二、yolov5原理与源码学习
提示:本专栏文章仅仅是个人学习记录过程,如有错误,欢迎评论!
文章目录
-
前言
-
一、detect.py的学习
-
1. 目录的创建过程
-
2. GPU的设置过程
-
3. 数据的加载过程
-
4. 后处理NMS过程
-
5. 推理结果解析过程
-
-
二、train.py的学习
-
1. parse_model过程
-
2. create_dataset过程
-
-
总结
前言
首先通过上一篇中提供的百度云链接下载yolov5-5.0的源码文件,这里使用的测试数据是mytest_video下的person.mp4,下面对推理过程和训练过程中的重点代码利用vscode进行逐行debug。
一、detect.py学习
对detect.py的详细解析可通过下载的源码文件自行查看。下面重点对推理过程中的以下五部分的实现代码进行深入学习。:
1. 目录的创建过程
save_dir = Path(increment_path(Path(opt.project) / opt.name, exist_ok=opt.exist_ok))已知在运行detect.py时每次会将结果保存在runs/detect/expxx中(这里的expxx代表exp或exp1,exp2,exp3,...),该行代码的作用便是每次创建expxx,用于保存测试结果。通过传入exist_ok=True可以将每次的测试结果都保存在runs/detect/exp中。如果传入exist_ok=False,第一次会生成runs/detect/exp目录,第二次运行detect.py会生成runs/detect/exp2目录,第三次运行detect.py会生成runs/detect/exp3目录,依次类推。参数sep采用默认就行。
进入increment_path函数内部通过打印每一步的结果查看具体实现过程。
def increment_path(path, exist_ok=True, sep=''):
# Increment path, i.e. runs/exp --> runs/exp{sep}0, runs/exp{sep}1 etc.
path = Path(path) # 第一次:runs/detect/exp
# 如果runs/detect/exp这个路径已经存在,并且使用这个路径作为测试结果的保存路径(exist_ok=True)则直接返回该路径
# 如果runs/detect/exp这个路径不存在,则直接返回该路径
if (path.exists() and exist_ok) or (not path.exists()):
return str(path)
# 如果runs/detect/exp这个路径存在,但不使用该路径保存测试结果(exist_ok=False)
else:
# dirs = glob.glob(f"{path}{sep}*") # similar paths
# matches = [re.search(rf"%s{sep}(\d+)" % path.stem, d) for d in dirs]
# i = [int(m.groups()[0]) for m in matches if m] # indices
dirs = glob.glob(f"{path}{sep}*") # 所有目录的列表,如只有一个时是['runs/detect/exp'],有两个时是['runs/detect/exp', 'runs/detect/exp2']
print(dirs) # ['runs/detect/exp']
matches = []
for d in dirs:
matches.append(re.search(rf"%s{sep}(\d+)" % path.stem, d)) # 匹配exp后面至少跟一个数字的路径,如exp2, 没有匹配到的为None
i = []
for m in matches:
if m:
# print(m.groups())
i.append(int(m.groups()[0])) # 取exp后面紧跟的数字,如exp2中的2,其中m.groups()[0] == m.group(1)
n = max(i) + 1 if i else 2 # 如果i为空,即当前只有exp,则n=2,否则取i中最大的数字并加1为新的数字编号
return f"{path}{sep}{n}" # update path主要用到python中re模块中的se arch方法和groups方法,其用法自行百度。
2. GPU的设置过程
device = select_device(opt.device)可以选择单卡或多卡。进入select_device函数内部通过打印每一步的结果查看具体实现过程。
def select_device(device='', batch_size=None):
# device = 'cpu' or '0' or '0,1,2,3'
s = f'YOLOv5 {git_describe() or date_modified()} torch {torch.__version__} ' # string
cpu = device.lower() == 'cpu' # 判断传入的device是不是cpu,这里加了一层保护,即先将device转为小写
if cpu: # 如果是cpu,设置os.environ['CUDA_VISIBLE_DEVICES'] = '-1'从而禁用GPU
os.environ['CUDA_VISIBLE_DEVICES'] = '-1' # force torch.cuda.is_available() = False
elif device: # non-cpu device requested
os.environ['CUDA_VISIBLE_DEVICES'] = device # set environment variable, python环境只能检测到这里设置的gpu,其它gpu”不可见“
assert torch.cuda.is_available(), f'CUDA unavailable, invalid device {device} requested' # check availability
# 判断gpu是否可用(如果传入的device='',即既不是cpu也不是gpu的情况)
cuda = not cpu and torch.cuda.is_available()
if cuda:
n = torch.cuda.device_count() # 显卡的数量
if n > 1 and batch_size: # check that batch_size is compatible with device_count,如果显卡数量大于1且bach_size不为空/None,bach_size要求是显卡的整数倍
assert batch_size % n == 0, f'batch-size {batch_size} not multiple of GPU count {n}'
space = ' ' * len(s)
for i, d in enumerate(device.split(',') if device else range(n)):
p = torch.cuda.get_device_properties(i) # 获取第i块显卡的描述属性(名称、现存)
s += f"{'' if i == 0 else space}CUDA:{d} ({p.name}, {p.total_memory / 1024 ** 2}MB)\n" # bytes to MB
else:
s += 'CPU\n'
# 打印日志(如果是win系统,需要对打印的字符串进行编码解码)
logger.info(s.encode().decode('ascii', 'ignore') if platform.system() == 'Windows' else s) # emoji-safe
return torch.device('cuda:0' if cuda else 'cpu') # torch.device代表将torch.Tensor分配到的设备的对象大致设置流程:
步骤1:判断是cpu或gpu,设置os.environ['CUDA_VISIBLE_DEVICES'];
步骤2:判断cuda是否可用,如果可用,判断bach_size是否是gpu数目的整数倍,并打印每块gpu的信息(显卡名称,显存);
步骤3:return torch.device('cuda:0' if cuda else 'cpu')
其中,调用了git_describe和date_modified函数,前者主要是利用git生成版本号,后者是获取可读文件的修改日期。
def git_describe(path=Path(__file__).parent): # path must be a directory
# return human-readable git description, i.e. v5.0-5-g3e25f1e https://git-scm.com/docs/git-describe
s = f'git -C {path} describe --tags --long --always' # 利用git生成版本号,其中的path是当前py文件上一级目录的绝对路径
try:
return subprocess.check_output(s, shell=True, stderr=subprocess.STDOUT).decode()[:-1] # 如果returncode不为0,则举出错误subprocess.CalledProcessError
except subprocess.CalledProcessError as e:
return '' # not a git repositorydef date_modified(path=__file__): # path为当前py文件的绝对路径
# return human-readable file modification date, i.e. '2021-3-26'
t = datetime.datetime.fromtimestamp(Path(path).stat().st_mtime)
return f'{t.year}-{t.month}-{t.day}'对于步骤3中最后的返回结果:
return torch.device('cuda:0' if cuda else 'cpu')如果传入device='0, 1',,即采用第1块显卡和第2块显卡,但返回结果中却只是返回了第0号gpu这里不清楚。因为自己只有一块卡,也没有验证。
3. 数据的加载过程
dataset = LoadImages(source, img_size=imgsz, stride=stride)这里由于自己用的视频测试,所以进入LoadImages类中的构造函数__init__中,通过打印每一步的结果查看具体实现过程。
class LoadImages: # for inference
