机器学习python实践——魏贞原
书籍pdf https://pan.baidu.com/s/1uERm5XdlcD6hibhfQQNeYQ?pwd=qzpz
书籍代码 https://pan.baidu.com/s/1MAHJLYrrs3lKmafB5Wsn0w?pwd=qzpz
文件链接
https://pan.baidu.com/s/1LZTW4-DO5Ht6dghd9DJMdw?pwd=qzpz
机器学习python实践
- 数据预处理
-
- 格式化数据
- 调整数据尺度大小
- 正态化数据分布
- 标准化数据
- 二值化数据
- 数据特征选定
-
- K方单变量特征选定
- RFE递归特征消除
- PCA主成分分析
- 特征重要性选定
- 选择模型
-
- 评估算法方法
- 评估算法指标
-
- 分类算法矩阵
- 回归算法矩阵
数据预处理
格式化数据
主要是用fit和transform函数对数据进行拟合和转换
sklearn里的封装好的各种算法使用前都要fit,fit相对于整个代码而言,为后续API服务。fit之后,然后调用各种API方法,transform只是其中一个API方法,所以当你调用transform之外的方法,也必须要先fit。
fit(): Method calculates the parameters μ and σ and saves them as internal objects.
解释:简单来说,就是求得训练集X的均值,方差,最大值,最小值,这些训练集X固有的属性。
transform(): Method using these calculated parameters apply the transformation to a particular dataset.
解释:在fit的基础上,进行标准化,降维,归一化等操作(看具体用的是哪个工具,如PCA,StandardScaler等)。
版权声明:本文为CSDN博主「九点澡堂子」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_38278334/article/details/82971752
调整数据尺度大小
通过MinMaxScaler类将不同计量单位的数据尺度调整到相同的尺度有利于对事物分类或者分组,也能够提高与距离相关的算法的准确度
正态化数据分布
使数据符合高斯分布,输出以0为均值,方差为1,提高算法准确度,简化计算量
标准化数据
将每一行的数据按比例缩放到距离为和为1的数据,也叫归一元处理,适合处理稀疏数据,对只用权重输入的神经网络和使用距离的K近邻算法的准确度有明显的提升作用
二值化数据
将数据转化为二值,大于阈值设为1,小于阈值设为0,在生成明确值或者增加属性的时候用
数据特征选定
由于以上处理方法代码类似,都是将数据缩放到0到1之间,只是公式不一样,这里统一分析
from pandas import read_csv
from numpy import set_printoptions
from sklearn.preprocessing import MinMaxScaler,StandardScaler,Normalizer,Binarizer
#导入数据
filename = "code\机器学习练习\pima-indians-diabetes.csv"
names = ["preg","plas","pres","skin","test","mass","pedi","age","class"]
data = read_csv(filename, names=names)
#将数据分为输入与输出数据
array = data.values
X = array[:, 0:8]
Y = array[:, 8]
transformer = MinMaxScaler(feature_range=(0,1))#归一化数据
transformer = StandardScaler().fit(X)#正态化数据
#transformer = Normalizer().fit(X)#标准化数据
#transformer = Binarizer(threshold=0.0).fit(X)#二值化数据
#数据转换,上面已经用了fit方法下面就用第二个代码
newX = transformer.fit_transform(X)
#newX = transformer.transform(X)
#设定数据的打印格式
set_printoptions(precision=3)
print(newX)
K方单变量特征选定
SelectKBest类利用K方检验选择对结果影响最大的特征,对每个特征进行评分并得到评分最高的K个数据特征
RFE递归特征消除
基于一个模型进行多次训练,每次训练消除若干权重系数的特征,例如rfe=RFE(model,3)
表示多模型训练多次之后,每次都会改变模型的权重系数,最终得到预测结果影响最大的三个特征
PCA主成分分析
PCA是为了让映射后的样本具有最大的发散性,无监督的降维
LDA是让映射后的样本有最好的分类性能,有监督的降维
若训练样本集两类的均值无明显的差异,但协方差差异很大,PCA降维的效果较优
https://zhuanlan.zhihu.com/p/32412043
https://view.inews.qq.com/a/20210426A02ODG00
特征重要性选定
集成学习像袋装决策树、随机森林等算法都会对特征进行选择来表示特征的重要性,这里引入的是集成学习中(ensemble)的极端随机树 Extra Trees
总结:以上都是基于不同模型对数据特征的选取,其代码基本类似,这里放在一起便于比较分析
from pandas import read_csv
from numpy import set_printoptions
from sklearn.feature_selection import SelectKBest,RFE
from sklearn.decomposition import PCA
from sklearn.feature_selection import chi2
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import ExtraTreesClassifier
#导入数据
filename = "code\机器学习练习\pima-indians-diabetes.csv"
names = ["preg","plas","pres","skin","test","mass","pedi","age","class"]
data = read_csv(filename, names=names)
#将数据分为输入与输出数据
