视觉处理基础
视觉处理基础
简介
卷积神经网络由一个或多个卷积层和顶端的全连通层(对应经典的神经网络)组成,同时也包括关联权重和池化层(Pooling Layer)等。

上图用一个比较简单的卷积神经网络对手写输入数据进行分类,由卷积层(Conv2d)、池化层(MaxPool2d)和全连接层(Linear)叠加而成。
代码实例:
import torch
import torch.nn as nn
import torch.nn.functional as F
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
class CNNNet(nn.Module):
def __init__(self):
super(CNNNet,self).__init__()
self.conv1 = nn.Conv2d(in_channels=3,out_channels=16,kernel_size=5,stride=1)
self.pool1 = nn.MaxPool2d(kernel_size=2,stride=2)
self.conv2 = nn.Conv2d(in_channels=16,out_channels=36,kernel_size=3,stride=1)
self.pool2 = nn.MaxPool2d(kernel_size=2,stride=2)
self.fc1 = nn.Linear(1296,128)
self.fc2 = nn.Linear(128,10)
def forward(self,x):
x=self.pool1(F.relu(self.conv1(x)))
x=self.pool2(F.relu(self.conv2(x)))
x=x.view(-1,36*6*6)
x=F.relu(self.fc2(F.relu(self.fc1(x))))
return x
net = CNNNet()
net = net.to(device)
卷积层
卷积层是卷积神经网络的核心层,而卷积(Convolution)又是卷积层的核心。对卷积直观的理解,就是两个函数的一种运算,这种运算就称为卷积运算。
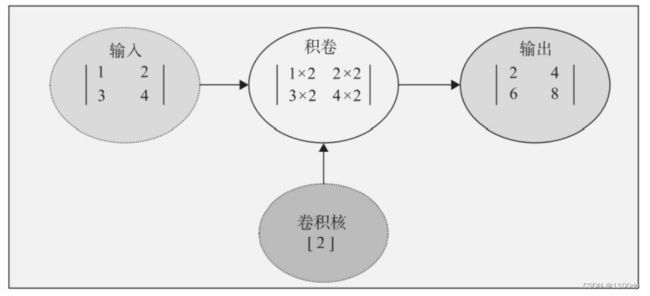
卷积核
比较简单的卷积核或过滤器有Horizontalfilter、Verticalfilter、Sobel Filter等。这些过滤器能够检测图像的水平边缘、垂直边缘、增强图像中心区域权重等。过滤器的具体作用:
(1)垂直边缘检测
这个过滤器是3×3矩阵(注,过滤器一般是奇数阶矩阵),其特点是有值的是第1列和第3列,第2列为0。经过这个过滤器作用后,就把原数据垂直边缘检测出来了。

(2)水平边缘检测
这个过滤器也是3×3矩阵,其特点是有值的是第1行和第3行,第2行为0。经过这个过滤器作用后,就把原数据水平边缘检测出来了。
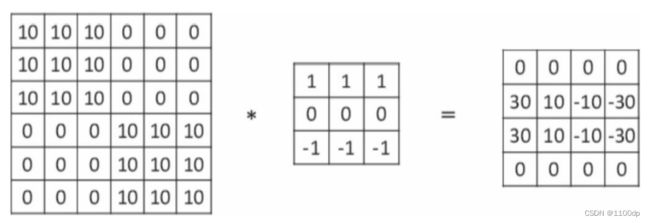
(3)过滤器对图像水平边缘检测、垂直边缘检测的效果图:

过滤器类似于标准神经网络中的权重矩阵W,W需要通过梯度下降算法反复迭代求得。同样,在深度学习学习中,过滤器也是需要通过模型训练来得到的。卷积神经网络主要目的就是计算出这些filter的数值。确定得到了这些filter后,卷积神经网络的浅层网络也就实现了对图像所有边缘特征的检测。
步幅
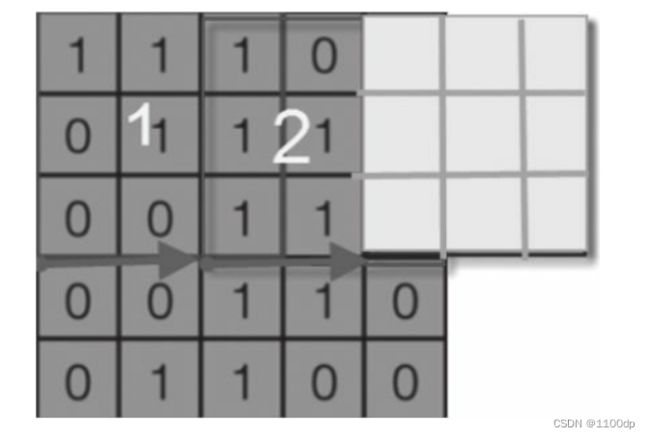
如何实现对输入数据进行卷积运算?回答这个问题前,我们先看下图。在下图的左边窗口中,左上方有个小窗口,这个小窗口实际上就是卷积核,其中x后面的值就是卷积核的值。如第1行为:x1、x0、x1对应卷积核的第1行[101]。右边窗口中这个4是如何得到的呢?就是5×5矩阵中由前3行、前3列构成的矩阵各元素乘以卷积核中对应位置的值,然后累加得到的,即:1×1+1×0+1×1+0×0+1×1+1×0+0×1+0×0+1×1=4。右边矩阵中第1行第2列的值如何得到呢?我们只要把左图中小窗口往右移动一格,然后,进行卷积运算第1行第3列,如此类推;第2行、第3行的值,只要把左边的小窗口往下移动一格,然后再往右即可。

小窗口(实际上就是卷积核或过滤器)在左边窗口中每次移动的格数(无论是自左向右移动,或自上向下移动)称为步幅(strides),在图像中就是跳过的像素个数。上面小窗口每次只移动一格,故参数strides=1。这个参数也可以是2或3等数。如果是2,每次移动时就跳2格或2个像素。

