OpenCV中文文档4.0.0学习笔记(更新中……)
系列文章目录
文章目录
- 系列文章目录
- 前言
- 一、简介
-
- 1.OpenCV-Python教程简介
- 2.OpenCV-Python
- 3.OpenCV-Python教程
- 4.OpenCV 需要你!!!
- 二、GUI功能
-
- 1.图像入门
- 2.视频入门
- 3.绘图功能
- 4.鼠标作为画笔
- 5.作为调色板的跟踪栏
- 三、核心操作
-
- 1.图像的基本操作
- 2.图像的算术运算
- 四、图像处理
-
- 1.更改颜色空间
- 2.图像的几何变换
- 3.图像阈值
- 4.平滑图像
- 5.形态转换
- 总结
前言
一、简介
1.OpenCV-Python教程简介
OpenCV 于 1999 年由 Gary Bradsky 在英特尔创立,第一个版本于 2000 年问世。Vadim Pisarevsky 加入了 Gary Bradsky,负责管理英特尔的俄罗斯软件 OpenCV 团队。2005 年,OpenCV 被用于 Stanley ,这辆车赢得了 2005 年美国穿越沙漠 DARPA 机器人挑战大赛。后来,在 Willow Garage 的支持下,在 Gary Bradsky 和 Vadim Pisarevsky 主导下,OpenCV 项目的开发工作变得活跃起来。OpenCV 现在支持与计算机视觉和机器学习相关的众多算法,并且每天都在拓展中。
OpenCV 支持各种编程语言,如 C++,Python,Java 等,可在不同的平台上使用,包括 Windows,Linux,OS X,Android 和 iOS。基于 CUDA 和 OpenCL 的高速 GPU 操作接口也在积极开发中。
OpenCV-Python 是 OpenCV 的 Python API,结合了 OpenCV C++ API 和 Python 语言的最佳特性。
2.OpenCV-Python
OpenCV-Python 是一个 Python 绑定库,旨在解决计算机视觉问题。
Python 是一种由 Guido van Rossum 开发的通用编程语言,它很快就变得非常流行,主要是因为它的简单性和代码可读性。它使程序员能够用更少的代码表达思想,而不会降低可读性。
与 C/C++ 这类语言相比,Python 的速度更慢。好在,可以使用 C/C++ 轻松的拓展 Python ,我们可以在 C/C++ 中编写计算密集型代码,并用 Python 来封装。这给我们带来了两个好处:首先,代码像原始的 C/C++ 代码一样快(因为后台实际上就是 C/C++ 代码在工作),其次,在 Python 中编写代码比在 C/C++ 中更容易。OpenCV-Python 就是 OpenCV C++ 的 Python 封装。
OpenCV-Python 使用了 Numpy,这是一个有着 MATLAB 风格语法,高度优化的用于数值计算的库。所有 OpenCV 数组结构都与 Numpy 数组进行转换。这也使得与使用 Numpy 的其他库(如 SciPy 和 Matplotlib)集成更容易。
3.OpenCV-Python教程
OpenCV 引入了一组新的教程,它将指导你学习 OpenCV-Python 中提供的各种功能。本教程主要关注 OpenCV 3.x 版本(尽管大多数内容也适用于 OpenCV 2.x)。
建议先了解 Python 和 Numpy,因为本教程不涉及它们。为了使用 OpenCV-Python 编写优化代码,你必须熟练使用 Numpy。
本教程最初由 Abid Rahman K.在 Alexander Mordvintsev 的指导下作为 Google Summer of Code 2013 计划的一部分启动。
4.OpenCV 需要你!!!
OpenCV 是一个开源的项目,欢迎所有人对库、文档和教程做出贡献。如果您在本教程中发现任何错误(从小的拼写错误到代码或概念中的严重错误),请在 Github 中 clone OpenCV ,并提交一个 pull request 来纠正错误。OpenCV 开发者将会检查你的 pull request,给你反馈,并且(一旦通过审核人员的批准),将更改合并到项目中。然后,你将成为开源贡献者。
随着新模块添加到 OpenCV-Python,本教程将不得不进行扩展。如果你熟悉特定算法,可以编写包含算法基本理论的教程,并能够编写使用样例,请参与到教程的编写中来。
记住,这个项目因我们的共同努力而变得伟大!!!
贡献者
以下是向 OpenCV-Python 提交教程的贡献者列表。
Alexander Mordvintsev (GSoC-2013 导师)
Abid Rahman K. (GSoC-2013 实习生)
二、GUI功能
1.图像入门
使用 OpenCV
读取图像
使用 cv.imread() 函数读取一张图像,图片应该在工作目录中,或者应该提供完整的图像路径。
第二个参数是一个 flag,指定了应该读取图像的方式
- cv.IMREAD_COLOR:加载彩色图像,任何图像的透明度都会被忽略,它是默认标志
- cv.IMREAD_GRAYSCALE:以灰度模式加载图像
- cv.IMREAD_UNCHANGED:加载图像,包括 alpha 通道
Note
- 你可以简单地分别传递整数 1、0 或-1,而不是这三个 flag。
看下面的代码
import numpy as np
import cv2 as cv
# 用彩色模式加载图像,1是彩色 0是灰度 -1包括alpha通道
img = cv.imread('messi5.jpg', 1)
注意
即使图像路径错误,它也不会抛出任何错误,但是打印 img会给你None
显示图像
用 cv.imshow() 函数在窗口中显示图像,窗口自动适应图像的大小。
第一个参数是窗口名,它是一个字符串,第二个参数就是我们的图像。你可以根据需要创建任意数量的窗口,但是窗口名字要不同。
cv.imshow('image', img)
cv.waitKey(0)
cv.destroyAllWindows()
一个窗口的截图可能看起来像这样 (in Fedora-Gnome machine):
cv.waitKey() 是一个键盘绑定函数,它的参数是以毫秒为单位的时间。该函数为任意键盘事件等待指定毫秒。如果你在这段时间内按下任意键,程序将继续。如果传的是 0,它会一直等待键盘按下。它也可以设置检测特定的击键,例如,按下键 a 等,我们将在下面讨论。
Note
- 除了绑定键盘事件,该函数还会处理许多其他 GUI 事件,因此你必须用它来实际显示图像。
cv.destroyAllWindows() 简单的销毁我们创建的所有窗口。如果你想销毁任意指定窗口,应该使用函数 cv.destroyWindow() 参数是确切的窗口名。
Note
- 有一种特殊情况,你可以先创建一个窗口然后加载图像到该窗口。在这种情况下,你能指定窗口是否可调整大小。它是由这个函数完成的 cv.namedWindow()。默认情况下,flag 是 cv.WINDOW_AUTOSIZE。但如果你指定了 flag 为 cv.WINDOW_NORMAL,你能调整窗口大小。当图像尺寸太大,在窗口中添加跟踪条是很有用的。
