论文笔记:Multi-focus image fusion with a deep convolutional neural network
论文笔记:Multi-focus image fusion with a deep convolutional neural network
- 年份:2016
- 实验室:合肥工业大学生物医学工程系、中国科技大学自动化系
- 名词总结:
- 景深(depth-of-field (DOF))
- 活动水平测量(activity level measurement)
- 融合规则(fusion rule)
- 聚焦图(focus map)
- 二值图(binary map)
- 一致性检验(consistency verification)
文章目录
- 论文笔记:Multi-focus image fusion with a deep convolutional neural network
- 摘要
- Introduction
-
- 1、多聚焦图像融合的背景
- 2、传统的图像融合方法
- 3、基于深度学习的图像融合方法
- CNN model for image fusion
-
- 1、CNN model
- 2、CNNs for image fusion
-
- 1)可行性(Feasibility)
- 2)优势(Superiority)
- 1、Overview
- 2、Network design
- 3、Training
- 4、Detailed fusion scheme
-
- 1)Focus detection
- 2)Initial segmentation
- 3)Consistency verification
- 4)Fusion
- Experiments
-
- 1、Experimental settings
- 2、Experimental results and discussions
-
- 1)交换性验证(Commutativity verification)
- 2)与其他融合方法进行比较(Comparison with other fusion methods)
- 3)提出方法的中间结果(Intermediate results of the proposed method)
- 4)内存消耗和计算效率(Memory consumption and computational efficiency)
- 3、Extension to other-type image fusion issues
- 4、Future directions
- Conclusion
摘要
-
Image fusion的两个重要因素:活动水平测量(activity level measurement)、融合规则(fusion rule)
活动水平测量基本上是通过设计局部滤波器来提取高频细节来实现的,然后使用一些精心设计的规则来比较不同源图像的计算清晰度信息,以获得清晰/聚焦图像(clarity/focus map)。
-
现有的融合方法:空间域(spatial domain)、变换域(transform domain)
-
本文目的:用深度学习的方法来解决以上两个问题,从而实现学习源图像和焦点图之间的直接映射
-
本文方法:采用由高质量图像块及其模糊版本训练的深度卷积神经网络(CNN)对映射进行编码。
-
创新点:通过学习CNN模型,可以联合生成活动水平度量和融合规则,克服了现有融合方法所面临的困难。
-
实验结果:
- ①该方法在视觉质量和客观评价两方面都能获得最先进的融合性能。
- ②该方法采用并行计算,计算速度快,适合实际应用。
- ③实验中还简要展示了学习到的CNN模型对于其他类型图像融合问题的潜力。
Introduction
1、多聚焦图像融合的背景
-
问题:在光学镜头的特定焦距设置下,只有景深(depth-of-fifield (DOF))范围内的物体在照片中具有清晰的外观,而其他物体则可能模糊。
-
解决:多聚焦图像融合——融合使用不同焦距设置拍摄的同一场景的多幅图像,获得全聚焦图像
-
方法类别:变换域方法(transform domain methods) 、空间域方法(spatial domain methods)
-
变换域方法:
-
基于多尺度变换(MST)理论,如:基于拉普拉金字塔(LP)的融合方法(Laplacian pyramid (LP)-based fusion method)
-
