HiveSQL 数据操控、查询语言(DML、DQL)
HiveSQL 数据操控、查询语言(DML、DQL)
1 Load——加载数据
-
将数据load加载到表中时,hive不会进行如何转换,加载操作是将数据文件移动到与Hive表对应的位置的纯复制/移动操作。
-
语法
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)] LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)] [INPUTFORMAT 'inputformat' SERDE 'serde'] (3.0 or later)- filepath:表示代移动数据的路径,可以引用一个文件,也可以是一个目录
- local:
- 如果指定了local,load命令将在本地文件系统中查找文件路径。如果指定了相对路径,他将相当于用户的当前工作目录进行解释
- 如果没有指定LOCAL关键字,如果filepath指向的是一个完整的URI,hive会直接使用这个URI。 否则如果没有指定schema或者authority,Hive会使用在hadoop配置文件中定义的schema 和 authority,即参数fs.default.name指定的(不出意外,都是HDFS)
- **注意:**如果对HiveServer2服务运行此命令。这里的本地文件系统指的是HiveServer2服务所在机器的本地Linux文件系统,不是Hive客户端所在的本地文件系统
- overwrite:如果使用了overwrite关键字,则目标表(或者分区)中的内容会被删除,然后再将 filepath 指向的文件/目录中的内容添加到表/分区中。
-
Hive3.0及更高版本中,除了移动复制操作之外,还支持其他加载操作,因为Hive在内部的某些场合下会将加载重写为insert as select
- 如果表是具有分区,load命令中没有指定分区,则将load转换为insert as select ,并假定最后一组为分区列。如果文件不符合预期的架构,就会报错
2. insert——插入数据
-
insert + select:将查询结果插入到表中
INSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...) [IF NOT EXISTS]] select_statement1 FROM from_statement; INSERT INTO TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement1 FROM from_statement;- insert overwrite 将覆盖表或分区中的如何现有的数据
- 需要保证查询结果列的数目和需要插入数据表格的列数目一致
- 如果查询出来的数据类型和插入表格对应的数据类型不一致,将会进行转换,但是不能保证转换一定成功,转换失败的数据将会是NULL
-
multiple inserts:多次插入,核心是:一次扫描。多次插入。功能就是减少扫描的次数
-
dynamic partition insert:动态分区插入
-
动态分区插入指的是:分区的值是由后续的select查询语句的结果来动态确定的,根据查询结果来自动分区
-
配置参数
set hive.exec.dynamic.partition = true; set hive.exec.dynamic.partition.mode = nonstrict; -
动态插入语法例子
-- 库下有一张student学生表 select * from student; -- 注意:分区字段名不能和表中的字段名重复 create table student_partition(Sno int,Sname string,Sex string,Sage int) partitioned by(Sdept string); -- 执行动态分区插入操作 insert into table student_partition partition(Sdept) select Sno,Sname,Sex,Sage,Sdept from student; -- 其中,Sno,Sname,Sex,Sage作为表的字段内容插入表中 -- Sdept作为分区字段值
-
-
insert + directory:支持将select查询的结果导出文件存放在文件系统中
-
语法
--标准语法: INSERT OVERWRITE [LOCAL] DIRECTORY directory1 [ROW FORMAT row_format] [STORED AS file_format] (Note: Only available starting with Hive 0.11.0) SELECT ... FROM ... --Hive extension (multiple inserts): FROM from_statement INSERT OVERWRITE [LOCAL] DIRECTORY directory1 select_statement1 [INSERT OVERWRITE [LOCAL] DIRECTORY directory2 select_statement2] ... --row_format : DELIMITED [FIELDS TERMINATED BY char [ESCAPED BY char]] [COLLECTION ITEMS TERMINATED BY char] [MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char] -
