机器学习模型自我代码复现:KD树
根据模型的数学原理进行简单的代码自我复现以及使用测试,仅作自我学习用。模型原理此处不作过多赘述,仅罗列自己将要使用到的部分公式。
如文中或代码有错误或是不足之处,还望能不吝指正。
某些机器学习模型,如KNN,中,需要在n维空间上计算距离,找到训练样本中距离自身最近的那一个点。如果直接计算距离,就需要O(n²)的时间复杂度。故而需要引入KD树作为索引,以此搜索最近距离的点。
KD树的大致原理,就是在每一层中,根据剩余数据集中方差最大的特征排序,选取正中间的点作为节点值,将左右两边的值分别构建左右子树。
在搜索时,
1 首先从根节点开始,根据当前节点的分割特征判断像左还是向右移,直至达到叶子节点。
2 将叶子节点作为“最近点”,并从叶子节点开始向前回溯,计算到此节点距离是否更小。是的话替代
3 在回溯过程的同时,还需要与当前节点的父节点进行比较:如果点到父节点对应所在的(超)平面(也就是父节点分割依据的那个特征所在平面)距离小于到当前节点的2点的距离, 那么就代表目标点其兄弟节点的距离有可能更短,应当从其兄弟节点处重新执行1~3步。
这里其实很好理解,因为目标点到平面的距离是垂直的最短距离,如果点到当前节点的距离比这个距离小,那么在平面上的其他节点也会小于这个距离。但是点到当前节点的距离比垂直距离更大时,那么兄弟节点就有可能成为那个“距离更小的节点”。
import numpy as np
from collections import deque
class Node:
def __init__(self,value=None,split=None,left=None,right=None,father=None):
self.value = value
self.split = split
self.left = left
self.right = right
self.father = father
class KDTree:
def __init__(self,x=None):
if x is not None:
self.root = self.buildtree(x)
else:
self.root = Node()
def get_median(self,sub_x):
x = list(sub_x)
length = len(x)
x_order = sorted(x)
return x_order[length//2],x.index(x_order[length//2])
def buildtree(self,x):
if len(x)== 0:
return None
#寻找方差最大的那个方向
max_std = 0
max_idx = 0
for i in range(x.shape[1]):
std = np.std(x[:,i])
if std>max_std:
max_idx = i
max_std = std
#找到中点
v,v_idx=self.get_median(x[:,max_idx])
#根据中点值分割
cur = Node(value=x[v_idx,:],split=max_idx)
left_idx = []
right_idx = []
for i in range(len(x)):
if x[i,max_idx]>v:
right_idx.append(i)
elif x[i,max_idx]而对于“在目标点的周围搜索K个最邻近的点”这一问题,应该将逻辑替换为“先保存k个节点,等到遇到距离更小的节点再替换保存的距离最大的节点”。很可惜我只找到理论部分,而sklearn的代码是pyd,我也没有找到反汇编(或是反编译?我个人缺乏此处的知识),自己写了部分代码,没有经过大量实验,故而只能作为参考,并不能作为真正的使用代码。
def search_nearest_k(self,x,k):
if k == 0:
return None
last_node = self.get_leaf(x,self.root)
que = [(self.root,last_node.father)]
que = deque(que)
distance = self.dist(x,last_node)
selected_nodes = [(last_node,distance)]
while que:
root,cur = que.popleft()
while cur is not root:
dist = self.dist(x,cur.value)
if len(selected_nodes)=distance:
selected_nodes.append((cur,dist))
else:
selected_nodes = [(cur,dist)]+selected_nodes
elif dist 使用numpy随机生成数据进行测试
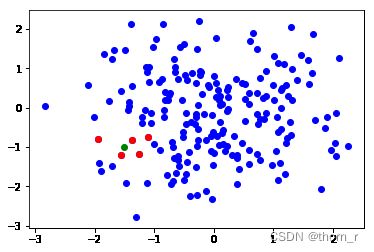
尽管从图中看起来成功找到了最近的5个点,但是在没有经过大批量的数据测试,故而仅供参考。