数据仓库Hive表
数据仓库Hive表,并且导入数据,整理文档
 移除点击此处添加图片说明文字
移除点击此处添加图片说明文字
接下来跑服务器环境,环境和本地有所区别了。
首先我们拿到几个目录,可以开干了。源数据目录,hdfs放置目录,集群地址即可。
 移除点击此处添加图片说明文字
移除点击此处添加图片说明文字
tar zxvf SafeData-2017-06-26.har.tar.gz -C /data/data/
 移除点击此处添加图片说明文字
移除点击此处添加图片说明文字
可以看到:
 移除点击此处添加图片说明文字
移除点击此处添加图片说明文字
因为这里是真正的集群环境,所以,有了环境变量:
 移除点击此处添加图片说明文字
移除点击此处添加图片说明文字
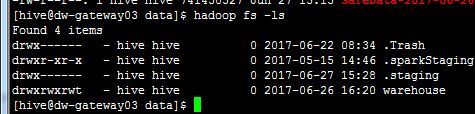
然后我们检查一下目录,找到他:
hadoop fs -ls /user/hive/warehouse/
 移除点击此处添加图片说明文字
移除点击此处添加图片说明文字
hadoop fs -mkdir /user/hive/warehouse/testing.db/input
hadoop fs -mkdir /user/hive/warehouse/testing.db/output
创建一个input输入,一个input输出。
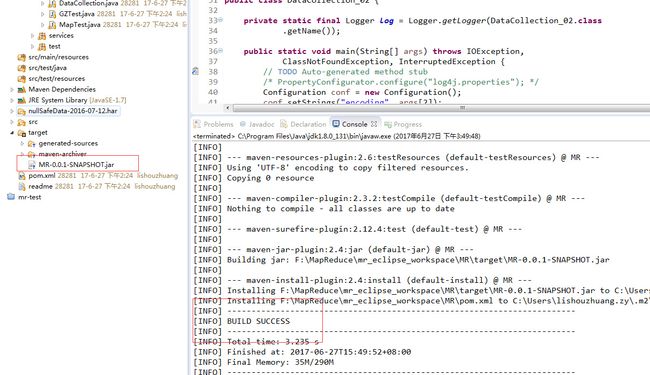
走到这里还有两步就可以跑了。让maven打jar包。
 移除点击此处添加图片说明文字
移除点击此处添加图片说明文字
放到服务器上,然后还有,把解压后的文件拿到hdfs上。
hadoop fs -put /data/data/SafeData-2017-06-26.har/ /user/hive/warehouse/testing.db/input/
因为总共有好多个GB,所以,要等很久,估计得有15分钟吧。然后可以开搞了。
hadoop jar /data/MR-0.0.1-SNAPSHOT.jar com.mr.DataCollection_02 /user/hive/warehouse/testing.db/input/ /user/hive/warehouse/testing.db/output/ utf-8
 移除点击此处添加图片说明文字
移除点击此处添加图片说明文字
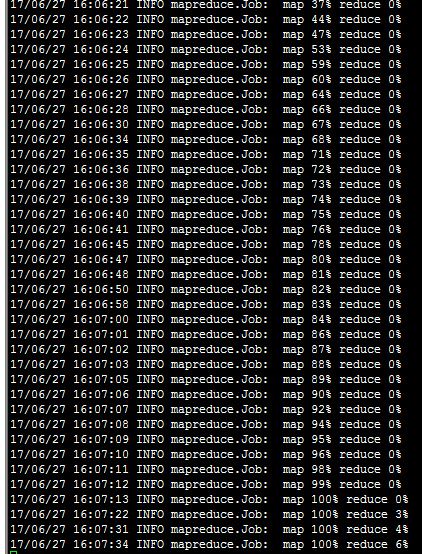
然后就开始跑了。。。但是总感觉不对劲啊,哪有这么快的,7个g,一下子就跑完了?等下我们看看。
 移除点击此处添加图片说明文字
移除点击此处添加图片说明文字
可以看一下时间间隔,实在是太快了。
 移除点击此处添加图片说明文字
移除点击此处添加图片说明文字
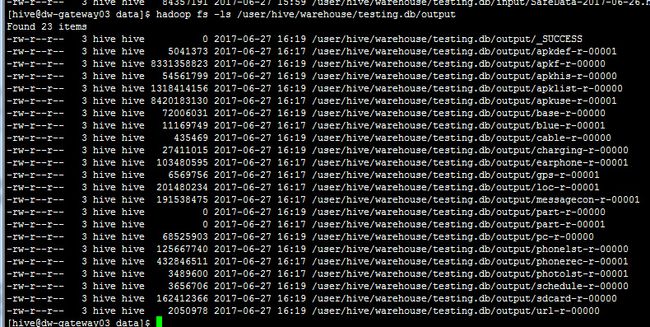
然后以后我们每天就可以用这个mr跑定时的按天过来的数据了,这个要交给shell脚本了,把命令一个个敲一下。那么现在,让我们把得到的数据,放到hive里,提供计算。首先库已经被创建了,我们去看一下。
进入后,切换用户,su hive
hive
show databases;
use d;
然后我们创建建表文档:
 移除点击此处添加图片说明文字
移除点击此处添加图片说明文字
