一文串起从NLP到CV 预训练技术和范式演进
本文首发于微信公众号:包包算法笔记。包大人班车原创内容分享。
主题是深度学习中的预训练技术发展,基本思路是顺着CV和NLP双线的预训练技术发展演进。看他们怎么影响和交织。
序言
会大致的看一下,在2013年,在CNN时代的word2vec,在2020年,Bert的时代的MAE,他们各自的预训练技术是在8年之间,从CNN发展到MAE,以及怎么从word2vec发展到Bert,各自的思路是怎样形成以及相互影响的。预训练技术的历史背景是什么,演进路线是什么,各个创新点是什么。为什么transformer作为集大成者,在CV和NLP上最后形成了交织和影响。
开头和结尾放同一张图,分别奠定本文的主线,所有细节将在后面逐渐展开!
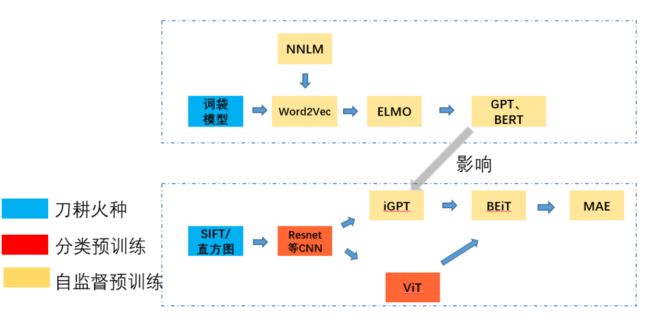
从NLP说起
从预训练技术说起,按照时间线,还是讲NLP里的word2vec吧,NLP里的有监督任务的范式,可以归纳成如下的样子。
输入是字词序列,中间一步关键的是语义表征,有了语义表征之后,然后交给下游的模型学习。预训练技术的发展,都是在围绕怎么得到一个好的语义表征(representation)的这一层次,逐渐改进的。
下面我们围绕表征(representation)这一块展开讲解。