MST方法的三步框架:分解(decomposition)、融合(fusion)和重构(reconstruction)
-
假设前提:源图像的活动水平可以通过选择变换域中的**分解系数(decomposed coefficients)**来测量
-
-
基于信号表示(SR)理论:利用独立分量分析(ICA)和稀疏表示(SR)等先进的信号表示理论将图像转换为单尺度特征域。
这类方法通常采用滑动窗口技术来实现近似的平移不变融合过程。这些方法的关键问题是探索一个有效的特征域来计算活动水平。
-
-
空间域方法:
-
基于块的融合策略(block-based methods)——将源图像分解成块,每对块用空间频率和和和修正拉普拉斯算子等有符号的活动水平度量进行融合。
改进:能够自适应对图像分割成不同大小的块。
-
基于像素的融合方法(pixel-based methods)——如:基于梯度信息的像素级空间域方法(pixel-based spatial domain method based on gradient information),这些方法通常对其活动水平测量的计算结果应用相对复杂的融合方案,从而进一步提高融合质量。
-
-
2、传统的图像融合方法
- 精心设计的活动水平度量和融合规则是很重要的,但问题是手动设计确实不是一项容易的任务。此外,从某种角度来看,几乎不可能提出一个考虑所有必要因素的理想设计
3、基于深度学习的图像融合方法
-
目的:采用深度学习的方法来解决传统方法需要手动设计活动水平度量和融合规则的问题,旨在学习源图像和焦点图之间的直接映射。
焦点映射表示像素级映射,该像素级映射包含在比较源图像的活动水平度量之后的清晰度信息。
-
实现:采用由高质量图像块及其模糊版本训练的深度卷积神经网络(CNN)对映射进行编码。
-
优势:通过学习CNN模型,可以联合生成活动水平测量和融合规则,从而克服了现有融合方法面临的上述困难。
-
本文贡献:
- 基于这一思想,提出了一种新的空间域多聚焦图像融合方法。
- 证明了从卷积网络获得的聚焦图是可靠的,非常简单的一致性验证技术可以产生高质量的融合结果。
- 该方法采用并行计算,计算速度快,适合实际应用。
- 最后,我们简要地展示了学习到的CNN模型对于其他类型的图像融合问题的潜力,如可见红外图像融合、医学图像融合和多曝光图像融合。
CNN model for image fusion
1、CNN model
-
CNN是一个典型的深度学习模型,该模型试图学习具有不同抽象级别的信号/图像数据的分层特征表示机制。
CNN是一个可训练的多阶段前馈人工神经网络,每个阶段包含一定数量的特征映射,对应于特征的抽象级别。特征图中的每个单位或系数称为神经元
-
通过对神经元进行线性卷积、非线性激活和空间池等操作,将不同阶段的特征图连接起来。
-
CNN的三个基本架构思想:局部感受野(local receptive fields)、共享权重(shared weights)和下采样(sub-sampling)
-
CNN中应用的3D卷积和非线性ReLU激活联合表示为: y j = m a x ( 0 , b j + ∑ i k i j ∗ x i ) y^j=max(0,b^j+\sum\limits_ik^{ij}*x^i) yj=max(0,bj+i∑kij∗xi)
-
卷积网络可以在一定程度上获得一些重要的平移不变性和尺度不变性。
-
CNN已成功地引入计算机视觉的各个领域,从高级任务到低级任务,如人脸检测、人脸识别、语义分割、超分辨率、面片相似性比较,这些基于CNN的方法通常在各自的领域优于传统方法,这是由于现代强大GPU的快速发展、有效训练技术的巨大进步以及易于访问大量图像数据。
2、CNNs for image fusion
1)可行性(Feasibility)
- 图像融合中焦点图的生成可以视为一个分类问题。具体而言,活动水平测量称为特征提取,而融合规则的作用类似于一般分类任务中使用的分类器。
- 对于大多数现有的融合方法,无论是在空间域还是变换域,活动水平测量基本上是通过设计局部滤波器来提取高频细节来实现的。
- 考虑到CNN模型中的基本操作是卷积(全连接操作可被视为与等于输入数据空间大小的核大小的卷积),将CNN应用于图像融合实际上是可行的
2)优势(Superiority)
- 它克服了人工设计复杂活动级别度量和融合规则的困难。主要任务被网络架构的设计所取代。
- 活动水平测量和融合规则可以通过学习CNN模型联合生成。在某种程度上,学习的结果可以被视为“最优”解决方案,因此可能比手动设计的更有效。
1、Overview
-
原理图

