深度学习之超分辨率算法——SRGAN
-
更新版本
-
实现了生成对抗网络在超分辨率上的使用
-
更新了损失函数,增加先验函数
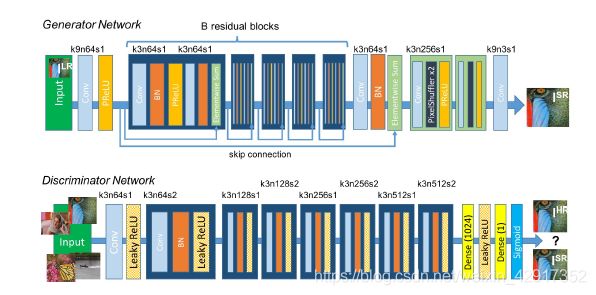
-
SRresnet实现
import torch
import torchvision
from torch import nn
class ConvBlock(nn.Module):
def __init__(self, kernel_size=3, stride=1, n_inchannels=64):
super(ConvBlock, self).__init__()
self.sequential = nn.Sequential(
nn.Conv2d(in_channels=n_inchannels, out_channels=n_inchannels, kernel_size=(kernel_size, kernel_size),
stride=(stride, stride), bias=False, padding=(1, 1)),
nn.BatchNorm2d(n_inchannels),
nn.PReLU(),
nn.Conv2d(in_channels=n_inchannels, out_channels=n_inchannels, kernel_size=(kernel_size, kernel_size),
stride=(stride, stride), bias=False, padding=(1, 1)),
nn.BatchNorm2d(n_inchannels),
nn.PReLU(),
)
def forward(self, x):
redisious = x
out = self.sequential(x)
return redisious + out
class Head_Conv(nn.Module):
def __init__(self):
super(Head_Conv, self).__init__()
self.sequential = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=64, kernel_size=(9, 9), stride=(1, 1), padding=(9 // 2, 9 // 2)),
nn.PReLU(),
)
def forward(self, x):
return self.sequential(x)
class PixelShuffle(nn.Module):
def __init__(self, n_channels=64, upscale_factor=2):
super(PixelShuffle, self).__init__()
self.sequential = nn.Sequential(
nn.Conv2d(in_channels=n_channels, out_channels=n_channels * (upscale_factor ** 2), kernel_size=(3, 3),
stride=(1, 1), padding=(3 // 2, 3 // 2)),
nn.BatchNorm2d(n_channels * (upscale_factor ** 2)),
nn.PixelShuffle(upscale_factor=upscale_factor)
)
def forward(self, x):
return self.sequential(x)
class Hidden_block(nn.Module):
def __init__(self):
super(Hidden_block, self).__init__()
self.sequential = nn.Sequential(
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=(3, 3), stride=(1, 1), padding=(3 // 2, 3 // 2)),
nn.BatchNorm2d(64),
)
def forward(self, x):
return self.sequential(x)
class TailConv(nn.Module):
def __init__(self):
super(TailConv, self).__init__()
self.sequential = nn.Sequential(
nn.Conv2d(in_channels=64, out_channels=3, kernel_size=(9, 9), stride=(1, 1), padding=(9 // 2, 9 // 2)),
nn.Tanh(),
)
def forward(self, x):
return self.sequential(x)
class SRResNet(nn.Module):
def __init__(self, n_blocks=16):
super(SRResNet, self).__init__()
self.head = Head_Conv()
self.resnet = list()
for _ in range(n_blocks):
self.resnet.append(ConvBlock(kernel_size=3, stride=1, n_inchannels=64))
self.resnet = nn.Sequential(*self.resnet)
self.hidden = Hidden_block()
self.pixelShuufe = []
for _ in range(2):
self.pixelShuufe.append(
PixelShuffle(n_channels=64, upscale_factor=2)
)
self.pixelShuufe = nn.Sequential(*self.pixelShuufe)
self.tail_conv = TailConv()
def forward(self, x):
head_out = self.head(x)
resnet_out = self.resnet(head_out)
out = head_out + resnet_out
result = self.pixelShuufe(out)
out = self.tail_conv(result)
return out
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.model = SRResNet()
def forward(self, x):
'''
:param x:lr_img
:return:
'''
return self.model(x)
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.hidden = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=64, kernel_size=(3, 3), stride=(1, 1), padding=(3 // 2, 3 // 2)),
nn.LeakyReLU(),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1)),
nn.BatchNorm2d(64),
nn.LeakyReLU(),
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=(3, 3), stride=(1, 1), padding=(0, 0)),
nn.BatchNorm2d(128),
nn.LeakyReLU(),
nn.Conv2d(in_channels=128, out_channels=128, kernel_size=(3, 3), stride=(2, 2), padding=(0, 0)),
nn.BatchNorm2d(128),
nn.LeakyReLU(),
nn.Conv2d(in_channels=128, out_channels=256, kernel_size=(3, 3), stride=(1, 1), padding=(0, 0)),
nn.BatchNorm2d(256),
nn.LeakyReLU(),
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=(3, 3), stride=(2, 2), padding=(0, 0)),
nn.BatchNorm2d(256),
nn.LeakyReLU(),
nn.Conv2d(in_channels=256, out_channels=512, kernel_size=(3, 3), stride=(1, 1), padding=(0, 0)),
nn.BatchNorm2d(512),
nn.LeakyReLU(),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=(3, 3), stride=(2, 2), padding=(0, 0)),
nn.BatchNorm2d(512),
nn.LeakyReLU(),
nn.AdaptiveAvgPool2d((6, 6))
)
self.out_layer = nn.Sequential(
nn.Linear(512 * 6 * 6, 1024),
nn.LeakyReLU(negative_slope=0.2, inplace=True),
nn.Linear(1024, 1),
nn.Sigmoid()
)
def forward(self, x):
result = self.hidden(x)
# print(result.shape)
result = result.reshape(result.shape[0], -1)
out = self.out_layer(result)
return out
SRGAN模型的生成器与判别器的实现
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.model = SRResNet()
def forward(self, x):
'''
:param x:lr_img
:return:
'''
return self.model(x)
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.hidden = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=64, kernel_size=(3, 3), stride=(1, 1), padding=(3 // 2, 3 // 2)),
nn.LeakyReLU(),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1)),
nn.BatchNorm2d(64),
nn.LeakyReLU(),
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=(3, 3), stride=(1, 1), padding=(0, 0)),
nn.BatchNorm2d(128),
nn.LeakyReLU(),
nn.Conv2d(in_channels=128, out_channels=128, kernel_size=(3, 3), stride=(2, 2), padding=(0, 0)),
nn.BatchNorm2d(128),
nn.LeakyReLU(),
nn.Conv2d(in_channels=128, out_channels=256, kernel_size=(3, 3), stride=(1, 1), padding=(0, 0)),
nn.BatchNorm2d(256),
nn.LeakyReLU(),
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=(3, 3), stride=(2, 2), padding=(0, 0)),
nn.BatchNorm2d(256),
nn.LeakyReLU(),
nn.Conv2d(in_channels=256, out_channels=512, kernel_size=(3, 3), stride=(1, 1), padding=(0, 0)),
nn.BatchNorm2d(512),
nn.LeakyReLU(),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=(3, 3), stride=(2, 2), padding=(0, 0)),
nn.BatchNorm2d(512),
nn.LeakyReLU(),
nn.AdaptiveAvgPool2d((6, 6))
)
self.out_layer = nn.Sequential(
nn.Linear(512 * 6 * 6, 1024),
nn.LeakyReLU(negative_slope=0.2, inplace=True),
nn.Linear(1024, 1),
nn.Sigmoid()
)
def forward(self, x):
result = self.hidden(x)
# print(result.shape)
result = result.reshape(result.shape[0], -1)
out = self.out_layer(result)
return out
```
- 针对VGG19 的层数截取
```python
class TruncatedVGG19(nn.Module):
"""
truncated VGG19网络,用于计算VGG特征空间的MSE损失
"""
def __init__(self, i, j):
"""
:参数 i: 第 i 个池化层
:参数 j: 第 j 个卷积层
"""
super(TruncatedVGG19, self).__init__()
# 加载预训练的VGG模型
vgg19 = torchvision.models.vgg19(pretrained=True)
print(vgg19)
maxpool_counter = 0
conv_count = 0
truncate_at = 0
# 迭代搜索
for layer in vgg19.features.children():
truncate_at += 1
# 统计
if isinstance(layer, nn.Conv2d):
conv_count += 1
if isinstance(layer, nn.MaxPool2d):
maxpool_counter += 1
conv_counter = 0
# 截断位置在第(i-1)个池化层之后(第 i 个池化层之前)的第 j 个卷积层
if maxpool_counter == i - 1 and conv_count == j:
break
# 检查是否满足条件
assert maxpool_counter == i - 1 and conv_count == j, "当前 i=%d 、 j=%d 不满足 VGG19 模型结构" % (
i, j)
# 截取网络
self.truncated_vgg19 = nn.Sequential(*list(vgg19.features.children())[:truncate_at + 1])
def forward(self, input):
output = self.truncated_vgg19(input) # (N, channels, _w,h)
return output
```