在小窗口移动过程中,其值始终是不变的,都是卷积核的值。也可以说,卷积核的值在整个过程中都是共享的,所以又把卷积核的值称为共享变量。卷积神经网络采用参数共享的方法大大降低了参数的数量。
参数strides是卷积神经网络中的一个重要参数,在用PyTorch具体实现时,strides参数格式为单个整数或两个整数的元组。
在上图strides=2中,小窗口如果继续往右移动2格,卷积核窗口部分将在输入矩阵之外,该如何处理?参考下节方法–填充(Padding)
填充
当输入图片与卷积核不匹配时或卷积核超过图片边界时,可以采用边界填充(Padding)的方法。即把图片尺寸进行扩展,扩展区域补零。
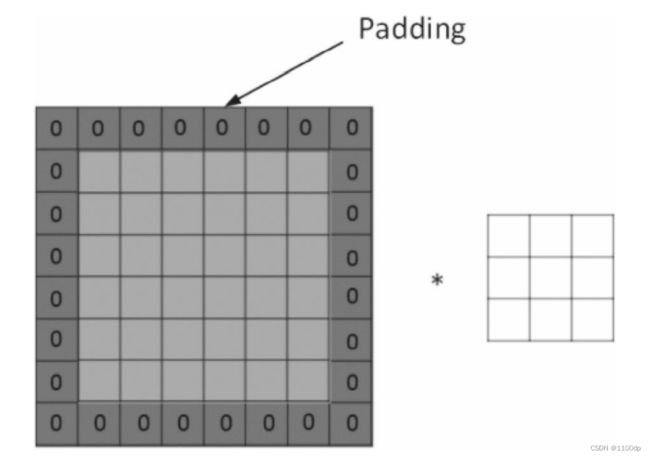
根据是否扩展Padding又分为Same、Valid。采用Same方式时,对图片扩展并补0;采用Valid方式时,不对图片进行扩展。那如何选择呢?在实际训练过程中,一般选择Same方式,使用Same不会丢失信息。设补0的圈数为p,输入数据大小为n,过滤器大小为f,步幅大小为s,则有:
p = f − 1 2 p=\frac{f-1}{2} p=2f−1
卷积后的大小为:
n + 2 p − f s + 1 \frac{n+2p-f}{s}+1 sn+2p−f+1
多通道上的卷积
但由于输入数据、卷积核都是单个,因此在图形的角度来说都是灰色的,并没有考虑彩色图片情况。但在实际应用中,输入数据往往是多通道的,如彩色图片就3通道,即R、G、B通道。对于3通道的情况应如何卷积呢?3通道图片的卷积运算与单通道图片的卷积运算基本一致,对于3通道的RGB图片,其对应的滤波器算子同样也是3通道的。例如一个图片是6×6×3,分别表示图片的高度(Height)、宽度(Weight)和通道(Channel)。过程是将每个单通道(R,G,B)与对应的filter进行卷积运算求和,然后再将3通道的和相加,得到输出图片的一个像素值。
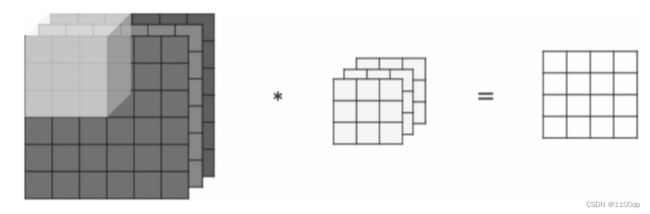
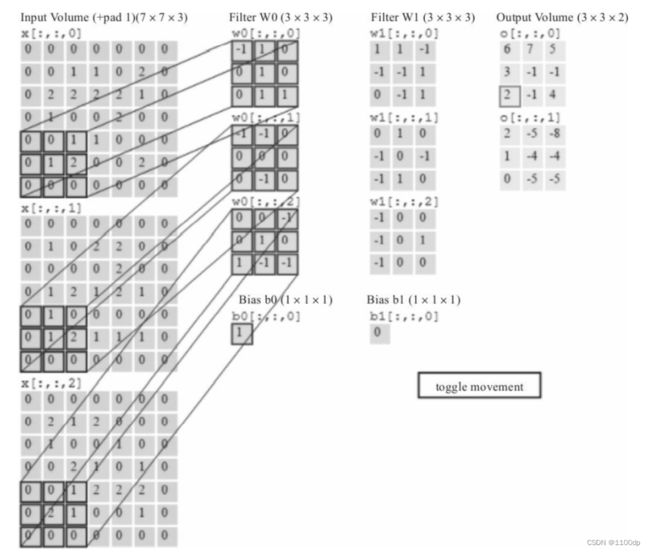
为了实现更多边缘检测,可以增加更多的滤波器组。下图就是两组过滤器Filter W0和Filter W1。7×7×3输入,经过两个3×3×3的卷积(步幅为2),得到了3×3×2的输出。
激活函数
卷积神经网络与标准的神经网络类似,为保证其非线性,也需要使用激活函数,即在卷积运算后,把输出值另加偏移量,输入到激活函数,然后作为下一层的输入。常用的激活函数有:nn.Sigmoid、nn.ReLU、nnLeakyReLU、nn.Tanh等。

卷积函数
nn.Conv2d函数
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True)
参数说明:
- in_channels(int):输入信号的通道。
- out_channels(int):卷积产生的通道。
- kerner_size(int or tuple):卷积核的尺寸。
- stride(int or tuple,optional):卷积步长。
- padding(int or tuple,optional):输入的每一条边补充0的层数。
- dilation(int or tuple,optional):卷积核元素之间的间距。
- groups(int,optional):控制输入和输出之间的连接。group=1,输出是所有的输入的卷积;group=2,此时相当于有并排的两个卷积层,每个卷积层计算输入通道的一半,并且产生的输出是输出通道的一半,随后将这两个输出连接起来。
- bias(bool,optional):如果bias=True,添加偏置。其中参数kernel_size、stride、padding、dilation也可以是一个int的数据,此时卷积height和width值相同;也可以是一个tuple数组,tuple的第一维度表示height的数值,tuple的第二维度表示width的数值。
输出形状:
- I n p u t : ( N , C i n , H i n , W i n ) Input:(N,C_{in},H_{in},W_{in}) Input:(N,Cin,Hin,Win)
- O u t p u t : ( N , C o u t , H o u t , W o u t ) Output:(N,C_{out},H_{out},W_{out}) Output:(N,Cout,Hout,Wout)这里