注意:导出操作是一个overwrite覆盖操作。慎用
-
目录可以是完整的URI。如果未指定scheme或Authority,则Hive将使用hadoop配置变量fs.default.name中的方案和Authority,该变量指定Namenode URI。
-
如果使用LOCAL关键字,则Hive会将数据写入本地文件系统上的目录。
-
写入文件系统的数据被序列化为文本,列之间用^ A隔开,行之间用换行符隔开。如果任何列都不是原始类型,那么这些列将序列化为JSON格式。也可以在导出的时候指定分隔符换行符和文件格式。
-
3. update、delete更新、删除操作
hive支持相关的update和delete操作,不过有很多的约束,需要Hive事务的支持
-
update操作语法
--1、开启事务配置(可以使用set设置当前session生效 也可以配置在hive-site.xml中) set hive.support.concurrency = true; --Hive是否支持并发 set hive.enforce.bucketing = true; --从Hive2.0开始不再需要 是否开启分桶功能 set hive.exec.dynamic.partition.mode = nonstrict; --动态分区模式 非严格 set hive.txn.manager = org.apache.hadoop.hive.ql.lockmgr.DbTxnManager; -- set hive.compactor.initiator.on = true; --是否在Metastore实例上运行启动压缩合并 set hive.compactor.worker.threads = 1; --在此metastore实例上运行多少个压缩程序工作线程。 --2、创建Hive事务表 create table trans_student( id int, name String, age int )clustered by (id) into 2 buckets stored as orc TBLPROPERTIES('transactional'='true'); --3、针对事务表进行insert update delete操作 insert into trans_student (id, name, age) values (1,"allen",18); select * from trans_student; update trans_student set age = 20 where id = 1; -
delete操作语法
--1、开启事务配置(可以使用set设置当前session生效 也可以配置在hive-site.xml中) set hive.support.concurrency = true; --Hive是否支持并发 set hive.enforce.bucketing = true; --从Hive2.0开始不再需要 是否开启分桶功能 set hive.exec.dynamic.partition.mode = nonstrict; --动态分区模式 非严格 set hive.txn.manager = org.apache.hadoop.hive.ql.lockmgr.DbTxnManager; -- set hive.compactor.initiator.on = true; --是否在Metastore实例上运行启动压缩合并 set hive.compactor.worker.threads = 1; --在此metastore实例上运行多少个压缩程序工作线程。 --2、创建Hive事务表 create table trans_student( id int, name String, age int )clustered by (id) into 2 buckets stored as orc TBLPROPERTIES('transactional'='true'); --3、针对事务表进行insert update delete操作 insert into trans_student (id, name, age) values (1,"allen",18); select * from trans_student; delete from trans_student where id =1;
3. select——查询数据
-
select语法
[WITH CommonTableExpression (, CommonTableExpression)*] SELECT [ALL | DISTINCT] select_expr, select_expr, ... FROM table_reference [WHERE where_condition] [GROUP BY col_list] [ORDER BY col_list] [CLUSTER BY col_list | [DISTRIBUTE BY col_list] [SORT BY col_list] ] [LIMIT [offset,] rows]-
查询的输入可以是普通物理表,视图,join查询结果或子查询结果,表名和列明不区分大小
-
all 和 distinct :选项指定是否返回重复的行。如果没有指定,则默认值为all(返回所有匹配的行)。distinct指定从结果集中删除重复的行
-
where:条件是一个bool表达式。在表达式中,你可以使用Hive支持的任何函数和运算符,但聚合函数除外。where子句支持某些类型的子查询
为什么不能使用聚合函数?