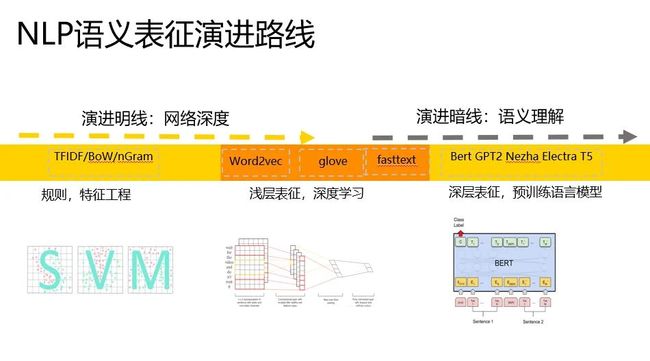
语义表征演进
我们可以把语义表征(representation)的计算,大致将演进路线归纳成如下的样子。
有两条路线,分别从网络深度和语义理解两个角度出发,网络越走越深,语义理解越来越深刻,越来越有代表性。
我们粗略的可以把语义表征的计算分为三个阶段,分别是:
一、特征工程阶段,以词袋模型为典型代表。
二、浅层表证阶段,以word2vec为典型代表。
三、深层表征阶段,以基于transformer的Bert为典型代表。
后面我们讲仔细讲解,演进中解决的关键问题和基本思路。
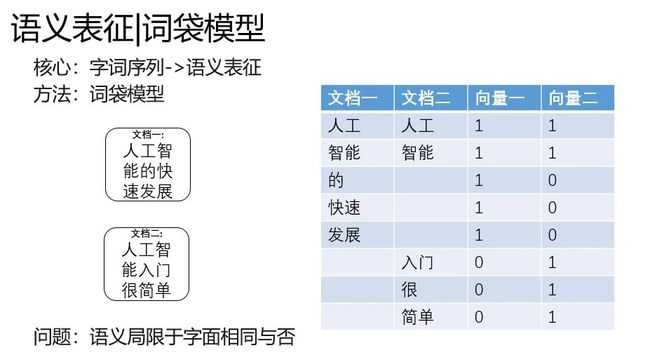
刀耕火种
首先是词袋模型,顾名思义,就是一个袋子打包词,表征计算如下文右边的篮筐,每个维度统计了文档中词的数量。
这种简单粗暴的表征有一个问题,就是语义局限与字面相同与否。
人工智能和AI两个词,在语义上是有强关联的,但是这个词袋模型就抓瞎了。
为了解决这个问题,word2vec在2013年被搞出来了。
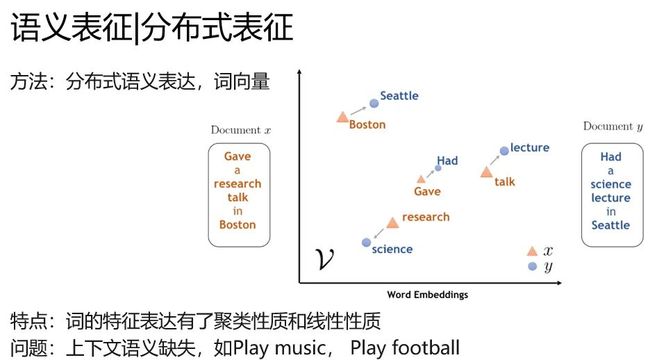
词向量
word2vec就是典型学术的分布式语义表征(distribution representation)的代表,你肯定听过另外一个名字,词向量。
嗯词袋模型的时候,人还真没把叫做词向量。顶多算特征工程的一种。在word2vec时候,这种语义表征有了专门的名字。
他的特别是词的特征表达具有了聚类性质和线性性质,在一篇文章中,football和baseketball天然聚集。
并且有 国王-女王=男人-女人的奇妙性质。(不过这个性质后来没有什么研究了,也没什么太多的应用)
word2vec解决了一个关键的问题,就是语义表征,真的有语义。不局限在字面意思。
但是不要太开心,他还没有解决一个关键的问题,上下文语义。比如play music和play football,同一个play没办法区分开是打球还是弹琴,他就是玩哎。
语言模型
看了刚才word2vec解决的问题和存在什么问题,你一定想知道,他是怎么做的吧。这里其实说来话长,说word2vec的话,要从语言模型说起。
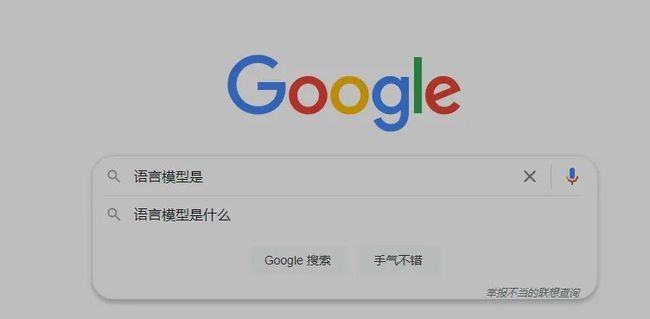
语言模型就是给你一串文本,让你猜猜后面的词是什么,以下面的图为例。不知道是啥的搜索引擎,在我敲出【语言模型是】的时候,给出了【什么】的预测,这里面就有一定程度语言模型的功劳。
形式化地表达就是算这个东西 P(wi|w1,w2,...wi−1),其中w是一个词,根据输入的前i-1个词,预测第i个词。
NNLM
语言模型除了类似贝叶斯那种统计的方法,有一个路子在这条线里非常重要,就是神经语言模型。
下面那个图,估计你看得云里雾里。不过你可以发挥一下聪明才智,要是让你穿越回20年前,让你做一个输入法预测的工具,你会怎么做?
跨时代的发明来了,这个东西是Bengio大神发明的,真的跨时代,现代NLP,都是这个简单模型的痕迹。
解释一下,这是一个基本的MLP网络,其中,最下面蓝色框是词的id,然后C是共享的矩阵参数,查表能到一个词的
嵌入参数,你这里可以理解为,输入为词的onehot表达的MLP网络。结果是一样的。
在中间经过concat后,走一层tanh激活的MLP。softmax激活,得到最大可能性词的输出概率。
其中输出的softmax维度。和词表V的大小是一样的,就是在词汇空间挑一个最大的词。
嗯,就是一个很简单的MLP。
其中关键的一步是,Table look up in C,这一步奠定了word2vec的基础。
这个东西,每个词对应的参数,掏出来就是词向量。
只不过在2013年的时候,最后那个词表对应的MLP网络实在是太奢侈了,毕竟一个词表动辄几十万,前文就算10个300维的词向量拼接,
那也是3k*30万的参数规模,实在是太奢侈了。

