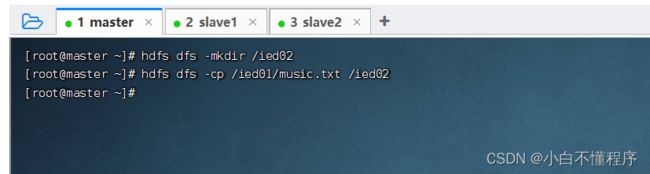
(1)同名复制文件
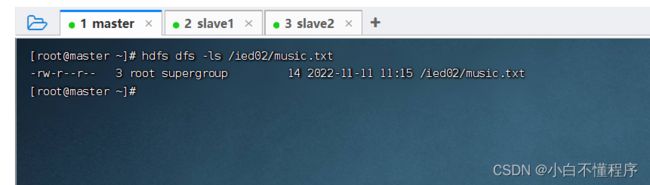
- 将/ied01/music.txt复制到/ied02里,执行命令:hdfs dfs -cp /ied01/music.txt /ied02
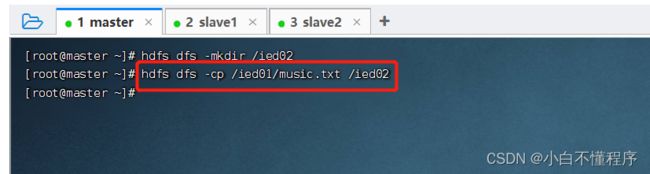
- 查看拷贝生成的文件,执行命令:hdfs dfs -ls /ied02/music.txt
(2)改名复制文件
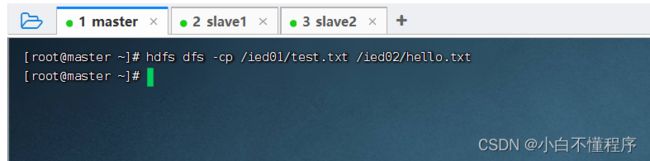
- 将/ied01/test.txt复制到/ied02目录,改名为hello.txt,执行命令:hdfs dfs -cp /ied01/exam.txt /ied02/hello.txt
- 查看拷贝后的文件内容
(3)复制目录
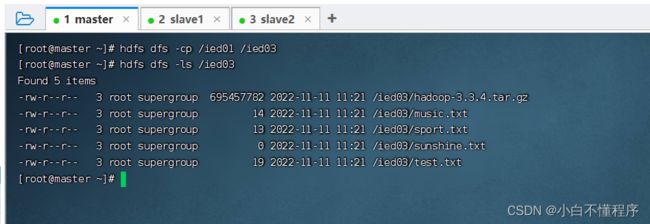
- 将/ied01目录复制到/ied03目录,执行命令:hdfs dfs -cp /ied01 /ied03
- 查看拷贝后的目录,执行命令:hdfs dfs -ls/ied03
13、查看文件大小
- 执行命令:hdfs dfs -du /ied01/test.txt
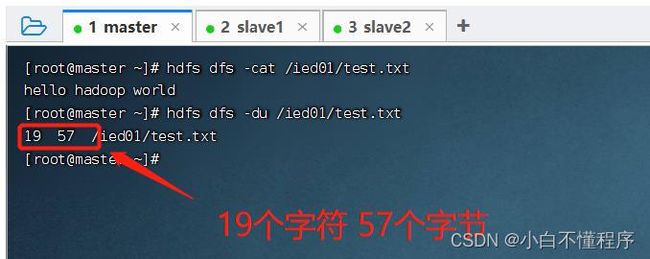
- 可以看到文件/ied01/test.txt大小是19个字符,包含一个看不见的结束符
14、上传文件
- -copyFromLocal类似于-put,执行命令:hdfs dfs -copyFromLocal merger.txt /ied02
- 查看是否上传成功,执行命令:hdfs dfs -ls /ied02
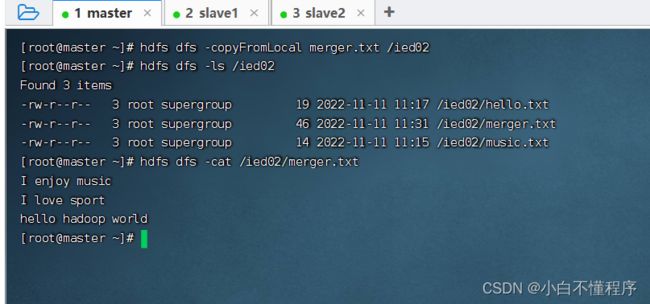
15、下载文件
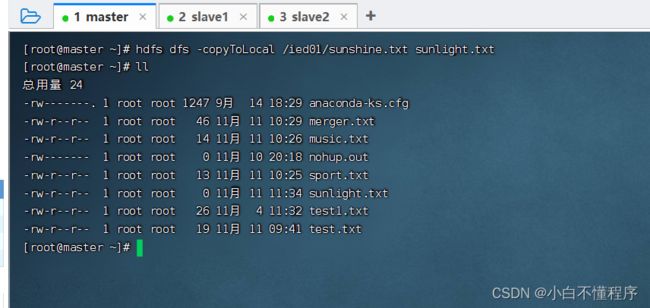
- -copyToLocal类似于-get,执行命令:hdfs dfs -copyToLocal /ied01/sunshine.txt sunlight.txt