def __init__(self, path, img_size=640, stride=32): # self是LoadImages object, path是测试视频路径(相对路径)
p = str(Path(path).absolute()) # 将测试视频路径转为绝对路径
if '*' in p:
files = sorted(glob.glob(p, recursive=True)) # glob
elif os.path.isdir(p):
files = sorted(glob.glob(os.path.join(p, '*.*'))) # dir
elif os.path.isfile(p): # 自己传入的mp4文件类型选择这个
files = [p] # 将测试视频存入列表中
else:
raise Exception(f'ERROR: {p} does not exist')
images = [x for x in files if x.split('.')[-1].lower() in img_formats] # 通过后缀判断是图片文件
videos = [x for x in files if x.split('.')[-1].lower() in vid_formats] # 通过后缀判断是视频文件
ni, nv = len(images), len(videos) # 图片文件和视频文件的数量
self.img_size = img_size # 640
self.stride = stride # 32
self.files = images + videos # 组合图片文件和视频文件(自己测试时只传入了1个测试视频)
self.nf = ni + nv # number of files
self.video_flag = [False] * ni + [True] * nv # 设置区分图片还是视频的flag
self.mode = 'image' # 初始化mode
if any(videos): # 如果videos不为空,即有视频文件,调用new_video函数对第一个视频文件进行初始化(初始化帧、cap、统计总帧数)
self.new_video(videos[0]) # new video
else:
self.cap = None # 如果没有视频文件,初始化cap为None
# 确认有测试文件(图片+视频)
assert self.nf > 0, f'No images or videos found in {p}. ' \
f'Supported formats are:\nimages: {img_formats}\nvideos: {vid_formats}'
def __iter__(self): # self是LoadImages object
self.count = 0 # 如果是图片,统计已读取的测试图片的数量,如果是视频,统计已读取的视频的数目(不是帧数)
return self
def __next__(self): # self是 LoadImages object
if self.count == self.nf: # 最后一次迭代的条件
raise StopIteration
path = self.files[self.count] # 取第count个文件(图片或视频)
if self.video_flag[self.count]: # 如果第count个文件是视频
# Read video
self.mode = 'video' # 设置mode
ret_val, img0 = self.cap.read() # 读取帧, cap在构造函数中已经完成初始化
if not ret_val: # 如果视频读取结束
self.count += 1 # 读取视频文件时,统计视频文件的数目(这里区分帧数的统计)
self.cap.release() # 释放掉cap
if self.count == self.nf: # last video
raise StopIteration
else:
path = self.files[self.count]
self.new_video(path)
ret_val, img0 = self.cap.read()
self.frame += 1 # 统计帧数
print(f'video {self.count + 1}/{self.nf} ({self.frame}/{self.nframes}) {path}: ', end='')
else:
# Read image
self.count += 1 # 读取图片文件时,统计图片数量
img0 = cv2.imread(path) # BGR
assert img0 is not None, 'Image Not Found ' + path
print(f'image {self.count}/{self.nf} {path}: ', end='')
# Padded resize ,自适应图片缩放与填充, 参考https://zhuanlan.zhihu.com/p/172121380中
img = letterbox(img0, self.img_size, stride=self.stride)[0] # (1080, 1920, 3) -> (384, 640, 3)
# Convert
img = img[:, :, ::-1].transpose(2, 0, 1) # img[:, :, ::-1]是实现BGR to RGB; .transpose(2, 0, 1)是实现(H, W, C) -> (C, H, W)
img = np.ascontiguousarray(img) # 提高处理效率用的
# 返回测试视频(绝对路径),读取的视频帧(letterbox处理后的),读取的视频帧(未处理的),cap
return path, img, img0, self.cap
def new_video(self, path): # path为视频文件(绝对路径)
self.frame = 0 # 初始化帧数
self.cap = cv2.VideoCapture(path) # 初始化cap
self.nframes = int(self.cap.get(cv2.CAP_PROP_FRAME_COUNT)) # 统计视频文件的总帧数
# __len__的用法参考 https://blog.csdn.net/qq_38883271/article/details/96439208
def __len__(self):
return self.nf # number of files
其中,
(1)LoadImages类中实现了__iter()__ 和 __next()__方法,因此LoadImages对象dataset是个迭代器,参考python魔法方法__iter__() 和 __next__() - 知乎。也实现了__len__魔法方法,参考python的__len__()方法_Legolas~的博客-CSDN博客_len()。
(2)在__next__中调用了letterbox函数,其对图像进行了自适应缩放和填充。这部分理论参考:深入浅出Yolo系列之Yolov5核心基础知识完整讲解 - 知乎中的讲解。
img = letterbox(img0, self.img_size, stride=self.stride)[0]进入letterbox函数中,通过打印每一步的结果查看具体实现过程。
def letterbox(img, new_shape=(640, 640), color=(114, 114, 114), auto=True, scaleFill=False, scaleup=True, stride=32):
# Resize and pad image while meeting stride-multiple constraints
shape = img.shape[:2] # current shape [height, width]
if isinstance(new_shape, int):
new_shape = (new_shape, new_shape) # 640 -> (640, 640)
# Scale ratio (new / old) 计算缩放比例,取小的缩放系数
r = min(new_shape[0] / shape[0], new_shape[1] / shape[1])
if not scaleup: # only scale down, do not scale up (for better test mAP),一般采用的是上下都填充,所以这里scaleup=rue
r = min(r, 1.0)
# Compute padding
ratio = r, r # width, height ratios
new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r)) # 原图宽、高乘以缩放系数后的宽高尺寸,维度顺序: (w,H)
dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - new_unpad[1] # wh padding, 宽高上的尺寸差
if auto: # minimum rectangle
# 为什么np.mod函数的后面用32?因为Yolov5的网络经过5次下采样,而2的5次方,等于32。所以至少要去掉32的倍数,再进行取余
dw, dh = np.mod(dw, stride), np.mod(dh, stride) # wh padding
elif scaleFill: # stretch
dw, dh = 0.0, 0.0
new_unpad = (new_shape[1], new_shape[0])
ratio = new_shape[1] / shape[1], new_shape[0] / shape[0] # width, height ratios
dw /= 2 # divide padding into 2 sides,再除以2,即得到图片左右两端和上下两端需要填充的数值
dh /= 2
if shape[::-1] != new_unpad: # resize, shape[::-1]是将维度顺序取反,(1080, 1920) -> (1920, 1080)
img = cv2.resize(img, new_unpad, interpolation=cv2.INTER_LINEAR)
top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
img = cv2.copyMakeBorder(img, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color) # add border, 上、下、左、右填充灰色
return img, ratio, (dw, dh)(3)使用dataset对象的过程如下:
for path, img, im0s, vid_cap in dataset: # LoadImages object
# for循环遍历的实现原理就是,先通过调用__iter__()获得迭代对象的迭代器,然后对迭代器不断调用__next__()取得值,
# 再处理掉最后一次迭代抛出的 StopIteration 异常
img = torch.from_numpy(img).to(device)
img = img.half() if half else img.float() # uint8 to torch.fp16/32
img /= 255.0 # 0 - 255 to 0.0 - 1.0
if img.ndimension() == 3:
img = img.unsqueeze(0)
# Inference
t1 = time_synchronized() # pytorch中测试程序运行时长的正确方法
pred = model(img, augment=opt.augment)[0] # [0]固定解析方法, pred的shape是(1, num_boxes, 5+num_class)
# Apply NMS
pred = non_max_suppression(pred, opt.conf_thres, opt.iou_thres, classes=opt.classes, agnostic=opt.agnostic_nms)
t2 = time_synchronized()
# Apply Classifier
if classify:
pred = apply_classifier(pred, modelc, img, im0s) # 学习yolov5的输出如何适配resnet的输入格式??》
# Process detections
for i, det in enumerate(pred): # detections per image
if webcam: # batch_size >= 1
p, s, im0, frame = path[i], '%g: ' % i, im0s[i].copy(), dataset.count
else:
p, s, im0, frame = path, '', im0s, getattr(dataset, 'frame', 0)
p = Path(p) # str to Path
save_path = str(save_dir / p.name)
txt_path = str(save_dir / 'labels' / p.stem) + ('' if dataset.mode == 'image' else f'_{frame}') # img.txt
s += '%gx%g ' % img.shape[2:] # print string '384x640 '
gn = torch.tensor(im0.shape)[[1, 0, 1, 0]] # normalization gain whwh, tensor([1920, 1080, 1920, 1080])
if len(det):
# Rescale boxes from img_size to im0 size
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], im0.shape).round()
# Print results
for c in det[:, -1].unique():
n = (det[:, -1] == c).sum() # detections per class
s += f"{n} {names[int(c)]}{'s' * (n > 1)}, " # add to string
# Write results
for *xyxy, conf, cls in reversed(det):
if save_txt: # Write to file
xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
line = (cls, *xywh, conf) if opt.save_conf else (cls, *xywh) # label format
with open(txt_path + '.txt', 'a') as f:
f.write(('%g ' * len(line)).rstrip() % line + '\n')
if save_img or view_img: # Add bbox to image
label = f'{names[int(cls)]} {conf:.2f}'
plot_one_box(xyxy, im0, label=label, color=colors[int(cls)], line_thickness=3)
# Print time (inference + NMS)
print(f'{s}Done. ({t2 - t1:.3f}s)')
# Stream results
if view_img:
cv2.imshow(str(p), im0)
cv2.waitKey(1) # 1 millisecond
# Save results (image with detections)
if save_img:
if dataset.mode == 'image':
cv2.imwrite(save_path, im0)
else: # 'video' or 'stream'
if vid_path != save_path: # new video
vid_path = save_path
if isinstance(vid_writer, cv2.VideoWriter):
vid_writer.release() # release previous video writer
if vid_cap: # video
fps = vid_cap.get(cv2.CAP_PROP_FPS)
w = int(vid_cap.get(cv2.CAP_PROP_FRAME_WIDTH))
h = int(vid_cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
else: # stream
fps, w, h = 30, im0.shape[1], im0.shape[0]
save_path += '.mp4'
vid_writer = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc(*'mp4v'), fps, (w, h))
vid_writer.write(im0)
在执行 for循环时注意函数的调用过程。
for path, img, im0s, vid_cap in dataset:第一次执行for循环首先会进入__iter__函数内部,紧接着进入__next__函数内部,后面每次执行for循环都直接进入__next__函数内部。
(4)可以看到在将图像送入模型进行推理前,对图像的预处理包括letterbox、BGR to RGB、通道调整(H, W, C) -> (C, H, W)(均在__next__中实现)、图像归一化[0, 255] -> [0, 1]。
4. 后处理NMS过程
模型推理结果pred的shape是(1, num_boxes, 5+num_class),然后进行非极大值抑制,对其中confidence较低的box和IOU较大的box进行过滤。
pred = non_max_suppression(pred, opt.conf_thres, opt.iou_thres, classes=opt.classes, agnostic=opt.agnostic_nms)进入non_max_suppression函数内部查看具体实现过程。
def non_max_suppression(prediction, conf_thres=0.25, iou_thres=0.45, classes=None, agnostic=False, multi_label=False,
labels=()):
"""
description:
Runs Non-Maximum Suppression (NMS) on inference results
param:
prediction: inference results, e.g. ([1, 15120, 85], 其中第一维的值1表示推理了1张图像,第二维的值15120表表示在这1张图像上共有15120个检测框,
第三维度的值85具体为:前4位值表示检测框的xywh, 第5位表示cls_conf,后面的80位值分别为每一类别的obj_conf
conf_thres: 置信度阈值,用于过滤掉conf较低的检测框
iou_thres: iou阈值,用于过滤掉冗余的检测框
Returns:
list of detections, on (n,6) tensor per image [xyxy, conf, cls]
"""
nc = prediction.shape[2] - 5 # number of classes
xc = prediction[..., 4] > conf_thres # candidates, 就是个掩膜,用于过滤掉cls_conf<=conf_thres的检测框
# Settings
min_wh, max_wh = 2, 4096 # (pixels) minimum and maximum box width and height,用于定义c的常量
max_det = 300 # maximum number of detections per image ,nms之后最多保留的框数量
max_nms = 30000 # maximum number of boxes into torchvision.ops.nms(), 送入nms()前最多保留的框数量
time_limit = 10.0 # seconds to quit after
redundant = True # require redundant detections
multi_label &= nc > 1 # multiple labels per box (adds 0.5ms/img)
merge = False # use merge-NMS
t = time.time()
output = [torch.zeros((0, 6), device=prediction.device)] * prediction.shape[0] # 初始化返回结果, prediction.shape[0]在这里表示推理了几张图
# 遍历推理结果中的每张图像和该张图像上的检测结果
for xi, x in enumerate(prediction): # image index 图像索引, image inference 图像上的检测结果
# Apply constraints
# x[((x[..., 2:4] < min_wh) | (x[..., 2:4] > max_wh)).any(1), 4] = 0 # width-height
print(xc[xi])
x = x[xc[xi]] # confidence,过滤掉conf<=conf_thres的检测框
# Cat apriori labels if autolabelling
if labels and len(labels[xi]):
l = labels[xi]
v = torch.zeros((len(l), nc + 5), device=x.device)
v[:, :4] = l[:, 1:5] # box
v[:, 4] = 1.0 # conf
v[range(len(l)), l[:, 0].long() + 5] = 1.0 # cls
x = torch.cat((x, v), 0)
# If none remain process next image 如果当前图像根据置信度过滤之后没有检测框了,则处理下一张图像的检测结果
if not x.shape[0]:
continue
# Compute conf
x[:, 5:] *= x[:, 4:5] # conf = obj_conf * cls_conf
# Box (center x, center y, width, height) to (x1, y1, x2, y2)
box = xywh2xyxy(x[:, :4])
# Detections matrix nx6 (xyxy, conf, cls)
if multi_label:
i, j = (x[:, 5:] > conf_thres).nonzero(as_tuple=False).T
x = torch.cat((box[i], x[i, j + 5, None], j[:, None].float()), 1)
else: # best class only
conf, j = x[:, 5:].max(1, keepdim=True) # dim=1寻找每一行的最大值, j为claas_id
x = torch.cat((box, conf, j.float()), 1)[conf.view(-1) > conf_thres] # [conf.view(-1) > conf_thres]为条件 ,这里是根据conf过滤不是cls_conf
# Filter by class
if classes is not None:
x = x[(x[:, 5:6] == torch.tensor(classes, device=x.device)).any(1)]
# Apply finite constraint
# if not torch.isfinite(x).all():
# x = x[torch.isfinite(x).all(1)]
# Check shape
n = x.shape[0] # number of boxes
if not n: # no boxes, 如果没有检测框,处理下一张图像的检测结果
continue
elif n > max_nms: # excess boxes, 如果检测框的数量超过30000,根据conf进行排序(递减),然后取前30000个框
x = x[x[:, 4].argsort(descending=True)[:max_nms]] # sort by confidence
# Batched NMS
c = x[:, 5:6] * (0 if agnostic else max_wh) # classes ,定义c用于对boxes进行处理,使得不同类别之间的检测框相距较远
boxes, scores = x[:, :4] + c, x[:, 4] # boxes (offset by class), scores, 这里的scores是cls_conf
i = torchvision.ops.nms(boxes, scores, iou_thres) # NMS,返回NMS后的检测框的索引
if i.shape[0] > max_det: # limit detections, 如果NMS之后检测框的数量大于300,只保留前300个
i = i[:max_det]
if merge and (1 < n < 3E3): # Merge NMS (boxes merged using weighted mean)
# update boxes as boxes(i,4) = weights(i,n) * boxes(n,4)
iou = box_iou(boxes[i], boxes) > iou_thres # iou matrix
weights = iou * scores[None] # box weights
x[i, :4] = torch.mm(weights, x[:, :4]).float() / weights.sum(1, keepdim=True) # merged boxes
if redundant:
i = i[iou.sum(1) > 1] # require redundancy
output[xi] = x[i] # 更新返回变量
if (time.time() - t) > time_limit:
print(f'WARNING: NMS time limit {time_limit}s exceeded')
break # time limit exceeded
return output其中真正的nms是通过torchvision.ops.nms(boxes, scores, iou_thres)实现的,其它的都是yolov5中对nms增加的额外的一些处理,拓展性很强,但很多其实在使用中使用默认选项没怎么用到,包括参数classes=None, agnostic=False, multi_label=False, labels=() 采用默认值即可。
二、train.py学习
对train.py的详细注释可通过下载的源码文件查看。下面重点对训练过程中模型的解析部分的实现代码进行深入学习。
1、模型解析
model = Model(opt.cfg or ckpt['model'].yaml, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) 以yolov5s模型的解析为例。查看如何从传入的网络配置文件中构建网络结构。这里传入的是yolov5s_mydata.yaml。对yolov5s_mydata.yaml文件的初步认识(与标准的yolov5s.yaml相比,只是将其中的类别数由80改为了自己的实际类别2)。

结合下面图1的框图可以看到用于构建网络结构的层共有25层(backbone+head),这里有些层的名称与图中的名称不同而已,但它们是对应的。其中参数number代表的仅仅是其中某个组件默认重复的次数,如[-1, 3, c3, [128]]中的3代表了在CSP1_X层中残差组件Res_unit默认重复3次,但实际的重复次数是通过下面这行代码(见parse_model.py)计算的:
'''
# 网络用n*gd控制模块的深度缩放,比如对于yolo5s来讲,gd为0.33,也就是把默认的深度缩放为原来的1/3。
# 深度在这里指的是类似CSP这种模块的重复迭代次数。而宽度一般我们指的是特征图的channel
'''
n = max(round(n * gd), 1) if n > 1 else n # depth gain进入yolo.py中查看Model类的具体实现过程。
class Model(nn.Module): # nn.Module的介绍参考https://zhuanlan.zhihu.com/p/34616199
def __init__(self, cfg='yolov5s.yaml', ch=3, nc=None, anchors=None): # model, input channels, number of classes
super(Model, self).__init__()
# 这里直接传入的cfg是个yaml文件,所以直接进入else里面
if isinstance(cfg, dict):
self.yaml = cfg # model dict
else: # is *.yaml
import yaml # for torch hub
self.yaml_file = Path(cfg).name # './models/yolov5s.yaml' -> 'yolov5s.yaml'
# 使用yaml.load解析yaml文件,解析后是一个dict形式
with open(cfg) as f:
self.yaml = yaml.load(f, Loader=yaml.SafeLoader) # model dict
# Define model
# 从yaml解析结果中获取ch,查看yaml文件可知在yaml文件中没有ch字段,所以会利用传入的ch创建该键值对 'ch':3
ch = self.yaml['ch'] = self.yaml.get('ch', ch) # input channels ,输入图像的channel,为3
# 如果给参数nc传值且和yaml中的nc值不同,会以输入参数更新配置文件中的类别数。这里并没有传值,所以执行if后面语句
if nc and nc != self.yaml['nc']:
logger.info(f"Overriding model.yaml nc={self.yaml['nc']} with nc={nc}")
self.yaml['nc'] = nc # override yaml value
# 如果给参数anchors传值了(自适应确定的新anchors),更新配置文件中默认的anchors。这里并没有给anchors传值,所以执行if后面语句
if anchors:
logger.info(f'Overriding model.yaml anchors with anchors={anchors}')
self.yaml['anchors'] = round(anchors) # override yaml value
# 从模型配置文件中解析模型
self.model, self.save = parse_model(deepcopy(self.yaml), ch=[ch]) # model, savelist
self.names = [str(i) for i in range(self.yaml['nc'])] # default names, 这里是索引,如果有n类,则names=['0', '1', ...'n-1']
# print([x.shape for x in self.forward(torch.zeros(1, ch, 64, 64))])
# Build strides, anchors
m = self.model[-1] # 提取了model中的Detect模块
if isinstance(m, Detect):
s = 256
# 获取下采样步长 stride = [256/32, 256/16, 256/8] -> tensor([ 8., 16., 32.])
m.stride = torch.tensor([s / x.shape[-2] for x in self.forward(torch.zeros(1, ch, s, s))]) # forward返回的是[shape(1,3,32,32,7)的feature map, shape(1,3,16,16,7)的feature map, shape(1,3,8,8,7)的feature map]
#
m.anchors /= m.stride.view(-1, 1, 1) # stride: [ 8., 16., 32.]->[[[8],[16],[32]]], anchors shape:[3, 3, 2]
check_anchor_order(m) # 保证anchor顺序与stride顺序相同
self.stride = m.stride # 这里的self就是model
self._initialize_biases() # only run once
# print('Strides: %s' % m.stride.tolist())
# Init weights, biases
initialize_weights(self) # 初始化Detect()层的bias
self.info()
logger.info('')可以看到,在构造函数中大致做了这么几件事:
(1)解析yolov5s_mydata.yaml并添加ch字段(输入图像通道数);
(2)从yolov5s_mydata.yaml中解析出网络模型mode;
(3)从模型mode中提取最后的Detect层,利用该层计算stride, anchors,初始化该层的bias;
(4)初始化整个model( Conv2d, BatchNorm2d, activation)。
其中调用了forward函数,进入forward函数查看:
def forward(self, x, augment=False, profile=False):
if augment: # 推理过程中augment默然False,直接进入else里面
img_size = x.shape[-2:] # height, width
s = [1, 0.83, 0.67] # scales
f = [None, 3, None] # flips (2-ud, 3-lr)
y = [] # outputs
for si, fi in zip(s, f):
xi = scale_img(x.flip(fi) if fi else x, si, gs=int(self.stride.max()))
yi = self.forward_once(xi)[0] # forward
# cv2.imwrite(f'img_{si}.jpg', 255 * xi[0].cpu().numpy().transpose((1, 2, 0))[:, :, ::-1]) # save
yi[..., :4] /= si # de-scale
if fi == 2:
yi[..., 1] = img_size[0] - yi[..., 1] # de-flip ud
elif fi == 3:
yi[..., 0] = img_size[1] - yi[..., 0] # de-flip lr
y.append(yi)
return torch.cat(y, 1), None # augmented inference, train
else:
return self.forward_once(x, profile) # single-scale inference, train1)forward的参数x为创建的shape为(1,3,256,256)的空图,参数augment表示在训练过程中是否使用图像增强处理,默认False,所以暂时不关注这块,参数profile是用于打印信息时的显示格式控制的,默认False,所以暂时也不关注。程序直接进入forward_once函数中。
def forward_once(self, x, profile=False): # x是创建的一张shape为[1,3,256,256]的空图, profile默然False
y, dt = [], [] # outputs
for m in self.model:
print(m)
if m.f != -1: # if not from previous layer ,如 concat层中出现 f=[-1, 6],表示取上一层的output和第6层的output作为当前层的输入x
x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # 取当前层在进行forward时的输入x,一般都是上一层的输出作为当前层的输入,但concat层和Detect层的输入却是前面某几层的输出
if profile: # 默然False,直接执行if后面的语句
o = thop.profile(m, inputs=(x,), verbose=False)[0] / 1E9 * 2 if thop else 0 # FLOPS
t = time_synchronized()
for _ in range(10):
_ = m(x)
dt.append((time_synchronized() - t) * 100)
print('%10.1f%10.0f%10.1fms %-40s' % (o, m.np, dt[-1], m.type))
# save=[4,6,10,14,17,20,23]表示self.model中第4,第6,第7,...第23层的index(第0层是Focus)
x = m(x) # 当前层的forward
y.append(x if m.i in self.save else None) # save output,已知save=[4, 6, 10, 14, 17, 20, 23],表示需要将这些层的output保存到y中,后面会作为concat和Detect层的输入使用
if profile: # profile默认False,直接return x,最后返回的x是输入x在经过model的forward过程的output,是个含有三个feature map 的list,[shape(1,3,32,32,7), shape(1,3,16,16,7), shape(1,3,8,8,7)]
print('%.1fms total' % sum(dt))
return x 2)函数forward_once中model会对输入的图像x进行forward,即前向推理,最后返回推理结果,return 的x 是个list,其有三个元素,每个元素是个feature map, 三个feature map的shape依次为:(1,3,32,32,7), (1,3,16,16,7), (1,3,8,8,7)。其中的7跟自己的类别数目相关,计算方式为5+num_class,5指的是box的xywh和obj conf, 剩下的是cls prob(即每一类的概率)。其中的3与分配的anchor的数目相同。32、16、8均为下采样的stride。
def _initialize_biases(self, cf=None): # initialize biases into Detect(), cf is class frequency
# https://arxiv.org/abs/1708.02002 section 3.3
# cf = torch.bincount(torch.tensor(np.concatenate(dataset.labels, 0)[:, 0]).long(), minlength=nc) + 1.
m = self.model[-1] # Detect() module包含三个卷积层:Conv2d(128,21), Conv2d(256,21), Conv2d(512,21),这里的输出channel=21与自己实际的类别相关,自己测试只有2类
for mi, s in zip(m.m, m.stride): # from
b = mi.bias.view(m.na, -1) # shape: conv.bias(21) to (3,7)
# b.data[:, 0:4],即前4位值代表预测框box的xywh, b.data[:, 4] 即第5位为obj conf, b.data[:, 5:7]即第5位与第6位分类为两个类别的prob
b.data[:, 4] += math.log(8 / (640 / s) ** 2) # obj (8 objects per 640 image) ## obj conf的计算方法
b.data[:, 5:] += math.log(0.6 / (m.nc - 0.99)) if cf is None else torch.log(cf / cf.sum()) # cls, ## cls prob的计算方法
mi.bias = torch.nn.Parameter(b.view(-1), requires_grad=True)3)_initialize_biases()完成对model中最后一层Detect层的初始化,具体初始化参数bias
def initialize_weights(model):
for m in model.modules(): # model.modules()的遍历方法参考https://www.zhihu.com/search?type=content&q=pytorch%20%20model.modules()
t = type(m)
if t is nn.Conv2d:
pass # nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif t is nn.BatchNorm2d:
m.eps = 1e-3
m.momentum = 0.03
elif t in [nn.Hardswish, nn.LeakyReLU, nn.ReLU, nn.ReLU6]:
m.inplace = True4) initialize_weights完成对整个model的初始化,具体初始化其中的Conv2d层、BatchNorm2d层和激活函数层。
这里先贴出网上看到的一张模型结构框图(出处),然后进入parse_model函数对照图1理解模型的构建过程。
self.model, self.save = parse_model(deepcopy(self.yaml), ch=[ch]) 这里传入的参数self.yaml为对yolov5s_mydata.yaml解析后的dict形式,ch=[3]。
返回参数model和save,其中 save=[4, 6, 10, 14, 17, 20, 23],对照下面的模型结构框图,可知在模型的forward过程中模型的第4层、6层、10层、14层、17层、20层、23层的输出是需要作为别的层的输入的。所以这里先用save把这些层的索引保存起来,在model 的forward中会用到。
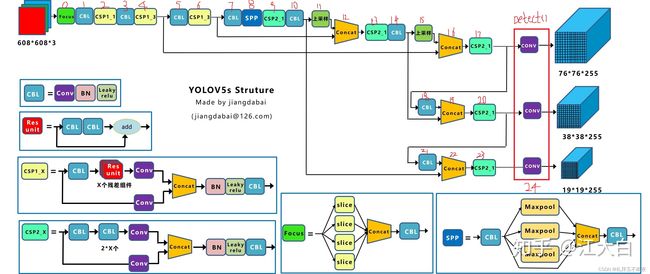
图1 yolov5s net
def parse_model(d, ch): # model_dict, input_channels(3)
logger.info('\n%3s%18s%3s%10s %-40s%-30s' % ('', 'from', 'n', 'params', 'module', 'arguments')) # 打印信息,进行显示格式控制
anchors, nc, gd, gw = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple']
na = (len(anchors[0]) // 2) if isinstance(anchors, list) else anchors # number of anchors
no = na * (nc + 5) # number of outputs = anchors * (classes + 5) 根据anchor数量推断的输出维度,输出维度=anchor数量*(类别数量+置信度+xywh四个回归坐标)
layers, save, c2 = [], [], ch[-1] # layers, savelist, ch out
'''
# 开始迭代循环backbone与head的配置。f,n,m,args分别代表着从哪层开始,模块的默认深度,模块的类型和模块的参数
'''
for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, args
print(i, (f, n, m, args))
# debug = eval(m) # 假设m='Focus', debug=, 表示Focus的是定义在models下common.py中的类,可以在common.py中查看
m = eval(m) if isinstance(m, str) else m # eval strings
# print(m)
for j, a in enumerate(args):
try:
args[j] = eval(a) if isinstance(a, str) else a # eval strings
except:
pass
'''
# 网络用n*gd控制模块的深度缩放,比如对于yolo5s来讲,gd为0.33,也就是把默认的深度缩放为原来的1/3。
# 深度在这里指的是类似CSP这种模块的重复迭代次数。而宽度一般我们指的是特征图的channel
'''
n = max(round(n * gd), 1) if n > 1 else n # depth gain
'''
# 对于以下的这几种类型的模块,ch是一个用来保存之前所有的模块输出的channle,ch[-1]代表着上一个模块的输出通道。args[0]是默认的输出通道
'''
if m in [Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, DWConv, MixConv2d, Focus, CrossConv, BottleneckCSP,
C3, C3TR]: # 注意列表中的值不是字符串,定义都在common.py中,所以上面需要eval(m)
c1, c2 = ch[f], args[0] # c1代表上一模块实际输出的channel,,c2代表当前模块默认的输出channel
if c2 != no: # if not output ???》c2如果表示当前层输出的channel,为什么要和no=anchors * (classes + 5)比较?没有关系呀》c2处理后也是!=no呀
'''
# make_divisible()函数,是为了放缩网络模块的宽度(既输出的通道数),比如对于第一个模块“Focus”,默认的输出通道是64,而yolov5s里的放缩系数是0.5,
# 所以通过以上代码变换,最终的输出通道为32。make_divisible()函数保证了输出的通道是8的倍数
'''
c2 = make_divisible(c2 * gw, 8)
'''
# 经过以下处理,args里面保存的前两个参数就是module的输入通道数、输出通道数。
# 只有 BottleneckCSP 、C3 和 C3TR 这三种module会根据深度参数n被调整该模块的重复迭加次数
'''
args = [c1, c2, *args[1:]] # 前两个参数代表上一模块的实际输出channel、当前模块的实际输出channel,(如果有)第三个参数为kernel,第四个参数为stride
if m in [BottleneckCSP, C3, C3TR]:
args.insert(2, n) # number of repeats, 在yaml配置文件中这几个模块没有重复次数参数,这里需要添加下
n = 1
# 以下是其他几种类型的Module。
# 如果是nn.BatchNorm2d则通道数保持不变。
# 如果是Concat则f是所有需要拼接层的index,则输出通道c2是所有层的channel和。
# 如果是Detect则对应检测头,这部分后面再详细讲。
# Contract和Expand目前未在模型中使用
elif m is nn.BatchNorm2d:
args = [ch[f]]
elif m is Concat:
c2 = sum([ch[x] for x in f]) # 假设f=[-1, 6],表示将当前模块的上一层模块的实际输出channel和第7个模块的实际输出channel相加,如sum([256,256])->512
elif m is Detect:
args.append([ch[x] for x in f]) # 将第17个模块、第20个模块、第23个模块的实际输出channel添加到args中
if isinstance(args[1], int): # number of anchors
args[1] = [list(range(args[1] * 2))] * len(f)
elif m is Contract:
c2 = ch[f] * args[0] ** 2
elif m is Expand:
c2 = ch[f] // args[0] ** 2
else:
c2 = ch[f]
# 这里把args里的参数用于构建了module m,然后当前模块的重复次数用参数n控制。m(*args)会执行common.py中对m的定义
m_ = nn.Sequential(*[m(*args) for _ in range(n)]) if n > 1 else m(*args) # module
# 这里做了一些输出打印,可以看到每一层module构建的编号、参数量等情况
# debug, debug1 = str(m), str(m)[8:-2] # 以Focus层为例,debug="", debug1='models.common.Focus'
t = str(m)[8:-2].replace('__main__.', '') # module type
# for x in m_.parameters(): # net.parameters的解释参考 https://zhuanlan.zhihu.com/p/119305088
# print(x, ' ', x.numel())
np = sum([x.numel() for x in m_.parameters()]) # number params
m_.i, m_.f, m_.type, m_.np = i, f, t, np # attach index, 'from' index, type, number params
logger.info('%3s%18s%3s%10.0f %-40s%-30s' % (i, f, n, np, t, args)) # print
save.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelist
# 最后把构建的模块保存到layers里,把该层的输出通道数写入ch列表里
layers.append(m_)
if i == 0: # 在ch中添加所有模块的实际输出channel,第一次添加第一个模块Focus的输出channel前将ch清空
ch = []
ch.append(c2)
# 待全部循环结束后再构建成模型。至此模型就全部构建完毕了
return nn.Sequential(*layers), sorted(save) 下面对网络结构中的25层逐层查看其实现过程(自己用的是yolov5-5.0版本,图1中不知道具体是哪个版本,二者尽管层数相同且对应,但具体每层的实现可能存在差异。)25层分以下8类,其它层均为重复层或相似层。
第1类、Focus层 :0 (-1, 1, 'Focus', [64, 3])
Focus层的输入channel为3,经过c2 = make_divisible(c2 * gw, 8)的计算实际输出通道为32。
class Focus(nn.Module):
# Focus wh information into c-space
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in=3, ch_out, kernel, stride, padding, groups
super(Focus, self).__init__()
self.conv = Conv(c1 * 4, c2, k, s, p, g, act)
# self.contract = Contract(gain=2)
def forward(self, x): # x(b,c,w,h) -> y(b,4c,w/2,h/2) 先对输入图像进行切片操作,在channel上进行拼接,然后送到Conv组件中
return self.conv(torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1))
# return self.conv(self.contract(x))在Focus层的forward中首先会对输入X进行切片操作并进行拼接,此时X的通道数变为原来的4倍,宽高变为原来的一半。然后送入Conv组件,Conv组件的实现如下:
class Conv(nn.Module):
# Standard convolution
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super(Conv, self).__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
return self.act(self.bn(self.conv(x)))Conv组件即:Conv2d-》BN-》激活函数(SiLU)
这里的Conv组件即图1中的CBL层,其中的激活函数实际为SiLU。
第2类、Conv层:1 (-1, 1, 'Conv', [128, 3, 2])
即Focus层中的Conv组件。输入channel为32,实际输出channel为64。
第3类、C3层(CSP1_1层):2 (-1, 3, 'C3', [128])
yolov5s.yaml中出现的C3具体分为图1中的CSP1_X和CSP2_X两种。通过args参数区分,其中有False的为CSP2_X,没有的为CSP1_X,args中的False参数决定了C3层中有没有残差组件Res_unit。
class C3(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super(C3, self).__init__()
c_ = int(c2 * e) # hidden channels = 32
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # act=FReLU(c2)
self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
# self.m = nn.Sequential(*[CrossConv(c_, c_, 3, 1, g, 1.0, shortcut) for _ in range(n)])
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))这里实现的CSP1_1与图1中有所不同。如图2所示。其中,Bottleneck即为Res_unit组件,与图1中结构相同。
class Bottleneck(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
super(Bottleneck, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, 3, 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
图2 C3层结构(对应图1中CSP1_X层)
第4类、SPP层:8 (-1, 1, 'SPP', [1024, [5, 9, 13]])
class SPP(nn.Module):
# Spatial pyramid pooling layer used in YOLOv3-SPP
def __init__(self, c1, c2, k=(5, 9, 13)):
super(SPP, self).__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * (len(k) + 1), c2, 1, 1)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
def forward(self, x):
x = self.cv1(x)
return self.cv2(torch.cat([x] + [m(x) for m in self.m], 1))SPP层与图1中的结构相同。
第5类、Upsample层:11 (-1, 1, 'nn.Upsample', ['None', 2, 'nearest'])
Upsample层直接使用nn.Upsample('None', 2, 'nearest')实现。经过上采样层,输出特征图的channel保持不变,但宽、高会变为原来的2倍。
第6类、Concat层:12 ([-1, 6], 1, 'Concat', [1])
通过图1可以看到,第6层和第11层的输出都指向了第12层的concat层。
elif m is Concat:
c2 = sum([ch[x] for x in f]) # 假设f=[-1, 6],表示将当前模块的上一层模块的实际输出channel和第7个模块的实际输出channel相加,如sum([256,256])->512如果是12层的Concat层,其作用是将第6层和第11层输出的channel求和,并作为下一层输入的channel。
对照图1,第16层、第19层、第22层的Concat层的功能同样是计算前面某两层输出的channel的和,并作为下一层输入的channel。因此Concat层改变的是下一层的输入的channel。
第7类、C3层(CSP2_1层):23 (-1, 3, 'C3', [1024, False])
与CSP1_X不同,在CSP2_X中尽管也有个Bottleneck组件,但它不是残差结构。CSP2_X与图1中的结构也有细微不同。实际的CSP2_X结构如图3所示。

图3 CSP2_X结构(对应图1中CSP2_X层)
第8类、Detect层:24 ([17, 20, 23], 1, 'Detect', ['nc', 'anchors'])
Detect层的结构比较简单,由三个Conv2d层构成(与图1中画的conv组件不同,这里其实是三个Conv2d层),三个Conv2d层输入的channel分别为128(第17层输出的channel), 256(第20层输出的channel), 512(第23层输出的channel)。输出的channel相同,计算方法都是(nc+5)*3,卷积层的kernel_size均为1, stride均为1。
class Detect(nn.Module):
stride = None # strides computed during build
export = False # onnx export
def __init__(self, nc=80, anchors=(), ch=()): # detection layer
super(Detect, self).__init__()
self.nc = nc # number of classes ,类别数
self.no = nc + 5 # number of outputs per anchor,每个anchor负责输出nc+5个参数
self.nl = len(anchors) # number of detection layers, Detect层有3层Conv2d
self.na = len(anchors[0]) // 2 # number of anchors, 给每层Conv2d分配3个anchor
self.grid = [torch.zeros(1)] * self.nl # init grid, 给每层Conv2d输出的特征图初始化网格数
a = torch.tensor(anchors).float().view(self.nl, -1, 2) # 将anchors reshape成[3, 3, 2]的shape
self.register_buffer('anchors', a) # shape(nl,na,2) # https://blog.csdn.net/weixin_38145317/article/details/104917218
self.register_buffer('anchor_grid', a.clone().view(self.nl, 1, -1, 1, 1, 2)) # shape(nl,1,na,1,1,2)
self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # Detect层分为3层Conv2d, 输入channel分别为128, 256, 512,输出channel为no*na, kernel_size=1
def forward(self, x): # 参数self是Detect层, 参数x是第17, 第20, 第23层输出的feature map
# x = x.copy() # for profiling
z = [] # inference output
self.training |= self.export # 或运算,这里的training取True或False在哪选择的??》training字段是继承自nn.Module的,默认True,设置model.eval()后变为False
for i in range(self.nl): # 遍历3个Conv2d层
x[i] = self.m[i](x[i]) # 将第17层输出的特征图送入第1个Conv2d, 将第20层输出的特征图送入第2个Conv2d, 将第23层输出的特征图送入第3个Conv2d
bs, _, ny, nx = x[i].shape # bs即batch_size, _代表第i层的Conv2d输出特征图的channel, ny,nx为第i层的Conv2d输出特征图的高、宽
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous() # 首先将x[i]的第2个维度分解为na*no,如[1,21, 4,4]->[1,3,7,4,4],然后调整顺序->[1,3,4,4,7],其中的3*4*4为当前特征图上预测框的数目
if not self.training: # inference, 通过函数forward_once中的x=m(x)行会进入到if中
temp = self.grid[i].shape[2:4] # self.grid[i]初始化只有1个维度,取第3和第4维shape得到的结果为[]
if self.grid[i].shape[2:4] != x[i].shape[2:4]: # 如果特征图的第3,第4维度的shape与该特征图上网格的第3,第4维度的shape不相同
# 为特征图分配网格。将高和宽为ny,nx的特征图划分为ny*nx的网格grid cell,ny*nx代表所有的网格数目
self.grid[i] = self._make_grid(nx, ny).to(x[i].device) # shape: torch.Size([1, 1, nx, ny, 2])
y = x[i].sigmoid() # 将特征图上的值映射到0~1之间,此时x[i]的shape: [bs, na, ny, nx, no] ,如[1, 3, 4, 4, 7]