Word2Vec
word2vec解决了这个关键的问题,并且设计了两种语言模型的任务。
直接大放异彩。
word2vec有两种任务,
分别是CBOW和SkipGram,分别对应着上下文预测中心词,和中心词预测上下文。
如下图所示。
还有两种加速技巧,分别是负采样和哈夫曼树,这里篇幅有限,实在是没办法展开了。
但是我们要注意这里的重点是,word2vec通过,大规模无标注语料上的自监督训练语言神经网络模型。
把网络中的lookup table参数掏出来,当成词向量的。
这里有两个不平凡的地方,一个是神经语言模型,一个是从网络中提出出来的参数。

NLP的初级预训练+下游任务
好了。现在词向量有了。
等等,似乎还没有讲word2vec怎么用在NLP任务里。
这里以文本分类为例,穿插一点。以CNN做文本分类为例。
输入是词的token id,经过词向量层,映射到预训练好的词向量,然后下游通过卷积层提取特征。
基本的范式是 词向量+DNN,词向量负责提升特征表达能力,DNN负责特征提取和预测。
而在最最初期的时候,基本就是Bow(wordcount vector) + LR这样的方案。
DNN改进了LR,词向量改进了BoW,还没有从根本上改进NLP的范式。

预训练语言模型
下面是激动人心的时刻,我们先回顾下词向量的问题。
他还没有解决一个关键的问题,上下文语义。比如play music和play football,同一个play没办法区分开是打球还是弹琴,他就是玩哎。
于是预训练语言模型出来了。

预训练语言模型,与word2vec不同的是。
1.同样在语料上进行自监督训练,我把任务改造成难度更大的形式,比如完形填空,句子顺序对预测等。
2.表征参数和特征提取组件的一体化。不需要像word2vec那样掏出一层固定网络参数,我预训练语言模型本身可以实时推断一个语义表征。
从ELMO说起
预训练语言模型的开篇之作是ELMO,
源于 Deep contextualized word representation,这是NAACL在2019年的best paper。ELMO的全程是Embedding from Language Models。
ELMO是深层LSTM的堆叠,他最大的改进有两点
1、表征参数和特征提取组件的一体化,抛弃了静态词向量的方案。
2、提出了两阶段上游预训练+下游任务微调的范式
ELMO不再拆分词向量和语言模型,用语言模型本身学好一个单词的Word Embedding,一步到位。
这样很巧妙的解决了静态词向量没有语义的问题。
不足之处就是,ELMO还是以LSTM堆叠为基础的。
而LSTM有一个致命的缺点,无法做到真正的并行,网络复杂度高,在堆叠深的时候,难以快速训练。
这就限制了这个框架的潜力,而Transformer正好解决了这个问题。