- 查看是否下载成功,执行命令:ll
16、查看某目录下文件个数
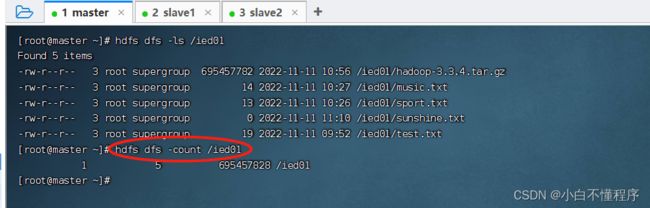
- 执行命令:hdfs dfs -count /ied01
17、检查hadoop本地库
- -执行命令:hdfs checknative -a
- 查看hadoop本地库文件

18、进入和退出安全模式
- 问题:哪些情况下HDFS会进入安全模式(只能读不能写)?
(1)名称起点启动时,进入安全模式,直到fsimage用edits更新完毕才退出安全模式
(2)当文件块的副本数量少于设置的副本数量,会进入安全模式,直到生成符合要求的副本数,才会退出安全模式。其实,也可以通过命令方式进入或退出安全模式。
(1)进入安全模式
- 执行命令:hdfs dfsadmin -safemode enter, 注意:进入安全模式之后,只能读不能写
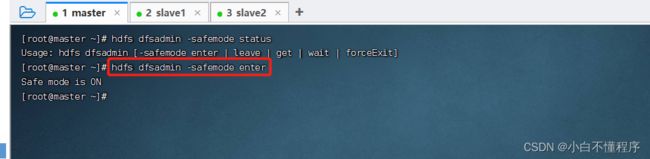
- 此时,如果要创建目录,就会报错
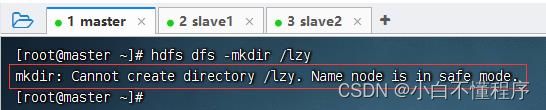
(2)退出安全模式
- 执行命令:hdfs dfsadmin -safemode leave
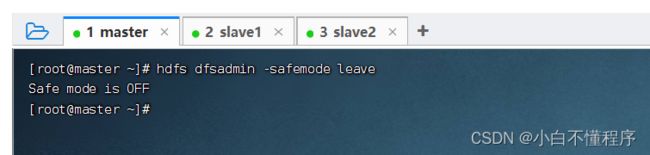
- 此时,创建目录/ied04就没有任何问题
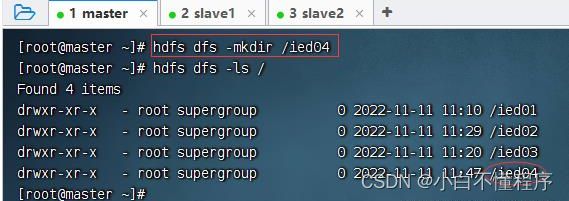
(四)案例- Shell定时采集数据到HDFS
- 服务器每天会产生大量日志数据,并且日志文件可能存在于每个应用程序指定的data目录中,在不使用其它工具的情况下,将服务器中的日志文件规范的存放在HDFS中。通过编写简单的Shell脚本,用于每天自动采集服务器上的日志文件,并将海量的日志上传至HDFS中。
- 创建日志文件存放的目录/export/data/logs/log/,执行命令:mkdir -p /export/data/logs/log

- 创建待上传文件存放的目录/export/data/logs/toupload/,
- 执行命令:mkdir -p /export/data/logs/toupload
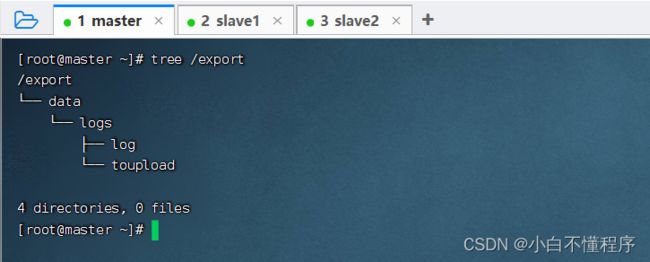