然后创建建表语句:
 移除点击此处添加图片说明文字
移除点击此处添加图片说明文字
然后,我们建表发现报错:
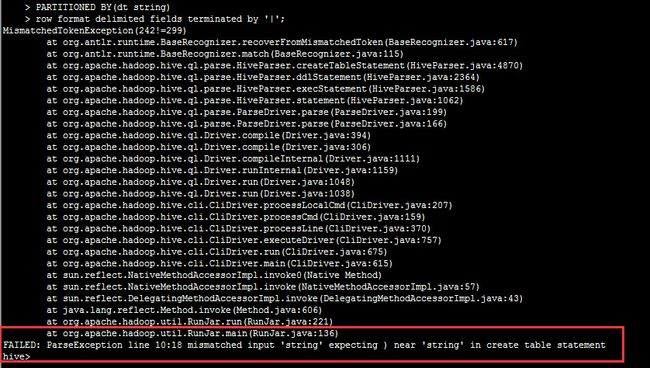 移除点击此处添加图片说明文字
移除点击此处添加图片说明文字
原因,由于两个string
 移除点击此处添加图片说明文字
移除点击此处添加图片说明文字
改好之后,我们重新创建表,出现ok
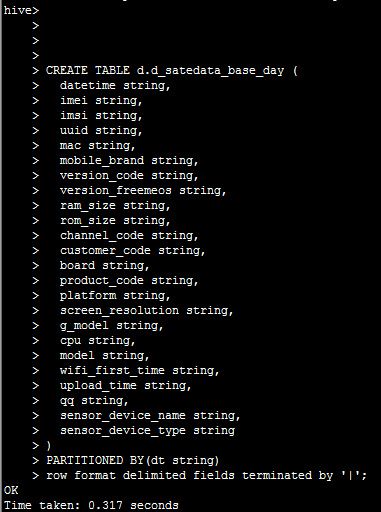 移除点击此处添加图片说明文字
移除点击此处添加图片说明文字
然后我们先查一下这个db下面发现没有分区:
hadoop fs -ls /user/hive/warehouse/d.db/d_satedata_base_day/
发现是空的,所以我们要去hive里面创建分区
然后我们创建分区:
alter table d.d_safedata_base_day add partition(dt='20170626');
接着查看一下
hadoop fs -ls /user/hive/warehouse/d.db/d_safedata_base_day/
 移除点击此处添加图片说明文字
移除点击此处添加图片说明文字
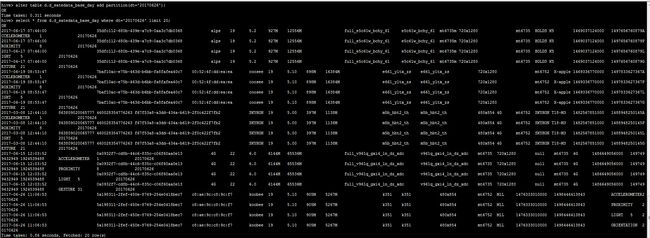
可以看到分区已经来了,接下来,我们要导入:
hadoop fs -cp /user/hive/warehouse/testing.db/output/base-r-* /user/hive/warehouse/d.db/d_safedata_base_day/dt=20170626
导入完毕之后,我们看一下
select * from d.d_safedata_base_day where dt='20170626' limit 20;
 移除点击此处添加图片说明文字
移除点击此处添加图片说明文字
数据导入hive成功。
但是,但是,当时间来到第四张表,也是晚上7点30时,发生了问题,挺严重的。
 移除点击此处添加图片说明文字
移除点击此处添加图片说明文字
等了一晚上,看别人的是没问题的,我靠,然后查一下。
在通过终端查询Hive时,终端结果显示为乱码。
这种情况出现的原因是:
1.ssh终端里的编码不是utf-8
如使用scrt,xshell等,都要把编码设成utf-8
2.hive在将数据写入hdfs时候,会把数据格式转换为utf-8格式的。
如果你导入hive表的源数据不是utf-8格式的,hive在进行写hdfs转换格式的时候会出现乱码,所有你查询出来的中文也是乱码。
解决办法:把源文件,用editplus等编辑软件打开,将文件转换为urf-8格式,保存。再重新导入到hive表中,问题解决。源文件只要是文本格式,如csv,txt,log等文本格式,均可用此种方法转化。
很显然是第一个原因,那我们就改xshell的编码格式。
文件-配置-》然后修改
 移除点击此处添加图片说明文字
移除点击此处添加图片说明文字
之后就可以了:
 移除点击此处添加图片说明文字
移除点击此处添加图片说明文字
这是个小坑,无所谓的,然后就是,领导提醒,这个表名称不可用,不可读,需要写完整了。那我们还得删除表。
最终经过很久,终于完成了。
 移除点击此处添加图片说明文字