array = data.values
X = array[:, 0:8]
Y = array[:, 8]
#选择特征一,K方检验
test = SelectKBest(score_func=chi2, k=4).fit(X, Y)
print(test.scores_)
features = test.transform(X)
#选择特征二,rfe
model = LogisticRegression()
rfe =RFE(model,3).fit(X,Y)
#选择特征三,pca
"""
https://zhuanlan.zhihu.com/p/32412043
https://view.inews.qq.com/a/20210426A02ODG00
PCA是为了让映射后的样本具有最大的发散性,无监督的降维
LDA是让映射后的样本有最好的分类性能,有监督的降维
若训练样本集两类的均值无明显的差异,但协方差差异很大,PCA降维的效果较优
"""
pca = PCA(n_components=3).fit(X)
#特征重要性,决策树
model = ExtraTreesClassifier()
fit = model.fit(X, Y)
#设定数据的打印格式
set_printoptions(precision=3)
print(features)
print("特征个数:%s" "选取的特征:%s" "特征排名:%s" %(rfe.n_features_,rfe.support_,rfe.ranking_))
print("解释方差:%s" % pca.explained_variance_ratio_)
print(pca.components_)
print(fit.feature_importances_)
选择模型
评估算法方法
方法一:将数据集分离训练集与评估数据集
from pandas import read_csv
from numpy import set_printoptions
from sklearn.feature_selection import SelectKBest,RFE
from sklearn.decomposition import PCA
from sklearn.feature_selection import chi2
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import ExtraTreesClassifier
#导入数据
filename = "code\机器学习练习\pima-indians-diabetes.csv"
names = ["preg","plas","pres","skin","test","mass","pedi","age","class"]
data = read_csv(filename, names=names)
#将数据分为输入与输出数据
array = data.values
X = array[:, 0:8]
Y = array[:, 8]
X_train,X_test,Y_train,Y_test = train_test_split(X,Y,test_size=0.2,random_state=7)
model = LogisticRegression()
model.fit(X_train, Y_train)
result = model.score(X_test, Y_test)
print("算法评估结果:%.3f%%" % (result*100))
方法二:K折交叉验证、留一法、重复随机分离评估数据集与训练数据集
K折交叉验证:
将原始数据集分为K组,每一组分别做一次验证集,剩余K-1组子集作为训练集,K一般取2,3,5,10.
留一法:
将原始数据N个样本,每次选择一个作为验证集,其余N-1个样本作为训练集,得到N个模型,是K折交叉验证的特殊化,对应模型评估结果可靠,但是计算量高。
重复随机分离评估数据集与训练数据集:
类似与方法一只是重复了K次
由于这三个方法类似放一起比较
from pandas import read_csv
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import KFold, cross_val_score,train_test_split,ShuffleSplit,LeaveOneOut
#导入数据
filename = "code\机器学习练习\pima-indians-diabetes.csv"
names = ["preg","plas","pres","skin","test","mass","pedi","age","class"]
data = read_csv(filename, names=names)
#将数据分为输入与输出数据
array = data.values
X = array[:, 0:8]
Y = array[:, 8]
model = LogisticRegression()
kfold = KFold(n_splits=10,random_state=7,shuffle=True)#方法一:k折交叉验证
loocv = LeaveOneOut()#方法二:留一法
kfold_ = ShuffleSplit(n_splits=10,test_size=0.33,random_state=7)#方法三:重复随机分离训练集与评估集
cv_results_1 = cross_val_score(model,X,Y,cv=kfold)
cv_results_2 = cross_val_score(model,X,Y,cv=loocv)
cv_results_3 = cross_val_score(model,X,Y,cv=kfold_)
print("算法评估结果: %.3f%%(%.3f%%)" %(cv_results_1.mean(),cv_results_1.std()))
print("算法评估结果: %.3f%%(%.3f%%)" %(cv_results_2.mean(),cv_results_2.std()))
print("算法评估结果: %.3f%%(%.3f%%)" %(cv_results_3.mean(),cv_results_3.std()))
评估算法指标
分类算法矩阵
1.分类准确度
2.对数损失函数
3.AUC图
4.混淆矩阵
5.分类报告
分类准确度即分类正确样本除以所有样本数得出的结果
对数损失函数指假设样本服从某分布,对其求分布的似然函数,取对数,求极值,对于逻辑回归分类算法将最大化似然函数看作最小化负的似然函数,从损失函数角度看,为对数损失函数,越小模型越好。