方法限制:一次只能处理两个预配准(pre-registered)的源图像。要处理两个以上的多焦点图像,可以将它们逐个串联融合。
-
四个步骤:
-
焦点检测(focus detection):两个源图像被馈送到预先训练好的CNN模型,以输出包含源图像焦点信息的分数图(score map)。然后,通过对重叠patches进行平均,从分数图中获得具有与源图像相同大小的聚焦图(focus map)。
分数图(score map)中的每个系数(coefficien)表示两幅源图像中一对patches的聚焦特性。
-
初始分割(initial segmentation):焦点图被分割为阈值为0.5的二值图(binary map)。
-
一致性检验(consistency verification):使用两种流行的一致性验证策略,即小区域移除和引导图像过滤,对二值分割地图进行细化,以生成最终决策图(decision map)。
-
融合(fusion):采用逐像素加权平均策略,利用最终决策图得到融合图像。
-
2、Network design
-
将多聚焦图像融合是一个二分类问题
-
输入:一对图像patches { p A , p B } \{p_A,p_B\} {pA,pB}
-
输出:目标是学习一个CNN,它的输出是从0到1的标量
当 p A p_A pA聚焦时, p B p_B pB散焦时,输出值应接近1;当 p A p_A pA聚焦时, p B p_B pB散焦时,输出值应接近0。输出值指示patch pair的焦点属性。
-
训练数据:训练CNN模型需要使用大量的补丁对作为训练样本。
每个训练样本都是同一场景的patch pair。当 p 1 p_1 p1比 p 2 p_2 p2清晰时,一个训练样本 { p 1 , p 2 } \{p_1,p_2\} {p1,p2}被定义为正样本,并且其标签被设置为1。相反,当 p 2 p_2 p2比 p 1 p_1 p1清晰且标签设置为0时,该示例被定义为负面示例。
-
输入图像大小问题:
-
背景:在实际应用中,源图像具有任意的空间大小。
-
解决:
-
滑动窗口技术(sliding-window technique):将图像分割为重叠的面片,然后将每对面片输入网络以获得分数。
考虑到由于patches重叠严重,存在大量重复卷积计算,这种基于patch-based的方法非常耗时。
-
通过reshaping parameters将全连接层转换为卷积层:将源图像作为一个整体输入到网络中,而不将其划分为块,直接生成密集预测图(输出大与输入尺寸相同,相当于像素级的分类预测)。
全连接操作可视为与内核大小的卷积,kernel大小等于输入数据的空间大小
-
-
本文方法:采用第二种方法,转换后,网络仅由卷积层和最大池化层组成,因此它可以将任意大小的源图像作为一个整体进行处理,以生成密集的预测。
网络的输出现在是一个分数图,其中的每个系数表示源图像中一对patches的聚焦特性。patch大小等于训练样本的大小(相当于没有切割)。【卷积核的移动步长为1,源图像中相邻patched的步长将由网络中最大池层的数量决定???】
-
-
两个输入分支的结构:采用相同的结构(siamese network),即权重相同
其他两种CNN的结构[47]:pseudo-siamese network、2-channel network
选择siamese network的原因:①图像融合中两张输入图像的重要性是相同的;②更容易训练
-
patch大小的选择(未将全连接层替换为卷积层的情况):16×16
-
太大(32×32):patch可能同时包含聚焦区域和散焦区域,这将导致融合图像中边界区域周围出现不期望的结果。
-
大小(8×8):用于训练CNN模型的补丁太小,无法保证分类精度。
-
-
模型结构:
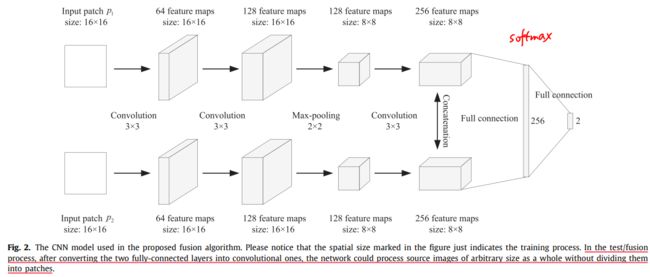
- 采用全连接层:
- 每个分支:three convolutional layers and one max-pooling layer
- 卷积核大小3×3,步长1
- 最大池化层的核大小2×2,步长2
- 输入:16×16的patches
- 输出:2维向量(2-way softmax layer)
- 全连接层转换为卷积层:
- 输入:H×W
- 卷积核大小3×3,步长1
- 最大池化层的核大小2×2,步长2
- 输出: ( ⌈ H / 2 ⌉ − 8 + 1 ) × ( ⌈ W / 2 ⌉ − 8 + 1 ) (\lceil H/2 \rceil-8+1)\times(\lceil W/2 \rceil-8+1) (⌈H/2⌉−8+1)×(⌈W/2⌉−8+1)
个人理解:每一卷积大小减小2,故3次卷积减小为8;一个池化层会使图像大小减半
- 相邻pathces的步长为2(池化层数k,步长 2 k 2^k 2k)
- 采用全连接层:
3、Training
- 数据集:ILSVRC 2012 validation image set,包含来自ImageNet数据集的50000幅高质量自然图像
- 模糊图像生成:对于每个图像(首先转换为灰度空间),使用高斯滤波获得五个具有不同模糊级别的模糊版本。具体而言,采用标准偏差为2且截止值为7×7的高斯滤波器。
- 后一个版本的模糊图像是在前一个版本基础上再进行一次高斯滤波得到的。
- 每一张模糊图像和原始图像被随机采样成20对的16×16的patches
- 数据集中有100,0000对patches(仅使用了约10000张)
- 数学定义:
- clear patch: p c p_c pc、blurred patch: p b p_b pb
- two input braches: p 1 p_1 p1 、 p 2 p_2 p2
- positive example: label=1 when p 1 = p c p_1=p_c p1=pc
- negative example: label=0 when p 1 = p b p_1=p_b p1=pb
- 损失函数:softmax loss function
- 优化:使用随机梯度下降(SGD)最小化loss function
- 超参数:batch size=128、momentum=0.9、weight decay=0.0005
- 权重更新的表达式: v i + 1 = 0.9 ⋅ v i − 0.0005 ⋅ α ⋅ ω − α ⋅ ∂ L ∂ ω w i , ω i + 1 = ω i + v i + 1 v_{i+1}=0.9·v_i-0.0005·\alpha·\omega-\alpha·\frac{\partial L}{\partial \omega_{w_i}} , \omega_{i+1}=\omega_i+v_{i+1} vi+1=0.9⋅vi−0.0005⋅α⋅ω−α⋅∂ωwi∂L,ωi+1=ωi+vi+1
- 权重初始化:Xavier algorithm(adaptively determines the scale of initialization according to the number of input and output neurons)
- 学习率:0.0001,当损失达到稳定状态时,我们手动将其降低10倍。
- 迭代次数:10 epochs through the 2 million training examples
- 为什么要手工使用高斯滤波器生成模糊图像作为训练数据,而不直接从真实的模糊图像中采样?
- 1、作者构建了一个包含一半来自真实图像的数据集,实验验证了效果与全部使用人工合成的相近
- 2、将 5个级别(五种离散标准差)的模糊效果减少为3个,验证集的精度降低,说明采用5个级别模糊效果的人工合成模糊图像能够很好覆盖现实的情况
- 3、可以更好将CNN模型扩展到其他融合任务上。我们可以自然地将学习的CNN模型扩展到其他类型的图像融合问题,例如多模态图像融合和多曝光图像融合。

