二手车保值率分析预测
文章目录
- 摘要
- 一、数据说明
- 二、建模分析
-
- 1.描述性分析
- 2.机器学习模型
- 总结
摘要
根据中国汽车消费者的消费观念,汽车的置换时间一般在4至10年,而每年新车的增量迅猛,因此将导致二手车的价格偏低,对于准备购车的年轻人和准备置换的消费者来说,一台年份较近、外观大方、性能良好的二手车型将是一个不错的选择。由于车辆的使用,必然会导致其有一定的贬值或降价,这跟车辆的保养情况、品牌、行驶里程等因素有着直接的关系。因而,本案例将分析二手车的保值率与哪些因素有关。关键词:随机森林、SVM、CV
一、数据说明
本数据包含二手车交易数据(共2034条数据,截至于2017年1月1日零时),本案例将引用其相关数据并仿照案例视频分析流程,通过R语言编程进行数据分析。
原始数据包括车辆品牌、品牌、品牌属地、款式、车型、排量、手动/自动、版型、上牌时间、行驶里程(万公里)、现价(万元)、购车原价(万元)、保值率、里程分组、排量分组等15个变量,其中响应变量为保值率,其余14个为自变量。
二、建模分析
1.描述性分析
保值率
代码如下(示例):
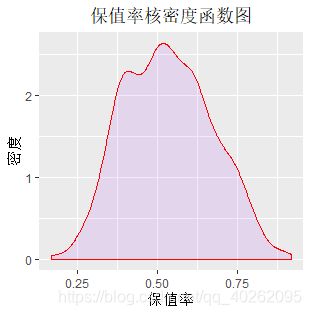
#因变量:保值率(密度核函数图)
ggplot(data,aes(x=保值率))+geom_density(fill="purple",colour="red",alpha=0.1)+
labs(title="保值率核密度函数图",x="保值率", y="密度") +
theme(plot.title = element_text(hjust = 0.5))
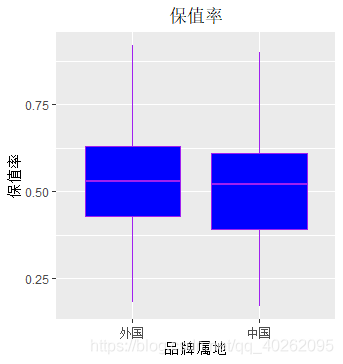
#自变量:车辆品牌(箱线图)
ggplot(data, aes(x=车辆品牌, y=保值率)) + geom_boxplot(fill="blue",colour="purple")+
labs(title="保值率",x="车辆品牌", y="保值率") +
theme(plot.title = element_text(hjust = 0.5))
#自变量:品牌属地
par(mfrow=c(1,2))
ggplot(data, aes(x=品牌属地, y=保值率)) + geom_boxplot(fill="blue",colour="purple")+
labs(title="保值率",x="品牌属地", y="保值率") +
theme(plot.title = element_text(hjust = 0.5))
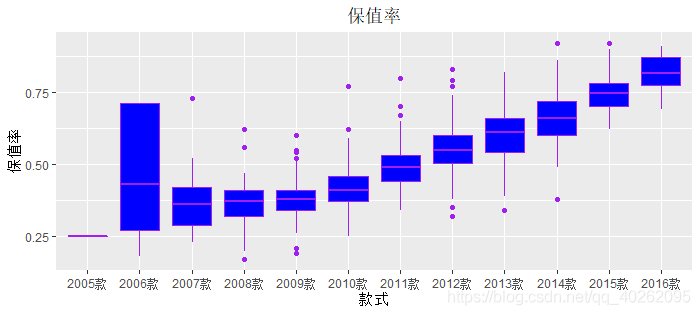
#自变量:款式
ggplot(data, aes(x=款式, y=保值率)) + geom_boxplot(fill="blue",colour="purple")+
labs(title="保值率",x="款式", y="保值率") +
theme(plot.title = element_text(hjust = 0.5))
#自变量:排量(规律不明显)
#ggplot(data, aes(x=排量, y=保值率)) + geom_boxplot()+
# stat_summary(fun.y = "mean",geom="point",shape=10,size=3,fill="white")+
# labs(title="不同车的保值率",x="里程", y="保值率") +
# theme(plot.title = element_text(hjust = 0.5))
ggplot(data, aes(x=排量分组, y=保值率)) + geom_boxplot(fill="blue",colour="purple")+
labs(title="保值率",x="排量分组", y="保值率") +
theme(plot.title = element_text(hjust = 0.5))
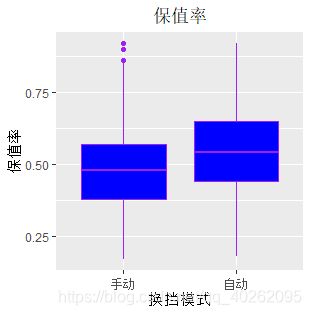
#自变量:手动/自动
ggplot(data, aes(x=手动.自动, y=保值率)) + geom_boxplot(fill="blue",colour="purple")+
labs(title="保值率",x="换挡模式", y="保值率") +
theme(plot.title = element_text(hjust = 0.5))
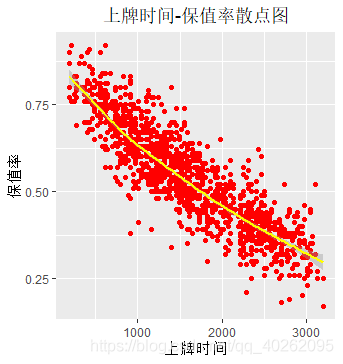
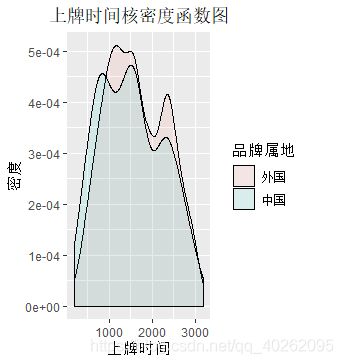
#自变量:上牌时间
ggplot(data, aes(x=上牌时间, fill=品牌属地))+geom_density(alpha=0.1)+
labs(title="上牌时间核密度函数图",x="上牌时间", y="密度") +