H o u t = H i n + 2 ∗ p a d d i n g [ 0 ] − d i l a t i o n [ 0 ] ∗ ( ( k e r n e l s i z e [ 0 ] − 1 ) − 1 ) s t r i d e [ 0 ] + 1 H_{out}=\frac{H_{in}+2*padding[0]-dilation[0]*((kernelsize[0]-1)-1)}{stride[0]}+1 Hout=stride[0]Hin+2∗padding[0]−dilation[0]∗((kernelsize[0]−1)−1)+1
W o u t = W i n + 2 ∗ p a d d i n g [ 1 ] − d i l a t i o n [ 1 ] ∗ ( ( k e r n e l s i z e [ 1 ] − 1 ) − 1 ) s t r i d e [ 1 ] + 1 W_{out}=\frac{W_{in}+2*padding[1]-dilation[1]*((kernelsize[1]-1)-1)}{stride[1]}+1 Wout=stride[1]Win+2∗padding[1]−dilation[1]∗((kernelsize[1]−1)−1)+1
- w e i g h t : ( o u t c h a n n e l s , i n c h a n n e l s g r o u p s , k e r n e l s i z e [ 0 ] , k e r n e l s i z e [ 1 ] ) weight:(out_channels,\frac{in_channels}{groups},kernelsize[0],kernel_size[1]) weight:(outchannels,groupsinchannels,kernelsize[0],kernelsize[1])
#当groups=1时:
conv = nn.Conv2d(in_channels=6, out_channels=12, kernel_size=1, groups=1)
conv.weight.data.size() #torch.Size([12, 6, 1, 1])
#当groups=2时:
conv = nn.Conv2d(in_channels=6, out_channels=12, kernel_size=1, groups=2)
conv.weight.data.size() #torch.Size([12, 3, 1, 1])
#当groups=3时:
conv = nn.Conv2d(in_channels=6, out_channels=12, kernel_size=1, groups=3)
conv.weight.data.size() #torch.Size([12, 2, 1, 1])
转置卷积
转置卷积(Transposed Convolution)在一些文献中也称为反卷积(Deconvolution)或部分跨越卷积(Fractionally-Strided Convolution)
通过卷积的正向传播的图像一般越来越小,记为下采样(Downsampled)。卷积的方向传播实际上就是一种转置卷积,它是上采样(Up-Sampling)。
假设卷积操作的相关参数为:输入大小为4,卷积核大小为3,步幅为2,填充为0,即(n=4,f=3,s=1,p=0),根据式(2)可知,输出o=2。
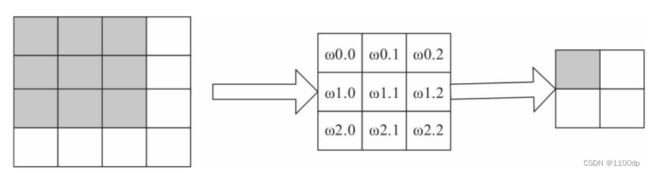
对于上述卷积运算,我们把上图所示的3×3卷积核展成一个如下所示的[4,16]的稀疏矩阵C,其中非0元素ωi,j表示卷积核的第i行和第j列。

我们再把4×4的输入特征展成[16,1]的矩阵X,那么Y=CX则是一个[4,1]的输出特征矩阵,把它重新排列2×2的输出特征就得到最终的结果,从上述分析可以看出,卷积层的计算其实是可以转化成矩阵相乘的。
反向传播:
假设损失函数为L,则反向传播时,对L关系的求导,利用链式法则得到

转置卷积在生成式对抗网络(GAN)中使用很普遍:
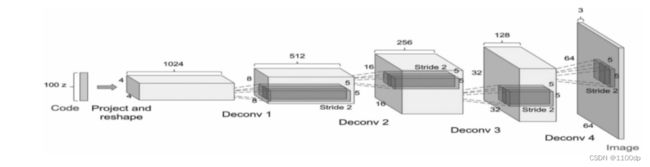
PyTorch二维转置卷积的格式为:
torch.nn.ConvTranspose2d(in_channels,out_channels,kernel_size,stride=1,padding=0,output_padding=0,groups=1,bias=True,dilation=1)
池化层