看下面的代码:
cv.namedWindow('image', cv.WINDOW_NORMAL)
cv.imshow('image',img)
cv.waitKey(0)
cv.destroyAllWindows()
保存图像
保存图像,用这个函数 cv.imwrite()。
第一个参数是文件名,第二个参数是你要保存的图像。
cv.imwrite('messigray.png',img)
将该图像用 PNG 格式保存在工作目录。
总结一下
下面的程序以彩色模式读取图像,显示图像,如果你按下 ‘s‘ 会保存和退出图像,或者按下 ESC 退出不保存。
import numpy as np
import cv2 as cv
img = cv.imread('test1.jpg',1)
cv.imshow('image',img)
k = cv.waitKey(0)
if k == 27: # ESC 退出
cv.destroyAllWindows()
elif k == ord('s'): # 's' 保存退出
cv.imwrite('messigray.png',img)
cv.destroyAllWindows()
注意
如果你使用的是 64 位机器,你需要修改k = cv.waitKey(0)像这样:k = cv.waitKey(0) & 0xFF
使用 Matplotlib
Matplotlib 是一个 Python 的绘图库,提供了丰富多样的绘图函数。你将在接下来的文章中看到它们。在这里,你将学习如何使用 Matplotlib 来显示图像。你还能用 Matplotlib 缩放图像,保存图像等。
import numpy as np
import cv2 as cv
from matplotlib import pyplot as plt
img = cv.imread('messi5.jpg',0)
plt.imshow(img, cmap = 'gray', interpolation = 'bicubic')
plt.xticks([]), plt.yticks([]) # 隐藏 X 和 Y 轴的刻度值
plt.show()
窗口的屏幕截图是这样的:

注意
彩色图像 OpenCV 用的 BGR 模式,但是 Matplotlib 显示用的 RGB 模式。因此如果图像用 OpenCV 加载,则 Matplotlib 中彩色图像将无法正常显示。
2.视频入门
捕捉视频
通常,我们用相机捕捉视频。OpenCV为此提供了一个非常简单的接口。我们用相机捕捉一个视频,将它转换成灰度视频并显示。获取一个视频,我们需要创建一个VideoCapture对象。它的参数可以是设备索引或者一个视频文件名。设备索引仅仅是摄像机编号。通常会连接一台摄像机。我们可以通过传1来选择第二个摄像机。以此类推,之后,我们可以逐帧捕获。但是最后不要忘记释放这个Capture对象。
import numpy as np
import cv2 as cv
cap =cv.VideoCapture(0)
#cap =cv.VideoCapture('vm7.mp4')
while(True):
#while(cap.isOpened()):
#一帧一帧捕获
ret,frame = cap.read()
#对帧操作
gray = cv.cvtColor(frame,cv.COLOR_BGR2GRAY)
#显示返回的每帧
cv.imshow('frame',gray)
if cv.waitKey(1) & 0xFF == ord('q'):
break
#当所有的事完成时,释放VideoCapture对象
cap.release()
cv.destroyAllWindows()
cap.read()返回一个Bool值(Ture/False)。如果加载成功,它会返回Ture。因此我们可以通过这个返回值判断视频是否结束。
有时,cap可能没有初始化capture。在这种情况下,此代码显示错误,我们可以通过该方法cap.isOpened()检查它是否初始化。如果是Ture,那么是好的,否则用cap.open()打开再使用。
我们也可以通过使用cap.get(propld)函数获取一些视频的特征,这里的propld是一个0-18的数字,每个数字代表视频的一个特征,或者使用cv::VideoCapture::get()获取全部细节。它们中有些值可以使用cap.set(propld,value)修改。Value就是我们想要的新值。
例如:我们可以用cap.get(cv.CAP_PROP_FRAME_WIDTH)获得宽,cap.get(cv.CAP_PROP_FRAME_HEIGHT)获得高。它返回的是640480,但是我想把它修改为320240、仅使用ret=cap.set(cv.CAP_PROP_FRAME_WIDTH,320)和ret=cap.set(cv.CAP_PROP_FRAME_HEIGHT,240)
Note:
- 如果报错,确保用任意其它相机程序可以正常工作
播放视频文件
它和从相机捕捉视频一样,只需要用视频文件名更改相机索引。同时显示frame,为cv.waitKey(),使用合适的时间。如果它太小,视频将非常快,如果太大则很慢(这就是如何显示慢动作)。正常情况下,25毫秒就可以了。
import numpy as np
import cv2 as cv
#cap =cv.VideoCapture(0)
cap =cv.VideoCapture('vm7.mp4')
#while(True):
while(cap.isOpened()):
#一帧一帧捕获
ret,frame = cap.read()
#对帧操作
gray = cv.cvtColor(frame,cv.COLOR_BGR2GRAY)
#显示返回的每帧
cv.imshow('frame',gray)
if cv.waitKey(1) & 0xFF == ord('q'):
break
#当所有的事完成时,释放VideoCapture对象
cap.release()
cv.destroyAllWindows()
Note
- 确保ffmpeg和gstreamer安装合适的版本。
保存视频
我们捕获视频,逐帧处理然后保存下来。对于图像来说,是非常简单的,就用cv.imwrite()。这里需要做更多的工作。这次我们创建一个VideoWriter对象。我们应该指定输出文件的名字。然后我们应该指定FourCC码。然后应该传递每秒帧数和帧大小。最后一个是isColor flag。如果是True,编码器期望彩色帧,否则它适用于灰度帧。
FourCC是用于指定视频解码器的4字节代码。这里fourcc.org是可用编码的列表。它取决于平台:
- In Fedora: DIVX, XVID, MJPG, X264, WMV1, WMV2. (XVID 是最合适的. MJPG 结果比较大. X264 结果比较小)
- In Windows: DIVX (还需要测试和添加跟多内容)
- In OSX: MJPG (.mp4), DIVX (.avi), X264 (.mkv).
