知识蒸馏 | 综述: 知识的类型
每天给你送来NLP技术干货!
来自:GiantPandaCV
作者:pprp
这篇是知识蒸馏综述的第一篇,主要内容为知识蒸馏中知识的分类,包括基于响应的知识、基于特征的知识和基于关系的知识。
1知识蒸馏简介
定义:知识蒸馏代表将知识从大模型向小模型传输的过程。
作用:可以用于模型压缩和训练加速 手段。
综述梳理思路:
知识蒸馏的种类
训练机制
教师-学生 架构
蒸馏算法
性能比较
实际应用
典型的知识蒸馏KD是Hinton于15年发表的paper,明确了知识蒸馏的想法是让学生模型通过模仿教师模型来取得具有竞争性的性能,甚至可以取得超越教师网络的性能。
知识蒸馏的核心研究:如何将知识从大模型传递给小模型。
知识蒸馏系统的三个核心组件:
知识 knowledge
蒸馏算法 distillation algorithm
教师学生架构 teacher-student architecture

知识蒸馏相关的扩展方向:
teacher - student learning
mutual learning
assistant teaching
life long learning
self learning
在知识蒸馏中,我们主要关心:知识种类、蒸馏策略、教师学生架构
最原始的蒸馏方法是使用大模型的logits层作为教师网络的知识进行蒸馏,但知识的形式还可以是:激活、神经元、中间层特征、教师网络参数等。可以将其归类为下图中三种类型。

2基于响应的知识(Response-Based Knowledge)

基于响应的知识一般指的是神经元的响应,即教师模型的最后一层逻辑输出。
响应知识的loss:
其核心想法是让学生模型模仿教师网络的输出,这是最经典、最简单、也最有效的处理方法
Hinton提出的KD是将teacher的logits层作为soft label.
T是用于控制soft target重要程度的超参数。
那么整体蒸馏loss可以写作:
一般来讲使用KL散度来衡量两者分布差异,通过优化以上loss可以使得学生网络的logits输出尽可能和教师网络的logits输出相似,从而达到学习的目的。
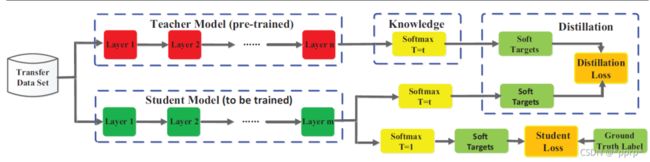
KD中除了蒸馏的一项通常还会使用交叉熵损失函数令学生网络学习真实标签(也称hard label),两项联合起来进行训练。
KD通常的解释是学生网络可以从教师网络中学习到额外的隐形知识(dark knowledge), 而这种知识要比通过标签学习的知识更容易理解。
KD其他角度的解释还包括:KD可以生成类似label smooth的soft target;KD可以视为一种正则化方法;
基于响应的知识只用到了模型最后一层logits中包含的知识,而并没有用到中间层的监督,而中间层的监督信息在表征学习中非常有用。
3基于特征的知识(Feature-Based Knowledge)
在深度卷积神经网络中,网络学习到的知识是分层的,从浅到深层对应的知识抽象程度越来越高。因此中间层的特征也可以作为知识的载体,供学生网络进行学习。
基于特征的知识可以视为基于响应的知识的一个扩展。
FitNets是第一个引入中间层表征的,教师网络的中间层可以作为学生网络对应层的提示(Hints层)从而提升学生网络模型的性能。其核心是期望学生能够直接模仿教师网络的特征激活值。
以FitNets为基础扩展出几篇工作:
Paying more attention to attention: 提出去学习从原先特征图中派生得到的注意力图(Attention map)
Like what you like: Knowledge distill via neuron selectivity transfer: 认为神经元是有选择性的,而这种选择性与任务是相关的,提出神经元选择性迁移,将教师与学生这种神经元的选择模式分布对齐。通过引入了MMD Matching Loss进行实现。
Learning deep representation with probabilistic knowledge transfer: 通过匹配特征空间的概率分布迁移知识。
paraphrasing complex network: Network Compression via factor transfer:引入factor作为一种中间层表征的可理解形式。
Knowledge distillation via route constrained optimization: 致力于降低教师网络和学生网络的gap,提出使用路线约束的暗示学习(Hints learning)。
Knowledge transfer via distillation of activation boundaries formed by hidden neurons: 提出使用隐层神经元的激活边界进行知识迁移。
Cross-Layer Distillation with Sematic Calibration: 为了匹配教师网络和学生网络的语义信息,提出通过attention allocation自适应为学生层分配合适的教师层, 实现跨层的知识蒸馏。