移除点击此处添加图片说明文字
这是通话记录:
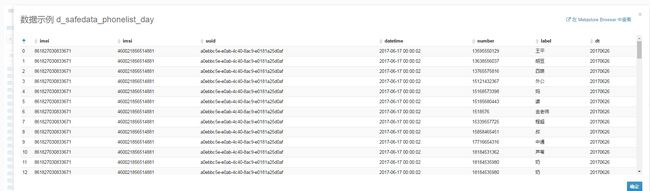 移除点击此处添加图片说明文字
移除点击此处添加图片说明文字
 移除点击此处添加图片说明文字
移除点击此处添加图片说明文字
当然也包括文档:
 移除点击此处添加图片说明文字
移除点击此处添加图片说明文字
好了,交差。现在hive里面可以处理了。这么做是有意义的啊,看一下:
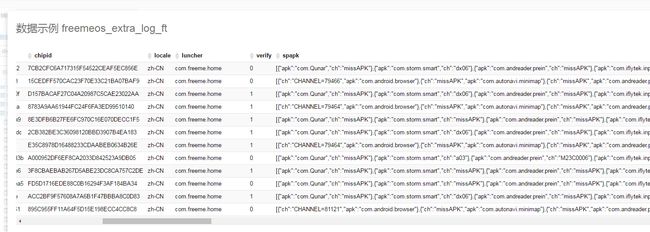 移除点击此处添加图片说明文字
移除点击此处添加图片说明文字
这样是没法作分析的,直接json数组放到字段里面。然而现在呢,
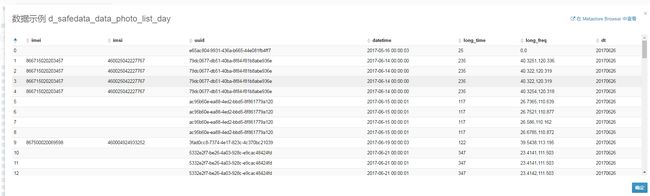 移除点击此处添加图片说明文字
移除点击此处添加图片说明文字
这样就完全可以处理了,维度被细粒化了,更容易做画像了。
好了,休息会儿吧,1点坐在电脑前到6点,动都没动过,交差了。
移除点击此处添加图片说明文字
接下来跑服务器环境,环境和本地有所区别了。
首先我们拿到几个目录,可以开干了。源数据目录,hdfs放置目录,集群地址即可。
移除点击此处添加图片说明文字
tar zxvf SafeData-2017-06-26.har.tar.gz -C /data/data/
移除点击此处添加图片说明文字
可以看到:
移除点击此处添加图片说明文字
因为这里是真正的集群环境,所以,有了环境变量:
移除点击此处添加图片说明文字
然后我们检查一下目录,找到他:
hadoop fs -ls /user/hive/warehouse/
移除点击此处添加图片说明文字
hadoop fs -mkdir /user/hive/warehouse/testing.db/input
hadoop fs -mkdir /user/hive/warehouse/testing.db/output
创建一个input输入,一个input输出。
走到这里还有两步就可以跑了。让maven打jar包。
移除点击此处添加图片说明文字
放到服务器上,然后还有,把解压后的文件拿到hdfs上。
hadoop fs -put /data/data/SafeData-2017-06-26.har/ /user/hive/warehouse/testing.db/input/
因为总共有好多个GB,所以,要等很久,估计得有15分钟吧。然后可以开搞了。
hadoop jar /data/MR-0.0.1-SNAPSHOT.jar com.mr.DataCollection_02 /user/hive/warehouse/testing.db/input/ /user/hive/warehouse/testing.db/output/ utf-8
移除点击此处添加图片说明文字
然后就开始跑了。。。但是总感觉不对劲啊,哪有这么快的,7个g,一下子就跑完了?等下我们看看。
移除点击此处添加图片说明文字
可以看一下时间间隔,实在是太快了。
移除点击此处添加图片说明文字
然后以后我们每天就可以用这个mr跑定时的按天过来的数据了,这个要交给shell脚本了,把命令一个个敲一下。那么现在,让我们把得到的数据,放到hive里,提供计算。首先库已经被创建了,我们去看一下。
进入后,切换用户,su hive
