为什么 NGINX 的 reload 命令不是热加载?
这段时间在 Reddit 看到一个讨论,为什么 NGINX 不支持热加载?乍看之下很反常识,作为世界第一大 Web 服务器,不支持热加载?难道大家都在使用的 nginx -s reload 命令都用错了?带着这个疑问,让我们开始这次探索之旅,一起聊聊热加载和 NGINX 的故事。
NGINX 相关介绍
NGINX 是一个跨平台的开源 Web 服务器,使用 C 语言开发。据统计,全世界流量最高的前 1000 名网站中,有超过 40% 的网站都在使用 NGINX 处理海量请求。
NGINX 有什么优势,导致它从众多的 Web 服务器中脱颖而出,并一直保持高使用量呢?
我觉得核心原因在于,NGINX 天生善于处理高并发,能在高并发请求的同时保持高效的服务。
相比于同时代的其他竞争对手例如 Apache、Tomcat 等,其领先的事件驱动型设计和全异步的网络 I/O 处理机制,以及极致的内存分配管理等众多优秀设计,将服务器硬件资源压缩到了极致。使得 NGINX 成为高性能 Web 服务器的代名词。
当然,除此之外还有一些其他原因,比如:
-
高度模块化的设计,使得 NGINX 拥有无数个功能丰富的官方模块和第三方拓展模块。
-
最自由的 BSD 许可协议,使得无数开发者愿意为 NGINX 贡献自己的想法。
-
支持热加载,能保证 NGINX 提供 7x24h 不间断的服务。
关于热加载
大家期望的热加载功能是什么样的?我个人认为,首先应该是用户端无感知的,在保证用户请求正常和连接不断的情况下,实现服务端或上游的动态更新。
那什么情况下需要热加载?在如今云原生时代下,微服务架构盛行,越来越多的应用场景有了更加频繁的服务变更需求。包括反向代理域名上下线、上游地址变更、IP 黑白名单更新等,这些都和热加载息息相关。
那么 NGINX 是如何实现热加载的?
NGINX 热加载的原理
执行 nginx -s reload 热加载命令,就等同于向 NGINX 的 master 进程发送 HUP 信号。在 master 进程收到 HUP 信号后,会依次打开新的监听端口,然后启动新的 worker 进程。
此时会存在新旧两套 worker 进程,在新的 worker 进程起来后,master 会向老的 worker 进程发送 QUIT 信号进行优雅关闭。老的 worker 进程收到 QUIT 信号后,会首先关闭监听句柄,此时新的连接就只会流进到新的 worker 进程中,老的 worker 进程处理完当前连接后就会结束进程。

从原理上看,NGINX 的热加载能很好地满足我们的需求吗?答案很可能是否定的,让我们来看下 NGINX 的热加载存在哪些问题。
NGINX 热加载的缺陷
首先,NGINX 频繁热加载会造成连接不稳定,增加丢失业务的可能性。
NGINX 在执行 reload 指令时,会在旧的 worker 进程上处理已经存在的连接,处理完连接上的当前请求后,会主动断开连接。此时如果客户端没处理好,就可能会丢失业务,这对于客户端来说明显就不是无感知的了。
其次,在某些场景下,旧进程回收时间长,进而影响正常业务。
比如代理 WebSocket 协议时,由于 NGINX 不解析通讯帧,所以无法知道该请求是否为已处理完毕状态。即使 worker 进程收到来自 master 的退出指令,它也无法立刻退出,而是需要等到这些连接出现异常、超时或者某一端主动断开后,才能正常退出。
再比如 NGINX 做 TCP 层和 UDP 层的反向代理时,它也没法知道一个请求究竟要经过多少次请求才算真正地结束。
这就导致旧 worker 进程的回收时间特别长,尤其是在直播、新闻媒体活语音识别等行业。旧 worker 进程的回收时间通常能达到半小时甚至更长,这时如果再频繁 reload,将会导致 shutting down 进程持续增加,最终甚至会导致 NGINX OOM,严重影响业务。
