Paper Reading——MoreFusion: Multi-object Reasoning for 6D Pose Estimation from Volume基于体素融合的多目标6D位姿估计
摘要
机器人和其他智能设备需要从视觉系统中获得高效的基于目标对象的场景表示,以进行接触、遮挡等物理特性的推理。已知的精确目标模型在未知结构的非参数化重建中起着十分重要的作用。我们提出了一个系统,该系统可以实时估计多视角场景中接触和遮挡的多个已知对象的精确位姿。我们的方法从单个RGB-D视图中估计3D对象位姿,当相机移动时,积累来自多个视图的位姿估计和非参数占用信息,并执行联合优化以对接触的多个接触目标进行一致非交叉的位姿估计。我们在富有挑战性的YCB-Video数据集上通过实验验证了我们方法的准确性和鲁棒性。我们演示了一个实时机器人应用,机械臂仅搭载一个RGB-D相机,就能精确有序地拆解复杂的堆积物。
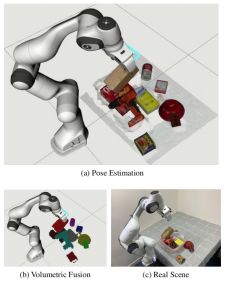
MoreFusion通过通过体素图显式地推断出占用空间和自由空间,可以生成准确的6D对象位姿估计。我们在实时机器人抓取应用程序中演示了该系统。
简介
对于执行复杂任务的机器人和其他智能设备,在杂乱的环境中进行精确的操作,需要从相机中捕获信息,以实现对物体之间的接触、遮挡等物理特性的推理。虽然之前有研究已经表明,一些短期任务可以使用端到端的学习模型来完成,将传感数据和动作进行映射,但我们认为,扩展和多阶段的任务可以从连续的3D场景表示中受益。
在场景中的物体具有已知模型的情况下,即使使用最先进的检测器,估计相互遮挡和接触的物体的位姿仍然是一个挑战。在本文中,我们提出了一个可以解决这个问题的视觉系统,从单个移动RGB-D相机的多视角图像中实时生成一个连续的3D多物体表示。我们的系统主要有四个部分,如图2所示:1)对RGB-D数据进行2D物体检测,并将其送入物体级融合,制作物体的体素占用图。2)利用RGB-D数据和周围的占位网格的位姿估计网络进行3D物体位姿估计。3)基于碰撞的位姿,联合优化多个物体的位姿,并进行可区分的碰撞检测。4)用信息丰富的CAD模型代替物体对象的体素表示。
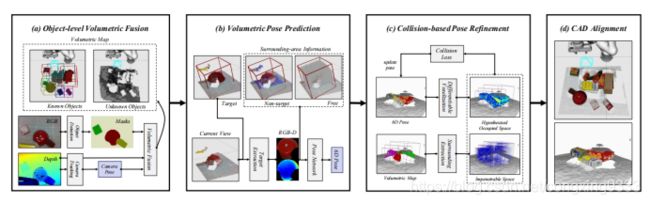
我们的6D位姿估算系统。将来自RGB图像的对象分割蒙版融合到一个体素图中,该体素图表示已占用空间和自由空间(a)。将该体素图与目标对象作物的RGB-D数据一起使用,以进行初始6D位姿估计(b)。然后通过可区分的碰撞检查(c)完善此位姿,然后将其用作CAD对齐阶段的一部分,以丰富体素图(d)。
我们的系统利用深度信息和多视图来估计物体的位姿。当模型能够基本对齐,并且不与其他物体相交时,将最初的粗略体素重建提升为精确的CAD模型拟合。这种能够估计多个物体位姿以及相互遮挡和接触的算法,使得机器人能够在杂乱的场景中进行拾取和放置,例如图1,机器人去除障碍物以拾取红框中的目标。
综上所述,本文的主要贡献有:
1.具有周围空间感知的位姿估计能力,其中估计网络接收体素占用栅格,作为对象不可穿透的空间;
2.联合优化多对象的位姿,其中使用可区分的碰撞检查评估和具有多个对象的场景配置;
3.将体素融合和6D位姿集成为一个实时系统,在该系统中,利用对象级体素图来进行精确的位姿估计。
相关工作
基于模板的方法[15],[26],[12],[11],[13],[24]是最早的位姿估计方法之一。传统上,这些方法涉及通过在离线训练阶段从不同的角度收集对象(或3D模型)的图像来生成模板,然后使用距离度量在整个图像上扫描模板以找到最佳匹配。这些方法对混乱,遮挡和光照条件敏感,导致许多误报,进而需要更大的后处理。多年来,基于特征的稀疏方法已成为基于模板的方法的流行替代方法[16],[21],[22]。这些方法涉及从图像中提取尺度不变点的兴趣点,使用局部描述符(例如SIFT [17]或SURF [1])描述它们,然后将它们存储在数据库中,以便以后在测试时与之匹配,以获得使用RANSAC [8]之类的方法估算位姿。可以在操纵任务(例如MOPED [5])中看到此处理管道。随着负担得起的RGB-D相机的增加,密集方法在对象和位姿识别中变得越来越流行[7],[25],[3]。这些方法包括构建目标对象的3D点云,然后使用流行的算法(如迭代最近点(ICP)[2])将其与存储的模型进行匹配。
