翻译:SMPL-X模型与SMPLify-X方法
论文翻译,详见原文:SMPL-X_CVPR2019.pdf
666
题目:Expressive Body Capture: 3D Hands, Face, and Body from a Single Image
Georgios Pavlakos, Vasileios Choutas, Nima Ghorbani, Timo Bolkart, Ahmed A. A. Osman, Dimitrios Tzionas, and Michael J. Black
MPI for Intelligent Systems,Tubingen,DE, University of Pennsylvania,PA,USA
{gpavlakos, vchoutas, nghorbani, tbolkart, aosman, dtzionas, black}@tuebingen.mpg.de
摘要
为了便于分析人类的行为、互动和情感,本文从一张单目图像计算人体姿势、手部姿势和面部表情的3D模型。为了实现这一点,本文扩展了SMPL,使之具有完全关节化的双手和富有表情的脸,使用数千次三维扫描来训练新的统一人体三维模型SMPL-X。
在没有成对图像和3DGroundTruth的情况下,直接从图像回归学习SMPL-X参数是一个挑战,因此,本文效仿SMPLify方法先估计2D特征,然后优化模型参数来拟合这些特征。
本文在几个重要的方面改进了SMPLify:
(1)检测出脸部、手和脚对应的2D特征,并将完整的SMPL-X模型拟合到这些特征;
(2)使用大型MoCap数据集训练一个新的先验姿态神经网络(a new neural network pose prior);
(3)定义了一种既快速又准确的新的互穿惩罚项(a new interpenetration penalty);
(4)自动检测性别和适用的身体模型(男性、女性或中性);
(5)实现了PyTorch版本,相对Chumpy提速了8倍。
使用新的SMPLify-X方法,使SMPL-X适用于约束图像和自然图像。在一个由100张带有伪标签(pseudo ground-truth)图像组成的新精选数据集上评估了3D精度。
这是迈向从单目RGB数据自动捕获人体的重要一步。
可在https://smpl-x.is.tue.mpg.de获取模型、代码和数据以用于研究。
1引言
人类通常是图像和视频的核心要素。了解他们的姿势、交流的社交线索、和与世界的互动对于全面了解场景至关重要。最近的方法已经显示出在2D中估计主要身体关节、手关节和面部特征的快速进展[15,31,70]。然而,我们与世界的互动基本上是三维的,最近直接从图片估计出3D主要关节和粗糙三维姿态的工作也取得了进展,[10,37,59,62]。
但是,要理解人类行为,不仅要捕捉人体的主要关节,还需要捕捉人体、手和脸的完整3D曲面。由于缺乏合适的3D模型和丰富的3D训练数据等几个主要挑战,目前还没有系统能够做到。图1说明了该问题。仅使用稀疏2D信息或缺少手和脸部细节的3D表示,很难对表达性和交际图像进行解释。为解决该问题,需要做两件事。首先,需要一个能够表示人脸、手和身体姿势复杂性的人体3D模型;其次,需要一种从单个图像中提取这种模型的方法。
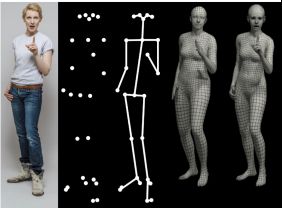
图 1 沟通和示意完全取决于身体的姿势、手势和面部表情。仅有身体主要关节不足以表示这点,当前的3D模型也不足以表现。较先前工作,本文方法从单个图像估计出更详细、更具表现力的3D模型。从左到右:RGB图像,主要关节,骨骼,SMPL模型(女),SMPL-X(女性)。 SMPL-X中的手和脸支持更全面和更具表现力的身体捕捉。
神经网络和人工标记图像的大数据集的发展使二维人体“姿势”估计取得了迅速的进展。该领域中的“姿势”通常意味着人体的主要关节。这不足以理解如图1所示的人类行为。OpenPose[15,60,70]将其扩展到包括2D手部关节和2D面部特征。尽管这捕获了更多关于交流意图的信息,但它不足以支持有关表面以及人类与3D世界交互。
