3.Spark 学习成果转化—机器学习—使用Spark MLlib的逻辑回归来预测音乐标签 (多元分类问题)
本文目录如下:
- 第3例 使用Spark ML的逻辑回归来预测音乐标签
-
- 3.1 数据准备
-
- 3.1.1 数据集文件准备
- 3.1.2 数据集字段解释
- 3.2 使用 Spark MLlib 实现代码
-
- 3.2.1 引入项目依赖
- 3.2.2 将 `MNIST` 数据集以 `libsvm` 格式进行加载并解析
- 3.2.3 准备训练和测试集
- 3.2.4 运行训练算法来创建模型
- 3.2.5 在测试上计算原始分数
- 3.2.6 为模型评估初始化一个多类度量
- 3.2.7 构造混淆矩阵
- 3.2.8 总体统计信息
- 3.2.9 项目完整代码
- 第4例 使用Spark MLlib的线性回归来预测音乐标签
-
- 4.1 数据准备
- 4.2 使用 Spark ML 实现代码
-
- 4.2.1 引入项目依赖
- 4.2.2 将 `MNIST` 数据集以 `libsvm` 格式进行加载并解析
- 4.2.3 计算特征向量, 简化降维操作
- 4.2.4 准备 训练集 和 测试集
- 3.2.5 训练线性回归模型
- 4.2.6 评估这两个模型
- 4.2.7 观察这两个模型的模型系数
- 4.2.8 项目完整代码
第3例 使用Spark ML的逻辑回归来预测音乐标签
- 这是一个 多元分类 问题, 也就是预测出来的结果有多种。
- 有关
Spark ML的介绍与知识点请参考: Spark ML学习笔记—Spark MLlib 与 Spark ML。
3.1 数据准备
3.1.1 数据集文件准备
-
(1) 该项目并为使用数据库当做数据源,而是直接将数据文件放在项目目录中, 这是一个结构化的简化数据集。
-
(2) 本项目使用的数据集是著名的
MNIST数据集,该数据集包含780个特征。数据集地址: 百万歌曲数据集。

3.1.2 数据集字段解释
- 由于字段太多,这里不做具体字段解释。
3.2 使用 Spark MLlib 实现代码
3.2.1 引入项目依赖
使用的依赖包多数来自于 Spark ML, 而非 Spark MLlib。
import org.apache.spark.SparkConf
import org.apache.spark.mllib.classification.LogisticRegressionWithLBFGS
import org.apache.spark.mllib.evaluation.MulticlassMetrics
import org.apache.spark.mllib.util.MLUtils
import org.apache.spark.sql.SparkSession
3.2.2 将 MNIST 数据集以 libsvm 格式进行加载并解析
val data = MLUtils.loadLibSVMFile(spark.sparkContext, "datas3/mnist.bz2")
3.2.3 准备训练和测试集
val splits = data.randomSplit(Array(0.75, 0.25), 12345L)
val training = splits(0).cache()
val test = splits(1)
3.2.4 运行训练算法来创建模型
val model = new LogisticRegressionWithLBFGS()
.setNumClasses(10)
.setIntercept(true)
.setValidateData(true)
.run(training)
- 到这一步, 预测模型便已经创建成功, 后续只需要根据这个模型进行预测即可。
3.2.5 在测试上计算原始分数
val scoreAndLabels = test.map{
point => {
val score = model.predict(point.features)
(score, point.label)
}
}
- 到这一步,预测结果也几经的出来了,只需要循环遍历输出一下即可,预测结果如下图所示:
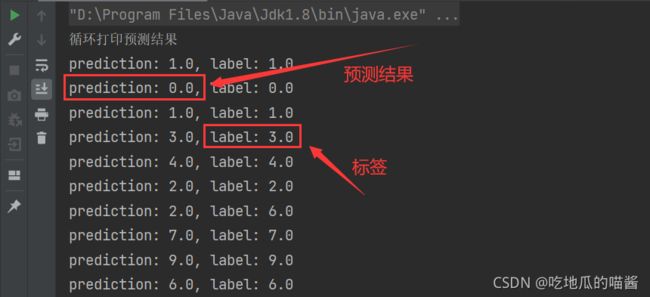
- 从上图中可以看出: 预测出来的
prediction与label完全一致, 说明预测的准确率是很高的。 - 至此, 预测工作已经进行结束了, 剩下还有一些 观察训练过程 和 模型评估 的操作。
3.2.6 为模型评估初始化一个多类度量
// 为模型评估初始化一个多类度量 (metrics包含模型的各种度量信息)
val metrics = new MulticlassMetrics(scoreAndLabels)
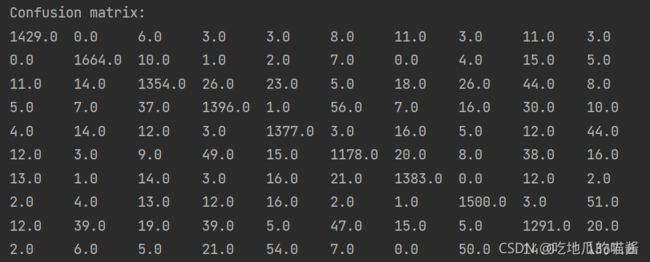
3.2.7 构造混淆矩阵
println("Confusion matrix: ")
println(metrics.confusionMatrix)
混淆矩阵如下图所示:
3.2.8 总体统计信息
val accuracy = metrics.accuracy
println("Summary Statistics")
println(s"Accuracy = $accuracy")
// Precision by label (准确率)
val labels = metrics.labels
labels.foreach(