AUC是一个图,横坐标为FPR,纵坐标为TPR(召回率)
FPR=FP / (FP + TN)
TPR=TP / (TP+FN)
精确率是针对我们预测结果而言的,它表示的是预测为正的样本中有多少是真正的正样本。那么预测为正就有两种可能了,一种就是把正类预测为正类(TP),另一种就是把负类预测为正类(FP),也就是而召回率是针对我们原来的样本而言的,它表示的是样本中的正例有多少被预测正确了。那也有两种可能,一种是把原来的正类预测成正类(TP),另一种就是把原来的正类预测为负类(FN)。
作者:Charles Xiao
链接:https://www.zhihu.com/question/19645541/answer/91694636
来源:知乎
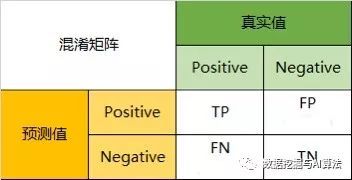
混淆矩阵比较分类值与实际预测值,把分类结果显示在一个混淆矩阵里,适用于监督学习,如上图所示也可以利用代码进行可视化,这里将混淆矩阵与分类报告放一起比较
from pandas import read_csv
import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from skLearn。metrics import classification_report,confusion_matrix
#导入数据
filename = "code\机器学习练习\pima-indians-diabetes.csv"
names = ["preg","plas","pres","skin","test","mass","pedi","age","class"]
data = read_csv(filename, names=names)
#将数据分为输入与输出数据
array = data.values
X = array[:, 0:8]
Y = array[:, 8]
X_train,X_test,Y_train,Y_test = train_test_split(X,Y,test_size=0.2,random_state=7)
model = LogisticRegression()
model.fit(X_train, Y_train)
predicted = model.predict(X_test)
#以上部分混淆矩阵与分类报告一样
#混淆矩阵,利用dataframe框架进行可视化
matrix = confusion_matrix(Y_test,predicted)
classes = ["0","1"]
dataframe = pd.DataFrame(data=matrix,index=classes,columns=classes)
print(dataframe)
#分类报告
report=classification_report(Y_test,predicted))
print(report)
分类报告包括2,3,4和样本数目,它更像是一个指标的描述
1.准确率(Accuracy) = (TP + TN) / (TP + FP + FN + TN)
(在整个观察结果中,预测正确的占比)
2.精确率(Precision) = TP / (TP + FP)(在所有预测为正例的结果中,预测正确的占比)
3.召回率(Recall) = TP / (TP + FN)
(在所有实际值为正例的结果中,预测正确的占比)
4.F1_score = 2PR/(P + R)
https://blog.csdn.net/weixin_43734080/article/details/118198379
(P代表精确率,R代表召回率)
分类准确度,对数损失函数,AUC图三个指标的代码类似,这里放一起比较主要是scoring的设置不同包括accuracy、neg_log_loss、roc_auc三种模式
默认None模式即accuracy模式
def cross_val_score(estimator, X, y=None, *, groups=None, scoring=None,
cv=None, n_jobs=None, verbose=0, fit_params=None,
pre_dispatch='2*n_jobs', error_score=np.nan):
这里默认选取模型方法用K折交叉验证法,即cv=kfold
from pandas import read_csv
from sklearn.linear_model import LogisticRegression,cross_val_score
from sklearn.model_selection import KFold
from sklearn.linear_model import LogisticRegression,LinearRegression
#导入数据
filename = "code\机器学习练习\pima-indians-diabetes.csv"
names = ["preg","plas","pres","skin","test","mass","pedi","age","class"]
data = read_csv(filename, names=names)
#将数据分为输入与输出数据
array = data.values
X = array[:, 0:8]
Y = array[:, 8]
model = LogisticRegression()
kfold = KFold(n_splits=10,random_state=7,shuffle=True)#方法一:k折交叉验证
scoring = ["accuracy","neg_log_loss","roc_auc"]
cv_results = cross_val_score(model,X,Y,cv=kfold,scoring=scoring[0])
print("算法评估结果: %.3f%%(%.3f%%)" %(cv_results.mean(),cv_results.std()))
回归算法矩阵
1.平均绝对误差(MAE)
2.均方误差(MSE)
3.决定系数( R 2 R^{2} R2)
平均绝对误差反映预测值误差的实际情况
均方误差用来衡量平方误差,可以评价数据的变化程度,均方误差越小,说明预测模型描述实验数据的准确度更高,可以理解平均绝对误差用来衡量微观,均方误差衡量宏观
决定系数反映因变量的全部变异能通过回归关系被自变量解释的比例,比较绕口,其实就是自变量与因变量拟合程度的好坏
代码与分类算法一样,只是scoring设置不同,分别为"neg_mean_absolute_error",“neg_mean_squared_error”,“r2”