关于Dialog和Clarifying question的一些调研
文章目录
- Paper1: Understanding User Satisfaction with Task-oriented Dialogue Systems
-
- Motivation:
- Classification:
- Contributions:
- Dataset
- Knowledge:
- Paper2: Evaluating Mixed-initiative Conversational Search Systems via User Simulation
-
- Motivation
- Classification:
- Contribution
- Methods
-
- Semantically-controlled text generation
- GPT2-based simulated user
- Datasets
-
- Qulac and ClariQ
- Multi-turn conversational data
- Future Work
- Knowledge
- Paper3: Users Meet Clarifying Questions: Toward a Better Understanding of User Interactions for Search Clarification
-
- Contributions
- Paper4: Reinforced History Backtracking for Conversational Question Answering
-
- Motivation
- Contributions
- Methods
-
- Environment
- Reward
- Algorithm
- Dataset
- Knowledge
- Paper5: Generating Clarifying Questions with Web Search Results
Paper1: Understanding User Satisfaction with Task-oriented Dialogue Systems
Understanding User Satisfaction with Task-oriented Dialogue Systems:
Motivation:
The influence of user experience on the user satisfaction ratings of TDS in addition to utility.
Classification:
Use and propose some metrics to evaluate task-oriented dialogue system(TDS)
Contributions:
- add an extra annotation layer for the ReDial dataset
- analyse the annotated dataset to identify dialogue aspects that influence the overall impression.
- Our work rates user satisfaction at both turn and dialogue level on six fine-grained user satisfaction aspects, unlike previous research rating both levels on overall impression
- propose additional dialogue aspects with significant contributions to the overall impression of a TDS
Dataset
ReDial(recommendation dialogue dataset): a large dialogue-based human-human movie recommendation corpus
- operations on datasets: create an additional annotation layer for the ReDial dataset. We set up an annotation experiment on Amazon Mechanical Turk (AMT) using so-called master workers. The AMT master workers annotate a total of 40 conversations on six dialogue aspects(relevance, interestingness, understanding, task completion, efficiency, and interest arousal)
Knowledge:
Dialogue systems(DSs) has two categories:
- task-oriented dialogue systems(TSDs), evaluate on utility
- open-domain chat-bots, evaluate on user experience
Paper2: Evaluating Mixed-initiative Conversational Search Systems via User Simulation
Evaluating Mixed-initiative Conversational Search Systems via User Simulation:
Motivation
Propose a conversational User Simulator, called USi, for automatic evaluation of such conversational search system.
Classification:
Develop the User Simulator to answer clarifying questions prompted by a conversational system.
Contribution
- propose a user simulator, USi, for conversational search systemevaluation, capable of answering clarifying questions prompted by the search system
- perform extensive set of experiments to evaluate the feasibility of substituting real users with the user simulator
- release a dataset of multi-turn interactions acquired through crowdsourcing
Methods
Semantically-controlled text generation
We define the task of generating answers to clarifying questions as a sequence generation task. Current SOTA language models formulate the task as next-word prediction task:

Answer generation needs to be conditioned on the underlying information need:

- a i a_i ai is the current token of the answer
- a < i a_{
- i n , q , c q in,q,cq in,q,cq correspond to the information need, initial query, current clarifying question
GPT2-based simulated user
- base USi in the GPT-2 model with language modelling and classification losses(DoubleHead GPT-2)
- learn to generate the appropriate seq through the language modelling loss
- distinguish a correct answer to the distractor one
Singel-turn responses:
-
GPT-2 input:

- accept two seq as input: one with the original target answer in the end, the other with the distractor answer
Conversation history-aware model:
- history-aware GPT-2 input:
![]()
Inference:
- omit the answer a a a from the input seq.
- In order to generate answers, we use a combination of SOTA sampling techniques to generate a textual sequence from the trained model
Datasets
Qulac and ClariQ
both built for single-turn offline evaluation.
Qulac: (topic, facet, clarifying_question, answer). ClariQ is an extension of Qulac
facet from Qulac and ClariQ represents the underlying information need, as it describes in detail what the intent behind the issued query is. Moreover, question represents the current asked question, while answer is our language modelling target.
Multi-turn conversational data
we construct multi-turn data that resembles a more realistic interaction between a user and the system. Our user simulator USi is then further fine-tuned on this data.
Future Work
- a pair-wise comparison of multi-turn conversations.
- aim to observe user simulator behaviour in unexpected, edge case scenarios
- for example, people will repeat the answer is the clarifying question is repeated. We want USi to do so.
Knowledge
Datasets: Qulac, ClariQ
Multi-turn passage retrieval: The system needs to understand the conversational context and retrieve appropriate passages from the collection.
Document-retrieval task: the initial query is expanded with the text of the clarifying question and the user’s answer and the fed into a retrieval model.
Paper3: Users Meet Clarifying Questions: Toward a Better Understanding of User Interactions for Search Clarification
Users Meet Clarifying Questions: Toward a Better Understanding of User Interactions for Search Clarification
Contributions
Paper4: Reinforced History Backtracking for Conversational Question Answering
Reinforced History Backtracking for Conversational Question Answering | Proceedings of the AAAI Conference on Artificial Intelligence
Motivation
Avoid the negative impact of unimportant history turns from the source by not considering them.
Contributions
- Propose a novel solution for modeling the conversation history in the ConvQA setting.we incorporate a reinforced backtracker in the traditional MRC model to filter the irrelevant history turns instead of evaluating them as a whole.
- model the conversation history selection problem as a sequential decision-making process, which can be solved by reinforcement learning(RL)
- Conduct extensive experiments on a large conversational QA dataset
QuAC
Methods
Model the ConvQA task as two subtasks:
- a ConvQA task using a neural MRC model
- a Conv history selection task with a reinforced backtracker
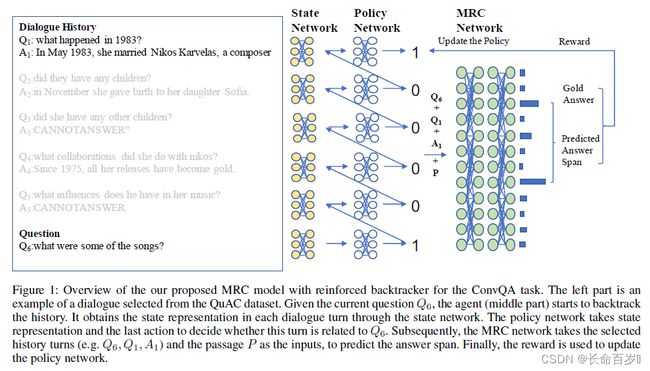
Environment
MRC model: BERT
-
input: [CLS] Q k Q_k Qk [SEP] H ′ H' H′ [SEP] P P P [SEP]
- Q k Q_k Qk is the current k-th question
- P P P is the passage
- H ′ H' H′ is the set of the selected history turns
-
output: H r c ∈ R L x D m H_{rc} \in R^{L x D_m} Hrc∈RLxDm .
- L L L is the passage length, D m D_m Dm is the vector dim.
-
predict the start and end position

Reward
Our goal: maximize the accuracy of the MRC model’s prediction, we can use F1 score:

- P P P is the overlap percentage of the gold answer that counts in the predicted answer
- R R R is the overlap percentage that counts in the gold answer
Reward: define the delayed reward as the difference of F1 scores after the model updates
- R d e l a y e d = △ F 1 R^{delayed} = \bigtriangleup F1 Rdelayed=△F1
Such sparse reward poses challenges for the RL policy. we shall encourage adding a sentence that is close to the
history segment embeddings, as it may provide coherent information to help history modeling
![]()
- w i w_i wi is the history segment embeddingen
Final reward:
![]()
- δ \delta δ is the discount factor and T is the final step index
Algorithm

Dataset
QuAC: a machine reading comprehension task with multi-turn interactions. where the current question oftrn refers to the dialogue history.
- 100k questions, 10k dialogue, maximum round is 12.
Canard: contains manually-generated questions(re-written questions which can be viewed as a good env without the need for history modeling) based on the context history.
- this dataset can help to examine whether the competing methods have the ability to choose proper context history to generate high quality rewritten questions close to the manually-generated questions.
Knowledge
-
MRC(Machine Reading Comprehension): MRC task is typically conducted in a single-turn QA manner. The goal is to answer the question by predicting an answer span in the given passage.
-
two lines of work in RL:
- value-based: take actions based on estimations of expected long-term return
- policy-based: optimize for a strategy that can map states to actions that promise the highest reward