- 查看创建的目录树结构
- 如果无法使用,需要下载,执行命令:yum -y install tree

- 查看创建的目录树结构,执行命令:tree /export
1、编程思路与步骤
(1)配置环境变量
- 首先在/export/data/logs目录下(如果目录不存在,则需要提前创建)使用vim命令创建upload2HDFS.sh脚本文件,在编写Shell脚本时,需要设置Java环境变量和Hadoop环境变量,这样做是用来提高系统的可靠性,保障运行程序的机器在没有配置环境变量的情况下依然能够运行脚本。
(2)准备日志存放目录和待上传文件
- 为了让开发者便于控制上传文件的流程,可以在脚本中设置一个日志存放目录和待上传文件目录,若上传过程中发生错误只需要查看该目录就能知道文件的上传进度。
(3)设置日志文件上传的路径
- 设置上传的HDFS目标路径,命名格式以时间结尾,并且输出打印信息。
(4)实现文件上传
- 上传文件的过程就是遍历文件目录的过程,将文件首先移动到待上传目录,再从待上传目录中上传到HDFS中。若是在每天12点凌晨执行一次,我们可以使用Linux Crontab表达式执行定时任务。
2、编写脚本,实现功能
- 进入/export/data/logs目录,执行命令:cd /export/data/logs
- 执行命令:vim upload2HDFS.sh
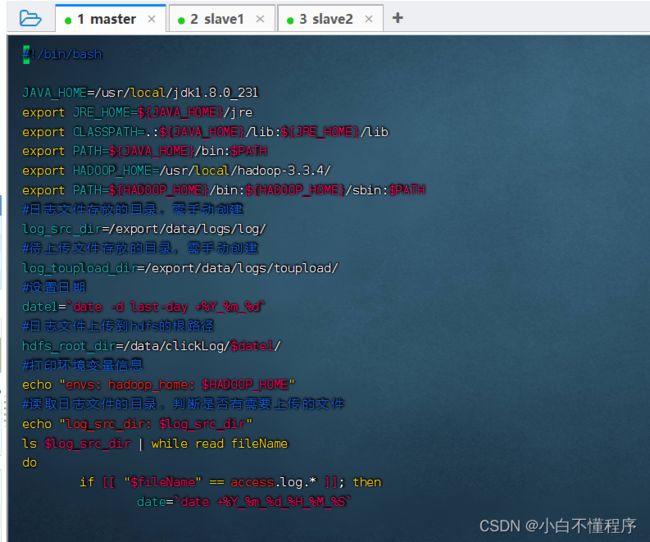
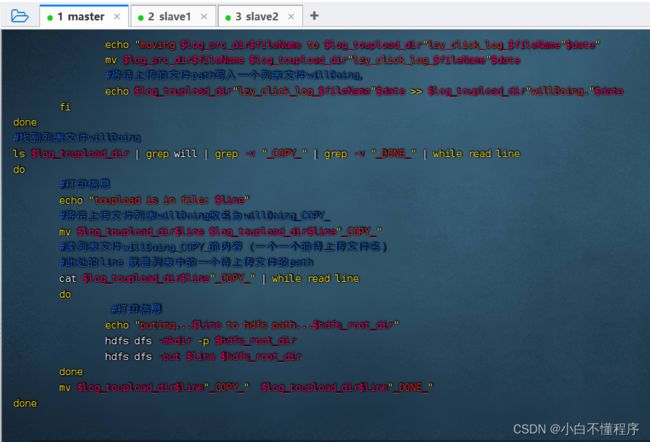
#!/bin/bash
JAVA_HOME=/usr/local/jdk1.8.0_231
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
export HADOOP_HOME=/usr/local/hadoop-3.3.4/
export PATH=${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:$PATH
#日志文件存放的目录,需手动创建
log_src_dir=/export/data/logs/log/
#待上传文件存放的目录,需手动创建