现在,在6D位姿估计领域中普遍使用深度神经网络。PoseCNN [29]是训练端到端系统以直接从RGB图像直接估计初始6D对象位姿的第一批工作之一,然后使用基于深度的ICP对其进行完善。最近基于RGB-D的系统是PointFusion [31]和DenseFusion [28],它们分别处理两种传感器模式(RGB的CNN,PointNet [23])。(针对点云),然后将它们融合以提取逐像素的密集特征嵌入。我们的工作与这些RGB-D和具有深度神经网络的基于学习的方法最为相关。与先前工作中基于点云的方法和以目标对象为重点的方法相比,我们使用结构化的体素表示法处理几何对象,并围绕目标对象进行了几何信息处理。
MoreFusion
我们的系统估计给定杂乱场景的RGB-D图像的一组已知物体的6D位姿。我们将6D位姿表示为一个均匀的变换矩阵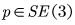
,并将位姿表示为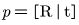
,其中,![]()
是旋转变换,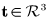
为平移变换。
我们的系统,总结在图2中,可以分为四个关键阶段。(1)物体级体素融合阶段,将物体检测产生的物体实例掩码与深度测量和相机跟踪组件相结合,产生已知和未知物体的体素图。(2)空间位姿估计阶段,利用空间图的周围信息和RGB-D掩码,产生每个物体的初始位姿估计。(3)基于碰撞的位姿细化阶段,该阶段利用对象CAD模型与来自体素地图的占用空间之间的可区分碰撞检查,通过梯度下降联合优化多个对象的位姿。(4)CAD对齐阶段,将每个物体的中间表示替换为CAD模型,包含紧凑而丰富的信息。在下面的章节中,我们将进一步阐述这些阶段的每一个阶段。
3.1 目标级体素融合
建立体测图是我们的位姿估计系统的第一步,它允许系统逐渐增加有关场景的知识,直到对场景中的对象位姿有信心为止。对于此对象级体素融合阶段,我们构建类似于[18],[27]和[30]的管道,将RGB-D相机跟踪,对象检测和检测到的对象的体素映射相结合。
RGB-D相机追踪
假设将相机安装在机械臂的末端,则我们可以使用正向运动学和经过良好校准的相机来检索相机的准确位姿。但是,为了也可以将其与手持式相机配合使用,我们采用稀疏的SLAM框架ORB-SLAM2 [20]进行相机跟踪。不同于其单眼的前身[19],ORB-SLAM2跟踪度量空间中的相机位姿,这对于体素映射至关重要。
物体检测
基于现有的工作[18] ,[30],RGB图像被传递到MASK-RCNN [9]其中产生2D实例掩模。
检测对象的体素映射
我们将基于八叉树的占用率映射OctoMap [14]用于体素映射。通过使用八叉树结构,OctoMap可以从查询点快速检索体素,这对于从深度测量值更新占用率值以及在管道的后续(位姿估计和细化)组件中使用时检查占用率值都是至关重要的。
我们为每个检测到的对象(包括未知(背景)对象)构建此体素图。为了跟踪已经初始化的对象,我们在当前帧中使用检测到的遮罩的并集的相交,并按照先前的工作[18],[30]渲染遮罩电流重建。对于已经初始化的对象,我们将新的深度测量值融合到该对象的体素图上,并在移动相机时找到新对象时初始化新的体素图。该对象级重构使得能够通过位姿估计在模型对准之前将对象的体素表示用作中间表示。
3.2 位姿估计
我们的系统从体素图检索周围的信息,以将对目标对象周围区域的空间感知纳入位姿估计。在本节中,我们描述如何在位姿估计中表示和使用周围的信息。
3.2.1将占用栅格作为周围信息