左侧和右侧列分别主要捕获水平和垂直梯度信息。
- 各层卷积层的表征能力:
- 第一层:对于第一个卷积层,一些特征映射捕获高频信息,如左列所示,而另一些特征映射类似于右列所示的输入图像。这表明空间细节不能完全由第一层描述。
- 第二层:主要集中于提取覆盖各种梯度方向的空间细节。
- 第三层:对前面的梯度信息进行集成,其输出特征映射成功地表征了不同源图像的焦点信息。
- 全连接层:可以最终获得准确率得分图(accurate score map)
4、Detailed fusion scheme
1)Focus detection

源图像的16×16的patch(红色或绿色方块)经过CNN得到对应分数图(Score map)上的一个点
-
源图像A和B→灰度图A’和B’→(CNN)→score map S→(将S的每个点赋给对应的小patch)→focus map M(大小与源图像相同)
score map (S):该值越接近1或0,源图像A‘或B’的patch越聚焦

focus map (M):具有丰富细节的区域的值似乎接近1(白色)或0(黑色),而普通区域的值往往接近0.5(灰色)。
2)Initial segmentation
-
为了尽可能地保留有用的信息,需要进一步处理焦点图M。
-
生成二值图像:“choose-max” strategy (阈值0.5)

3)Consistency verification
-
问题1:二值分割地图可能包含一些分类错误的像素,可以使用小区域移除策略轻松移除这些像素。
-
方法:在二值映射中反转小于面积阈值的区域。(去除Fig.5(b)白色区域的黑色小孔)。阈值设置为0.001×H×W
-
问题2:使用初始决策图和加权平均规则得到融合图像在聚焦区域和散焦区域之间的边界周围存在一些不期望的伪影。
-
方法:利用引导滤波器来提高初始决策图的质量。
引导滤波器是一种非常有效的边缘保持滤波器,它能将引导图像的结构信息转化为输入图像的滤波结果。利用初始融合图像作为引导图像,指导初始决策图的滤波。
引导滤波算法中有两个自由参数:局部窗口半径 r r r和正则化参数 ε ε ε。在这项工作中,我们通过实验将r设置为8,ε设置为0.1。

4)Fusion
- 像素加权平均规则(pixel-wise weighted-average rule): F ( x , y ) = D ( x , y ) A ( x , y ) + ( 1 − D ( x , y ) ) B ( x , y ) F(x,y)=D(x,y)A(x,y)+(1-D(x,y))B(x,y) F(x,y)=D(x,y)A(x,y)+(1−D(x,y))B(x,y)
Experiments
1、Experimental settings

-
测试数据:40 pairs of multi-focus images (来自两个数据集)
-
方法比较:(6种)
-
Transform domain methods:the NSCT-based、SR-based 、NSCT-SR based methods
使用MST-SR fusion toolbox实现(地址见论文(似乎无法打开))
-
Spacial domain methods : the guided filtering (GF)-based、 the multi-scale weighted gradient (MWG)-based、 the dense SIFT (DSIFT)-based
使用MATLAB实现(地址见论文)
-
-
评估指标(4类)(每一类选择一种进行实验)
四类指标:基于信息理论的、基于图像特征的、基于图像结构相似性的和基于人类感知的。
- 标准化的相互信息 Q M I Q_{MI} QMI(Normalized mutual information):测量融合图像和源图像之间的互信息量。
- 基于梯度的度量 Q G Q_G QG(Gradient-based metric):评估从源图像注入融合图像的空间细节的范围。
- 基于结构相似性的度量 Q Y Q_Y QY(Structural similarity-based metric):测量融合图像中保留的结构信息量。
- 基于人类感知的度量 Q C B Q_{CB} QCB(Human perception-based metric):阐述了人类视觉系统的主要特征。
2、Experimental results and discussions
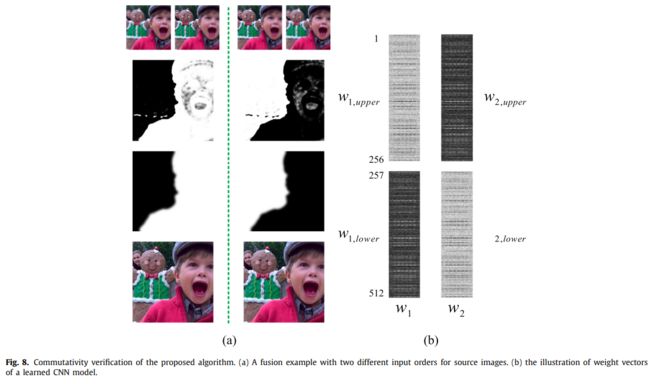
1)交换性验证(Commutativity verification)
-
图像融合的一个基本规则是可交换性,即源图像的顺序对融合结果没有影响。
-
考虑到所设计的网络,尽管两个分支共享相同的权重,但网络的交换性似乎是无效的,因为存在完全连接的层。切换源图像时,可能不会相应地切换完全连接层的输出来确保可交换性。
-
实验:
-
设计1:使用两种不同的输入顺序进行融合,使用分数图和最终融合图像来验证交换性。
分数图评估:对于来自相同源图像的每个score map pair,形成像素级求和。理想情况下,如果交换性有效,则每个像素的和值为1。
图像相似度:SSIM Index用于测量同一源图像对的两幅融合图像之间的接近程度。当两幅图像相同时,SSIM得分为1。
-
结果:
- 分数图:在所有40个示例中,上述平均值的平均值和标准偏差分别为1.001468和0.001873。
- 融合图像相似度(采用SSIM index度量):所有40个样本的SSIM得分平均值和标准偏差分别为0.999964和0.000161。
-
设计2:应用了一个轻微的CNN模型来解释上述结果,展示了前两层神经元权重矩阵的可视化图像
-
结果:两个神经元的bias接近0,因此满足交换性
-
为什么以上的设置得到满足:每一对样本都可以作为正/负样本,训练后的CNN权重受到这种条件约束。
-
结论:由于所提出的融合算法具有可交换性,因此在实际应用中不必考虑两幅源图像的顺序。
-
2)与其他融合方法进行比较(Comparison with other fusion methods)
-
基于视觉感知比较了不同融合方法的性能。
- 基于CNN的方法在boundary regions和mis-registered都表现良好
- 当仔细比较所有融合图像中grass和arm之间的边缘时,我们可以看到所提出的基于CNN的方法比所有其他方法(包括基于GF的方法)产生更自然的效果
-
客观性能评估
-