log_toupload_dir=/export/data/logs/toupload/
#设置日期
date1=`date +%Y_%m_%d`
#日志文件上传到hdfs的根路径
hdfs_root_dir=/data/clickLog/$date1/
#打印环境变量信息
echo "envs: hadoop_home: $HADOOP_HOME"
#读取日志文件的目录,判断是否有需要上传的文件
echo "log_src_dir: $log_src_dir"
ls $log_src_dir | while read fileName
do
if [[ "$fileName" == access.log.* ]]; then
date=`date +%Y_%m_%d_%H_%M_%S`
#将文件移动到待上传目录并重命名
echo "moving $log_src_dir$fileName to $log_toupload_dir"lzy_click_log_$fileName"$date"
mv $log_src_dir$fileName $log_toupload_dir"lzy_click_log_$fileName"$date
#将待上传的文件path写入一个列表文件willDoing,
echo $log_toupload_dir"lzy_click_log_$fileName"$date >> $log_toupload_dir"willDoing."$date
fi
done
#找到列表文件willDoing
ls $log_toupload_dir | grep will | grep -v "_COPY_" | grep -v "_DONE_" | while read line
do
#打印信息
echo "toupload is in file: $line"
#将待上传文件列表willDoing改名为willDoing_COPY_
mv $log_toupload_dir$line $log_toupload_dir$line"_COPY_"
#读列表文件willDoing_COPY_的内容(一个一个的待上传文件名)
#此处的line 就是列表中的一个待上传文件的path