位姿估计的每个目标对象都带有自己的体素占用网格。组成这个网格的体素可以处于以下状态之一:(1)在目标对象重建中被对象本身占用的空间。(2)重建周围物体所占用的其他物体空间。(3)深度测量确定的自由空间。(4)由于遮挡和传感器范围限制,地图无法观测到的未知空间(图3)。
理想情况下,即使被遮挡,周围信息的包围框也应该覆盖目标对象的整个区域。这意味着边框的大小应该根据目标对象的大小而改变。由于我们需要使用固定的体素维来进行网络估计(例如32×32×32),所以我们根据对象模型的大小(包围框的对角线除以体素维)计算出每个对象的体素大小。
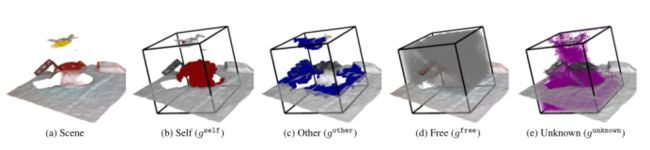
周围的空间信息。这些数字显示了红色碗的占用网格(32×32×32体素)。自由(d)和未知(e)网格用点而不是立方体来显示可见性。
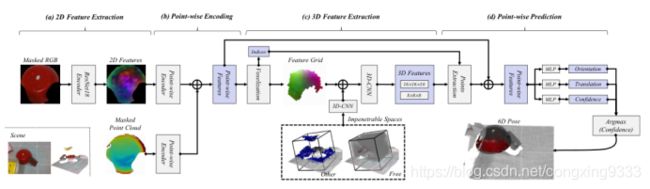
网络架构,它使用隐藏目标对象的RGB-D及其周围信息作为占用网格来执行位姿估计。
3.2.2 位姿估计算法的网络架构
每个对象的初始6D位姿是通过一个深度神经网络(图4中进行了总结)进行估计的,该神经网络同时接受第3.2.1节中所述的占用栅格信息和蒙版RGB-D图像。该体系结构可分为4个核心组件:(1)从ResNet的RGB中提取2D特征;(2) RGB特征和点云的逐点编码;(3) 3D-CNN之后的点状特征的体素化;(4)从2D和3D特征进行逐点位姿估计。
从RGB提取2D特征
即使可以进行深度测量,RGB图像仍然可以携带重要的传感器信息,以进行精确的位姿估计。由于RGB图像中的颜色和纹理细节,对于高度纹理化和非对称对象的位姿估计,这可能是一个特别强的信号。
继[28],[31]之后,我们将ResNet18 [10]与后续的上采样层[32]一起使用,以从蒙版图像中提取RGB特征。尽管两种先前的方法[28],[31]都使用带有边框的对象的裁剪图像,但是我们使用了蒙版图像,使网络不改变背景外观,并鼓励其专注于使用占用网格来检索周围的信息。
Rgb功能和点云的逐点编码
与[28]相似,RGB特征和提取的点云点(使用目标对象蒙版)都通过几个完全连接的层进行编码,以生成逐点特征,然后将其进行级联。
体素化和3D-CNN处理
从这些点状要素中,我们构建了一个要素栅格(与占用栅格的尺寸相同),该栅格将与从体素融合中提取的占用栅格合并。3D-CNN处理串联的体素网格,以提取分层的3D特征,从而减少体素尺寸并增加通道大小。我们使用2步卷积处理原始网格(体素尺寸:32)以具有分层特征(体素尺寸:16、8)。
此管道中的一个重要设计选择是在体素化之前执行2D特征提取,而不是直接在原始RGB像素值的体素网格上应用3D特征提取。尽管3D CNN和2D CNN在处理RGB-D输入时具有相似的行为,但与2D图像不同,很难在高分辨率网格上使用3D CNN,而且体素化网格比RGB图像具有更多的缺失点,因为深度图像中的传感器噪声。
从2D-3D功能进行逐点位姿估计
为了将2D和3D特征组合在一起进行位姿估计,我们从3D特征网格中提取了与使用Triliner插值的逐点2D特征相对应的点。这些3 d和2D特征被连接为位姿估计的逐点特征向量,从中我们可以估计位姿和置信度,如[28]所示。
3.2.3训练位姿估计网络
训练损失函数
对于逐点位姿估计,我们遵循DenseFusion [28]进行训练损失,这是来自PoseCNN [29]的模型对齐损失的扩展版本。对于每个逐像素估计,此损失将计算通过地面真实性和估计位姿(位姿损失)转换后的对象模型相应点的平均距离。
令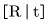
作为真实的位姿,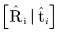
是位姿的第i-次指向性估计,
是对象模型中的采样点。网络的位姿损失可表示为:

对于对称对象,其在对象模型中的对应关系存在模糊性,采用变换点的最近邻作为对应关系(对称位姿损失):
