【八数码问题】基于状态空间法的知识表示与状态搜索:无信息搜索(BFS/DFS) & 启发式搜索(A*)
- 前言
- 一、问题引入
- 二、状态空间法
-
- 1. 知识及其表示
- 2. 状态空间法定义
- 3. 问题求解
- 三、基于状态空间搜索法解决八数码问题
-
- 1. 八数码问题的知识表示
- 2. 状态空间图搜索
-
- 1. 无信息搜索
-
- 广度优先搜索(Breadth-First Search)
- 深度优先搜索(Depth-First Search)
- 2. 启发式搜索
-
- Dijkstra(UCS)算法
- A*算法
- 八数码问题构造启发函数$h(n)$实例
-
- 欧式距离法
- 曼哈顿距离法
- 总结
前言
搜索是人工智能里面研究的一个核心问题,个人认为机器学习本质也可以理解为一种搜索。类似强化学习,对抗学习等,都是用了一些值函数近似的方法,其本质都是在搜索参数,也可以理解为一种状态搜索。近些年来也有非常多学术研究者慢慢开始将两者融汇贯通,比如像Goog的planet,Muzero以及将熵用于蒙特卡洛树搜索中平衡探索和利用的关系等。
当然笔者也是初学者,这里给出两篇文章探讨:
机器学习的过程可以理解为一种问题空间搜索的过程吗?
将应用机器学习转化为求解搜索问题
一、问题引入
我们以《八数码难题》为例,题本身不是很难,但我们可以借助它来理解AI中的搜索策略,尝试从状态空间搜索的角度去理解它的解决方法。
问题描述 :在3×3的棋盘上,摆有八个棋子,每个棋子上标有1至8的某一数字。棋盘中留有一个空格,空格用0来表示。空格周围的棋子可以移到空格中。要求解的问题是:给出一种初始布局(初始状态)和目标布局(为了使题目简单,设目标状态为123804765),找到一种
最少步骤的移动方法,实现从初始布局到目标布局的转变。

二、状态空间法
1. 知识及其表示
知识:知识是人们在长期的生活和社会实践中,在科学研究及实验中累积起来的对客观世界的认识与经验。
注意:知识具有相对正确性、不确定性和不完整性,它在一定的条件和环境下正确。知识一定是可表示的,类似于艺术家的手感绘画方式、诗人的即兴作词方式,它大概率是不能用机器语言表示的,也就不能称之为知识。
(e.g. 刮台风大概率会下雨 、今天是火烧云明天是大概率是晴天…诸如此类“经验”我们都认为它是“知识”)
知识表示:知识表示是将人类知识形式化或者模型化,是对各种知识的机器形式语言描述,更通俗易懂的讲也可以理解为一种让计算机可以“接受”的用于描述知识的数据结构(表示方式)。
2. 状态空间法定义
状态空间方法 可形式化为四元组表示: (S,O,S0,G)
其中: S是状态空间,即问题所有可能状态的集合,O是操作算子的集合, S0是初始状态, G是目标状态。
以八数码问题为例,可以基于状态空间法形式化表示为:

状态空间的解:从初始状态 S0 到目标状态 G 的操作算子序列
3. 问题求解
问题求解(problem solving)是人工智能主要应用领域之一,它涉及表示、归约、推断、决策、规划、定理证明和相关过程等核心概念。
问题求解主要包括两个主要的方面
问题的表示:将问题以计算机可理解接受的方式进行描述,即知识表示。例如:利用我们在数据结构学习的图进行机器语言描述,将地图表示为图结构。

求解的方法:解决问题的办法,如搜索法,归约法,推理法。
问题的类型
• 单状态问题:确定的且可全部观察(八数码)
知道问题的所有状态,从而可以计算出最佳动作序列达到目标状态。
• 多状态问题:确定的且不可全部观察(军棋)
必须通过假定的动作序列和状态来推理以达到目标状态。
• 偶然性问题:不确定的且不可全部观察(股市分析)
必需通过实时反馈来决定执行下一步行动
• 探索性问题:状态空间未知(游戏,王者荣耀,英雄联盟)
通过实时环境感知和探索学习来决定实时执行行动
三、基于状态空间搜索法解决八数码问题
1. 八数码问题的知识表示
状态空间
一个八数码的局面就是一个状态,根据八数码问题定义给出所有可能的局面组成的集合即为状态空间。本问题实际上求解初始状态到目标状态的操作算子序列。
单状态的知识表示
八数码九宫格可以看作一个隐式节点图,只有九个存储数据的格子(节点),没有边的概念。针对本题而言,我们可以采用可以采用1*9的一维数组来存储这个隐式图的数据。在网上有不少利用9位整型数字存储的做法,但这里笔者采用Python列表来存储每一个状态(八个格子)的数据,使用这种存储结构的好处是我们可以很方便的对同类问题(4阶)进行扩展,并且能够在列表中存储空格的操作算子序列。

操作算子
显然,每一个状态可执行操作有:空格上移、空格下移、空格左移、空格右移,我们需要在我们定义的知识表示方式(数据结构)中实现状态的可执行操作,即我们需要在列表上交换对应位置的值:

代码实现:(Python多元赋值写法,其中space_index表示空格在列表中的索引)
空格左移:
if space_index % 3 != 0: # 判断空格是否可以向左移动
state[space_index], state[space_index - 1] = state[space_index - 1], state[space_index]
空格右移:
if (space_index + 1) % 3 != 0: # 判断空格是否可以向右移动
state[space_index], state[space_index + 1] = state[space_index + 1], state[space_index]
空格上移:
if space_index - 3 >= 0: # 判断空格是否可以向上移动
state[space_index], state[space_index - 3] = state[space_index - 3], state[space_index]
空格下移:
if space_index + 3 <= 8: # 判断空格是否可以向下移动
state[space_index], state[space_index + 3] = state[space_index + 3], state[space_index]
改进方法:利用一个字典来保存每个空格位置所能移动的所有位置索引,因此我们只需要直接遍历对应位置的列表即可。
position_movable={0:[1,3],1:[0,2,4],2:[1,5],3:[0,4,6],4:[1,3,5,7],5:[2,4,8],6:[3,7],7:[4,6,8],8:[5,7]}
list_position_movable = position_movable[space_index]
# 遍历位置列表进行交换:
for position in list_position_movable:
temp[space_index], temp[position] = temp[position], temp[space_index]
两种的时间效率差距不大,笔者在下面的代码中分别体现两种方法(DFS/BFS使用第一种;A*使用第二种)。
连续状态的知识表示
初始状态到目标状态的状态搜索过程可以表示为树结构,将每一个状态看作搜索树的一个节点,每个节点的子节点表示经过一次空格移动得到的下一状态,由此我们可以构建搜索状态空间树。
对一个图进行搜索意味着按照某种特定的顺序依次访问其顶点。为了提高我们解决问题的效率,在搜索前我们可以先尝试着去寻找判断问题是否有解的方法。对于八数码问题,我们可以通过下面的方法来判断两个状态之间是否可达:
首先判断两个状态之间的可达性 :
分别计算八数码状态的八个数据组成的序列的逆序数,根据两者逆序数进行判断。我们都知道:从小到大称为顺序,例如1,2,3。如果一对数的前后位置与大小顺序相反,即前面的数大于后面的数(例如:8,7),那么它们就称为一个逆序。一个排列中逆序的总数就称为这个排列的逆序数。逆序数为偶数的排列称为偶排列;逆序数为奇数的排列称为奇排列。
计算八数码节点的逆序数时将代表空格的0去除(不影响状态逆序数的计算),例如:
初始状态排列为:[1 , 3 , 2 , 4 , 5 , 6 , 7 , 8]
逆序数为:0 + 1 + 0 + 0 + 0 + 0 + 0 + 0 = 1 即为奇排列
目标状态排列为:[1 , 2 , 3 , 8 , 4 , 7 , 6 , 5]
逆序数为:0 + 0 + 0 + 4 + 0 + 2 + 1 + 0 = 7 即为奇排列
结论: 具有同奇或同偶排列的两个八数码才能移动可达,否则不可达。
2. 状态空间图搜索
图搜索策略主要分为无信息搜索(Uninformed Search)和启发式搜索(Heuristic Search)。
无信息搜索:也称为盲目搜索,即只按预定的控制策略进行搜索,在搜索过程中获得的中间信息不会用来改进控制策略。
启发式搜索: 在搜索中加入了与问题有关的启发性信息,用于指导搜索朝着最有希望的方向进行,加速问题的求解过程并找到最优解。
1. 无信息搜索
笔者水平十分有限,因此在算法的原理上不会深入探究,明白思想且能够运用即可,首先在这推荐几篇个人参考,觉得讲得不错且有深度的博文:
【算法】广度优先搜索(BFS)和深度优先搜索(DFS)
广度/宽度优先搜索 BFS (动画解算法 附C++\C、JAVA、Python的代码实现)
深度优先搜索和广度优先搜索及典例分析(走迷宫问题(BFS)和棋盘问题(DFS))
广度优先搜索(Breadth-First Search)
从树(本质上也可以看作图)上看:从初始状态开始在状态空间树搜索目标状态,首先遍历本层树节点,遍历完每一层树节点再遍历下一层,直到找到目标状态。
从图上看就是:首先遍历起点周围邻近的点,然后再遍历已经遍历过的点邻近的点,逐步的向外扩散,直到找到终点。

图上广度优先遍历与深度优先遍历对比(动画,可设置障碍)


检测去重
不难发现,在初始状态到目标状态的转移过程中会出现大量重复性的状态,产生了不必要的重复性无效搜索,因此我们可以在每一次状态入队前先检验该状态是否已经入队,确保每一种状态只检测一次,能有效避免重复性的搜索,极大的节省了搜索时间。
网上有不少解决重复的方法,例如:生成九位数全排列+二分查找记录去重、Hash去重(可能存在哈希冲突)等等。 Python的字典和集合其实也有不错的效果。Python的字典和集合底层原理简述
- Dict底层依靠哈希表(hash table)实现, 使用开放寻址法解决冲突,字典在内存中开销很大。实际上是以空间换时间。
- Set底层利用红黑树查询,查询复杂度O(logn);Dict是对key先进行了hash,然后再对hash生成一个红黑树进行查找,查找复杂虽然也是O(logn),但多了一个hash的过程。
就本题而言我们在判重时经常需要对重复状态进行判重查询,经过测试,使用Set集合时间和空间效率会更高,因此我们更适合用Set作为我们的判重记录表,节省计算资源。
笔者这里写了一个函数用于检测当前状态是否已经被访问,用于状态入队前检测:( 请注意这种方法只适用于不限制搜索层数的搜索方式,具体原因在下面深度优先搜索时会解释并解决。Set不能保存value,后面深度优先搜索中判重需要保存层数,所以我还是选择了dict。使用set代码会更加简洁,读者可以自行动手实现。)