因为聚合函数要使用在确定的结果集中,而where子句还处于确定结果集的过程中,因而不能使用聚合函数
-
分区裁剪:对分区表进行查询时,会检查where子句或join中的on子句中是否存在对分区字段的过滤,如果存在,则访问查询符合条件的分区,即裁剪掉没必要的分区
-
group by:根据一个或多个列对结果集进行分组。
注意:出现在group by 中的字段,要么是group by 分组的字段,要么是被聚合函数应用的字段,避免出现一个字段多个值的歧义 -
having:可以让我们筛选分组后的各组数据,并且可以在having中使用聚合函数,因为此时where,group by已经执行结束,结果集已经确定
having 和 where 的区别:
- having是在分组后对数据进行过滤
- where是在分组前对数据进行过滤
- having后面可以使用聚合函数
- where后面不可以使用聚合函数
-
limit:用于约束select语句返回的行数。接受一个或两个函数,这两个函数都必须是非负数常量。
-
-
高级查询
-
order by :对输出的结果进行全局排序。默认排序顺序为升序(ASC),也可以指定为降序(DESC)
在Hive 2.1.0和更高版本中,支持在“ order by”子句中为每个列指定null类型结果排序顺序。ASC顺序的默认空排序顺序为NULLS FIRST,而DESC顺序的默认空排序顺序为NULLS LAST。
-
cluster by:根据同一个字段,分且排序。(不能指定排序规则)分为几组根据reduce task个数决定
分组规则:hash_func(col_name) % reduce task nums
-
distribute by + sort by :将cluster by 功能一分为二,distribute by 负责分,sort by负责分组内排序,并且可以是不同的字段。
如果distribute by + sort by 的字段一样,等同于cluster by
-
总结:
-
order by 会对输入做全局排序,因此只有一个reducer,会导致当输入规模较大时,需要较长的计算时间
-
sort by 不是全局排序,其在数据进入reduce前完成排序。因此,如果sort by进行排序,并且mapred.reduce.tasks>1,则sort by只保证每个reducer的输出有序,不保证全局有序。
-
distribute by(字段)根据指定字段将数据分到不同的reducer,分发算法是hash散列。
-
Cluster by(字段) 除了具有Distribute by的功能外,还会对该字段进行排序。
如果distribute和sort的字段是同一个时,此时,cluster by = distribute by + sort by

-
-
-
Hive SQL查询执行顺序
- from > join > where > group > having > order > select
- 聚合语句要比having子句优先执行,而where子句在查询过程中执行级别优先聚合函数
4. union——联合查询
-
用于将多个select语句的结果合并为一个结果集
-
语法
select_statement UNION [ALL | DISTINCT] select_statement UNION [ALL | DISTINCT] select_statement ...- 使用distinct关键字与只使用union默认值效果一样,都会删除重复行
- 使用all关键字,不会删除重复行,结果集包括所有select语句的匹配行(包括重复行)
- 注意:每个表返回的列的数量和名称必须相同
5. join——连接
-
语法树
join_table: table_reference [INNER] JOIN table_factor [join_condition] | table_reference {LEFT|RIGHT|FULL} [OUTER] JOIN table_reference join_condition | table_reference LEFT SEMI JOIN table_reference join_condition | table_reference CROSS JOIN table_reference [join_condition] (as of Hive 0.10)- table_reference:是join查询中使用的表名,也可以是子查询别名(查询结果当成表参与join)。
- table_factor:与table_reference相同,是联接查询中使用的表名,也可以是子查询别名。
- join_condition:join查询关联的条件, 如果在两个以上的表上需要连接,则使用AND关键字。
-
inner join
-
内连接:只有两个表中都存在于连接条件相匹配的数据才会被留下来。其中inner可以省略,inner join = join

-

-
-
left join
-
左外连接:以左表的全数据为准,右边与之关联。左表数据全部返回,右表关联上的显示返回,关联不上的显示null返回

-

-
-
right join