对于 MJPG, FourCC 的代码作为 cv.VideoWriter_fourcc(‘M’,’J’,’P’,’G’) 或 cv.VideoWriter_fourcc(*’MJPG’) 传递。
下面的代码从相机捕获,在垂直方向翻转每一帧然后保存它。
import numpy as np
import cv2 as cv
#cap = cv.VideoCapture(0)
cap = cv.VideoCapture('vm7.mp4')
# 声明编码器和创建 VideoWrite 对象
fourcc = cv.VideoWriter_fourcc(*'XVID')
out = cv.VideoWriter('output.avi',fourcc, 20.0, (640,480))
while(cap.isOpened()):
ret, frame = cap.read()
if ret==True:
frame = cv.flip(frame,0)
# 写入已经翻转好的帧
out.write(frame)
cv.imshow('frame',frame)
if cv.waitKey(1) & 0xFF == ord('q'):
break
else:
break
# 释放已经完成的工作
cap.release()
out.release()
cv.destroyAllWindows()
3.绘图功能
用OpenCV画不同的几何图形;
函数:cv.line(), cv.circle() , cv.rectangle(), cv.ellipse(), cv.putText() 等。
Code
- img:你想画的图片
- color:形状的颜色,如 BGR,它是一个元组,例如:蓝色(255,0,0)。对于灰度图,只需传一个标量值。
- thickness: 线或圆等的厚度。如果传 -1 就是像圆的闭合图形,它将填充形状。 默认 thickness = 1
- lineType:线条类型,如 8 连接,抗锯齿线等。默认情况下,它是 8 连接。cv.LINE_AA 画出抗锯齿线,非常好看的曲线。
画图形
import numpy as np
import cv2 as cv
# 创建一个黑色的图像
img = np.zeros((512,512,3), np.uint8)
cv.line(img,(0,0),(511,511),(255,0,0),5) # 画一条 5px 宽的蓝色对角线
cv.rectangle(img,(384,0),(510,128),(0,255,0),3) #画矩形
cv.circle(img,(447,63), 63, (0,0,255), -1) #画圆
cv.ellipse(img,(256,256),(100,50),0,0,180,255,-1) #画椭圆
pts = np.array([[10,5],[20,30],[70,20],[50,10]], np.int32) #画多边形
pts = pts.reshape((-1,1,2))
cv.polylines(img,[pts],True,(0,255,255))
cv.imshow('aaa',img)
cv.waitKey(0)
给图像加文字
4.鼠标作为画笔
函数:cv.setMouseCallback()
举例:我们创建一个鼠标回调函数,该函数在鼠标事件发生时执行。鼠标事件可以是与鼠标有关的任何内容,比如按下鼠标左键,弹起,双击等;所有的鼠标事件都给我们提供坐标(x,y)。通过这个事件和位置我们能做任何我们喜欢的事情。下面代码列出了所有可用的事件:
import cv2 as cv
events = [i for i in dir(cv) if 'EVENT' in i]
print(events)
Result:
['EVENT_FLAG_ALTKEY', 'EVENT_FLAG_CTRLKEY', 'EVENT_FLAG_LBUTTON', 'EVENT_FLAG_MBUTTON', 'EVENT_FLAG_RBUTTON', 'EVENT_FLAG_SHIFTKEY', 'EVENT_LBUTTONDBLCLK', 'EVENT_LBUTTONDOWN', 'EVENT_LBUTTONUP', 'EVENT_MBUTTONDBLCLK', 'EVENT_MBUTTONDOWN', 'EVENT_MBUTTONUP', 'EVENT_MOUSEHWHEEL', 'EVENT_MOUSEMOVE', 'EVENT_MOUSEWHEEL', 'EVENT_RBUTTONDBLCLK', 'EVENT_RBUTTONDOWN', 'EVENT_RBUTTONUP']
创建鼠标回调函数是有特定格式,在任何地方都一样,它仅仅是函数的功能不同。因此我们的鼠标回调函数是做一件事,就是我们双击的地方画圆:
import numpy as np
import cv2 as cv
# 鼠标回调函数
def draw_circle(event,x,y,flags,param):
if event == cv.EVENT_LBUTTONDBLCLK:
cv.circle(img,(x,y),100,(255,0,0),-1)
# 创建一个黑色图像,一个窗口,然后和回调绑定
img = np.zeros((512,512,3), np.uint8)
cv.namedWindow('image')
cv.setMouseCallback('image',draw_circle)
while(1):
cv.imshow('image',img)
if cv.waitKey(20) & 0xFF == 27:
break
cv.destroyAllWindows()
Result:

更多高级例子:
现在我们寻求更好的应用。这次,我们通过拖动鼠标绘制矩形或圆(取决于我们选择的模式),就像在Paint程序中一样。因此我们的鼠标回调函数有两个,一个画矩形一个画圆形。这个例子有助于我们创建和理解交互程序,像对象跟踪,图像分割等。
import numpy as np
import cv2 as cv
drawing = False # 如果 True 是鼠标按下
mode = True # 如果 True,画矩形,按下‘m’切换到曲线
ix,iy = -1,-1
# 鼠标回调函数
def draw_circle(event,x,y,flags,param):
global ix,iy,drawing,mode
if event == cv.EVENT_LBUTTONDOWN:
drawing = True
ix,iy = x,y
elif event == cv.EVENT_MOUSEMOVE:
if drawing == True:
if mode == True:
cv.rectangle(img,(ix,iy),(x,y),(0,255,0),-1)
else:
cv.circle(img,(x,y),5,(0,0,255),-1)
elif event == cv.EVENT_LBUTTONUP:
drawing = False
if mode == True:
cv.rectangle(img,(ix,iy),(x,y),(0,255,0),-1)
else:
cv.circle(img,(x,y),5,(0,0,255),-1)
下面我们用鼠标回调函数和 OpenCV 窗口绑定。在主循环中,我们应该设置一个‘m‘按健绑定以在矩形和圆形之间切换。
img = np.zeros((512,512,3), np.uint8)
cv.namedWindow('image')
cv.setMouseCallback('image',draw_circle)
while(1):
cv.imshow('image',img)
k = cv.waitKey(1) & 0xFF
if k == ord('m'):
mode = not mode
elif k == 27:
break
cv.destroyAllWindows()
完整代码:
import numpy as np
import cv2 as cv
drawing = False # 如果 True 是鼠标按下
mode = True # 如果 True,画矩形,按下‘m’切换到曲线
ix,iy = -1,-1
# 鼠标回调函数
def draw_circle(event,x,y,flags,param):
global ix,iy,drawing,mode
if event == cv.EVENT_LBUTTONDOWN:
drawing = True
ix,iy = x,y
elif event == cv.EVENT_MOUSEMOVE:
if drawing == True:
if mode == True:
cv.rectangle(img,(ix,iy),(x,y),(0,255,0),-1)
else:
cv.circle(img,(x,y),5,(0,0,255),-1)
elif event == cv.EVENT_LBUTTONUP:
drawing = False
if mode == True:
cv.rectangle(img,(ix,iy),(x,y),(0,255,0),-1)
else:
cv.circle(img,(x,y),5,(0,0,255),-1)
img = np.zeros((512,512,3), np.uint8)
cv.namedWindow('image')
cv.setMouseCallback('image',draw_circle)
while(1):
cv.imshow('image',img)
k = cv.waitKey(1) & 0xFF
if k == ord('m'):
mode = not mode
elif k == 27:
break
cv.destroyAllWindows()
Result:
5.作为调色板的跟踪栏
代码演示
这里,我们将创建简单的程序,显示你指定颜色。 你有一个显示颜色的窗口和三个轨迹栏,用来指定 B,G,R 颜色的。你可以滑动轨迹栏改变窗口的颜色。默认情况下,初始颜色被设置为黑色。 Here we will create a simple application which shows the color you specify. You have a window which shows the color and three trackbars to specify each of B,G,R colors. You slide the trackbar and correspondingly window color changes. By default, initial color will be set to Black.