至此我们就可以给出基于BFS搜索策略解决八数码问题的主要流程图:

其中堆栈直接用了Python标准库 queue模块,当然也可以自己写一个类实现,实现一些自己的存储结构和方法
queue模块有三种队列及构造函数
class queue.Queue(maxsize) :FIFO(队列),先进先出。
class queue.LifoQueue(maxsize): LIFO(堆栈),即先进后出。
class queue.PriorityQueue(maxsize):还有一种是优先级队列级别越低越先出来。
笔者这里只用到几个常用的方法,更多详细可查阅queue帮助文档
Q = queue.Queue()#生成一个队列 Q = queue.LifoQueue()#生成一个栈 Q.empty() Q.put(item) Q.get()Queue.empty()
如果队列为空,返回 True ,否则返回 False
Queue.put(item, block=True, timeout=None)
将 item 放入队列
Queue.get(block=True, timeout=None)
从队列(首部)移除并返回一个项目
运行环境:Python 3.6.9
笔者给了十分详细的注释,相信能帮助初学者理解
import time
import queue
# @Function: 计算逆序数
# @Parameter: state是存储每个状态的数据列表(九个字符型数字的列表)
def calculate_reverse_number(state):
state.remove('0')
# reverse_number用来记录逆序数
reverse_number = 0
for cur in state:
index = state.index(cur)
# 遍历cur后面的数字
for after_cur in state[index:]:
if cur > after_cur:
reverse_number += 1
if reverse_number % 2 == 0:
return 0
else:
return 1
# @Function: 判断初始状态到目标状态是否有解
# @Parameter: initial 初始状态数据列表
# purpose 目标状态数据列表
def judge_solvable(initial,purpose):
if initial == purpose:
print("起始状态为目标状态!")
exit(0)
initial_rev_num = calculate_reverse_number(initial)
purpose_rev_num = calculate_reverse_number(purpose)
if initial_rev_num != purpose_rev_num:
print("无法到达!")
exit(0)
# enqueued 字典 用来记录已经入队过的状态
# key表示当前状态,value表示是否入队 1已经入队,0未入队
enqueued = {} # E.G {'123405678':1,'123405687':1}
# 判断当前状态是否已经被访问
def is_visited(state):
state_key = ''.join(state)
# 字典get方法: 在字典中寻找state,找到则返回字典的值,找不到则返回默认值0
if enqueued.get(state_key, 0):
# 已经访问过
return True
else:
# 如果判断为未访问过,下一步要入队,直接在这里更改,提高代码复用性
enqueued[state_key] = 1
return False
# 寻找当前状态的所有下一步所有可行状态,将其加入队列
def find_next_state(state):
global create_point,Open
#找到空格(0)的位置
space_index = state.index('0')
if space_index - 3 >= 0: # 空格向上移动
temp = state.copy()
temp[space_index], temp[space_index - 3] = temp[space_index - 3], temp[space_index]
#未被访问过则入队
if not is_visited(temp[:9]):
temp.append("up")
Open.put(temp)
create_point += 1
if space_index + 3 <= 8: # 空格向下移动
temp = state.copy()
temp[space_index], temp[space_index + 3] = temp[space_index + 3], temp[space_index]
# 未被访问过则入队
if not is_visited(temp[:9]):
temp.append("down")
Open.put(temp)
create_point += 1
if space_index % 3 != 0: # 空格向左移动
temp = state.copy()
temp[space_index], temp[space_index - 1] = temp[space_index - 1], temp[space_index]
# 未被访问过则入队
if not is_visited(temp[:9]):
temp.append("left")
Open.put(temp)
create_point += 1
if (space_index + 1) % 3 != 0: # 空格向右移动
temp = state.copy()
temp[space_index], temp[space_index + 1] = temp[space_index + 1], temp[space_index]
# 未被访问过则入队
if not is_visited(temp[:9]):
temp.append("right")
Open.put(temp)
create_point += 1
if __name__ == '__main__':
initial_state = list(input('请输入初始状态:').split())
purpose_state = list(input('请输入目标状态:').split())
# 判断是否可以到达,如果不可以到达,则直接退出
judge_solvable(initial_state.copy(), purpose_state.copy())
# search_point为搜索的节点数 (已经经过判断,确认过不是目标状态的状态,入队然后检测删除的节点)
# create_point为生成节点数 (加入队列中的所有状态)
search_point = create_point = 0
# Open队列 用来存储生成节点
Open = queue.Queue()
# 初始状态入队,设置初始状态为已访问
Open.put(initial_state)
enqueued[''.join(initial_state)] = 1
# 开始搜索
start = time.time()
while True:
if Open.empty():
# open表空说明已经搜索完所有可能状态,未找到解
print("未找到解!")
exit(0)
# 取出队头元素 get是queue的方法:返回并删除队头元素
queue_first = Open.get()
# 判断是否是目标状态,是则输出查询信息,退出
if queue_first[:9] == purpose_state:
end = time.time()
search_point += 1
print("搜索成功!")
print('当前层次:{},已搜索节点数:{},已生成结点数{}'.format(len(queue_first) - 9, search_point, create_point))
print("空格的移动路径依次为:", end='')
for i in queue_first[9:]:
print(i, end='->')
print("完成")
print('消耗时间:{} Seconds'.format(end - start))
exit(0)
# 不是目标状态,本状态的所有下一步可能状态入队
search_point += 1
find_next_state(queue_first.copy())
测试示例对比:
无去重
去重
层数比较高时,不去重的方法会消耗大量的时间,时间复杂度和空间复杂度远远高于去重方法(实测差距巨大,不去重的代码跑几分钟)