theme(plot.title = element_text(hjust = 0.5)) #上牌时间核密度函数
ggplot(data, aes(x=上牌时间,y=保值率))+geom_point(colour="red")+geom_smooth(colour="yellow")+
labs(title="上牌时间-保值率散点图",x="上牌时间", y="保值率") +
theme(plot.title = element_text(hjust = 0.5)) #上牌时间-保值率散点图
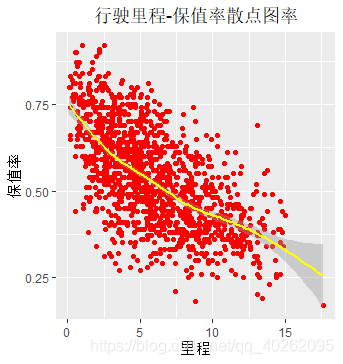
#自变量:行驶里程
ggplot(data, aes(x=行驶里程.万公里., y=保值率)) + geom_point(colour="red")+geom_smooth(colour="yellow")+
labs(title="行驶里程-保值率散点图率",x="里程", y="保值率") +
theme(plot.title = element_text(hjust = 0.5)) #行驶里程-保值率散点图
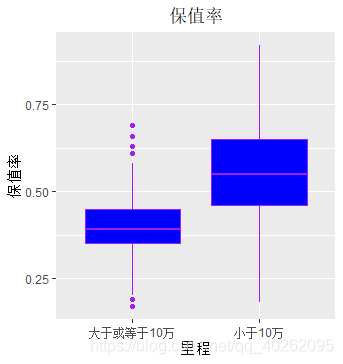
ggplot(data, aes(x=里程分组, y=保值率)) + geom_boxplot(fill="blue",colour="purple")+
labs(title="保值率",x="里程", y="保值率") +
theme(plot.title = element_text(hjust = 0.5))
2.机器学习模型
代码如下(示例):
MSE_all=matrix(NA,nrow=4,ncol=2,dimnames=list(c("RandomForest","Nnet","SVM","lm"),c("训练集的NMSE","测试集的NMSE")))
#10折交叉验证(参考:吴喜之.复杂数据统计方法-基于R语言应用)
RS=function(n, Z, seed=100){
z=rep(1:Z,ceiling(n/Z))[1:n] #ceiling: 返回大于或等于所给数字表达式的最小整数
set.seed(seed)
z=sample(z,n) #为1:10的随机排列
mm=list()
for(i in 1:Z) mm[[i]]=(1:n)[z==i] #mm[[i]]为第i个下标集
return(mm)}
n=nrow(data);Z=10
mm=RS(n,Z) #将原始数据分为10份
#RandomForest回归
library(randomForest)
set.seed(101)
NMSE.rf=rep(0,10)
NMSE0.rf=NMSE.rf
for(i in 1:Z){
m=mm[[i]]
c=randomForest(hedgeratio~.,data[-m,],importance=TRUE,proximity=TRUE)
y0=predict(c,data[-m,]) #对训练集预测
y1=predict(c,data[m,]) #对测试集预测
#训练集的NMSE
NMSE0.rf[i]=mean((data$hedgeratio[-m]-y0)^2)/mean((data$hedgeratio[-m]-mean(data$hedgeratio[-m]))^2)
#测试集的NMSE
NMSE.rf[i]=mean((data$hedgeratio[m]-y1)^2)/mean((data$hedgeratio[m]-mean(data$hedgeratio[m]))^2)
}
MNMSE0.rf=mean(NMSE0.rf)
MNMSE.rf=mean(NMSE.rf)
MSE_all[1,1]=MNMSE0.rf
MSE_all[1,2]=MNMSE.rf
#神经网络回归
library(nnet)
set.seed(444)
NMSE.nn=rep(0,10)
NMSE0.nn=NMSE.nn
for(i in 1:Z){
m=mm[[i]]
d=nnet(hedgeratio~.,data=data[-m,],size=5,range=0.1,decay=5e-4,maxit=200)
y0=predict(d,data[-m,-7]) #对训练集预测
y1=predict(d,data[m,-7]) #对测试集预测
#训练集的NMSE
NMSE0.nn[i]=mean((data$hedgeratio[-m]-y0)^2)/mean((data$hedgeratio[-m]-mean(data$hedgeratio[-m]))^2)
#测试集的NMSE
NMSE.nn[i]=mean((data$hedgeratio[m]-y1)^2)/mean((data$hedgeratio[m]-mean(data$hedgeratio[m]))^2)
}
MNMSE0.nn=mean(NMSE0.nn)
MNMSE.nn=mean(NMSE.nn)