Transformer引入
tansformer有个非常好的优点,就是可以跑得很快,并且做的很深。
至于是怎么实现的,还要从self-attention说起。self-attention改进了CNN那种粗暴的建模局部关键信息的思路,侧重建模元素之间的关系,
能够自动捕捉信息的关键和信息的交互,所以被称为注意力机制。
并且他有个非常好的好处,
1.就是实现以无时序的矩阵乘法为核心,矩阵乘法是GPU最擅长地方,那么我就可以做的很快。
2.可以做的比较深,我没有LSTM那种超级的复杂的非线性。我就是简单的MHA+残差。
我可以通过每一层,微弱的非线性表达做深,来提升网络容量,又不至于过拟合和难以训练。
这两个天赋决定了,transformer的潜力无穷,只要你善于挖掘他。而Bert就是充分挖掘了transformer的潜力。

Bert千呼万唤
重头戏Bert来了,其实在他之前有个GPT,这个东西,实在是尴尬,理论上GPT才是把transformer和预训练语言模型结合起来的最早的方法。
但是Bert通过改进预训练和模型细节,实在是效果太好了抢了风头,这两者区别不太大,不单独写GPT了。特别没有面子。
Bert比GPT的改进有两点:
第一、预训练任务的改进,MaskLM(完形填空)的成功应用,要比普通的根据前文预测下文效果好很多,构成了语义上的双向性。
第二、NSP任务的引进(后来很多模型把他干掉了)
还是沿用了EMLo那种两阶段的微调范式。

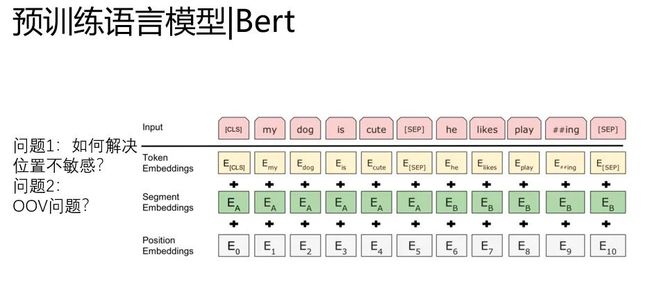
除了预训练任务的改进,Bert里面有两个关键的地方
1. position embedding引入解决了上下文不敏感的问题
2.word level降级到BPE level(单词拆分)一定程度解决了OOV的问题。
(2这个思路,在bert没有出现的时候,我们在Kaggle上2017年 jigsaw第一届的比赛用过,把word拆成bpe来训练,提分很多)
从NLP到CV的预训练
好了说了这么多,我们总结下NLP预训练技术的演进特点吧。
一、模型从浅变深,从简单NNLM变化到深层的transformer。
二、预训练任务逐渐复杂,从上下文预测演进成完形填空。
三、任务从拆分静态词向量向 深度语义向量一体化演进。
四、语义从表面向深层,语义从孤立到上下文情景敏感。
好了NLP到这里,我们继续翻到CV上。
CV从imagenet说起吧,imagenet是深度学习兴起的见证者,见证了alexnet,vgg,resenet,densenet一直到现在的基于automl的efficient。
我们对比一下,CV和NLP在初期的预训练上有什么特点。
CV上,预训练来的还是比较简单粗暴的,大家发现,在大的分类数据集上训练好的参数,当其他的初始化,效果特别好。
这么简单的思想一直在各种backbone上沿用。
但是这里面有个问题:
1.NLP里的预训练都是自监督的,凭啥你CV可以找人标注数据。
2.NLP里的预训练都是侧重输入本身的表征学习的,凭啥你CV拿个分类backbone到处忽悠人?
这两点,成为了最近CV预训练任务改进的重大范式。