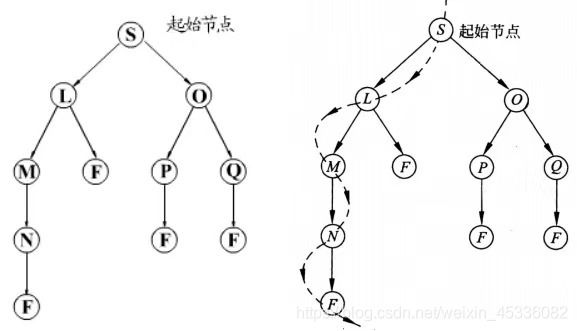
深度优先搜索(Depth-First Search)
深度优先搜索:顾名思义,优先扩展最新产生的(即最深的)节点,深度优先搜索沿着状态空间某条单一的路径从起始节点向下进行下去;只有当搜索到达一个没有子节点的状态时,它才考虑另一条替代的路径。
状态空间搜索树的深度可能为无限深,往往给出一个节点扩展的最大深度—深度界限。
图上广度优先遍历与深度优先遍历对比(动画,可设置障碍)

检测去重
我们前面写了一个检测函数,在每一次状态入队前先检验该状态是否已经入队,确保每一种状态只检测一次,但是它是建立在无搜索层数限制的前提下的。
深度优先搜索通常会设置一个最大搜索深度,因此在这种情况下判重状态不入队可能会导致部分子节点直接被忽略掉搜索不到的情况 。
假如下图中标红圈的两个状态是同一个状态,那么按照我们前面的去重方法,4号会先入队,在搜索11号时判定该状态已经入队,那么11号就不再入队,但是这样会出现一个问题,由于搜索深度的限制,导致4号只能继续向下搜索一层,而从11号出发还可以继续搜索3层,所以从11号出发搜索的第二层第三层就会直接被忽略掉没有搜索,而目标状态可能就在其中,因此会出现BUG。

容易知道:状态越浅,它搜索到的子节点越多
因此当判断状态的层数比已经入队的那个状态更深的时候,不需要入队(因为这个状态的子节点都已经被前面那个入队的状态的子节点所包含);比已经入队的那个状态更浅的时候则需要重复入队,并更新该状态的入队最浅层数。修改如下:
至此我们就可以给出基于DFS搜索策略解决八数码问题的主要流程图:

import time
import queue
# @Function: 计算逆序数
# @Parameter: state是存储每个状态的数据列表(九个字符型数字的列表)
def calculate_reverse_number(state):
state.remove('0')
# reverse_number用来记录逆序数
reverse_number = 0
for cur in state:
index = state.index(cur)
# 遍历cur后面的数字
for after_cur in state[index:]:
if cur > after_cur:
reverse_number += 1
if reverse_number % 2 == 0:
return 0
else:
return 1
# @Function: 判断初始状态到目标状态是否有解
# @Parameter: initial 初始状态数据列表
# purpose 目标状态数据列表
def judge_solvable(initial,purpose):
if initial == purpose:
print("起始状态为目标状态!")
exit(0)
initial_rev_num = calculate_reverse_number(initial)
purpose_rev_num = calculate_reverse_number(purpose)
if initial_rev_num != purpose_rev_num:
print("无法到达!")
exit(0)
# enqueued 字典 用来记录已经入队过的状态
# key表示当前状态,value表示当前状态的层数
enqueued = {} # E.G {'123405678':5,'123405687':6}
# 判断当前状态是否已经被访问
def is_visited(state):
global max_layers
state_key = ''.join(state[:9])
# 获取当前状态的层数
cur_layer = len(state) - 9
# 字典get方法: 在字典中寻找state,找到则返回字典的值,找不到则返回默认值0
if enqueued.get(state_key, 0):
# 判断当前的层数是否比已经入队的那个状态更低(浅),如果是的话则需要入队
if cur_layer < enqueued.get(state_key):
enqueued[state_key] = cur_layer
return False
return True
else:
# 如果判断为未访问过,下一步要入队,直接在这里更改,提高代码复用性
enqueued[state_key] = cur_layer
return False
# 寻找当前状态的所有下一步所有可行状态,将其加入队列
def find_next_state(state):
global create_point
# 找到空格(0)的位置
space_index = state.index('0')
if space_index - 3 >= 0: # 空格向上移动
temp = state.copy()
temp[space_index], temp[space_index - 3] = temp[space_index - 3], temp[space_index]
# 未被访问过则入队,如果是倒数第二层那么就不进行去重
if not is_visited(temp):
temp.append("up")
Open.put(temp)
create_point += 1
if space_index + 3 <= 8: # 空格向下移动
temp = state.copy()
temp[space_index], temp[space_index + 3] = temp[space_index + 3], temp[space_index]
# 未被访问过则入队
if not is_visited(temp):
temp.append("down")
Open.put(temp)
create_point += 1
if space_index % 3 != 0: # 空格向左移动
temp = state.copy()
temp[space_index], temp[space_index - 1] = temp[space_index - 1], temp[space_index]
# 未被访问过则入队
if not is_visited(temp):
temp.append("left")
Open.put(temp)
create_point += 1
if (space_index + 1) % 3 != 0: # 空格向右移动
temp = state.copy()
temp[space_index], temp[space_index + 1] = temp[space_index + 1], temp[space_index]
# 未被访问过则入队
if not is_visited(temp):
temp.append("right")
Open.put(temp)
create_point += 1
if __name__ == '__main__':
initial_state = list(input('请输入初始状态(例如:2 4 8 6 0 3 1 7 5):').split())
purpose_state = list(input('请输入目标状态(例如:1 2 3 8 0 4 7 6 5):').split())
max_layers = int(input("请输入深度优先搜索最大层数:"))
cur_layers = 0
# 判断是否可以到达,如果不可以到达,则直接退出
judge_solvable(initial_state.copy(), purpose_state.copy())
# search_point为搜索的节点数 (已经经过判断,确认过不是目标状态的状态,入队然后检测删除的节点)
# create_point为生成节点数 (加入队列中的所有状态)
search_point = create_point = 0
# Open后入先出队列 用来存储生成节点
Open = queue.LifoQueue()
# 初始状态入队,设置初始状态为已访问
Open.put(initial_state)
enqueued[''.join(initial_state)] = 1
# 开始搜索
start = time.time()
while true:
if Open.empty():
print("搜索完毕! 在",max_layers,"层未找到解!")
exit(0)
# 取出队头元素 get是queue的方法:返回并删除队头元素
queue_first = Open.get(block=True, timeout=None)
# 判断是否是目标状态,是则输出查询信息,退出
if queue_first[:9] == purpose_state:
end = time.time()
search_point += 1
print("搜索成功!")
print('当前层次:{},已搜索节点数:{},已生成结点数{}'.format(len(queue_first) - 9, search_point, create_point))
print("空格的移动路径依次为:", end='')
for i in queue_first[9:]:
print(i, end='->')
print("完成")
print('消耗时间:{} Seconds'.format(end - start))
exit(0)
# 不是目标状态,本状态的所有下一步可能状态入队
search_point += 1
cur_layers = len(queue_first) - 9
if cur_layers < max_layers:
find_next_state(queue_first.copy())
else:
print("已到最大深度",cur_layers,"层,返回父节点搜索")
#exit(0)
测试示例对比:
去重
不去重
层数比较高时,不去重的方法会消耗大量的时间,远远高于去重方法



2. 启发式搜索
启发式搜索(Heuristically Search)又称为有信息搜索(Informed Search),它是利用问题拥有的启发信息来引导搜索,达到减少搜索范围、降低问题复杂度的目的,这种利用启发信息的搜索过程称为启发式搜索。其代表算法为:贪婪最佳优先搜索(Greedybest-first search)和 A * 搜索。
举个形象的例子来说明A*算法思想:你是一个盲人,你在在广东,现在要步行去到北京,假如你任何信息都没有,就只是满世界随机游走(盲目搜索),直到寻找到北京。但我们都知道更优做法是:先去询问北京和广东的相对地理位置(启发信息),至少确定方向再去走。在寻找过程中,我们可以知道我们已经走过多长的路程(我们称之前向代价,它是真实的),再通过某种方法判断当前位置与北京的距离(我们称之为后向代价,它通常是估计出来的,实际求解问题我们是不知道解(路径)的),把前向代价和后向代价的和作为我们的代价,优先去走代价最小的方向,这就是A*算法的思想。
Dijkstra(UCS)算法
Dijkstra(UCS)算法详解
简单的说:简单的理解就是在宽度优先搜索的基础上加上了深度(已经遍历的层数)作为代价,优先扩展代价(已经走的路径消耗)最小的结点,你可以理解为在每一次入队时,都会对该状态所走过的路径进行计算,并以此进行排序,将走过路径最短的节点放在Open表的首部。
A*算法
A ∗ A* A∗ 可以认为是添加了启发式函数的 D i j k s t r a ( U C S ) Dijkstra(UCS) Dijkstra(UCS)算法,在 D i j k s t r a Dijkstra Dijkstra算法的基础上,构造一个函数, n n n为当前扩展结点, h ( n ) h(n) h(n)表示结点 n n n到终点的开销估计,我们称 h ( n ) h(n) h(n)为启发函数。然后建立估价函数
f ( n ) = g ( n ) + h ( n ) f(n)=g(n)+h(n) f(n)=g(n)+h(n)
其中 g ( n ) g(n) g(n)为从起点到结点n已经使用了的代价, h ( n ) h(n) h(n)为从当前结点n到目标节点的预测代价。所以 f ( n ) f(n) f(n)可以理解为是“从起点出发经过结点n再到终点的代价估计”。
显然对于八数码问题中,我们的 g ( n ) g(n) g(n)就是空格移动的步数,也就是当前的搜索深度。接下来我们需要构造结点 n n n到终点的开销估计函数 h ( n ) h(n) h(n)
h ( n ) ≤ h ∗ ( n ) h(n) ≤ h^*(n) h(n)≤h∗(n)
我们构造的必须满足可纳性:(其中 h ∗ ( n ) h^*(n) h∗(n)表示结点 n n n到终点的真实开销估计)
可纳启发式函数不会过高估计结点到目标的代价, 此时算法的解是最优的, h ( n ) h(n) h(n)越接近 h ∗ ( n ) h^*(n) h∗(n),效果越优。当 h ( n ) = h ∗ ( n ) h(n)=h^*(n) h(n)=h∗(n)时,算法的解是最优的,效果也是最优的。

几篇写得不错的参考文章:
Dijkstra算法和A* 算法总结
启发式搜索 (Heuristically Search)-【贪婪最佳优先搜索】和【A*搜索】
八数码问题构造启发函数 h ( n ) h(n) h(n)实例
欧式距离法
欧式距离: 初始状态中的每一个棋子位置与目标状态的相应棋子位置的几何距离
例如:初始状态的6和目标状态的6相差了1个单位距离,初始状态的8和目标状态的8相差了 2 \sqrt{2} 2个单位距离
因此我们的启发函数就是去找出当前状态所有不在目标位置的棋子,它们距离目标位置的欧式距离之和就是当前状态到目标状态的开销估计代价 h ( n ) h(n) h(n)。
曼哈顿距离法
曼哈顿距离: 初始状态中的每一个棋子位置与目标状态的相应棋子位置的网格线距离
图片来源

同理我们可以得到以曼哈顿距离计算的开销估计代价 h ( n ) h(n) h(n)。
它们的代码实现也非常简单,我们只需要找出当前状态所有不在目标位置的棋子坐标,分别计算与目标坐标的距离再求和即可

支持我们就构建好了 A ∗ A^* A∗算法的两种估价函数,我们使用前面提到的python标准库的queue模块优先队列作为Open表进行存储,它在新状态入队存储时会自动根据我们设定的富比较方法进行排序。
为了帮助初学者,我写了下面这个小demo,初学者可以尝试跑一跑代码理解一下。
#@desc: 实验python中的富比较方法,__lt__, __gt__, __le__, __ge__, __eq__, __ne__这6个富比较方法
import queue
class Test(object):
def __init__(self, value):
self.value = value
# 可以理解为:用户指定排序方法,教计算机比较大小的准则
def __lt__(self, other):
print('调用Test的__lt__方法')
return self.value < other.value
def __gt__(self, other):
print('调用Test的__gt__方法')
return self.value > other.value
def test_a(self):
print(self.value)
# 优先队列
q = queue.PriorityQueue()
q.put(Test(1))
q.put(Test(2))
q.put(Test(-1))
# 观察输出顺序,值低的会先出来,说明优先队列中从小到大进行排序
q.get().test_a()
q.get().test_a()
q.get().test_a()
接下来我们可以给出我们的对于八数码问题的解决方法
我们通过一个优先队列来实现 A ∗ A^* A∗算法,每一个状态入队都会根据该状态的 f ( n ) f(n) f(n)进行排序入队,整个Open表会根据 f ( n ) f(n) f(n)从小到大排序状态,因此我们每一次取出的队头元素都是目前队列中估价 f ( n ) f(n) f(n)最低的状态。