hive
show databases;
use d;
然后我们创建建表文档:
移除点击此处添加图片说明文字
然后创建建表语句:
移除点击此处添加图片说明文字
然后,我们建表发现报错:
移除点击此处添加图片说明文字
原因,由于两个string
移除点击此处添加图片说明文字
改好之后,我们重新创建表,出现ok
移除点击此处添加图片说明文字
然后我们先查一下这个db下面发现没有分区:
hadoop fs -ls /user/hive/warehouse/d.db/d_satedata_base_day/
发现是空的,所以我们要去hive里面创建分区
然后我们创建分区:
alter table d.d_safedata_base_day add partition(dt='20170626');
接着查看一下
hadoop fs -ls /user/hive/warehouse/d.db/d_safedata_base_day/
移除点击此处添加图片说明文字
可以看到分区已经来了,接下来,我们要导入:
hadoop fs -cp /user/hive/warehouse/testing.db/output/base-r-* /user/hive/warehouse/d.db/d_safedata_base_day/dt=20170626
导入完毕之后,我们看一下
select * from d.d_safedata_base_day where dt='20170626' limit 20;
移除点击此处添加图片说明文字
数据导入hive成功。
但是,但是,当时间来到第四张表,也是晚上7点30时,发生了问题,挺严重的。
移除点击此处添加图片说明文字
等了一晚上,看别人的是没问题的,我靠,然后查一下。
在通过终端查询Hive时,终端结果显示为乱码。
这种情况出现的原因是:
1.ssh终端里的编码不是utf-8
如使用scrt,xshell等,都要把编码设成utf-8
2.hive在将数据写入hdfs时候,会把数据格式转换为utf-8格式的。
如果你导入hive表的源数据不是utf-8格式的,hive在进行写hdfs转换格式的时候会出现乱码,所有你查询出来的中文也是乱码。
解决办法:把源文件,用editplus等编辑软件打开,将文件转换为urf-8格式,保存。再重新导入到hive表中,问题解决。源文件只要是文本格式,如csv,txt,log等文本格式,均可用此种方法转化。
很显然是第一个原因,那我们就改xshell的编码格式。
文件-配置-》然后修改
移除点击此处添加图片说明文字
之后就可以了:
移除点击此处添加图片说明文字
这是个小坑,无所谓的,然后就是,领导提醒,这个表名称不可用,不可读,需要写完整了。那我们还得删除表。
最终经过很久,终于完成了。
移除点击此处添加图片说明文字
这是通话记录:
移除点击此处添加图片说明文字
移除点击此处添加图片说明文字
当然也包括文档:
移除点击此处添加图片说明文字
好了,交差。现在hive里面可以处理了。这么做是有意义的啊,看一下:
移除点击此处添加图片说明文字
这样是没法作分析的,直接json数组放到字段里面。然而现在呢,
移除点击此处添加图片说明文字
这样就完全可以处理了,维度被细粒化了,更容易做画像了。
好了,休息会儿吧,1点坐在电脑前到6点,动都没动过,交差了。