速通yolov5s.yaml
源码注释版参考:
YOLOv5的Backbone详解_Marlowee的博客-CSDN博客_yolov5 backbone
YOLOv5的head详解_Marlowee的博客-CSDN博客_head yolov5
文章目录
-
-
- conv
-
-
- 网络结构
- 源码
- 参数解读
- 作用
-
- concat
-
-
- 网络结构
- 源码
- 参数解读
- 作用:
-
- C3
-
-
- 网络结构
- 源码
- 参数解读
- 作用
-
- SPPF
-
-
- 网络结构
- 源码
- 参数解读
- 作用
-
- Upsample
-
-
- 网络结构
- 源码
- 参数解读
- 作用
-
- Detect
-
-
- 参数解读
-
-
conv
网络结构
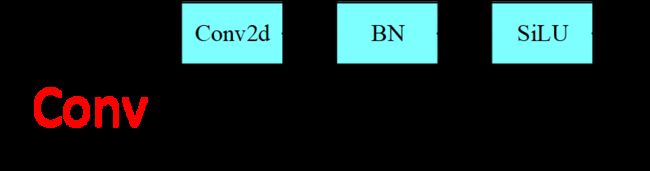
源码
# 标准卷积操作:conv2D+BN+SiLU
# 在Focus、Bottleneck、BottleneckCSP、C3、SPP、DWConv、TransformerBloc等模块中调用
class Conv(nn.Module):
# Standard convolution
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True):
"""
:params c1: 输入的channel值
:params c2: 输出的channel值
:params k: 卷积的kernel_size
:params s: 卷积的stride
:params p: 卷积的padding 一般是None 可以通过autopad自行计算需要pad的padding数
:params g: 卷积的groups数 =1就是普通的卷积 >1就是深度可分离卷积
:params act: 激活函数类型 True就是SiLU()/Swish False就是不使用激活函数
类型是nn.Module就使用传进来的激活函数类型
"""
super().__init__()
# bias是空洞卷积的时候,之间的距离参数
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
# 这里的nn.Identity()不改变input,直接return input
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
return self.act(self.bn(self.conv(x)))
# 前向加速推理模块
# 用于Model类的fuse函数,融合conv+bn 加速推理 一般用于测试/验证阶段
def forward_fuse(self, x):
return self.act(self.conv(x))
参数解读
[ from, number, model, args ]
[-1, 1, Conv, [64, 6, 2, 2]
from:-n表示从第n层获得输入
number: 网络模块数量
model: 网络模块的名称
args:[ch_out, kernel, stride, padding, groups] 省略了ch_in(输入通道),直接默认了是上一层的输出通道数
注意:
反映不出来一张照片的像素大小
如:input: 3x640x640
[ch_out, kernel, stride, padding]=[64,6,2,2]
故新的通道数为64x0.5=32(这里0.5是width_multiple)
根据特征图计算公式:Feature_new=(Feature_old-kernel+2xpadding)/stride+1可得:新的特征图尺寸为:
Feature_new=(640-6+2x2)/2+1=320
作用
①通过矩阵的点乘来提取图片中的特征
②1×1时候改变通道数
concat
网络结构

源码
class Concat(nn.Module):
# Concatenate a list of tensors along dimension
# 沿维度连接张量列表
def __init__(self, dimension=1):
super().__init__()
self.d = dimension
def forward(self, x):
return torch.cat(x, self.d)
参数解读
[[-1, 6], 1, Concat, [1]] # cat backbone P4
[ -1, 6 ]: 表示把上一层和第六层的拼接起来(这里可以把特征图打印出来,特别明显)
1: block的number
Concat: module
[ 1 ]: 指定拼接维度,此处按照维度1进行拼接,其他维度不变(只拼接channel维度:相加)
作用:
把两个层的通道数连接起来,合并前后两个feature map
C3
网络结构
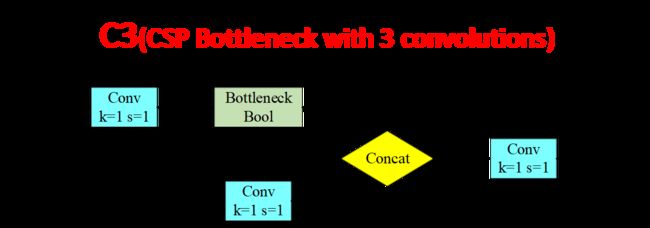
C3模块其实是简化版的BottleneckCSP,该部分除了Bottleneck之外,只有3个卷积模块,可以减少参数,所以取名C3
在backbone中有shortcut,而在Neck中不存在shortcut模块(因为backbone已经完成了特征的提取,Neck就不用一味的加深网络(不带残差))。这也是为什么Neck端的C3block有False的参数
源码
class C3(nn.Module):
# C3() is an improved version of CSPBottleneck()
# It is simpler, faster and lighter with similar performance and better fuse characteristics
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # act=FReLU(c2)
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
# self.m = nn.Sequential(*[CrossConv(c_, c_, 3, 1, g, 1.0, shortcut) for _ in range(n)])
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))
参数解读
[-1, 3, C3, [1024]],
-1:-1表示从上一层获得输入
3: 有3个C3模块
c3: 模块的名称(和yolo.py和commom.py相对应)
[1024]: 输出通道数
作用
精简网络结构,减少计算量,降低模型推理时间
SPPF
网络结构

源码
class SPPF(nn.Module):
# Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher
def __init__(self, c1, c2, k=5): # equivalent to SPP(k=(5, 9, 13))
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * 4, c2, 1, 1)
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
def forward(self, x):
x = self.cv1(x)
with warnings.catch_warnings():
warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning
y1 = self.m(x)
y2 = self.m(y1)
return self.cv2(torch.cat([x, y1, y2, self.m(y2)], 1))
参数解读
[-1, 1, SPPF, [1024, 5]
[1024, 5]: 输出通道数1024和最大池化卷积核为5×5
作用
为了保证准确率相似的条件下,减少计算量,以提高速度,使用3个5x5的最大池化,代替原来的5×5、9x9、13×13最大池化
Upsample
网络结构
可参考FPN上采样的网络结构(我猜的)
源码
见Pytorch官方
参数解读
[-1, 1, nn.Upsample, [None, 2, 'nearest']]
[None, 2, ‘nearest’]: 上采样倍数为2,采样样式为nearest,也就是最近填充
作用
上采样,提取语义特征
Detect
参考:YOLOv5的head详解_Marlowee的博客-CSDN博客_head yolov5
里面有detect的源码解读
参数解读
[17, 20, 23], 1, Detect, [nc, anchors]
[17, 20, 23]: 指那些层数传递到Detect层中
1: number
Detect: name