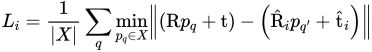
利用这些位姿损失,以无监督的方式训练了位姿估计的置信度。设N为像素估计的个数,为第i个估计置信度。最终训练损失L公式为:
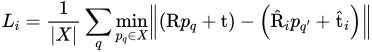
其中,λ 是正则化比例因子。
对称位姿损失的局部最小值
尽管对称位姿损失被设计为使用最近邻搜索来处理对称对象,但是我们发现与标准位姿损失相比,该损失倾向于停留在局部最小值上,而标准位姿损失在对象模型中使用了一对一的地面真相对应。图5b显示了示例性示例,其中对称位姿损失对非凸形对象的局部最小值有问题。
对于此问题,我们在训练过程中引入标准位姿损失(例如1个时期)的热身阶段,然后再切换到对称位姿损失。这种具有预热的训练策略允许首先通过忽略对称性来优化网络而无需局部极小问题的位姿估计,然后考虑对称性来进行优化,这为复杂形状的对称对象的位姿估计提供了更好的结果(图5c)。

一个空洞的局部极小值与损失热身。我们的损失预热©为复杂形状(如非凸)对称对象提供了更好的位姿估计,对于这类对称对象,对称位姿损失(b)很容易达到局部最小值。
3.3 基于碰撞的位姿优化
在上一节中,我们展示了如何结合基于图像的物体检测,RGB-D数据和附近物体形状的体素估计,以根据网络前向进行每个物体的位姿估计。这通常可以给出良好的初始位姿估计,但不一定是相互紧密接触的对象的一组相互一致的估计。因此,在本节中,我们介绍一个测试时位姿优化模块,该模块可以共同优化多个对象的位姿。
对于联合优化,我们引入了可区分的碰撞检查,包括对象CAD模型的占用体素化和占用网格之间的相交损失。由于两者都是可区分的,因此它允许我们使用梯度下降和GPU上的优化批处理操作来优化对象位姿。
可区分的占用体素
第3节中提到的特征向量的平均体素化。2.2使用基于点的特征向量,并且相对于特征向量是可区分的。相反,占用体素化需要相对于这些点是可区分的。这意味着,占用栅格中每个体素的值必须是点的函数,这些点已通过估计的对象位姿进行了转换。
让 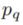
是一点 ,s 是体素大小,并且l是体素的原点(即体素网格的左下角)。我们可以使用以下方法将点转换为体素坐标:![]()
对于每个体素![]()
我们计算距离集合对点:![]()
我们根据与离最近点的距离成比例来确定占用值,从而计算出第k个体素的占用值![]()
为:
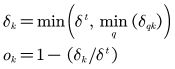
其中,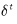
为距离阈值。
目标对象的占用体素化
这种可区分的占有体素化从对象模型和虚拟对象位姿得到占有网格。对于目标对象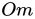
,将从其CAD模型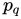
中采样的点按照假设位姿![]()
进行变换:![]()
,从中计算占用值。该点均匀地从CAD模型(包括内部部分)中采样,给出了目标对象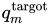
的假设占用网格。
类似地,我们对周围的对象执行这种体素化。与目标对象的体素化不同,周围的对象在目标的体素坐标中被体素化:![]()
,其中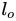
是目标对象的占用网格原点,![]()
是其体素大小。这就给出了目标对象
周围对象的假设占用网格。
对于碰撞检查的交叉损失
占用体素化给出了目标
(场景中的第m个物体)和周围物体的假设占用空间对象![]()
周围对象的占用网格构建在目标对象的体素坐标(中心,体素大小)中,并与元素方式的max聚合:
![]()
这给了一个单一的不可穿透的占用网格,其中目标对象的位姿是惩罚交叉。除了来自周围物体的位姿假设的不可穿透的占用网格,我们还使用了来自体素融合的占用信息:包括背景物体在内的占用空间![]()
