csv文件读取与写出
文章目录
- 一、pandas读取csv文件
- 二、pandas写出csv文件
- 三、利用csv模块读取csv文件
- 四、利用csv模块写出csv文件
一、pandas读取csv文件
1.导入pandas包
import pandas as pd
2.小数据量csv文件读取
pd.read_csv(file,encoding='utf-8',sep='\t')
# 可通过参数encoding修改编码方式,默认值为'gbk';sep修改分隔符,sep 默认值为',';
pd.read_csv() 返回结果为DataFrame
3.大数据量csv文件读取,利用参数chunksize
reader = pd.read_csv(file,chunksize=1000)
for df in reader: # 通过循环 获取每个分片的数据
print(df.head()) # 根据需要自定义后续处理
参数chunksize 默认为None,不分片处理;如需对数据分片处理添加chunksize,参数值需为整型,结果为按指定的chunksize大小分片的TextFileReader,可通过循环获取每个分片的数据
4.无表头csv文件读取
pd.read_csv(file,header=None)
参数header 用于判定是否把数据中第一行作为列名读入,默认数据第一行只作为列名;当待读取文件无表头时,可设置参数header=None;想把其他行作为列名时,可设置参数header为行索引
注意:header=0表示行索引为0的数据,即数据的第一行,非csv文件第一行
5.列名设置
pd.read_csv(file,header=None,names=col) # col为自定义列名,需为不包含重复元素的list
当header=None时,可用参数names自定义列名,如未定义则列名默认为由列数生成的整数列表
6.跳过错误行
pd.read_csv(file,warn_bad_lines=True)
当csv文件存在部分行格式或其他错误导致文件无法正常读取时,设置warn_bad_lines,可跳过错误行保证csv文件的读入,并抛出错误行行索引
7.跳过csv文件部分行
# 跳过文件开头行或指定行,使用参数skiprows
pd.read_csv(file,skiprows=5) # skiprows 值根据需要设置,可传整型或元素为整型的list
# 跳过文件结尾行
pd.read_csv(file,skipfooter=5) # skipfooter 默认值为值,具体可根据需要设置,可传整型
8.当待读取的文件名中包含中文时,直接read可能报如下OSError
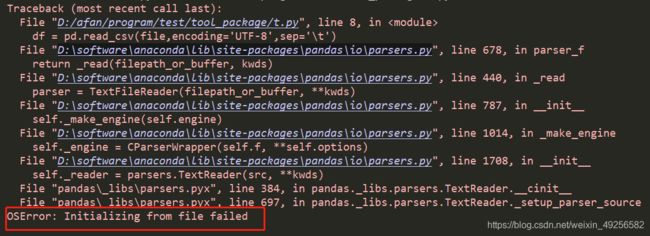
可配合使用with open as 和read_csv 读取文件,避免OSError
with open(file,encoding='utf-8') as f:
df = pd.read_csv(f,sep='\t') # encoding、sep参数根据需要调整
二、pandas写出csv文件
1.csv文件写出
pd.to_csv(output_file, sep=',', encoding='gbk')
# 可通过参数encoding修改编码方式,默认值为'gbk';sep修改分隔符,sep 默认值为',';
2.写出 无列名 csv文件
pd.to_csv(output_file, header=None) # header控制写出的csv文件是否包含列名,默认True 包含列名
3.写出 无索引 csv文件
pd.to_csv(output_file, index=False) # index默认值为True,当设置False时,不写出索引
三、利用csv模块读取csv文件
1.导入csv包
import csv
2.csv文件读取
with open(file, encoding='utf-8') as csvfile:
creader = csv.reader(csvfile, delimiter='\t') # 参数encoding、delimiter根据需要自定义
返回一个reader对象,可通过循环获取对象中的每一行
for row in creader:
print(row) # reader对象的每一行为字符串列表
后续可通过如下方式将reader对象转换为DataFrame
datas = []
with open(file, encoding='utf-8') as csvfile:
creader = csv.reader(csvfile, delimiter='\t')
for row in creader:
datas.append(row)
df = pd.DataFrame(datas[1:],columns=datas[0])
四、利用csv模块写出csv文件
1.csv文件写出
with open(output_file, 'w', encoding='utf-8', newline='') as csvfile:
cwriter = csv.writer(csvfile, delimiter='\t')
for row in datas:
cwriter.writerow(row)
# cwriter.writerow(['John', 'Lily']) # 自定义写出内容时,可直接将list传给cwriter.writerow()
注意:在定义csvfile时,一定要加newline=’’,否则写出的数据为隔行写出