括号内的两位数字表示相应方法分别获得第一个(左一个)和第二个(右一个)位置的图像对的数量
-
DSIFT-based方法和本文提出方法在四种指标上明显优于其他四种方法
-
QMI测量源图像和融合图像之间的全局灰度统计特征的相似性(通过灰度直方图),而不管信息在图像中的空间分布如何。
-
当融合图像的像素值接近一个源图像时,QMI趋于变大。
-
必须考虑度量QMI与其他度量相结合
-
对于其他三个指标QG, QY和QCB,所提出的基于cnn的方法在平均分数上略优于基于dsift的方法
-
总的来说,至少可以说,所提出的方法与基于DSIFT的方法相比获得了具有竞争力的目标性能。
-
3)提出方法的中间结果(Intermediate results of the proposed method)

-
二值分割图:“choose-max” strategy(阈值为0.5)
- 对于多聚焦图像融合,二值分割patches可以解释为CNN模型的实际输出。
- 图中第二列可以看出,获得的分割贴图非常精确,大多数像素都被正确分类,这表明学习的CNN模型具有良好的能力。
-
二值分割图仍然存在两个缺陷:
-
一些像素有时分类错误,导致分割图中出现小区域或孔洞。
由于这些分类错误的像素所占比例很小,并且通常位于平坦区域,因此它们对融合结果的影响实际上很小。尽管如此,我们还是应用了**小区域移除策略(small region removal strategy)**来校正这些像素。【第三列】
-
聚焦区域和散焦区域之间的边界通常存在轻微的块效应。
-
初始决策图的融合图像【第四列】。
-
边缘保持滤波(edge-preserving filtering)提供了一个合适的工具来解决这个问题。使用引导滤波器(guided filter)获得的最终决策图【第五列】在边界区域中更自然。
-
-
-
总之,我们采用了两种时间高效的一致性验证方法(consistency verification approaches)【后处理】来细化二分类结果,即小区域移除/过滤和引导过滤。
- 图像融合方法中常用的一致性验证方法通常基于各种图像滤波技术,包括多数滤波(majority filtering)、中值滤波(median filtering)、形态学滤波(morphological filtering)、小区域滤波(small region filtering)、边缘保持滤波(edge-preserving filtering)。由于这些一致性验证技术通常比较简单,并且在图像融合中已广泛应用多年,因此可以将其视为常规的后处理技术。
- 为了取得进一步的进展并追求最先进的性能,许多最近提出的多聚焦图像融合方法倾向于采用一些先进的后处理技术,如图像消光技术(image matting technique),特征匹配方法(feature matching approach)和基于马尔可夫随机场(Markov Random Field based regularization method,MRF)的正则化方法。
- 由于CNN模型的高焦点检测精度,我们在融合算法中没有使用任何复杂的后处理技术。