# 一直存在旧 worker 进程:nobody 6246 6241 0 10:51 ? 00:00:00 nginx: worker processnobody 6247 6241 0 10:51 ? 00:00:00 nginx: worker processnobody 6247 6241 0 10:51 ? 00:00:00 nginx: worker processnobody 6248 6241 0 10:51 ? 00:00:00 nginx: worker processnobody 6249 6241 0 10:51 ? 00:00:00 nginx: worker processnobody 7995 10419 0 10:30 ? 00:20:37 nginx: worker process is shutting down <= herenobody 7995 10419 0 10:30 ? 00:20:37 nginx: worker process is shutting downnobody 7996 10419 0 10:30 ? 00:20:37 nginx: worker process is shutting down
从上述内容可以看到,通过 nginx -s reload方式支持的“热加载”,虽然在以往的技术场景中够用,但是在微服务和云原生迅速发展的今天,它已经捉襟见肘且不合时宜。
如果你的业务变更频率是每周或者每天,那么 NGINX 这种 reload 还是满足你的需求的。但如果变更频率是每小时、每分钟呢?假设你有 100 个 NGINX 服务,每小时 reload 一次的话,就要 reload 2400 次;如果每分钟 reload 一次,就是 864 万次。这显然是无法接受的。
因此,我们需要一个不需要进程替换的 reload 方案,在现有 NGINX 进程内可以直接完成内容的更新和实时生效。
在内存中直接生效的热加载方案
在 Apache APISIX 诞生之初,就是希望来解决 NGINX 热加载这个问题的。
Apache APISIX 是基于 NGINX + Lua 的技术栈,以 ETCD 作为配置中心实现的云原生、高性能、全动态的微服务 API 网关,提供负载均衡、动态上游、灰度发布、精细化路由、限流限速、服务降级、服务熔断、身份认证、可观测性等数百项功能。
使用 APISIX 你不需要重启服务就可以更新配置,这意味着修改上游、路由、插件时都不用重启。既然是基于 NGINX,APISIX 又是如何摆脱 NGINX 的限制实现完美热更新?我们先看下 APISIX 的架构。
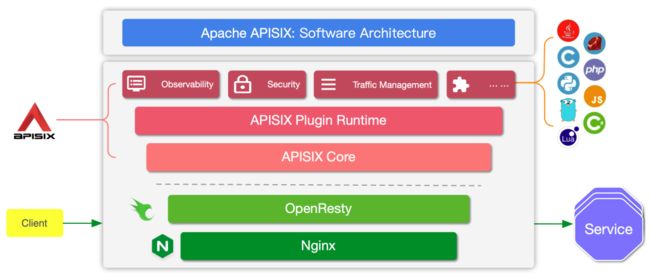
通过上述架构图可以看到,之所以 APISIX 能摆脱 NGINX 的限制是因为它把上游等配置全部放到 APISIX Core 和 Plugin Runtime 中动态指定。
以路由为例,NGINX 需要在配置文件内进行配置,每次更改都需要 reload 之后才能生效。而为了实现路由动态配置,Apache APISIX 在 NGINX 配置文件内配置了单个 server,这个 server 中只有一个 location。我们把这个 location 作为主入口,所有的请求都会经过这个 location,再由 APISIX Core 动态指定具体上游。因此 Apache APISIX 的路由模块支持在运行时增减、修改和删除路由,实现了动态加载。所有的这些变化,对客户端都零感知,没有任何影响。
再来几个典型场景的描述。
比如增加某个新域名的反向代理,在 APISIX 中只需创建上游,并添加新的路由即可,整个过程中不需要 NGINX 进程有任何重启。再比如插件系统,APISIX 可以通过 ip-restriction 插件实现 IP 黑白名单功能,这些能力的更新也是动态方式,同样不需要重启服务。借助架构内的 ETCD,配置策略以增量方式实时推送,最终让所有规则实时、动态的生效,为用户带来极致体验。
总结
NGINX 的热加载在某些场景下会长时间存在新旧两套进程,导致额外消耗资源,同时频繁热加载也会导致小概率业务丢失。面对当下云原生和微服务的技术趋势下, 服务变化更加的频繁,控制 API 的策略也发生了变化,导致我们对热加载的需求提出了新需求,NGINX 的热加载已经不能满足实际业务需求。
现在是时候切换到更贴合云原生时代并且更完善的热加载策略、性能表现卓越的 API 网关——Apache APISIX,从而享受动态、统一管理等特性带来的管理效率上的极大提升。