cat $log_toupload_dir$line"_COPY_" | while read line
do
#打印信息
echo "puting...$line to hdfs path...$hdfs_root_dir"
hdfs dfs -mkdir -p $hdfs_root_dir
hdfs dfs -put $line $hdfs_root_dir
done
mv $log_toupload_dir$line"_COPY_" $log_toupload_dir$line"_DONE_"
done
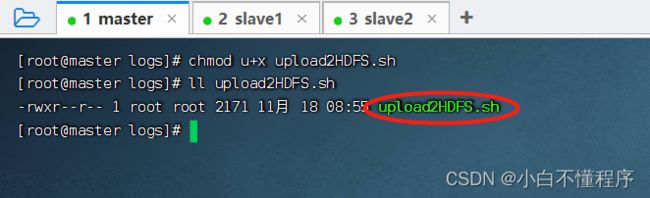
- 编辑权限,执行命令:chmod u+x upload2HDFS.sh
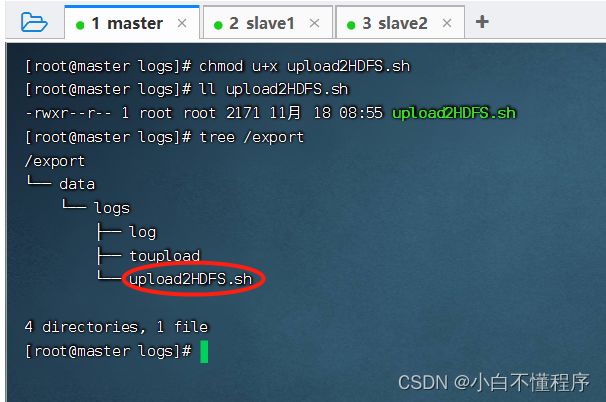
- 查看export目录树结构,执行命令:tree /export
3、运行脚本,查看结果
- 为了模拟生产环境,在日志存放目录/export/data/logs/log/中,手动创建日志文件,access.log表示正在源源不断的产生日志的文件,access.log.1、access.log.2等表示已经滚动完毕的日志文件,即为待上传日志文件。
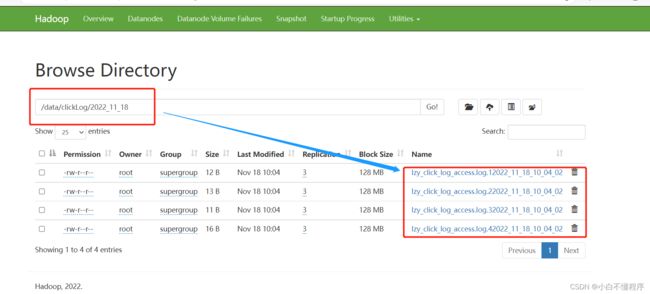
- 在upload2HDFS.sh文件路径下运行脚本,先将日志存放目录log中的日志文件移到待上传toupload目录下,并根据业务需求重命名;然后脚本执行“hdfs dfs -put”上传命令,将待上传目录下的所有日志文件上传至HDFS;最后通过HDFS Web界面可看到需要采集的日志文件已按照日期分类,上传至HDFS中。
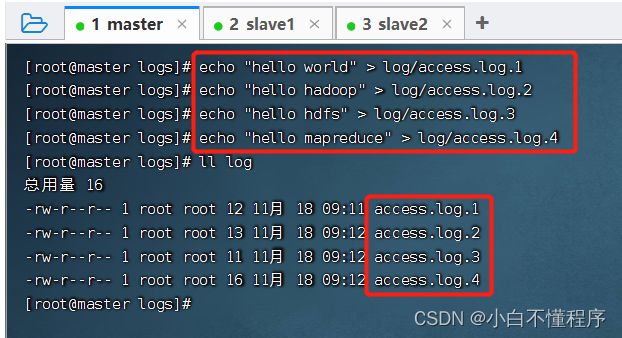
- 创建四个日志文件
- 查看export目录树结构
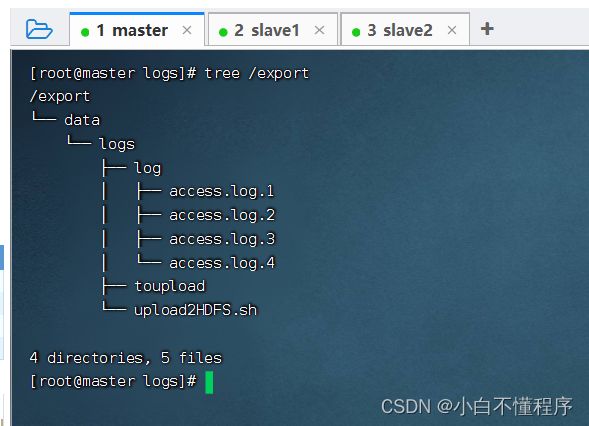
- 执行命令:./upload2HDFS.sh
- 查看export目录树结构
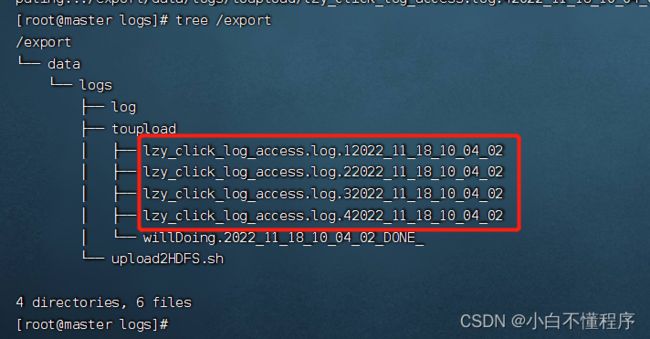
- 打开HDFS集群WebUI查看上传的日志文件
本章节,到此结束!