池化(Pooling)又称下采样,通过卷积层获得图像的特征后,理论上可以直接使用这些特征训练分类器(如Softmax)。但是,这样做将面临巨大的计算量挑战,而且容易产生过拟合的现象。为了进一步降低网络训练参数及模型的过拟合程度,就要对卷积层进行池化(Pooling)处理。常用的池化方式通常有3种。
- 最大池化(Max Pooling):选择Pooling窗口中的最大值作为采样值。
- 均值池化(Mean Pooling):将Pooling窗口中的所有值相加取平均,以平均值作为采样值。
- 全局最大(或均值)池化:与平常最大或最小池化相对而言,全局池化是对整个特征图的池化而不是在移动窗口范围内的池化。

池化层在CNN中可用来减小尺寸,提高运算速度及减小噪声影响,让各特征更具有健壮性。池化层比卷积层更简单,它没有卷积运算,只是在滤波器算子滑动区域内取最大值或平均值。而池化的作用则体现在降采样:保留显著特征、降低特征维度,增大感受野。深度网络越往后面越能捕捉到物体的语义信息,这种语义信息是建立在较大的感受野基础上。
局部池化
我们通常使用的最大或平均池化,是在特征图(Feature Map)上以窗口的形式进行滑动(类似卷积的窗口滑动),操作为取窗口内的平均值作为结果,经过操作后,特征图降采样,减少了过拟合现象。其中在移动窗口内的池化被称为局部池化。
在PyTorch中,最大池化常使用nn.MaxPool2d,平均池化使用nn.AvgPool2d。在实际应用中,最大池化比其他池化方法更常用。它们的具体格式如下:
torch.nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)
参数说明:
-
kernel_size:池化窗口的大小,取一个4维向量,一般是[height,width],如果两者相等,可以是一个数字,如kernel_size=3。
-
stride:窗口在每一个维度上滑动的步长,一般也是[stride_h,stride_w],如果两者相等,可以是一个数字,如stride=1。
-
padding:和卷积类似。
-
dilation:卷积对输入数据的空间间隔。
-
return_indices:是否返回最大值对应的下标。
-
ceil_mode:使用一些方块代替层结构。
输入、输出的形状计算公式如下所示。
假设输入input的形状为: ( N , C , H i n , W i n ) (N,C,H_{in},W_{in}) (N,C,Hin,Win)
输出output的形状为: ( N , C , H o u t , W o u t ) (N,C,H_{out},W_{out}) (N,C,Hout,Wout),则则输出大小与输入大小的计算公式如下所示。
H o u t = [ H i n + 2 ∗ p a d d i n g [ 0 ] − d i l a t i o n [ 0 ] ∗ ( ( k e r n e l s i z e [ 0 ] − 1 ) − 1 ) s t r i d e [ 0 ] + 1 ] H_{out}=[\frac{H_{in}+2*padding[0]-dilation[0]*((kernelsize[0]-1)-1)}{stride[0]}+1] Hout=[stride[0]Hin+2∗padding[0]−dilation[0]∗((kernelsize[0]−1)−1)+1]
W o u t = [ W i n + 2 ∗ p a d d i n g [ 1 ] − d i l a t i o n [ 1 ] ∗ ( ( k e r n e l s i z e [ 1 ] − 1 ) − 1 ) s t r i d e [ 1 ] + 1 ] W_{out}=[\frac{W_{in}+2*padding[1]-dilation[1]*((kernelsize[1]-1)-1)}{stride[1]}+1] Wout=[stride[1]Win+2∗padding[1]−dilation[1]∗((kernelsize[1]−1)−1)+1]
实例:
# 池化窗口为正方形 size=3, stride=2
m1 = nn.MaxPool2d(3, stride=2)
# 池化窗口为非正方形
m2 = nn.MaxPool2d((3, 2), stride=(2, 1))
input = torch.randn(20, 16, 50, 32)
output = m2(input)
print(output.shape)
#输出结果:torch.Size([20, 16, 24, 31])