l => println(s"Precision($l) = " + metrics.precision(l))
)
// Recall by label (召回率)
labels.foreach(
l => println(s"Recall($l) = " + metrics.recall(l))
)
// False positive rate by label (假正类比例)
labels.foreach(
l => println(s"FPR($l) = " + metrics.falsePositiveRate(l))
)
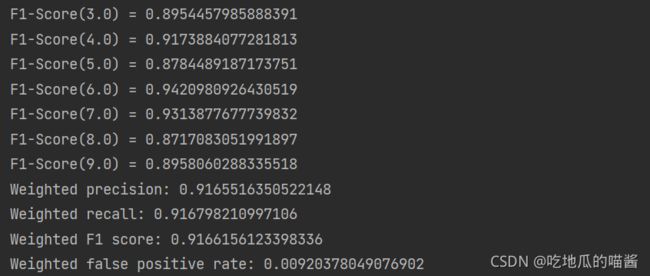
// F-measure by label (F1分数)
labels.foreach(
l => println(s"F1-Score($l) = " + metrics.fMeasure(l))
)
// 计算总体的统计信息
println(s"Weighted precision: ${metrics.weightedPrecision}")
println(s"Weighted recall: ${metrics.weightedRecall}")
println(s"Weighted F1 score: ${metrics.weightedFMeasure}")
println(s"Weighted false positive rate: ${metrics.weightedFalsePositiveRate}")
上述代码的输出信息如下图所示:
3.2.9 项目完整代码
import org.apache.spark.SparkConf
import org.apache.spark.mllib.classification.LogisticRegressionWithLBFGS
import org.apache.spark.mllib.evaluation.MulticlassMetrics
import org.apache.spark.mllib.util.MLUtils
import org.apache.spark.sql.SparkSession
/**
* description: 使用 逻辑回归 的多元分类: 原版
*/
object SparkML_0105_test5 {
def main(args: Array[String]): Unit = {
// TODO 创建 Spark SQL 的运行环境
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("sparkML")
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
// step 1: 将 MNIST 数据集以 libsvm 格式进行加载并解析
val data = MLUtils.loadLibSVMFile(spark.sparkContext, "datas3/mnist.bz2")
// step 2: 准备训练和测试集 (将数据拆分为训练集(75%) 和 测试集(25%))
val splits = data.randomSplit(Array(0.75, 0.25), 12345L)
val training = splits(0).cache()
val test = splits(1)
// step 3: 运行训练算法来创建模型
val model = new LogisticRegressionWithLBFGS()
.setNumClasses(10)
.setIntercept(true)
.setValidateData(true)
.run(training)
// step 4: 清理默认的阈值
model.clearThreshold()
// step 5: 在测试上计算原始分数
val scoreAndLabels = test.map{
point => {
val score = model.predict(point.features)
(score, point.label)
}
}
// step 6: 为模型评估初始化一个多类度量 (metrics包含模型的各种度量信息)
val metrics = new MulticlassMetrics(scoreAndLabels)
// step 7: 构造混淆矩阵
println("Confusion matrix: ")
println(metrics.confusionMatrix)
// step 8: 总体统计信息
val accuracy = metrics.accuracy
println("Summary Statistics")
println(s"Accuracy = $accuracy")
// Precision by label (准确率)
val labels = metrics.labels
labels.foreach(
l => println(s"Precision($l) = " + metrics.precision(l))
)
// Recall by label (召回率)
labels.foreach(
l => println(s"Recall($l) = " + metrics.recall(l))
)
// False positive rate by label (假正类比例)