CNN初步演进主要还是集中在网络结构上,对于预训练任务,大家约定俗成的似乎不太重视。
自监督的水花:对比学习
当然,在这里面也有一些水花,比如对比学习。他是图像领域为了解决
“在没有更大标注数据集的情况下,如何采用自监督预训练模式,来从中吸取图像本身的先验知识分布,得到一个预训练的模型”。
这一点很关键,在NLP里很自然的。大家使用无标注的语料,学习词向量的表达,但是在CV里,就很怪。
有没有办法不依赖标注数据,要从无标注图像中自己学习知识。
基本套路归结成三步走:
1.构造输入的变化:对同一个样本进行增强变换
2.使用backbone提取表征
3.loss:同一个样本(原始和增强),表征距离相似,不同的样本,表征的距离拉远。
具体的细节暂且不展开。
嗯这样的操作终于解决了不要标注的问题,你是一个成熟的CNN了,可以自己学起来了。不过让人比较丧气的是,这种方案的上限不太高,在imagenet能刷到70%就不错了。
但是,这是一个伟大而美好的尝试,我们先放一放,看看transformer在CV里折腾出什么花样来了。

Transformer初见威力:iGPT
与NLP不一样的地方,图像作为一种高维、噪声大、冗余度高的形态,被认为是生成建模的难点,这也是为什么过了好几年,transformer才应用到视觉领域。
其实我们想一下 就很离谱。
1. 图像是连续的,NLP是离散的,如何解决图像token输入的问题?文本是个1D序列,图像是个2D矩阵,transformer输入的形式是类序列,因此,如何转化图片为transformer的输入很关键。
2.怎么搞定图像的预训练呢?还是简单的在分类上train吗?似乎没有梦想。我想像NLP一样,自监督,学习上下文,效果还特别好。
3.transfomer的self-attention的复杂度是O(n^2 d)的。CIFA图像展开之后的序列长度是 3072,再长的大分辨率图完全搞不定了。
关键一:为了解决问题1,本文把像素从上到下,从左到右拉平,作为离散的token来输入transfomer,这里会带来问题3。后面会讲
关键二:为了解决问题2,这个论文借鉴了GPT2的结构,预训练任务设计为
1.自回归任务,根据前边的像素,逐个预测后面的像素
2.掩码语言模型MLM,类似Bert中的完形填空,只不过是像素级别的
关键三:为了解决问题3,这个论文对图像进行了压缩操作。分为两步,第一步是尺度的降采样,第二步是用Kmeans对颜色降采样为9bit。这样就非常小了。
文章中有个小trick就是,第三步。作者发现最后一层的表征不一定是最好的,结果最好的可能是中间几层,所以做了这样的操作。
这个效果挺好的,在各个数据集上刷到了SOTA,但是,他也有几个问题。
1.iGPT要想达到同样的效果,需要的参数是CNN的2倍多,速度也特别慢,iGPTL在V100上要跑2500天。。。
2.iGPT对于图片降采样,损失信息很多,CNN对这个问题不是很敏感
后续有继续的改进工作。下面再说。