全局池化
全局池化也分最大或平均池化。所谓的全局就是针对常用的平均池化而言,平均池化会有它的filter size,比如2×2,而全局平均池化就没有size,它针对的是整张Feature Map。下面以全局平均池化为例。全局平均池化(GlobalAverage Pooling,GAP),不以窗口的形式取均值,而是以特征图为单位进行均值化,即一个特征图输出一个值。
下图左边把4个特征图,先用一个全连接层展平为一个向量,然后通过一个全连接层输出为4个分类节点。GAP可以把这两步合二为一。我们可以把GAP视为一个特殊的Average Pool层,只不过其Pool Size和整个特征图一样大,其实就是求每张特征图所有像素的均值,输出一个数据值,这样4个特征图就会输出4个数据点,这些数据点组成一个1*4的向量。
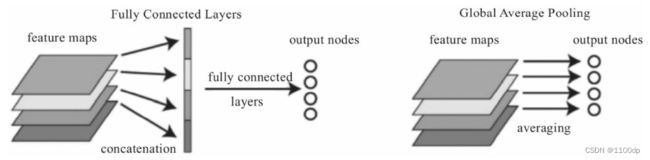
使用全局平均池化代替CNN中传统的全连接层。在使用卷积层的识别任务中,全局平均池化能够为每一个特定的类别生成一个特征图(Feature Map)。
GAP的优势在于:各个类别与Feature Map之间的联系更加直观(相比与全连接层的黑箱来说),Feature Map被转化为分类概率也更加容易,因为在GAP中没有参数需要调,所以避免了过拟合问题。GAP汇总了空间信息,因此对输入的空间转换鲁棒性更强。所以目前卷积网络中最后几个全连接层,大都用GAP替换。
全局池化层在Keras中有对应的层,如全局最大池化层(GlobalMaxPooling2D)。PyTorch虽然没有对应名称的池化层,但可以使用PyTorch中的自适应池化层(AdaptiveMaxPool2d(1)或nn.AdaptiveAvgPool2d(1))来实现,如
自适应池化层格式:
nn.AdaptiveMaxPool2d(output_size, return_indices=False)
实例:
# 输出大小为5×7
m = nn.AdaptiveMaxPool2d((5,7))
input = torch.randn(1, 64, 8, 9)
output = m(input)
# t输出大小为正方形 7×7
m = nn.AdaptiveMaxPool2d(7)
input = torch.randn(1, 64, 10, 9)
output = m(input)
# 输出大小为 10×7
m = nn.AdaptiveMaxPool2d((None, 7))
input = torch.randn(1, 64, 10, 9)
output = m(input)
# 输出大小为 1×1
m = nn.AdaptiveMaxPool2d((1))
input = torch.randn(1, 64, 10, 9)
output = m(input)
print(output.size())
#结果:torch.Size([1, 64, 1, 1])
Adaptive Pooling输出张量的大小都是给定的output_size。例如输入张量大小为(1,64,8,9),设定输出大小为(5,7),通过Adaptive Pooling层,可以得到大小为(1,64,5,7)的张量。
现代经典网络

PyTorch实现CIFAR-10多分类
数据集
CIFAR-10数据集由10个类的60000个32×32彩色图像组成,每个类有6000个图像。有50000个训练图像和10000个测试图像。
数据集分为5个训练批次和1个测试批次,每个批次有10000个图像。测试批次包含来自每个类别的恰好1000个随机选择的图像。训练批次以随机顺序包含剩余图像,但由于一些训练批次可能包含来自一个类别的图像比另一个更多,因此总体来说,5个训练集之和包含来自每个类的正好5000张图像。
下图显示了数据集中涉及的10个类,以及来自每个类的10个随机图像。
这10类都是彼此独立的,不会出现重叠,即这是多分类单标签问题。
加载数据
#导入库及下载数据
import torch
import torchvision
import torchvision.transforms as transforms
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=4,shuffle=False, num_workers=2)
classes = ('plane', 'car', 'bird', 'cat','deer', 'dog', 'frog', 'horse', 'ship', 'truck')
#随机查看部分数据