基于特征的知识迁移可以建模为:
其中表示一个转换函数,因为教师网络和学生网络的特征层可能出现尺寸不匹配的情况,所以需要转换。表示用于匹配教师网络和学生网络的相似度计算函数。
下图总结了各个基于特征的知识的匹配类型:

一般而言,在基于特征的知识迁移中,研究的对象包括了:
如何需选择知识类型?特征图、注意力图、gram矩阵或其他
如何选择教师层和学生层?简单的一对一匹配,自适应通过注意力匹配。
如何弥补教师网络与学生网络之间的GAP?如果容量相差过大,可能会导致学习效果变差。
4基于关系的知识(Relation-Based Knowledge)
基于关系的知识进一步扩展了基于响应的知识以及基于特征的知识,更全面深入的探索了不同层、不同数据样本之间的关系。
不同层之间的关系建模
A gift from knowledgedistillation:fast optimization, network minimization and transfer learning: (FSP) 提出了Flow of solution process(FSP)的方法,定义了两个层之间的Gram矩阵,从而可以总结特征图不同对之间的关系。https://github.com/yoshitomo-matsubara/torchdistill/blob/5377be466c9460e0125892aa0d92aeb86418c752/torchdistill/losses/single.py L110行有具体实现。
self-supervised knowledge distillation using singular value decompostion: 提出利用特征图之间的相关性进行蒸馏,使用奇异值分解的方式来提取特征图中关键信息。
Better and faster: knowledge transfer from multiple self-supervieds learning tasks via graph distillation for video classification: 为了使用多个教师网络的知识,构建了使用logits层和特征图作为节点的两个graph。
Graph-based knowledge distillation by multi-head attention network: 提出使用Multi head graph-based 知识蒸馏方法,通过使用graph建模两两feature map之间的关系。
Heterogeneous Knowledge Distillation using information flow modeling: 提出让学生模仿教师网络信息流动过程来得到知识。
基于关系的知识通常可以建模为:
表示学生网络内成对的特征图,代表相似度函数,代表教师网络与学生网络的关联函数。
不同样本之间的关系建模
传统的知识迁移通常只关心个体知识蒸馏,但是通常知识不仅包括特征的信息,还包括数据样本之间的互作用关系。
Knowledge distillation via instance relationship graph提出了通过个体及关系图进行知识蒸馏的方法,迁移的知识包括个体级别特征。Relational knowledge distillation提出关系知识蒸馏,从个体关系中进行知识迁移Learning student networks via feature embedding结合流型学习,学生网络可以通过特征嵌入进行学习,从而保证教师网络中间层特征的样本相似度。Probabilistic Knowledge Transfer for Lightweight Deep Representation Learning使用概率分布来建模教师网络和学生网络的关系。Similarity-preserving knowledge distillation提出相似性保留的知识,使得教师网络和学生网络根据相同的样本对产生相似的激活。Correlation congruence for knowledge distillation提出基于关系一致的知识蒸馏方法,可以同时蒸馏instance-level的信息以及between instance的信息。

instance relation的建模如下:
与不同层之间建模不同的是,上边的公式衡量的对象是层与层的关系即:, 而此处衡量的是样本与样本之间的关系(如上图所示),即
下表对蒸馏知识从不同角度进行分类,比如数据的结构化知识、输入特征的专有知识等。

5参考
Gou, J., Yu, B., Maybank, S.J., & Tao, D. (2021). Knowledge Distillation: A Survey. ArXiv, abs/2006.05525.
https://arxiv.org/pdf/2006.05525.pdf
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看!