,自由空间![]()
(图3),作为附加不可穿透区域: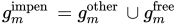
。碰撞罚损失![]()
计算为目标的假设占有空间与周围不可穿透网格的交点:
其中,![]()
是逐元素乘法。
虽然这个损失正确地惩罚了目标和周围物体之间的碰撞,但仅对此进行优化是不够的,因为它没有考虑到目标物体的可见表面约束
。损失中的另一项是目标的假设占用空间与该网格之间的交集
,为了鼓励物体位姿假设和体素重建之间的曲面相交:![]()
我们通过GPU上的批处理操作计算N个对象的碰撞和表面对齐损失,并将它们相加为总损失L:
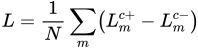
梯度下降使这种损失最小化,使我们能够联合优化多个对象的位姿假设。
3.4 CAD对齐
在完成位姿估计和细化后,一旦在不同视图中对所估计的位姿有足够的一致性,我们就会在地图中生成目标CAD模型。为了比较在不同相机坐标下估计的物体位姿,我们首先使用相机跟踪模块中跟踪的相机位姿将这些位姿转换为世界坐标(§3.1)。利用位姿损失来比较变换后的目标位姿,我们也用它来训练位姿估计网络(§3.2.3)。对于最近的N个位姿假设,我们计算每一对的位姿损失,得到N(N−1)位姿损失:
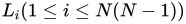
我们计算有多少构成损失低于阈值![]()
: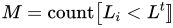
。当M达到一个阈值时,我们用那个一致的位姿初始化对象。
4.实验
在本节中,我们首先评估位姿估计(第4.2节)和优化(第4.3节)在6D位姿估计数据集上的表现。然后,我们演示了在机器人拾取和放置任务(第4.4节)上运行的系统。
4.1 实验设定
数据集
我们使用YCB视频数据集[29]中使用的21类YCB对象[4]来评估我们的位姿估计分量。YCB视频数据集在以前的工作中通常用于评估6D位姿估计,但是,由于所有场景都是桌面,因此该数据集在对象方向和遮挡方面受到限制。
为了使重遮挡和任意方向的评估成为可能,我们构建了自己的综合数据集:杂乱的YCB(图6)。我们使用物理模拟器[6]从随机位姿中放置具有可行配置的对象模型。这个数据集有1200个场景(火车:val = 5:1),每个场景有15帧。
我们使用与之前工作相同的度量[29,28],它计算对应点的平均距离:ADD, ADD- s。ADD使用ground truth, ADD使用最近的邻居作为对应,用ground truth和估计位姿转换模型。这些距离是为数据集中的每个目标位姿计算的,并用x轴上的误差阈值和y轴上的精度绘制的。度量是曲线下的面积(AUC),使用10cm作为x轴的最大阈值
4.2 位姿估计评价
基准模型
我们使用DenseFusion[28]作为基线模型。为了与我们提出的模型进行公平比较,我们重新实现了DenseFusion,并使用相同的设置(例如数据增加、归一化、丢失)进行训练。
表1显示了使用[29]的检测蒙版在YCB- Video数据集上的位姿估计结果,其中DenseFu-sian是GitHub的官方实现1,Dense-Fusion是我们的版本,其中包括预热损耗(第3.2节) .3)和输入点云的集中化(与我们模型中体素化步骤类似)。我们发现,添加两个组件将大大提高性能。在以下评估中,我们使用DenseFusion *作为基线模型。

结论
我们已经证明了对在杂乱场景中可能被其他物体严重遮挡和紧密接触的物体的一致和准确的位姿估计。我们的实时增量式位姿估计系统构建了一个描述场景中物体的完整几何图形的物体级地图,使机器人能够通过对遮挡物体的隐藏和定向放置的智能操作复杂的堆中的物体。我们相信,要使用已知的对象模型来为困难的、杂乱的场景创建连续的模型,还有很长的路要走。一个关键的未来方向是将物理推理引入到我们的优化框架中。