- 右外连接:join时以右表的全部数据为准,左边与之关联;右表数据全部返回,左表关联上的显示返回,关联不上的显示null返回
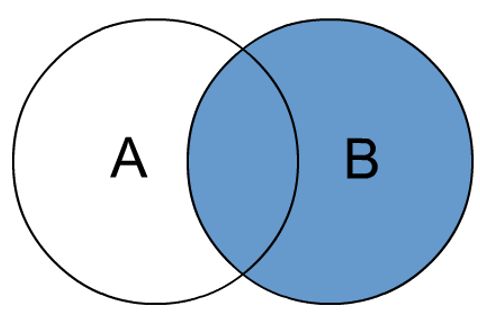

- 右外连接:join时以右表的全部数据为准,左边与之关联;右表数据全部返回,左表关联上的显示返回,关联不上的显示null返回
-
full outer join = full join
-
全外连接:对这两个数据集合分别进行左外连接和右外连接,然后再使用消去重复行的操作将上述两个结果集合并为一个结果集。
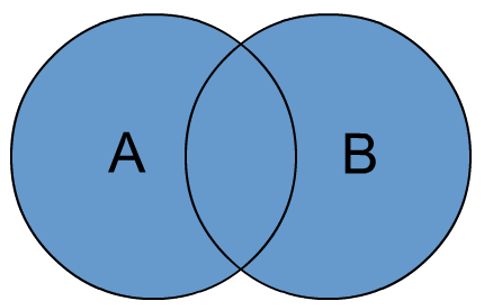
-
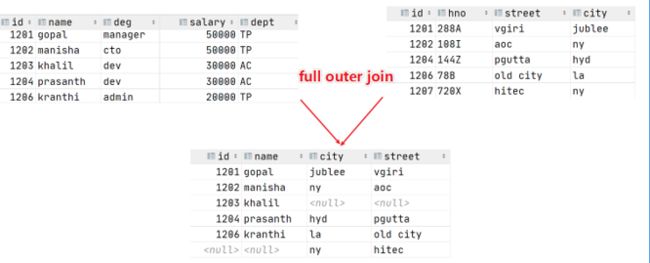
-
-
left semi join
- 左半开连接:返回左边表的记录,前提是其记录对于右边表满足on语句中的判断条件。(有点像inner join之后只返回左表的结果)
-
cross join
- 交叉连接:将会返回被连接的两个表的笛卡尔积,返回结果的行数等于两个表行数的乘机。对于大表来时,cross join慎用
-
join使用注意事项
-
如果每个表在连接子句中使用相同的列,则hive将多个表上的连接转换为单个MR作业
select a.val, b.val, c.val from a join b on (a.key = b.key1) join c on (c.key = b.key1) --由于联接中仅涉及b的key1列,因此被转换为1个MR作业来执行 select a.val, b.val, c.val from a join b on (a.key = b.key1) join c on (c.key = b.key2) --会转换为两个MR作业,因为在第一个连接条件中使用了b中的key1列,而在第二个连接条件中使用了b中的key2列。第一个map / reduce作业将a与b联接在一起,然后将结果与c联接到第二个map / reduce作业中。 -
join时的最后一个表会通过reduce流式传输,并在其缓冲之前的其他表,因此,将大表放置在最后有利于减少reduce阶段缓存数据所需要的内存
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key1) --由于联接中仅涉及b的key1列,因此被转换为1个MR作业来执行,并且表a和b的键的特定值的值被缓冲在reducer的内存中。然后,对于从c中检索的每一行,将使用缓冲的行来计算联接。 SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key2) --计算涉及两个MR作业。其中的第一个将a与b连接起来,并缓冲a的值,同时在reducer中流式传输b的值。 在第二个MR作业中,将缓冲第一个连接的结果,同时将c的值通过reducer流式传输。
-
6. CET——公用表表达式
-
公用表达式是一个临时结果集,该结果集是从with子句中指定的简单查询派生而来的,该查询紧接在select 或 insert关键字之前
-
CET案例
--选择语句中的CTE with q1 as (select sno,sname,sage from student where sno = 95002) select * from q1; -- from风格 with q1 as (select sno,sname,sage from student where sno = 95002) from q1 select *; -- chaining CTEs 链式 with q1 as ( select * from student where sno = 95002), q2 as ( select sno,sname,sage from q1) select * from (select sno from q2) a; -- union案例 with q1 as (select * from student where sno = 95002), q2 as (select * from student where sno = 95004) select * from q1 union all select * from q2; --视图,CTAS和插入语句中的CTE -- insert create table s1 like student; with q1 as ( select * from student where sno = 95002) from q1 insert overwrite table s1 select *; select * from s1; -- ctas create table s2 as with q1 as ( select * from student where sno = 95002) select * from q1; -- view create view v1 as with q1 as ( select * from student where sno = 95002) select * from q1; select * from v1;