对于 cv.getTrackbarPos() 函数,第一个参数是轨迹栏名字,第二那个是被附上窗口名字,第三个参数是默认值,第四个是最大值,第五个是回调函数,滑条改变所执行的函数。这个回调函数也有一个默认参数,表示轨迹栏位置。我们并不关心函数做什么事,所以我们简单提一下。
轨迹栏的另一个重要应用是用作按钮或者开关。OpenCV,默认情况,是没有按钮功能的。因此我们能用轨迹栏做一些这样的功能。在我们的程序中,我门创建了一个开关,其中程序只会在开关打开时有效,否则屏幕始终是黑色。
import numpy as np
import cv2 as cv
def nothing(x):
pass
# 创建一个黑色图像,一个窗口
img = np.zeros((300,512,3), np.uint8)
cv.namedWindow('image')
# 创建一个改变颜色的轨迹栏
cv.createTrackbar('R','image',0,255,nothing)
cv.createTrackbar('G','image',0,255,nothing)
cv.createTrackbar('B','image',0,255,nothing)
# 创建一个开关用来启用和关闭功能的
switch = '0 : OFF \n1 : ON'
cv.createTrackbar(switch, 'image',0,1,nothing)
while(1):
cv.imshow('image',img)
k = cv.waitKey(1) & 0xFF
if k == 27:
break
# get current positions of four trackbars
r = cv.getTrackbarPos('R','image')
g = cv.getTrackbarPos('G','image')
b = cv.getTrackbarPos('B','image')
s = cv.getTrackbarPos(switch,'image')
if s == 0:
img[:] = 0
else:
img[:] = [b,g,r]
cv.destroyAllWindows()

三、核心操作
1.图像的基本操作
- 访问像素值并修改它们
- 访问像素属性
- 设置感兴趣区域(ROI)
- 拆分和合并图像
本节中的几乎所有操作都与Numpy又关,熟悉Numpy才能使用Opencv编写更好的优化代码;
访问和修改像素值
先来理解一下,图像与一般的矩阵或张量有何不同(不考虑图像的格式,元数据等信息)。首先,一张图像有自己的属性,宽,高,通道数。其中宽和高是我们肉眼可见的属性,而通道数则是图像能呈现色彩的属性。我们都知道,光学三原色是红色,绿色和蓝色,这三种颜色的混合可以形成任意的颜色。常见的图像的像素通道也是对应的R,G,B三个通道,在OpenCV中,每个通道的取值为0~255,。(注:还有RGBA,YCrCb,HSV等其他图像通道表示)。即,一般彩色图像读进内存之后是一个h w c的矩阵,其中h为图像高(相当于矩阵的行),w为图像宽(相当于矩阵列),c为通道数。
下面我们先加载一副彩色图像,更准确的说,是一副黄色图像,如图所示。

黄色为绿色和红色的混合,所以,该图像的所有像素值都应为R=255,G=255,B=0
import numpy as np
import cv2
img = cv2.imread("yellow.png")
h,w,c = img.shape
#图像为128*128*3的大小
print(h,w,c)
Result:
300 506 3
从上面的代码中可以看到,您可以通过行和列坐标访问像素值。注意,对于 常见的RGB 图像,OpenCV的imread函数返回的是一个蓝色(Blue)、绿色(Green)、红色(Red)值的数组,维度大小为3。而对于灰度图像,仅返回相应的强度。
>>> import numpy as np
>>> import cv2
>>> img = cv2.imread("yellow.png")
>>> h,w,c = img.shape
>>> #图像为128*128*3的大小
... print(h,w,c)
300 506 3
>>> img[100,100]
array([ 0, 255, 255], dtype=uint8)
>>> blue=img[100,100,0]
>>> print(blue)
0
你也可以使用同样的方法来修改像素值
>>> img[100,100] = [255,255,255]
>>> print(img[100,100])
[255 255 255]
提示:Numpy 是一个用于快速阵列计算的优化库。因此,简单地访问每个像素值并对其进行修改将非常缓慢,并不鼓励这样做。
注意 :上述方法通常用于选择数组的某个区域,比如前 5 行和后 3 列。对于单个像素的访问,可以选择使用 Numpy 数组方法中的 array.item()和 array.itemset(),注意它们的返回值是一个标量。如果需要访问所有的 G、R、B 的值,则需要分别为所有的调用 array.item()。
更好的访问像素和编辑像素的方法:
import numpy as np
import cv2
img = cv2.imread("yellow.png")
h,w,c = img.shape
#图像为128*128*3的大小
print(h,w,c)
img[100,100]
# 仅访问蓝色通道的像素
blue = img[100,100,0]
print(blue)
z=img.item(10,10,2)
print(z)
img.itemset((10,10,2),100)
a=img.item(10,10,2)
print(a)
访问图像属性
图像属性包括行数,列数和通道数,图像数据类型,像素数等。
与一般的numpy.array一样,可以通过 img.shape 访问图像的形状。它返回一组由图像的行、列和通道组成的元组(如果图象是彩色的):
print(img.shape)
Result:
(300, 506, 3)
注意: 如果图像是灰度图像,则返回的元组仅包含行数和列数,因此它是检查加载的图像是灰度图还是彩色图的一种很好的方法。
通过 img.size 访问图像的总像素数:
print(img.size)
Result:
455400
图像数据类型可以由 img.dtype 获得:
print(img.dtype)
Result:
uint8
注意: img.dtype 在调试时非常重要,因为 OpenCV—Python 代码中的大量错误是由无效的数据类型引起的。
图像中的感兴趣区域
有时,您将不得不处理某些图像区域。对于图像中的眼部检测,在整个图像上进行第一次面部检测。当获得面部时,我们单独选择面部区域并在其内部搜索眼部而不是搜索整个图像。它提高了准确性(因为眼睛总是在脸上:D)和性能(因为我们在一个小区域搜索)。
使用 Numpy 索引再次获得 ROI(感兴趣区域)。在这里,我选择球并将其复制到图像中的另一个区域:
2.图像的算术运算
目标:
- 学习对图像的几种算术运算,如加法、减法、按位运算;