import matplotlib.pyplot as plt
import numpy as np
%matplotlib inline
#显示图像
def imshow(img):
img = img / 2 + 0.5 #unnormalize
npimg = img.numpy()
plt.imshow(np.transpose(npimg,(1,2,0)))
plt.show()
#随机获取部分训练数据
dataiter = iter(trainloader)
images, labels = dataiter.next()
#显示图像
imshow(torchvision.utils.make_grid(images))
#打印标签
print(' '.join('%5s' % classes[labels[j]] for j in range(4)))
结果:

构建网络
#构建网络
import torch.nn as nn
import torch.nn.functional as F
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
class CNNNet(nn.Module):
def __init__(self):
super(CNNNet,self).__init__()
self.conv1 = nn.Conv2d(in_channels=3,out_channels=16,kernel_size=5,stride=1)
self.pool1 = nn.MaxPool2d(kernel_size=2,stride=2)
self.conv2 = nn.Conv2d(in_channels=16,out_channels=36,kernel_size=3,stride=1)
self.pool2 = nn.MaxPool2d(kernel_size=2,stride=2)
self.fc1 = nn.Linear(1296,128)
self.fc2 = nn.Linear(128,10)
def forward(self,x):
x = self.pool1(F.relu(self.conv1(x)))
x = self.pool2(F.relu(self.conv2(x)))
x = x.view(-1,36*6*6)
x = F.relu(self.fc2(F.relu(self.fc1(x))))
return x
net = CNNNet()
net = net.to(device)
#查看网络结构
print(net)
#取模型中的前四层
nn.Sequential(*list(net.children())[:4])
#初始化参数
for m in net.modules():
if isinstance(m,nn.Conv2d):
nn.init.normal_(m.weight)
nn.init.xavier_normal_(m.weight)
nn.init.kaiming_normal_(m.weight)#卷积层参数初始化
nn.init.constant_(m.bias,0)
elif isinstance(m,nn.Linear):
nn.init.normal_(m.weight)#全连接层参数初始化
CNNNet(
(conv1): Conv2d(3, 16, kernel_size=(5, 5), stride=(1, 1))
(pool1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv2): Conv2d(16, 36, kernel_size=(3, 3), stride=(1, 1))
(pool2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(fc1): Linear(in_features=1296, out_features=128, bias=True)
(fc2): Linear(in_features=128, out_features=10, bias=True)
)
训练模型
#选择优化器
import torch.optim as optim
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(),lr=0.001,momentum=0.9)
#训练模型
for epoch in range(10):
running_loss = 0.0
for i,data in enumerate(trainloader,0):
#获取数据集
inputs,labels = data
inputs,labels = inputs.to(device),labels.to(device)
#权重参数梯度清零
optimizer.zero_grad()
#正向及反向传播
outputs = net(inputs)
loss = criterion(outputs,labels)
loss.backward()
optimizer.step()
#显示损失值
running_loss += loss.item()
if i%2000 == 1999: # print every 2000 mini-batches
print('[%d,%5d] loss: %.3f' %(epoch+1,i+1,running_loss/2000))
running_loss = 0.0
print('Finished Training')
结果:
测试模型
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images,labels = data
images,labels = images.to(device),labels.to(device)
outputs = net(images)
_,predicted = torch.max(outputs.data,1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the netword on the 10000 test images: %d %%' %(100*correct/total))
结果:Accuracy of the netword on the 10000 test images: 68 %
#各种类别的准确率:
class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))
with torch.no_grad():
for data in testloader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = net(images)
_, predicted = torch.max(outputs, 1)
c = (predicted == labels).squeeze()
for i in range(4):
label = labels[i]
class_correct[label] += c[i].item()
class_total[label] += 1
for i in range(10):
print('Accuracy of %5s : %2d %%' % (classes[i], 100 * class_correct[i] / class_total[i]))

采用全局平均池化
PyTorch可以用nn.AdaptiveAvgPool2d(1)实现全局平均池化或全局最大池化。
import torch.nn as nn
import torch.nn.functional as F
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
class Net(nn.Module):
def __init__(self):
super(Net,self).__init__()
self.conv1 = nn.Conv2d(3,16,5)
self.pool1 = nn.MaxPool2d(2,2)
self.conv2 = nn.Conv2d(16,36,5)
#self.fc1 = nn.Linear(16*5*5,120)
self.pool2 = nn.MaxPool2d(2,2)
#使用全局平均池化层
self.aap = nn.AdaptiveAvgPool2d(1)
self.fc3 = nn.Linear(36,10)
def forward(self,x):
x = self.pool1(F.relu(self.conv1(x)))
x = self.pool2(F.relu(self.conv2(x)))
x = self.aap(x)
x = x.view(x.shape[0],-1)
x = self.fc3(x)
return x
net = Net()
net = net.to(device)
参考书籍:《Python深度学习:基于PyTorch》