3D身体模型专注于捕捉身体整体形状和姿态,不包括手和脸[2,3,6,26,48]。还有大量的文献是关于手[39,53,57,58,68,69,71,74,75]和脸[4,9,11,13,14,43,63,76,79]的3D建模,但与身体的其他部分是隔离的。直到最近才开始与手[68]或与手和脸[36]一起对身体建模。例如,Frank模型[36]结合了SMPL身体模型的简化版本[48]、艺术手绑定和FaceWarehouse[14]脸部模型。这些分离模型被缝合在一起,导致模型不完全真实。
我们从一个大型3D扫描语料库中学习了一个新的、整体的、带有脸和手的身体模型。新的SMPL-X模型(SMPL expression)基于SMPL并保留了该模型的优点:与图形软件兼容、简单参数化、体积小、高效、可区分等。我们将SMPL与FLAME头模型[43]和MANO手模型相结合[68],然后将这个组合模型注册到5586个3D扫描中,以保证质量。通过从数据中学习模型,我们捕捉到了身体、面部和手的形状之间的自然关联,并且得到的模型没有Frank所看到的伪影。模型的表现力如图2所示,其中我们将SMPL-X拟合到具有表现力的RGB图像中,以及在图4中,我们将SMPL-X拟合到公共LSP数据集的图像中[33]。SMPL-X可免费用于研究目的。

图 2 学习了一个名为SMPL-X的新人体3D模型,可以对身体、面部和手部进行联合建模。使用SMPLify-X将女性SMPL-X模型与单张RGB图像拟合,表明它可以捕获多种多样的自然且富有表现力的3D人体姿势、手势和面部表情表达式。
有几种方法使用深度学习从单个图像回归SMPL的参数[37,59,62]。然而,要用手和脸来估计一个三维人体,却没有合适的训练数据集。为了解决这个问题,我们遵循SMPLify的方法。首先,我们使用OpenPose“自底而上”估计2D图像特征[15,70,77],检测身体、手、脚的关节和面部特征。然后,将SMPL-X模型“自顶而下”拟合这些2D特征,称为SMPLify-X法。为此,我们对SMPLify进行了几项重要的改进。具体而言,使用变分自动编码器从大型的运动捕获数据集[50、51]中学习新的、性能更好的先验姿势。这个先验至关重要,因为从2D特征到3D姿态的映射是不明确的。我们还定义了一个新的(自我)渗透惩罚项,它比SMPLify的近似方法更加精确和有效,且仍然是可微的。我们训练了一个性别检测器,并使用它来自动确定要使用的身体模型,无论是男性、女性或是中性。最后,训练直接回归方法以估计SMPL参数的一个动机是SMPLify速度很慢。这里通过利用现代gpu的计算能力,使用比相应的Chumpy实现至少快8倍的PyTorch实现来解决这个问题。此SMPLify-X方法的示例如图2所示。
为了评估精度,我们需要带有全身RGB图像和相应的3D-Ground-Truth的新数据。为了达到这个目的,我们创建了一个新的评估数据集,其中包含一个主体各种姿势、手势和表情的图像。我们使用扫描系统捕捉三维人体形状,并将SMPL-X模型与扫描结果相匹配。这种形式的伪标签(pseudo ground-truth)足够精确,可以对身体、手和脸的模型一起进行定量评估。我们发现我们的模型和方法的性能明显优于相关和功能较弱的模型,结果自然而富有表现力。我们相信这项工作是朝着从单张RGB图像中同时捕捉身体、手和脸迈出的重要一步。我们在https://smpl-x.is.tue.mpg.de为研究目的提供SMPL-X模型、SMPLify-X代码、训练过的网络、模型匹配和评估数据集。
2相关工作
3技术方法
4实验




5结论
在这项工作中,我们展示了SMPL-X,一种可以将身体、脸和手结合在一起的新模型。我们还提出了SMPLify-X,一种将SMPL-X拟合到单张RGB图像和 OpenPose检测到的2D关节点的方法。我们利用新的强大的身体姿态先验和快速准确的穿透检测和惩罚方法在模糊情况下正则化拟合。我们利用野外图像提供了大量定性结果,显示了SMPL-X的表达能力和SMPLify-X的有效性。我们引入了一个带有伪标签(pseudo ground-truth)的精选数据集来执行定量评估,这显示了更具表达性的模型的重要性。在未来的工作中,我们将整理一个SMPL-X拟合数据集,并学习一个直接从RGB图像中回归SMPL-X参数的回归器。我们认为,这项工作是朝着从RGB图像同时捕获身体、手部和脸部的重要一步。