- 学习函数:cv.add()、cv.addWeighted()等;
图像加法:
我们可以通过OpenCV函数,cv.add()或简单的通过numpy操作将两个图像相加,res=img1+img2。两个图像应该具有相同的深度和类型,或者第二个图像可以是像素值,比如(0,0,0)黑色;(255,255,255)白色;
注意:OpenCV相加操作和Numpy相加操作之间存在差异。OpenCV添加是饱和操作,而Numpy添加是模运算。要注意的是,两种加法对于结果溢出的数据,会通过某种方法使在限定的数据范围内。
import numpy as np
import cv2
x = np.uint8([250])
y = np.uint8([10])
print(cv2.add(x,y))
print(x+y)
输出:
[[255]]
[4]
注:在将两个图像相加时会发现OpenCV函数能够提供更好的结果,所以尽可能地选择OpenCV函数。
图像混合:
这也是图像相加,但是对图像赋予不同的权重,从而给出混合感或透明感,按以下等式添加:
g ( x ) = ( 1 − α ) f 0 ( x ) + α f 1 ( x ) g(x)=(1-α) f_0 (x)+αf_1 (x) g(x)=(1−α)f0(x)+αf1(x)
通过在(0,1)之间改变α的值,可以用来对两幅图像或两段视频产生时间上的画面叠化(cross-dissolve)效果。(注:在幻灯片翻页时可以设置为前后页缓慢过渡以产生叠加效果)
案例:
cv.addWeighted()在图像上应用以下等式
g ( x ) = ( 1 − α ) f 0 ( x ) + α f 1 ( x ) g(x)=(1-α) f_0 (x)+αf_1 (x) g(x)=(1−α)f0(x)+αf1(x)
import numpy as np
import cv2
img1 = cv2.imread('pi1.jpg',)
img2 = cv2.imread('pi2.jpg')
dst = cv2.addWeighted(img1,0.7,img2,0.3,0)
cv2.imshow('dst',dst)
cv2.waitKey(0)
cv2.destroyAllWindows()
效果展示

统一图片大小
from PIL import Image
import os.path
import glob
def convertjpg(jpgfile,outdir,width=512,height=512):
img=Image.open(jpgfile)
try:
new_img=img.resize((width,height),Image.BILINEAR)
if not os.path.exists(outdir):
os.mkdir(outdir)
new_img.save(os.path.join(outdir,os.path.basename(jpgfile)))
except Exception as e:
print(e)
path = r"E:\py\python3.7\test2\test27opencv\pho_size\image\*.jpg"
for jpgfile in glob.glob(path):
convertjpg(jpgfile,r"E:\py\python3.7\test2\test27opencv\pho_size\pic")
按位操作:
这包括按位AND,OR,NOT和XOR。它们在提取图像的某一部分,定义和使用非矩形ROI等方面非常有用,下面将介绍如何更改特定区域:
假如我想加一个logo在一个图像上,如果只是简单的将两张图像相加,则会改变叠加处的颜色,如果进行混叠操作,则会得到一个由透明效果的结果,我们希望得到一个不透明的logo,如果是一个矩形logo我们可以用ROI来做,但是不规则形状的logo用bitwise来进行。
四、图像处理
1.更改颜色空间
目标:
- 如何将图片从一个颜色空间转换到另一个,例如BGR到Gray,BGR到HSV等
- 创建一个从视频中提取彩色对象的应用
- cv.cvtColor(),cv.inRange()
改变颜色空间:
在 OpenCV 中有超过 150 种颜色空间转换的方法。但我们仅需要研究两个最常使用的方法,他们是 BGR 到 Gray,BGR 到 HSV。
我们使用 cv.cvtColor(input_image, flag)函数进行颜色转换,其中 flag 决定了转换的类型。
对于 BGR 到 Gray 转换我们令 flag 为 cv.COLOR_BGR2GRAY。 同样,对于 BGR 到 HSV, 我们令 flag 为 cv.COLOR_BGR2HSV。如想得到其他 flag 值,只需要在 Python 终端中输入如下命令:
import cv2 as cv
flags = [i for i in dir(cv) if i.startswith('COLOR_')]
print(flags)
注意:对于HSV,色调(Hue)范围为[0,179],饱和度(Saturation)范围为[0,255],明亮度(Value)为[0,255]。不同的软件使用不同的比例,所以如果你想用OpenCV的值与别的软件的值做对比,需要归一化这些范围。
目标追踪:
现在我们知道了如何将 BGR 图片转化为 HSV 图片,我们可以使用它去提取彩色对象。HSV 比 BGR 在颜色空间上更容易表示颜色。在我们的应用中,我们会尝试提取一个蓝色的彩色对象,方法为:
- 提取每一视频帧。
- 将 BGR 转化为 HSV 颜色空间。
- 我们用蓝色像素的范围对该 HSV 图片做阈值。
- 现在提取出了蓝色对象,我们可以随意处理图片了 。
import cv2 as cv
import numpy as np
cap = cv.VideoCapture(0)
while(1):
# Take each frame
_, frame = cap.read()
# Convert BGR to HSV
hsv = cv.cvtColor(frame, cv.COLOR_BGR2HSV)
# define range of blue color in HSV
lower_blue = np.array([100,50,50])
upper_blue = np.array([140,255,255])
# Threshold the HSV image to get only blue colors
mask = cv.inRange(hsv, lower_blue, upper_blue)
# Bitwise-AND mask and original image
res = cv.bitwise_and(frame,frame, mask= mask)
cv.imshow('frame',frame)
cv.imshow('mask',mask)
cv.imshow('res',res)
k = cv.waitKey(5) & 0xFF
if k == 27:
break
cv.destroyAllWindows()
如何找到HSV值去追踪?