MSE_all[2,1]=MNMSE0.nn
MSE_all[2,2]=MNMSE.nn
#支持向量机回归
library(rminer)
set.seed(444)
NMSE.svm=rep(0,10)
NMSE0.svm=NMSE.svm
for(i in 1:Z){
m=mm[[i]]
e=fit(hedgeratio~.,data[-m,],model="svm")
y0=predict(e,data[-m,]) #对训练集预测
y1=predict(e,data[m,]) #对测试集预测
#训练集的NMSE
NMSE0.svm[i]=mean((data$hedgeratio[-m]-y0)^2)/mean((data$hedgeratio[-m]-mean(data$hedgeratio[-m]))^2)
#测试集的NMSE
NMSE.svm[i]=mean((data$hedgeratio[m]-y1)^2)/mean((data$hedgeratio[m]-mean(data$hedgeratio[m]))^2)
}
MNMSE0.svm=mean(NMSE0.svm)
MNMSE.svm=mean(NMSE.svm)
MSE_all[3,1]=MNMSE0.svm
MSE_all[3,2]=MNMSE.svm
#线性回归
NMSE.lm=rep(0,10)
NMSE0.lm=NMSE.lm
for(i in 1:Z){
m=mm[[i]]
f=lm(hedgeratio~.,data[-m,])
y0=predict(f,data[-m,]) #对训练集预测
y1=predict(f,data[m,]) #对测试集预测
#训练集的NMSE
NMSE0.lm[i]=mean((data$hedgeratio[-m]-y0)^2)/mean((data$hedgeratio[-m]-mean(data$hedgeratio[-m]))^2)
#测试集的NMSE
NMSE.lm[i]=mean((data$hedgeratio[m]-y1)^2)/mean((data$hedgeratio[m]-mean(data$hedgeratio[m]))^2)
}
MNMSE0.lm=mean(NMSE0.lm)
MNMSE.lm=mean(NMSE.lm)
MSE_all[4,1]=MNMSE0.lm
MSE_all[4,2]=MNMSE.lm
#预测:
value=matrix(NA,nrow=4,ncol=1,dimnames=list(c("RandomForest","Nnet","SVM","lm"),c("predict")))
x_new=data[1064,]#2014款的宝马3系中级轿车,自动档,上牌时间为823天,行驶里程13.1万公里
set.seed(1)
value[1,1]=predict(c,x_new)
value[2,1]=predict(d,x_new)
value[3,1]=predict(e,x_new)
value[4,1]=predict(lm4,x_new)
value
训练集的NMSE 测试集的NMSE
RandomForest 0.06092967 0.1427269
Nnet 0.25652926 0.2757021
SVM 0.14456982 0.1796370
Lm 0.18781496 0.1960912
| 训练集NMSE | 测试集NMSE | |
|---|---|---|
| RandomForest | 0.06092967 | 0.1427269 |
| Nnet | 0.25652926 | 0.2757021 |
| SVM | 0.14456982 | 0.1796370 |
| Lm | 0.18781496 | 0.1960912 |
显然就这个数据而言,随机森林方法无论是训练集的均方误差还是测试集的均方误差都是最小的,表现最佳,其次是SVM、Nnet、Lm。
## 预测 假如现在有一台2014款的宝马3系中级轿车,自动档,上牌时间为823天,行驶里程13.1万公里,则通过以上不同方法的预测保值率为:
| Method | Predict |
|---|---|
| RandomForest | 0.6618649 |
| Nnet | 0.6530373 |
| SVM | 0.6628383 |
| Lm | 0.6124372 |
总结
本案例通过建立多元线性回归模型,进行了模型的诊断和检验,从中找出了影响二手车保值率的因素有汽车品牌、品牌属地、汽车款式、换挡模式、上牌时间、行使里程、排量等7个因素,汽车品牌越知名、上牌时间越短、行驶里程越短等的二手车会有一个较高的保值率。
通过和无模型假设的机器学习的随机森林、神经网络、支持向量机回归方法做对比,就本案例而言,随机森林的方法均方误差最小,表现最佳,用该方法进行预测的效果会最好,最终对一辆宝马3系的轿车进行预测,估计保值率在0.6618649。
探讨学习请联系wx:acircleAcircle