y[..., 0:2] = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xy的计算方法, 最后一个维度的前两位值代表预测框的中心坐标xy
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh的计算, 最后一个维度的第3、第4位值代表预测框的宽、高
z.append(y.view(bs, -1, self.no)) # 对y进行了reshape后第2维度为这一特征图中预测框的数目,na*ny*nx=3*ny*nx, 第3维度为预测框的参数(xywh + 目标得分obj score + 每一类的概率cls prob)
# 如果self.training=False,返回元组(torch.cat(z,1), x), torch.cat(z,1)对三个Conv2d输出的特征图上的预测框进行了合并, 第二个元素是三个Conv2d输出的特征图列表
return x if self.training else (torch.cat(z, 1), x)
@staticmethod
def _make_grid(nx=20, ny=20):
yv, xv = torch.meshgrid([torch.arange(ny), torch.arange(nx)]) # ny,nx为特征图的高和宽,返回所有采样点的y坐标与所有采样点的x坐标
return torch.stack((xv, yv), 2).view((1, 1, ny, nx, 2)).float() # 合并成采样点的坐标(x, y)并reshape成(1, 1, ny, nx, 2)
在Detect层的forward过程中,其输入X为第17层,第20层, 第23层输出的feature map列表,shape分别为[1, 128, 32, 32],[1, 256, 16, 16],[1, 512, 8, 8]。X[0]会送入第一个Conv2d层中,X[1]会送入第二个Conv2d层中,X[2]会送入第三个Conv2d层中。如下所示:
X[0]: input feature map [1, 128, 32, 32] ——> Con2d(128, 21, 1, 1) ——> output feature map [1, 21, 32, 32] ——> feature map [1, 3, 32, 32, 7]
X[1]: input feature map [1, 256, 16, 16] ——> Con2d(256, 21, 1, 1) ——> output feature map [1, 21, 16, 16] ——> feature map [1, 3, 16, 16, 7]
X[2]: input feature map [1, 512,8, 8] ——> Con2d(512, 21, 1, 1) ——> output feature map [1, 21, 8, 8] ——> feature map [1, 3, 8, 8, 7]
再看下Detect层forward中inference阶段(self.training=False)的处理过程。
上面得到了三个特征图,然后对每个特征图根据尺寸划分网格,计算每个特征图上预测框的中心坐标和高宽,最后将三个特征图上的预测框合并,作为最后的推理结果返回。
最后打印出详细的网络结构如下所示:
Focus(
(conv): Conv(
(conv): Conv2d(12, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
)
Conv(
(conv): Conv2d(32, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
C3(
(cv1): Conv(
(conv): Conv2d(64, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(64, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv3): Conv(
(conv): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(m): Sequential(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(32, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(32, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
)
)
)
Conv(
(conv): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
C3(
(cv1): Conv(
(conv): Conv2d(128, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(128, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv3): Conv(
(conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(m): Sequential(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
)
(1): Bottleneck(
(cv1): Conv(
(conv): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
)
(2): Bottleneck(
(cv1): Conv(
(conv): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
)
)
)
Conv(
(conv): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
C3(
(cv1): Conv(
(conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv3): Conv(
(conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(m): Sequential(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
)
(1): Bottleneck(
(cv1): Conv(
(conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
)
(2): Bottleneck(
(cv1): Conv(
(conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
)
)
)
Conv(
(conv): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
SPP(
(cv1): Conv(
(conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(m): ModuleList(
(0): MaxPool2d(kernel_size=5, stride=1, padding=2, dilation=1, ceil_mode=False)
(1): MaxPool2d(kernel_size=9, stride=1, padding=4, dilation=1, ceil_mode=False)
(2): MaxPool2d(kernel_size=13, stride=1, padding=6, dilation=1, ceil_mode=False)
)
)
C3(
(cv1): Conv(
(conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv3): Conv(
(conv): Conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(m): Sequential(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
)
)
)
Conv(
(conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
Upsample(scale_factor=2.0, mode=nearest)
Concat()
C3(
(cv1): Conv(
(conv): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv3): Conv(
(conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(m): Sequential(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
)
)
)
Conv(
(conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
Upsample(scale_factor=2.0, mode=nearest)
Concat()
C3(
(cv1): Conv(
(conv): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv3): Conv(
(conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(m): Sequential(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
)
)
)
Conv(
(conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
Concat()
C3(
(cv1): Conv(
(conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv3): Conv(
(conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(m): Sequential(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
)
)
)
Conv(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
Concat()
C3(
(cv1): Conv(
(conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv3): Conv(
(conv): Conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(m): Sequential(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=0.001, momentum=0.03, affine=True, track_running_stats=True)
(act): SiLU()
)
)
)
)
Detect(
(m): ModuleList(
(0): Conv2d(128, 21, kernel_size=(1, 1), stride=(1, 1))
(1): Conv2d(256, 21, kernel_size=(1, 1), stride=(1, 1))
(2): Conv2d(512, 21, kernel_size=(1, 1), stride=(1, 1))
)
)
总结
train.py中还有很多待学习的知识点,能力有限这次暂且只关注了parse_model过程。后面将补充学习create_datase过程并加深对parse_model过程的深层理解。总而言之,还需要自己动手debug进行代码的理解才能有所收获。网上对yolov5源码的解析博客很多,但感觉都是从自己的理解角度进行注释的,对像自己一样的菜鸟来说还是不好理解。