2.图像的几何变换
目标:
- 几何变换,如平移、旋转、仿射变换;
- cv.getPerspectiveTransform
变换:
OpenCV 提供了两个变换函数, cv.warpAffine 和 cv.getPerspectiveTransform ,用这两个函数就可以完成所有类型的变换。
缩放:
缩放是调整图片的大小。 OpenCV 使用 cv.resize() 函数进行调整。可以手动指定图像的大小,也可以指定比例因子。可以使用不同的插值方法。对于下采样(图像上缩小),最合适的插值方法是 cv.INTER_AREA 对于上采样(放大),最好的方法是 cv.INTER_CUBIC (速度较慢)和 cv.INTER_LINEAR (速度较快)。默认情况下,所使用的插值方法都是 cv.INTER_AREA 。你可以使用如下方法调整输入图片大小:
import numpy as np
import cv2 as cv
img = cv.imread('test1.jpg')
res = cv.resize(img,None,fx=2,fy=2,interpolation = cv.INTER_CUBIC)
height,width = img.shape[:2]
res = cv.resize(img,(2*width,2*height),interpolation = cv.INTER_CUBIC)
cv.imshow('res',res)
cv.waitKey(0)
提示:
cv.warpAffine 函数的第三个参数是输出图像的大小,其形式应为(宽度、高度)。记住宽度=列数,高度=行数。
3.图像阈值
目标:
- 简单阈值法、自适应阈值法、以及Otsu阈值法(俗称大津法)
- cv.threshold、cv.adaptiveThreshold
简单阈值法:
此方法是直接了当的,如果像素值大于阈值,则会被赋予一个值(白色或黑色)。使用的函数是cv.threshold。第一个参数是源图像,它应该是灰度图像,第二个参数是阈值,用于对像素值进行分类,第三个参数是maxval,它代表像素值大于或小于阈值时给定的值。openCV提供了不同类型的阈值,由函数的第四个参数决定,不同类型有:
- cv.THRESH_BINARY
- cv.THRESH_BINARY_INV
- cv.THRESH_TRUNC
- cv.THRESH_TOZERO
- cv.THRESH_TOZERO_INV
获得两个输出,第一个是retval,第二个输出是我们的阈值图像;
import cv2 as cv
import numpy as np
from matplotlib import pyplot as plt
img = cv.imread('m4.png',0)
ret,thresh1 = cv.threshold(img,127,255,cv.THRESH_BINARY)
ret,thresh2 = cv.threshold(img,127,255,cv.THRESH_BINARY_INV)
ret,thresh3 = cv.threshold(img,127,255,cv.THRESH_TRUNC)
ret,thresh4 = cv.threshold(img,127,255,cv.THRESH_TOZERO)
ret,thresh5 = cv.threshold(img,127,255,cv.THRESH_TOZERO_INV)
titles = ['Original Image','BINARY','BINARY_INV','TRUNC','TOZERO','TOZERO_INV']
images = [img, thresh1, thresh2, thresh3, thresh4, thresh5]
for i in range(6):
plt.subplot(2,3,i+1),plt.imshow(images[i],'gray')
plt.title(titles[i])
plt.xticks([]),plt.yticks([])
plt.show()
效果如下:

自适应阈值:
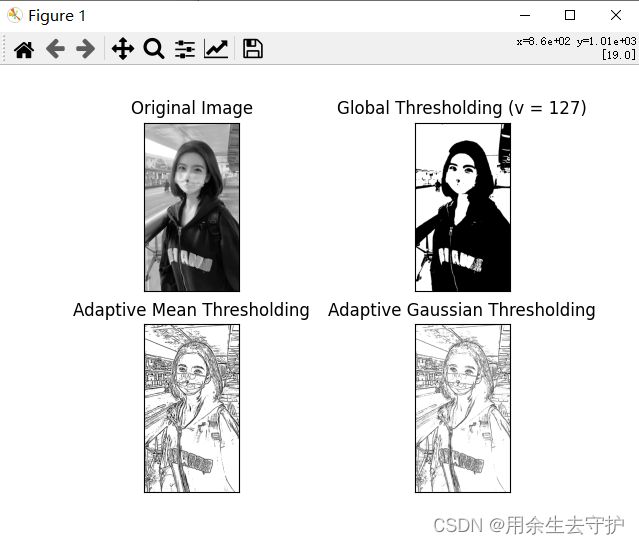
在前一节中,我们使用一个全局变量作为阈值。但在图像在不同区域具有不同照明条件的条件下,这可能不是很好。在这种情况下,我们采用自适应阈值。在此,算法计算图像的一个小区域的阈值。因此,我们得到了同一图像不同区域的不同阈值,对于不同光照下的图像,得到了更好的结果。
它有三个“特殊”输入参数,只有一个输出参数。
Adaptive Method-它决定如何计算阈值。
- cv.ADAPTIVE_THRESH_MEAN_C 阈值是指邻近地区的平均值。
- cv.ADAPTIVE_THRESH_GAUSSIAN_C 阈值是权重为高斯窗的邻域值的加权和。
Block Size-它决定了计算阈值的窗口区域的大小。
C-它只是一个常数,会从平均值或加权平均值中减去该值。
下面的代码比较了具有不同照明的图像的全局阈值和自适应阈值:
import cv2 as cv
import numpy as np
from matplotlib import pyplot as plt
img = cv.imread('3.jpg',0)
img = cv.medianBlur(img,5)
ret,th1 = cv.threshold(img,127,255,cv.THRESH_BINARY)
th2 = cv.adaptiveThreshold(img,255,cv.ADAPTIVE_THRESH_MEAN_C,\
cv.THRESH_BINARY,11,2)
th3 = cv.adaptiveThreshold(img,255,cv.ADAPTIVE_THRESH_GAUSSIAN_C,\
cv.THRESH_BINARY,11,2)
titles = ['Original Image', 'Global Thresholding (v = 127)',
'Adaptive Mean Thresholding', 'Adaptive Gaussian Thresholding']
images = [img, th1, th2, th3]
for i in range(4):
plt.subplot(2,2,i+1),plt.imshow(images[i],'gray')
plt.title(titles[i])
plt.xticks([]),plt.yticks([])
plt.show()
效果如下:
Otsu二值化:
在第一部分中,我告诉过您有一个参数 retval。当我们进行 Otsu 二值化时,它的用途就来了。那是什么?
在全局阈值化中,我们使用一个任意的阈值,对吗?那么,我们如何知道我们选择的值是好的还是不好的呢?答案是,试错法。但是考虑一个双峰图像(简单来说,双峰图像是一个直方图有两个峰值的图像)。对于那个图像,我们可以近似地取这些峰值中间的一个值作为阈值,对吗?这就是 Otsu 二值化所做的。所以简单来说,它会自动从双峰图像的图像直方图中计算出阈值。(对于非双峰图像,二值化将不准确。)
为此,我们使用了 cv.threshold 函数,但传递了一个额外的符号 cv.THRESH_OTSU 。对于阈值,只需传入零。然后,该算法找到最佳阈值,并作为第二个输出返回 retval。如果不使用 otsu 阈值,则 retval 与你使用的阈值相同。
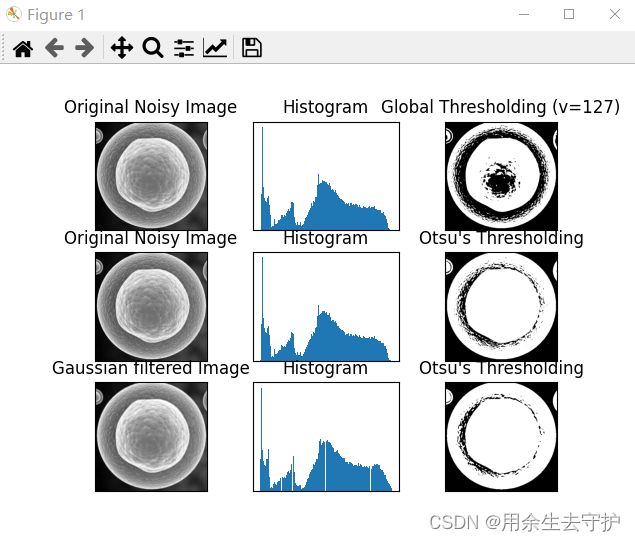
查看下面的示例。输入图像是噪声图像。在第一种情况下,我应用了值为 127 的全局阈值。在第二种情况下,我直接应用 otsu 阈值。在第三种情况下,我使用 5x5 高斯核过滤图像以去除噪声,然后应用 otsu 阈值。查看噪声过滤如何改进结果。
import cv2 as cv
import numpy as np
from matplotlib import pyplot as plt
img = cv.imread('2.png',0)
# 全局阈值
ret1,th1 = cv.threshold(img,127,255,cv.THRESH_BINARY)
# Otsu 阈值
ret2,th2 = cv.threshold(img,0,255,cv.THRESH_BINARY+cv.THRESH_OTSU)
# 经过高斯滤波的 Otsu 阈值
blur = cv.GaussianBlur(img,(5,5),0)
ret3,th3 = cv.threshold(blur,0,255,cv.THRESH_BINARY+cv.THRESH_OTSU)
# 画出所有的图像和他们的直方图
images = [img, 0, th1,
img, 0, th2,
blur, 0, th3]
titles = ['Original Noisy Image','Histogram','Global Thresholding (v=127)',
'Original Noisy Image','Histogram',"Otsu's Thresholding",
'Gaussian filtered Image','Histogram',"Otsu's Thresholding"]
for i in range(3):
plt.subplot(3,3,i*3+1),plt.imshow(images[i*3],'gray')
plt.title(titles[i*3]), plt.xticks([]), plt.yticks([])
plt.subplot(3,3,i*3+2),plt.hist(images[i*3].ravel(),256)
plt.title(titles[i*3+1]), plt.xticks([]), plt.yticks([])
plt.subplot(3,3,i*3+3),plt.imshow(images[i*3+2],'gray')
plt.title(titles[i*3+2]), plt.xticks([]), plt.yticks([])
plt.show()
效果如下:
Otsu 二值化原理:
本节演示了 otsu 二值化的 python 实现,以展示它的实际工作原理。如果你不感兴趣,可以跳过这个。
由于我们使用的是双峰图像,因此 Otsu 的算法试图找到一个阈值(t),该阈值将由下式计算得到的类内加权方差最小化:
它实际上找到一个 T 值,它位于两个峰值之间,使得两个类的方差最小。它可以简单地在 python 中实现,如下所示:
import cv2 as cv
import numpy as np
img = cv.imread('3.jpg',0)
blur = cv.GaussianBlur(img,(5,5),0)
# 找到归一化直方图还有累计分布函数
hist = cv.calcHist([blur],[0],None,[256],[0,256])
hist_norm = hist.ravel()/hist.max()
Q = hist_norm.cumsum()
bins = np.arange(256)
fn_min = np.inf
thresh = -1
for i in range(1,256):
p1,p2 = np.hsplit(hist_norm,[i]) # 概率
q1,q2 = Q[i],Q[255]-Q[i] # 类别总和
b1,b2 = np.hsplit(bins,[i]) # 权重
# f 找到均值与方差
m1,m2 = np.sum(p1*b1)/q1, np.sum(p2*b2)/q2
v1,v2 = np.sum(((b1-m1)**2)*p1)/q1,np.sum(((b2-m2)**2)*p2)/q2
# 计算最小函数
fn = v1*q1 + v2*q2
if fn < fn_min:
fn_min = fn
thresh = i
# 用 OpenCV 函数的 otsu'阈值
ret, otsu = cv.threshold(blur,0,255,cv.THRESH_BINARY+cv.THRESH_OTSU)
print( "{} {}".format(thresh,ret) )
.\opencv.py:388: RuntimeWarning: divide by zero encountered in double_scalars
m1,m2 = np.sum(p1*b1)/q1, np.sum(p2*b2)/q2
.\opencv.py:391: RuntimeWarning: invalid value encountered in double_scalars
fn = v1*q1 + v2*q2
105 104.0
4.平滑图像
目标:
- 用各种低通滤波器模糊图像
- 对图像应用自定义过滤器(二维卷积)
二维卷积(图像滤波)
与一维信号一样,图像也可以通过各种低通滤波器(LPF)、高通滤波器(HPF)等进行过滤。LPF 有助于消除噪音、模糊图像等。HPF 滤波器有助于在图像中找到边缘。
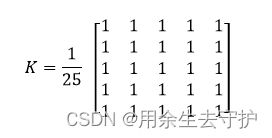