- 在应用QG、QY和QCB的一致性验证技术时,分数略有增加。( Q M I Q_{MI} QMI比较特殊)
- 即使不使用一致性验证技术的基于CNN的方法在所有四个指标上都优于所有其他融合方法,这进一步验证了CNN用于图像融合的有效性。当然,通过应用一些先进的后处理技术,可以进一步提高融合质量。
4)内存消耗和计算效率(Memory consumption and computational efficiency)

- CNN模型占用的物理内存大小为35036168字节(约33.4 MB)。
- fc1层在整个参数中所占比例最大(约95.8%)。因此,大幅度降低内存消耗的可行方法是删除“fc1”层,即“conv3”层获得的512个有限元图直接连接到二维输出向量。
- 剩余完全连接层中的参数数为65538,slight模型仅占用约1.66MB的空间,

- slight模型的性能稍逊于原始模型,但差距非常小。这一结果意味着CNN模型设计的高度灵活性,而本文所使用的网络只是一个可行的网络。

- GPU模式:由并行和串行两部分组成。
- 并行部分表示源图像到获得分数图的过程。
- 串行部分表示从分数图开始的后续程序。
- slight模型的计算效率比使用原始模型高出两倍以上
3、Extension to other-type image fusion issues
- 为了展示学习到的CNN模型的泛化能力,我们将其应用扩展到多模态图像融合和多曝光图像融合。
- 本文针对以下两类任务进行了测试:
- 多模态图像融合算法被用于红外-可见光融合和医学图像融合。可以看出,融合图像很好地保留了源图像中的重要信息。
- 多曝光图像的融合质量也相对较高,因为融合图像可以提取大部分空间细节,而不会引入不需要的伪影。
- 不同图像融合问题所采用的技术并不相同。然而,他们共享从源图像到焦点图的CNN映射过程,可根据特定融合任务的特征选择或设计应用于聚焦图的后续技术。

4、Future directions
- 网络体系结构设计(Design of network architecture)
- 三类网络模型
- 网络深度
- patch大小
- 设计一个真正的端到端网络(需要ground-truth fused images用于训练)
- 开发更复杂的融合方案(Development of more complicated fusion schemes)
- 本文将patch大小设置为16,主要是为了提高边界区域的融合质量,但会牺牲一些焦/离焦分类的准确性。
- 一种可能的改进方法是训练几个输入大小不同的CNN模型,并联合它们来追求更好的性能。
- 扩展到其他类型的图像融合任务()Extension to other-type image fusion tasks)
Conclusion
- 本文提出的基于CNN的multi-focus image fusion method实现了source images到focus map的直接映射。
- 基于这一思想,通过学习CNN模型,可以联合生成活动水平度量和融合规则,从而克服现有融合方法所面临的困难。
- 本文四个主要贡献:
- 1)将CNN引入图像融合领域。讨论了CNN用于图像融合的可行性和优越性。据我们所知,这是第一次将CNN用于图像融合任务。
- 2) 我们提出了一种基于CNN模型的多聚焦图像融合方法。实验结果表明,该方法在视觉质量和客观评价方面均能达到最先进的效果。
- 3) 我们展示了学习到的CNN模型对于其他类型图像融合的潜力。
- 4) 对基于CNN的图像融合的未来研究提出了一些建议。