新状态入队:
![]()
至此我们可以给出完整的八数码解决方案
"""
@Author: XDT
@last_edit_time: 2021-04-07
@version: python 3.6.9
@Description:本程序分别输出四种方法(BFS,DFS,A*_Euclidean,A*_Manhattan)解决用户八数码问题的搜索结果
@Input:手动输入初始状态和目标状态、深度优先搜索的最大搜索深度
@Input_example:
最小深度31层 最小23层 最小18层
初始状态: 2 6 4 1 3 7 0 5 8 初始状态: 1 2 3 4 5 6 7 8 0 初始状态: 2 7 3 6 0 4 5 8 1
目标状态: 8 1 5 7 3 6 4 0 2 目标状态: 2 0 4 8 6 5 3 1 7 目标状态: 1 2 3 8 0 4 7 6 5
"""
import time
import queue
from math import sqrt
# State是一个类,data:数据列表存储9个数字以及初始状态到这个状态的操作序列
# f_distance表示该状态到目标状态的估价(gn+hn)
# 注意:我们只在使用A*算法时才使用State类作为数据结构,放入优先队列
class State(object):
def __init__(self, data, f_distance):
self.data = data
self.f_distance = f_distance
# 富比较,用户指定类的排序方法
def __lt__(self, other):
return self.f_distance < other.f_distance
# @Function: 计算f(n) = f_distance = g_distance + h_distance
# @Parameter: state是每一个状态数据列表,数据列表存储9个数字以及初始状态到这个状态的操作序列(上面定义的状态类中的data)
# : purpose是目标状态
# : method是方法 如:欧式距离法,曼哈顿距离法
def calculate_h_distance(state, purpose, methods):
g_distance = len(state) - 9
state = state[:9]
h_distance = 0
for index_cur in range(9):
if state[index_cur] != purpose[index_cur]:
# 获取该数字在当前状态的位置坐标
x_cur = index_cur % 3
y_cur = index_cur / 3
# 找到该数字在目标状态的索引
index_pur = purpose.index(state[index_cur])
# 获取该数字在目标状态的位置坐标
x_pur = index_pur % 3
y_pur = index_pur / 3
# 根据用户要求的方法计算距离
if methods == "A*_Euclidean":
h_distance += sqrt((x_cur - x_pur) ** 2 + (y_cur - y_pur) ** 2)
elif methods == "A*_Manhattan":
h_distance += abs(x_cur - x_pur) + abs(y_cur - y_pur)
return g_distance + h_distance
# @Function: 计算逆序数
# @Parameter: state是存储每个状态的数据列表(九个字符型数字的列表)
def calculate_reverse_number(state):
state.remove('0')
# reverse_number用来记录逆序数
reverse_number = 0
for cur in state:
index = state.index(cur)
# 遍历cur后面的数字
for after_cur in state[index:]:
if cur > after_cur:
reverse_number += 1
if reverse_number % 2 == 0:
return 0
else:
return 1
# @Function: 判断初始状态到目标状态是否有解
# @Parameter: initial 初始状态数据列表
# purpose 目标状态数据列表
def judge_solvable(initial, purpose):
if initial == purpose:
print("起始状态为目标状态!")
exit(0)
initial_rev_num = calculate_reverse_number(initial)
purpose_rev_num = calculate_reverse_number(purpose)
if initial_rev_num != purpose_rev_num:
print("无法到达!")
exit(0)
# @Function: 判断当前状态是否已经被访问
# @Parameter: state是每一个状态数据列表,数据列表存储9个数字以及初始状态到这个状态的操作序列(上面定义的状态类中的data)
# : enqueued 字典 用来记录已经入队过的状态
# : key表示当前状态,value表示是否入队 1已经入队,0未入队
enqueued = {} # E.G {'123405678':1,'123405687':1}
def is_visited(state):
global max_layers
state_key = ''.join(state[:9])
# 获取当前状态的层数
cur_layer = len(state) - 9
# 字典get方法: 在字典中寻找state,找到则返回字典的值,找不到则返回默认值0
if enqueued.get(state_key, 0):
# 对于DFS:判断当前的层数是否比已经入队的那个状态更低(浅),如果是的话则需要入队
if cur_layer < enqueued.get(state_key):
enqueued[state_key] = cur_layer
return False
# 已经访问过
return True
else:
# 如果判断为未访问过,下一步要入队,直接在这里更改,提高代码复用性
enqueued[state_key] = cur_layer
return False
# @Function: 寻找当前状态的所有下一步所有可行状态,将其加入队列
# @Parameter: state是每一个状态数据列表,数据列表存储9个数字以及初始状态到这个状态的操作序列(上面定义的状态类中的data)
# : position_movable 字典用来记录空格所能移动的位置
# : key表示空格位置索引,value表示该位置所能移动到的位置列表
position_movable = {0: [1, 3], 1: [0, 2, 4], 2: [1, 5], 3: [0, 4, 6], 4: [1, 3, 5, 7], 5: [2, 4, 8], 6: [3, 7],
7: [4, 6, 8], 8: [5, 7]}
def find_next_state(state):
global create_point, Open, method, methods_dict
# 找到空格(0)的位置,并获取该位置所能移动的位置列表
space_index = state.index('0')
list_position_movable = position_movable[space_index]
# 遍历所有能利用的位置
for position in list_position_movable:
temp = state.copy()
temp[space_index], temp[position] = temp[position], temp[space_index]
# 未被访问过则入队
if not is_visited(temp):
# 记录空格移动的位置
if space_index == position + 3:
temp.append("up")
elif space_index == position - 3:
temp.append("down")
elif space_index == position + 1:
temp.append("left")
elif space_index == position - 1:
temp.append("right")
# 当使用A*算法时:创建State类 使用bfs和dfs则直接用列表入队
if method >= 3:
temp = State(temp, calculate_h_distance(temp, purpose_state, methods_dict[method]))
Open.put(temp)
create_point += 1
# @Function: 搜索:循环检测Open表
# @Parameter: method_index是当前使用的方法的索引,也就是methods_dict的key
# : methods_dict = {1: "BFS", 2: "DFS", 3: "A*_Euclidean", 4: "A*_Manhattan"}
def search(method_index):
global Open, search_point, create_point, methods_dict
# 开始搜索
start = time.time()
while True:
if Open.empty():
# open表空说明已经搜索完所有可能状态,未找到解
print("使用", methods_dict[method_index],"算法未找到解!\n")
return
# 取出队头元素(如果是A*算法,Open表中存储的是一个类) get是queue的方法:返回并删除队头元素
if method_index >= 3:
queue_first = Open.get().data
else:
queue_first = Open.get()
# 判断是否是目标状态,是则输出信息,退出
if queue_first[:9] == purpose_state:
end = time.time()
search_point += 1
print("使用", methods_dict[method_index], "算法搜索成功!结果如下:")
print('当前层次:{},已搜索节点数:{},已生成结点数{}'.format(len(queue_first) - 9, search_point, create_point))
print("空格的移动路径依次为:", end='')
for i in queue_first[9:]:
print(i, end='->')
print("完成")
print('消耗时间:{} Seconds'.format(end - start),"\n")
return
search_point += 1
# 不是目标状态,本状态的所有下一步可能状态入队 (其中DFS需要判断是否到达最大深度)
cur_layers = len(queue_first) - 9
if method_index == 2:
if cur_layers < max_layers:
find_next_state(queue_first.copy())
else:
find_next_state(queue_first.copy())
if __name__ == '__main__':
print("欢迎使用本程序,本程序输出四种方法(BFS,DFS,A*_Euclidean,A*_Manhattan)的搜索结果,部分搜索可能会稍慢,请耐心等待程序运行完毕!")
initial_state = list(input('请输入初始状态:').split())
purpose_state = list(input('请输入目标状态:').split())
max_layers = int(input('请输入最大搜索深度(仅用于DFS):'))
# 判断是否可以到达,如果不可以到达,则直接退出
judge_solvable(initial_state.copy(), purpose_state.copy())
methods_dict = {1: "BFS", 2: "DFS", 3: "A*_Euclidean", 4: "A*_Manhattan"}
#分别使用四种方法进行搜索,展示搜索结果
for method, method_name in methods_dict.items():
# search_point为搜索的节点数 (已经经过判断,确认过不是目标状态的状态,入队然后检测删除的节点)
# create_point为生成节点数 (加入队列中的所有状态)
search_point = create_point = 0
# 初始状态入队
create_point += 1
enqueued[''.join(initial_state)] = 1
if method == 1:
# Open队列 用来存储生成节点
Open = queue.Queue()
Open.put(initial_state)
search(method)
elif method == 2:
# Open栈 用来存储生成节点
Open = queue.LifoQueue()
Open.put(initial_state)
search(method)
else:
# Open优先队列 用来存储生成节点
Open = queue.PriorityQueue()
Open.put(State(initial_state, calculate_h_distance(initial_state, purpose_state, methods_dict[method])))
search(method)
enqueued.clear() # 每一次搜索完毕,清空字典和open表
Open.queue.clear()
测试案例:


总结
-
深度优先搜索优缺点
①优点:优先搜索一棵子树,然后是另一棵,所以和宽度优先搜索对比,有着平均消耗内存相对较少的优点,在一定条件下消耗时间会很少(搜索方向和解大致一致时很快)。
②缺点:要多次回溯遍历,会受到搜索顺序(初始方向)的影响,可能会搜索所有路径,在解深度很大的情况下效率不高。 -
宽度优先搜索优缺点
①优点:对于解决最短或最短路径问题特别有效,而且寻找深度小,每个结点只访问一遍,不需要回溯,结点总是以最短路径被访问,所以第二次路径确定不会比第一次短
②缺点:平均内存耗费量相对深度优先搜索较大,在解深度很大时空间复杂度和时间复杂度都较高。 -
贪婪算法是指在对问题求解时,一定程度利用了启发信息(例如路径查找时预估与目的地的距离),总是做出在当前看来是最好的选择,也就是说,不从整体最优上加以考虑,只做出在某种意义上的局部最优解,因此它可能找不到最短的路径,但也是一种启发式的方法,搜索效果十分受启发函数准确性的影响。
-
A/A*算法
对于问题的搜索过程,如果加上启发函数,不让它盲目的寻找,就衍生出很多启发式搜索算法。A* 是其中的一种。之所以加一个 * 号,是因为它的启发式函数是有限制的,这个限制确保它能找到绝对最优解,去掉这个限制,就是 A 算法了,所以A算法是有可能得不到最优解的。
优点: A ∗ A* A∗类似于Dijkstra和贪婪算法的结合体,它既考虑走过的真实代价,也考虑了预估代价,它比Dijkstra更具有启发性,不会过于盲目的搜索,也比贪婪算法更谨慎,不会太过于依赖启发函数的影响。它具有优势性,能找到最优解,平均消耗时间更低。
缺点: A ∗ A* A∗算法在搜索过程中需要相对准确且完整的启发信息,虽然在八数码问题中我们有多种距离构造的可纳性函数得到了不错的启发信息,但这在更泛化的搜索问题中其实是很难保证启发信息的可纳性的。( D ∗ D* D∗算法:不完整启发信息搜索)