这张图展示了TRM不同层向量对于结果的影响,可以看出来,先上升后下降的,所以中间层效果更好。

ViT:高效的Transformer分类预训练
我觉得上面那个iGPT的思路是不错的,不过看起来就不是很完美的文章,为了预训练的目标,降采样这种操作都出来了。
嗯后来大家改进了这个问题。我们看一下ViT吧。
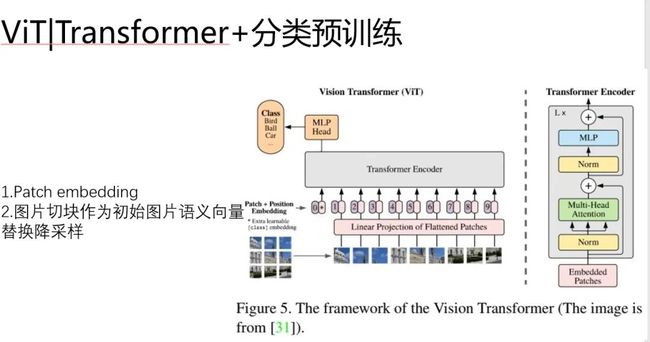
ViT很重要的一点是提出了Path+embedding的思想 替换了降采样的方式。
另外,Bert里是通过在输入开头加【CLS】来实现文本的语义表达的。如果文本能做到这件事,似乎说明了在我们离图片语义越来越近了。
ViT具体的做法是:
1.模仿Bert中的position embeding ,标记图片的位置,称为patch embeddings
2.每一个patch是一个图形小块,类比Bert中的 word embedding
ViT通过这样的方式把图片塞进了transformer,并且没有压缩。维持了【CLS】作为语义向量用来分类的特色。
但是,唯一美中不足的是,他是分类任务进行预训练的(开倒车)。
别忘了我们最初美好的愿景,我们希望像NLP一样,能从语料库里面用自监督的方式,学习到语义信息。
BEiT:Transformer+自监督
于是更接近Bert的图像Transformer出现了,他是BEIT。BEiT: BERT Pre-Training of Image Transformers
BEiT继承了ViT中Patch的做法,改进了预训练任务。
1、预训练任务变成了图像复原。
2、Patch级别的MLM引入到预训练任务中
搞CV的同学可能对这个数字很有疑惑。这个东西是个啥玩意?
他是为了引入图像复原的Visual Tokens,对应的东西是一个编号,编号里的玩意,是这个位置对应的语义向量,
预训练任务就是学习预测的 visual tokens ,复原网络,这里是通过encoder-decoder的方式来实现的。
嗯这个工作真是承上启下已经接近完美了。
但是还有一个问题,
这个模型训练的时候是分两步的。
stage1:首先优化 dVAE(图重构组件),这个我们叫重构损失,通过优化 编码和解码 ,好让dVAE 能够学习到更好的隐变量又能更好还原原图,:
stage2:然后再优化 Encoder 和 Masked Image Modeling Head(语义编码组件),为了能更好的预测出对应的 visual tokens
有没有什么办法能像NLP那样自然呢?完形填空,大道至简。
有的,kaiming大神MAE呼之欲出。


MAE:Transformer+大规模自监督的巅峰之作
大道至简,MAE秉承了自监督预训练的基因,通过encoder-decoder预训练框架,encoder输入只有image的token,decoder同时送入image token和mask token,对patch序列进行重建,完成图片复原任务。他改进了BEiT两阶段的任务。去掉了预训练编解码器的过程,并且做到了image token和mask token和分离。添加positional embedding来保持patch的位置信息。
encoder只做语义编码的事情,decoder只做图像恢复的事情。简化的模型,让速度提升显著。
在预训练任务里面,提速可以让同样的时间,过更多的数据。而自监督,意味着无穷无尽的无标注数据唾手可得。
我可以把Transformer的潜力压榨到死。

看一下图片恢复的效果,简直震惊了,这哪里是图片复原,这是脑洞打开的自动画面!

CV中的演进总结
类比下NLP中语义编码路线的发展。
我们把他从CV中扒拉出来。
一条线是从CNN到transformer的探索
另一条线是从分类预训练发展到大规模的自监督预训练。
嗯,清晰了。

CV和NLP演进的交汇
我们最后一起来看一下吧。
下图通过三种颜色标识了几个关键的阶段,然后箭头指引了优化借鉴和发展的方向。
要是非要说一条路线的话,那就是为了更好的理解知识表征这一件事。围绕着这件事,我们在更自动化,设计学习任务,加速模型,提升模型潜力天花板,上做了大量的优化工作。

你都看到了这了,一定要分享给你的同学同事,一起来学习下吧~
往期精彩回顾
适合初学者入门人工智能的路线及资料下载机器学习及深度学习笔记等资料打印机器学习在线手册深度学习笔记专辑《统计学习方法》的代码复现专辑
AI基础下载黄海广老师《机器学习课程》视频课黄海广老师《机器学习课程》711页完整版课件本站qq群955171419,加入微信群请扫码:
