hive 修改cluster by算法_疯狂Hive之DML操作(四)

DML操作
Load
在将数据加载到表中时,Hive不会进行任何转换。加载操作是将数据文件移动到与Hive表对应的位置的纯复制、移动操作。
语法结构:
load data [local] inpath ‘filepath’ [overwrite] into table tablename [partition(par2=val1,par2=val2......)]
说明:
1、filepath
相对路径:如project/data1
绝对路径:如/user/hive/project/data1
完整URI:如hdsf://namenode:9000/user/hive/project/data1
filepath可以引用一个文件(在这种情况下,Hive将文件移动到表中),或者它可以是一个目录(在这种情况下,Hive将把该目录中的所有文件移动到表中)
- Local
如果指定了local,load命令将在本地文件系统中查找文件路径
load命令会将filepath中的文件复制到目录文件系统中。目标文件系统由表的位置属性决定。被复制的数据文件移动到表的数据对应的位置
如果没有指定local关键字,如果filepath指向的是一个完整的URI,Hive会直接使用这个URI.否则:如果没有指定schema或者authority,Hive会使用在hadoop配置文件中定义的schema和authority,fs.default.name制定了Namenode的URI
- Overwrite
如果使用了overwrite关键字,则目标表(或者分区)中的内容会被删除,然后再将filepath指向的文件或目录中的内容添加到表或者分区中
如果目标表(分区)已经有一个文件,并且文件名和filepath中的文件名冲突,那么现有的文件会被新文件所替代
Insert
Hive中insert主要是结合select查询语句使用,将查询结果插入到表中,例如:
insert overwrite table stu_buck
select * from student cluster by (sno);
需要保证查询结果的数目和需要插入数据表格的列数目一致
如果查询出来的数据类型和插入表格对应的列数据类型不一致,将会进行转换,但还是不能保证装换一定成功,转换失败的数据将会为null
可以将一个查询出来的数据插入到原表中,结果相当于自我复制了一份数据。
Multi inserts多重插入
form source_table
insert overerite table tablename1 [partition (par1=val1,par2=val2.......)]
select_statement1
insert overerite table tablename2 [partition (par1=val1,par2=val2.......)]
select_statement1.....
多重插入
创建三张表,如下
create table source_table (id int,name string) row format delimited fields terminated by ',';
create table test_insert1(id int) row format delimited fields terminated by ',';
create table test_insert2(name string) row format delimited fields terminated by ',';
给source_table创建数据,新建文件source.txt,在文件中编写如下数据
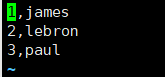
加载数据
命令:load data local inpath '/root/hivedata/source.txt' into table source_table;
执行多重插入
from source_table
insert overwrite table test_insert1
select id
insert overwrite table test_insert2
select name;

Dynamic partition inserts动态分区插入
语法:insert overwrite table tablename partition (par1=val1,par2=val2......) select_statement from from_statement;
动态分区是通过位置来对应分区值的。原始select出来的值和输出partition的值的挂你仅仅是通过位置来确定的,和名字并没有关系
动态分区插入
set hive.exec.dynamic.partition=true; #是否开启动态分区功能,默认是false关闭
set hive.exec.dynamic.partition.mode=nonstrict; #动态分区模式,默认是static,表示必须指定至少一个动态分区为静态分区,nonstrict模式表示允许所有的分区字段都可以使用动态分区
需求
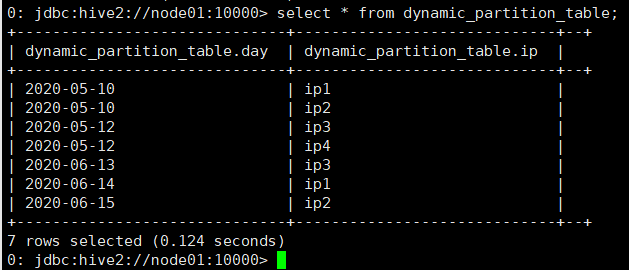
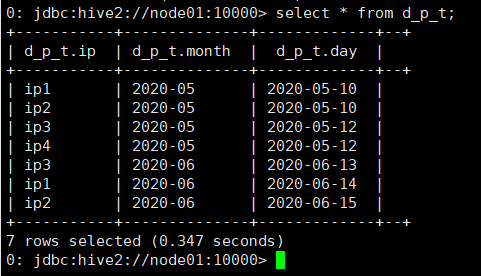
将dynamic_partition_table中的数据按照时间(day),插入到目标表d_p_t的相应分区中
原始表
create table dynamic_partition_table (day string,ip string) row format delimited fields terminated by ',';
数据信息
2020-05-10,ip1
2020-05-10,ip2
2020-05-12,ip3
2020-05-12,ip4
2020-06-13,ip3
2020-06-14,ip1
2020-06-15,ip2
load data local inpath '/root/hivedata/dynamic_partition_table.txt' into table dynamic_partition_table;
目标表
create table d_p_t(ip string) partitioned by (month string,day string);
动态插入
insert overwrite table d_p_t partition (month,day)
select ip,substr (day,1,7) as month,day
from dynamic_partition_table;
导出表数据
语法结构:
insert overwrite [local] directory directory1 select.....form.....
multiple inserts:
from form_statement
insert overwrite [local] directory directory1 select_statement1
[insert overwrite [local] directory directory1 select_statement1].....
数据写入到文件系统时进行文本序列化,且每列用^A来区分,n为换行符
查询结果导出到文件系统
将查询的结果保存到指定的文件目录(可以是本地,也可以是HDFS)
需求:将Hive中source_table中数据导入到node01上的hive目录下
创建hive目录:mkdir hive
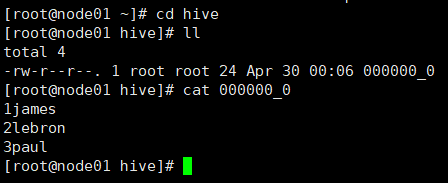
insert overwrite local directory '/root/hive'
select * from source_table;
执行完成查看是否有数据导出
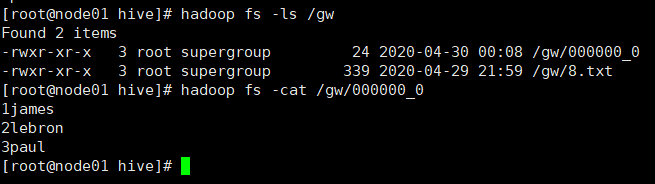
需求:将Hive中source_table中数据导入到HDFS上的gw目录下
insert overwrite directory '/gw'
select * from source_table;
执行完成查看是否有数据导出
Select
基本的select操作
语法结构
Select [all | distinct] select_expr,select_expr,.....
Form table_reference
Join table_other on expr
[where where_condition]
[group by col_list[having condition]]
[cluster by col_list
| [distribute by col_list] [sort by | order by col_list]
]
[limit number]
说明:
- order by会对输入做全局排序,因此只有一个reducer,会导致当输入规模较大 时,需要较长的计算时间
- sort by 不是全局排序,其在数据进入reducer前完成排序。因此,如果用sort by 进行排序,并且设置mapred.reduce.tasks>1,则sort by只保证每个reducer的 输出有序,不保证全局有序
- Distrubute by(字段) 根据指定字段将数据分到不同的reducer,分发算法是 hash散列。
- Cluster by(字段) 除了具有distribute by的功能,还会度该字段进行排序。
如果distribute和sort的字段是用一个时,此时,cluster by = distribute by + sort by
分桶、排序查询
select * from student cluster by(sno);
如下语句会报错,应为cluster和sort不能共存
select * from student cluster by(sno) sort by (sage asc);
对某列进行分桶的同时,根据另一个进行排序
select * from student distribute by(sno) sort by(sage asc);
总结
cluster(分且排序,必须一样)==distribute(分) + sort(排序)(可以不一样)
Hive join操作
Hive中除了支持和传统数据库中一样的内关联、左关联、右关联、全关联,还支持left semi join 和cross join,但是两种join类型也可以用前面的代替
Hive支持等值连接(a.id=b.id),不支持非等值(a.id>b.id)的连接,因为非等值连接非常男转化到map/reduce任务。另外,Hive支持多2个以上表之间的join
写join查询时,需要注意一下几点:
join时,每次map/reduce任务的逻辑:
Reduce会缓存join序列中除了最后一个表的所有表的记录,再通过最后一个表将结果序列化到文件系统。这一实现有助于在reduce端减少内存的使用量。实践中,应该把最大的那个表写在最后(否则或因为缓存浪费大量内存)
left,right和full outer关键字用于处理join中空记录的情况
对应所有a变中的记录都有一条记录输出。输出的结果应该是a.val,b.val,当a.key=b.key时,而当b.key中找不到等值的a.key记录时也会输出:
a.val,null
所以a表中的所有记录都被保留了
a right outer join b 会保留所有b表的记录
准备数据
a表数据
1,a
2,b
3,c
4,d
7,y
8,u
b表数据
2,bb
3,cc
7,yy
9,pp
建表
create table a(id int,name string) row format delimited fields terminated by ',';
create table b(id int,name string) row format delimited fields terminated by ',';
导入数据
load data local inpath '/root/hivedata/a.txt' into table a;
load data local inpath '/root/hivedata/b.txt' into table b;
实验
设置Hive本地模式执行,提高执行效率
set hive.exec.mode.local.auto=true;
内关联:inner join
select * fro a inner join b on a.id = b.id
左关联:left join
select * from a left join b on a.id=b.id;
右关联:right join
select * from a right join b on a.id=b.id;
全关联:full outer join
select * from a full outer join b on a.id=b.id;
Hive中的特别join
select * from a left semi join b on a.id=b.id