opencv 提供了函数 cv.filter2D(),用于将内核与图像卷积起来。作为一个例子,我们将尝试对图像进行均值滤波操作。5x5 均值滤波卷积核如下:
操作如下:将该内核中心与一个像素对齐,然后将该内核下面的所有 25 个像素相加,取其平均值,并用新的平均值替换这个25x25窗口的中心像素。它继续对图像中的所有像素执行此操作。试试下面这段代码并观察结果:
import numpy as np
import cv2 as cv
from matplotlib import pyplot as plt
img = cv.imread('4.png')
kernel = np.ones((5,5),np.float32)/25
dst = cv.filter2D(img,-1,kernel)
plt.subplot(121),plt.imshow(img),plt.title('Original')
plt.xticks([]), plt.yticks([])
plt.subplot(122),plt.imshow(dst),plt.title('Averaging')
plt.xticks([]), plt.yticks([])
plt.show()
效果展示:
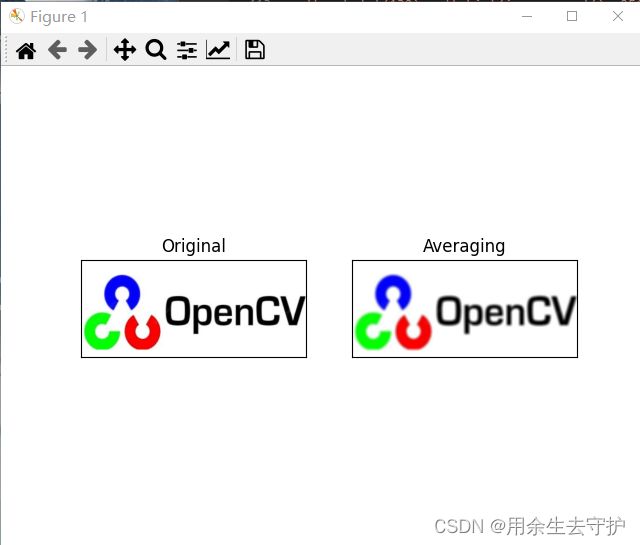
图像模糊(图像平滑)
图像模糊是通过将图像与低通滤波核卷积来实现的。它有助于消除噪音。它实际上从图像中删除高频内容(例如:噪声、边缘)。所以在这个操作中边缘有点模糊。(好吧,有一些模糊技术不会使边缘太模糊)。OpenCV 主要提供四种模糊技术。
1、均值模糊
这是通过用一个归一化的滤波器内核与图像卷积来完成的。它只需取内核区域下所有像素的平均值并替换中心元素。这是通过函数 cv.blur()或 cv.boxFilter()完成的。有关内核的更多详细信息,请查看文档。我们应该指定滤波器内核的宽度和高度。3x3 标准化框滤波器如下所示:
注意 如果你不用标准化滤波,使用 cv.boxFilter(),传入 normalize=False 参数。
5x5 核的简单应用如下所示:
import cv2 as cv
import numpy as np
from matplotlib import pyplot as plt
img = cv.imread('4.png')
blur = cv.blur(img,(5,5))
plt.subplot(121),plt.imshow(img),plt.title('Original')
plt.xticks([]), plt.yticks([])
plt.subplot(122),plt.imshow(blur),plt.title('Blurred')
plt.xticks([]), plt.yticks([])
plt.show()
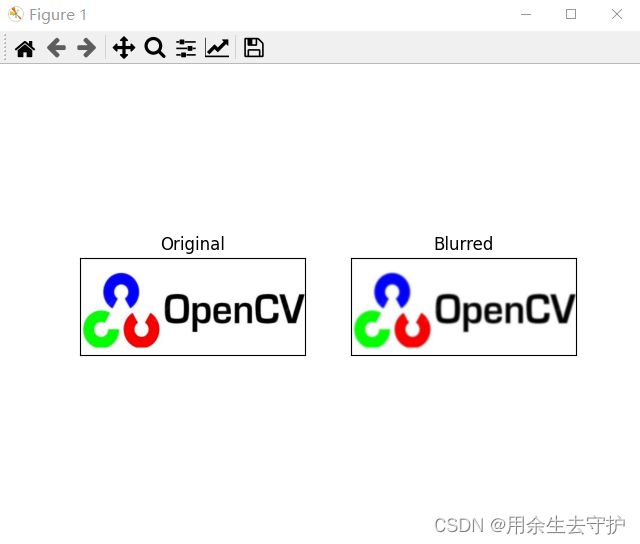
效果展示:

2、高斯模糊
在这种情况下,使用高斯核代替了核滤波器。它是通过函数 cv.GaussianBlur()完成的。我们应该指定内核的宽度和高度,它应该是正数并且是奇数(奇数才有一个中位数)。我们还应该分别指定 x 和 y 方向的标准偏差、sigmax 和 sigmay。如果只指定 sigmax,则 sigmay 与 sigmax 相同。如果这两个值都是 0,那么它们是根据内核大小计算出来的。高斯模糊是消除图像高斯噪声的有效方法。
如果需要,可以使用函数 cv.getGaussianKernel()创建高斯内核。
上述代码可以修改为高斯模糊:
blur = cv.GaussianBlur(img,(5,5),0)
import cv2 as cv
import numpy as np
from matplotlib import pyplot as plt
img = cv.imread('4.png')
blur = cv.GaussianBlur(img,(5,5),0)
plt.subplot(121),plt.imshow(img),plt.title('Original')
plt.xticks([]), plt.yticks([])
plt.subplot(122),plt.imshow(blur),plt.title('Blurred')
plt.xticks([]), plt.yticks([])
plt.show()
效果展示:
3、中值滤波
在这里,函数 cv.medianBlur()取内核区域下所有像素的中值,将中央元素替换为该中值。这对图像中的椒盐噪声非常有效。有趣的是,在上面的过滤器中,中心元素是一个新计算的值,它可能是图像中的像素值,也可能是一个新值。但在中值模糊中,中心元素总是被图像中的一些像素值所取代,可以有效降低噪音。它的内核大小应该是一个正的奇数整数。
在这个演示中,我在原始图像中添加了 50%的噪声,并应用了中间模糊。结果如下:
median = cv.medianBlur(img,5)
4、双边滤波
cv.bilateralFilter()在保持边缘锐利的同时,对噪声去除非常有效。但与其他过滤器相比,操作速度较慢。我们已经看到高斯滤波器取像素周围的邻域并找到其高斯加权平均值。该高斯滤波器是一个空间函数,即在滤波时考虑相邻像素。但是它不考虑像素是否具有几乎相同的强度,也不考虑像素是否是边缘像素。所以它也会模糊边缘,这是我们不想做的。
双边滤波器在空间上也采用高斯滤波器,而另一个高斯滤波器则是像素差的函数。空间的高斯函数确保模糊只考虑邻近像素,而强度差的高斯函数确保模糊只考虑与中心像素强度相似的像素。所以它保留了边缘,因为边缘的像素会有很大的强度变化。
下面的示例显示使用双边滤波(有关参数的详细信息,请访问文档)。
blur = cv.bilateralFilter(img,9,75,75)
5.形态转换
目标:
- 学习不同形态操作,如腐蚀、膨胀、开、闭;
- 不同的函数,如: cv.erode()、 cv.dilate()、 cv.morphologyEx() 等。
理论:
形态学变换是基于图像形状的一些简单操作。它通常在二值图像上执行。它需要两个输入,一个是我们的原始图像,第二个是决定操作性质的结构元素或内核。两个基本的形态学操作是腐蚀和膨胀。接下来如开,闭,梯度等也会介绍。在下图的帮助下,我们将逐一看到它们:
总结
分享:
写作是心灵的自我对话一—它有着诸多的约束条件,因此并不是所有的人在任何时段、任何环境下都适合写作。没有思想骨架作为支撑,任何文字都只是一种软体的堆积。对于一个作者而言,什么时候都可以写,问题在于想不想写。