labels.foreach(
l => println(s"FPR($l) = " + metrics.falsePositiveRate(l))
)
// F-measure by label (F1分数)
labels.foreach(
l => println(s"F1-Score($l) = " + metrics.fMeasure(l))
)
// 计算总体的统计信息
println(s"Weighted precision: ${metrics.weightedPrecision}")
println(s"Weighted recall: ${metrics.weightedRecall}")
println(s"Weighted F1 score: ${metrics.weightedFMeasure}")
println(s"Weighted false positive rate: ${metrics.weightedFalsePositiveRate}")
spark.close()
}
}
第4例 使用Spark MLlib的线性回归来预测音乐标签
4.1 数据准备
- 略
4.2 使用 Spark ML 实现代码
4.2.1 引入项目依赖
使用的依赖包多数来自于 Spark ML, 而非 Spark MLlib。
import org.apache.spark.SparkConf
import org.apache.spark.mllib.feature.PCA
import org.apache.spark.mllib.util.MLUtils
import org.apache.spark.sql.SparkSession
import org.apache.spark.mllib.regression.LinearRegressionWithSGD
注: LinearRegressionWithSGD 这个类在新版本的 Spark API 中已经被删除了, 所以这里要用老版本的 API 进行测试。
4.2.2 将 MNIST 数据集以 libsvm 格式进行加载并解析
val data = MLUtils.loadLibSVMFile(spark.sparkContext, "datas3/mnist.bz2")
4.2.3 计算特征向量, 简化降维操作
val featureSize = data.first().features.size
println("Feature Size: " + featureSize)
4.2.4 准备 训练集 和 测试集
// 准备 训练集 和 测试集 (第一种: 即使用原始特征维度的数据集)
val splits = data.randomSplit(Array(0.75, 0.25), 12345L)
val (training, test) = (splits(0), splits(1))
// 现在, 对于降维后, 训练集准备如下 (第二种: 即使用一半的特征)
val pca = new PCA(featureSize/2).fit(data.map(_.features))
val training_pca = training.map(
p => p.copy(features = pca.transform(p.features))
)
val test_pca = test.map(
p => p.copy(features = pca.transform(p.features))
)
3.2.5 训练线性回归模型
val numIterations = 20
val stepSize = 0.0001
val model = LinearRegressionWithSGD.train(training, numIterations, stepSize)
val model_pca = LinearRegressionWithSGD.train(training_pca, numIterations)
- 到这一步, 预测模型便已经创建成功, 后续只需要根据这个模型进行预测即可。
4.2.6 评估这两个模型
val valuesAndPreds = test.map(
point => {
val score = model.predict(point.features)
(score, point.label)
}
)
println("循环打印预测结果")
valuesAndPreds.foreach{
case (prediction, label) => {
println("prediction: " + prediction + ", label: " + label)
}
}
// 计算 PCA 的预测集
val valuesAndPreds_pca = test.map(
point => {
val score = model_pca.predict(point.features)
(score, point.label)
}
)
// 为不同的情况计算MSE并打印
val MSE = valuesAndPreds.map { case (v, p) => math.pow(v-p, 2) }.mean()
val MSE_pca = valuesAndPreds_pca.map { case (v, p) => math.pow(v-p, 2) }.mean()
println("Mean Squared Error = " + MSE)
println("PCA Mean Squared Error = " + MSE_pca)
不知为什么,博主运行出来的预测结果并不准,偏差很大:
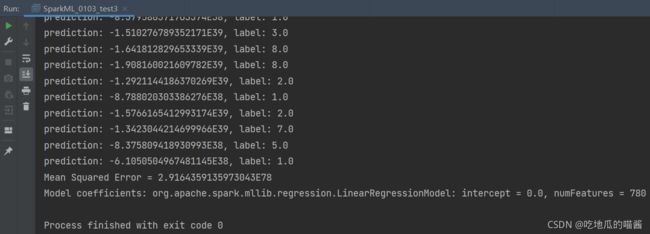
4.2.7 观察这两个模型的模型系数
println("Model coefficients: " + model.toString())
println("Model with PCA coefficients: " + model_pca.toString())
4.2.8 项目完整代码
import org.apache.spark.SparkConf
import org.apache.spark.mllib.feature.PCA
import org.apache.spark.mllib.util.MLUtils
import org.apache.spark.sql.SparkSession
import org.apache.spark.mllib.regression.LinearRegressionWithSGD
object SparkML_0103_test3 {
def main(args: Array[String]): Unit = {
// TODO 创建 Spark SQL 的运行环境
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("sparkML")
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
// step 1: 加载数据集并创建 RDD
val data = MLUtils.loadLibSVMFile(spark.sparkContext, "datas3/mnist.bz2")
// step 2: 计算特征向量, 简化降维操作
val featureSize = data.first().features.size
println("Feature Size: " + featureSize)
// step 3: 准备 训练集 和 测试集 (第一种: 即使用原始特征维度的数据集)
val splits = data.randomSplit(Array(0.75, 0.25), 12345L)
val (training, test) = (splits(0), splits(1))
// 现在, 对于降维后, 训练集准备如下 (第二种: 即使用一半的特征)
val pca = new PCA(featureSize/2).fit(data.map(_.features))
val training_pca = training.map(
p => p.copy(features = pca.transform(p.features))
)
val test_pca = test.map(
p => p.copy(features = pca.transform(p.features))
)
// step 4: 训练线性回归模型
val numIterations = 20
val stepSize = 0.0001
val model = LinearRegressionWithSGD.train(training, numIterations, stepSize)
val model_pca = LinearRegressionWithSGD.train(training_pca, numIterations)
// step 5: 评估这两个模型
val valuesAndPreds = test.map(
point => {
val score = model.predict(point.features)
(score, point.label)
}
)
println("循环打印预测结果")
valuesAndPreds.foreach{
case (prediction, label) => {
println("prediction: " + prediction + ", label: " + label)
}
}
// 计算 PCA 的预测集
val valuesAndPreds_pca = test.map(
point => {
val score = model_pca.predict(point.features)
(score, point.label)
}
)
// 为不同的情况计算MSE并打印
val MSE = valuesAndPreds.map { case (v, p) => math.pow(v-p, 2) }.mean()
val MSE_pca = valuesAndPreds_pca.map { case (v, p) => math.pow(v-p, 2) }.mean()
println("Mean Squared Error = " + MSE)
println("PCA Mean Squared Error = " + MSE_pca)
// step 6: 观察这两个模型的模型系数
println("Model coefficients: " + model.toString())
println("Model with PCA coefficients: " + model_pca.toString())
spark.close()
}
}